[논문리뷰] Segment Any Motion in Videos
CVPR 2025. [Paper] [Page] [Github]
Nan Huang, Wenzhao Zheng, Chenfeng Xu, Kurt Keutzer, Shanghang Zhang, Angjoo Kanazawa, Qianqian Wang
UC Berkeley | Peking University
28 Mar 2025

Introduction
본 논문에서는 SAM2의 능력을 활용하여 moving object segmentation (MOS)을 위한 장기적인 track과 SAM2의 조합을 제안하였다. Point tracking은 변형 및 occlusion에 robust한 장기적인 모션 정보를 포착한다. 동시에, DINO feature를 통합하여 모션 기반 segmentation을 지원하는 보완적인 semantic 정보를 추가한다. 본 논문에서는 모션 및 semantic 정보를 고차원에서 효과적으로 결합하는 방대한 데이터셋을 기반으로 모델을 학습시킴으로써 기존의 MOS 방식에서 벗어나고자 하였다.
장기적인 2D track 세트가 주어졌을 때, 모델은 이동하는 물체에 해당하는 track을 식별하도록 설계되었다. 동적인 track이 식별되면, SAM2에 반복적으로 프롬프팅하여 sparse point들을 segmentation mask로 변환하는 sparse-to-dense mask densification 전략을 적용한다. MOS가 주요 목표이므로, semantic 정보를 보조적인 정보로 사용하면서 모션 단서를 강조한다. 이 두 가지 유형의 정보를 효과적으로 균형 있게 조절하기 위해, 저자들은 두 가지 전문화된 모듈을 제안하였다.
- Spatio-Temporal Trajectory Attention: 입력 track의 장기적인 특성을 고려하여, spatial attention을 통합하여 서로 다른 궤적 간의 관계를 파악하고, temporal attention을 통합하여 개별 궤적 내의 시간 경과에 따른 변화를 모니터링.
- Motion-Semantic Decoupled Embedding: 모션 패턴의 우선순위를 정하고 보조 경로에서 semantic feature를 처리하기 위한 특수 attention 메커니즘.
저자들은 합성 데이터와 실제 데이터를 모두 포함한 광범위한 데이터셋을 사용하여 모델을 학습시켰다. DINO feature의 self-supervised 특성 덕분에, 본 모델은 주로 합성 데이터로 학습했을 때에도 강력한 일반화 성능을 보여준다.
기존 MOS 방식은 optical flow를 활용했지만, optical flow는 단기적인 모션에만 국한되며 장기적인 모션에서는 추적이 어려울 수 있다. 또한, 모션 단서로 포인트 궤적을 활용하는 방식들은 복잡한 모션을 처리하는 데 어려움을 겪는다. 일부 방법들은 외형 단서를 활용하였지만, 일반적으로 다양한 모달리티를 여러 단계로 나누어 처리하기 때문에 상호 보완적인 정보의 효과적인 통합이 제한된다. 이러한 한계를 해결하기 위해 본 논문의 방법은 장기적인 궤적, DINO feature, SAM2의 통합을 달성했다.
Method
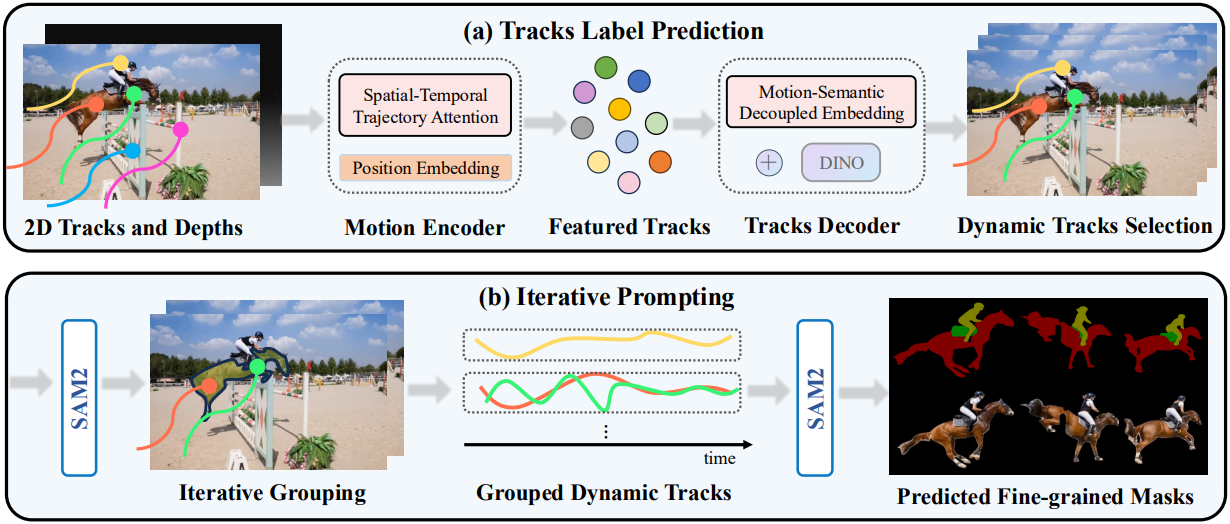
1. Motion Pattern Encoding
포인트 궤적은 모션을 이해하는 데 중요한 정보를 제공하며, 관련 MOS 기법은 일반적으로 2-프레임 기법과 다중 프레임 기법의 두 가지 카테고리로 분류할 수 있다. 그러나 2-프레임 기법은 시간적 불일치가 심하고 입력 flow에 잡음이 많을 때 성능이 저하되는 경우가 많다. 다중 프레임 기법은 잡음에 매우 민감하며 글로벌하고 동적이며 복잡한 움직임 패턴을 효과적으로 처리하는 데 어려움을 겪는다.
이러한 한계를 해결하기 위해, 저자들은 특수 궤적 처리 모델을 통해 처리된 장기적 point track을 활용하여 궤적별 모션 레이블을 예측하는 방법을 제안하였다. 네트워크는 인코더-디코더 아키텍처를 채택한다. 인코더는 장기적 궤적 데이터를 직접 처리하고, 궤적 전반에 걸쳐 Spatio-Temporal Trajectory Attention 메커니즘을 적용한다. 이 메커니즘은 공간적 단서와 시간적 단서를 모두 통합하여 시간과 공간에 걸쳐 로컬 및 글로벌 정보를 모두 포착하여 각 궤적의 모션 패턴을 임베딩한다.
장기적인 궤적의 정확도와 품질이 모델 성능에 상당한 영향을 미친다는 점을 고려하여 BootsTAP을 사용하여 궤적을 생성한다. BootsTAP은 각 timestep의 각 궤적에 대한 신뢰도 점수를 제공하여 신뢰도가 낮은 포인트를 마스킹할 수 있도록 한다. 또한, 동적 물체의 움직임과 카메라 모션으로 인해 장기적인 궤적의 가시성(visibility)은 시간이 지남에 따라 달라질 수 있다. 궤적이 가려지거나 프레임 밖으로 이동할 수 있기 때문이다. 이러한 visibility와 신뢰도의 변동성으로 인해 각 궤적 데이터는 매우 불규칙적이기 때문에, transformer 모델을 사용하여 데이터를 효과적으로 처리한다.
입력 데이터는 장기적인 궤적으로 구성되며, 각 궤적은 정규화된 픽셀 좌표 $(u_i, v_i)$, visibility \(\rho_i\), 신뢰도 점수 $c_i$로 구성된다. 마스크 \(\mathcal{M}_i\)는 픽셀 좌표가 보이지 않거나 신뢰도가 낮은 포인트를 나타내는 데 적용된다. 또한, Depth-Anything으로 추정된 monocular depth map $d_i$를 통합한다. $d_i$는 약간의 노이즈에도 불구하고 기본 3D 장면 구조에 대한 귀중한 통찰력을 제공하여 공간 레이아웃과 occlusion에 대한 이해를 향상시킨다. 입력 데이터를 더욱 풍부하게 하고 시간적 모션 단서를 강화하기 위해, 인접 프레임 간의 궤적 좌표의 차이 \((\Delta u_i, \Delta v_i)\)와 깊이의 차이 \(\Delta d_i\)를 계산한다.
좌표에서 인접한 샘플링 포인트는 공간적으로 가까운 feature의 oversmoothing을 초래할 수 있으므로, NeRF와 비슷하게 위치 인코딩에 주파수 변환을 적용하여 세밀한 공간적 디테일을 더욱 효과적으로 포착한다.
최종 궤적은 두 개의 MLP를 통과하여 중간 feature를 생성한 다음, 이 feature들을 transformer 인코더 $\mathcal{E}$에 공급한다. 입력 데이터의 장기적인 특성을 고려하여, 인코더 $\mathcal{E}$를 위한 Spatio-Temporal Trajectory Attention을 제안하였다. 이 attention은 track과 시간 차원을 번갈아 가며 작동하는 attention layer를 끼어넣은 디자인이다. 이 디자인을 통해 모델은 각 궤적 내의 시간적 역학과 여러 궤적 간의 공간적 관계를 모두 포착할 수 있다. 마지막으로, 개별 포인트가 아닌 각 전체 궤적에 대한 feature 표현을 얻기 위해 시간 차원을 따라 max-pooling을 수행한다. 이 프로세스는 각 궤적에 대해 하나의 feature 벡터를 생성하여 자연스럽게 각 궤적의 고유한 모션 패턴을 암시적으로 포착하는 고차원 feature track을 형성한다.
2. Per-trajectory Motion Prediction
모션 패턴을 인코딩했지만 모션 단서만으로 움직이는 물체를 구분하는 것은 여전히 어렵다. 이는 고도로 추상화된 궤적에서 물체의 움직임과 카메라 모션을 구분하는 학습이 모델에 어렵기 때문이다. 본 논문에서는 self-supervised 모델인 DINO v2에서 예측한 DINO feature를 통합하여 외형 정보를 일반화하는 데 도움을 주었다. 그러나 단순히 DINO feature를 입력으로 도입하면 모델이 semantic에 지나치게 의존하게 되어, 동일한 semantic 카테고리 내에서 움직이는 물체와 정적 물체를 구분하는 능력이 저하된다. 이 문제를 해결하기 위해, 저자들은 transformer 디코더 $\mathcal{D}$가 semantic 단서를 고려하면서도 모션 정보의 우선순위를 정할 수 있도록 하는 Motion-Semantic Decoupled Embedding을 제안하였다.
최종 임베딩된 feature track $\mathcal{P}$는 다음과 같다.
\[\begin{equation} \mathcal{P} = \mathcal{E} ((\gamma (u), \gamma (v), \gamma (\Delta u), \gamma (\Delta v), d, \Delta d, \rho, c), \mathcal{M}) \end{equation}\]Transformer 디코더 $\mathcal{D}$의 인코더 레이어는 모션 정보만을 포함하는 $\mathcal{P}$에 대해서만 attention을 수행한다. Attention 가중치가 적용된 feature를 계산한 후, DINO feature를 concat하고 이 concat된 feature를 feed-forward layer로 전달한다. 디코더 레이어에서는 self-attention이 모션 feature에만 적용되지만, multi-head attention을 사용하여 semantic 정보가 포함된 메모리에 attention한다. 마지막으로, sigmoid 함수를 적용하여 최종 출력을 생성하고, 각 궤적에 대한 예측 레이블을 도출한다.
그런 다음, weighted binary cross-entropy loss를 사용하여 예측된 레이블과 track별 GT 레이블 간의 loss를 계산한다. 샘플링된 포인트 좌표가 실제 동적 마스크 내에 있는지 확인하여 각 궤적에 GT 레이블을 할당한다. 포인트가 마스크 내에 있으면 동적 레이블로 표시된다.
3. SAM2 Iterative Prompting
각 궤적의 예측 레이블을 구하고 동적 궤적을 필터링한 후, 이 궤적들을 SAM2의 포인트 프롬프트로 사용하여 반복적인 2단계 프롬프트 전략을 적용한다. 첫 번째 단계는 동일한 물체에 속하는 궤적들을 그룹화하고 각 물체의 궤적을 메모리에 저장하는 데 중점을 둔다. 두 번째 단계에서는 이 메모리를 SAM2의 프롬프트로 사용하여 동적 마스크를 생성한다.
이 접근 방식의 동기는 두 가지이다.
- SAM2가 입력으로 object ID를 요구하기 때문에 필수적이다. 그러나 모든 동적 객체에 동일한 object ID를 할당하면, SAM2는 동일한 ID를 공유하는 여러 물체를 동시에 분할하는 데 어려움을 겪는다.
- 이 방법은 더욱 세밀한 segmentation을 달성할 수 있다는 이점을 제공한다.
첫 번째 단계에서는 보이는 포인트의 수가 가장 많은 프레임을 선택하고 해당 프레임의 모든 보이는 포인트 중 가장 dense한 포인트를 찾는다. 이 포인트는 SAM2의 초기 프롬프트 역할을 하며, 이후 해당 프레임에 대한 초기 마스크를 생성한다. 이 마스크를 생성한 후 경계를 확장하기 위해 dilation을 적용하고, 확장된 마스크 영역 내의 모든 포인트를 제외하여 edge point를 제거하고 이러한 포인트가 동일한 물체에 속한다고 가정한다. 그런 다음, 보이는 포인트의 수가 가장 많은 다음 프레임으로 진행하고 모든 프레임에서 남아 있는 보이는 포인트가 너무 적어서 처리할 수 없을 때까지 이 프로세스를 반복한다. 같은 물체에 속하는 것으로 식별된 궤적은 각각에 고유한 객체 ID가 할당되어 메모리에 저장된다. 각 물체에 대해 dilation되지 않은 마스크 내의 포인트만 저장한다.
두 번째 단계에서는 이 메모리를 사용하여 저장된 궤적 내에서 가장 dense한 지점과 그 지점에서 가장 먼 두 지점을 찾아 프롬프트 선택을 개선한다. SAM2가 중간에 물체를 추적하지 못하는 것을 방지하기 위해 일정한 간격으로 프롬프트를 생성한다. SAM2는 부분적인 물체 마스크를 생성할 수 있으므로, 모든 마스크에 후처리를 수행하여 내부적으로 겹치거나 동일한 마스크 경계 내에 나타나는 마스크를 병합한다. 이를 통해 각 개별 물체에 대한 완전한 마스크가 생성된다.
Experiments
1. Moving Object Segmentation
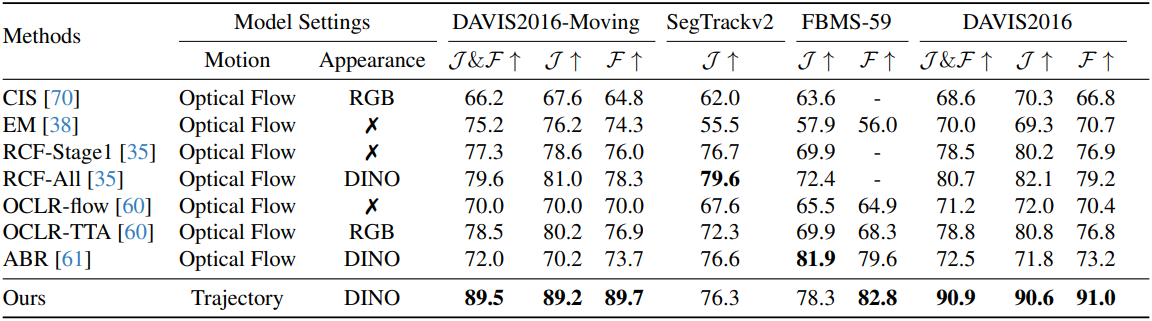
다음은 다양한 MOS 벤치마크에서의 성능을 비교한 표이다.
다음은 DAVIS17-moving 벤치마크에서의 결과를 비교한 예시이다.

다음은 FBMS-59 벤치마크에서의 결과를 비교한 예시이다.

다음은 SegTrack v2 벤치마크에서의 결과를 비교한 예시이다.

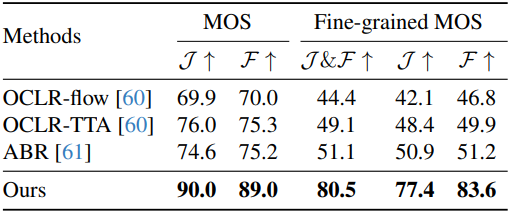
2. Fine-grained Moving Object Segmentation
다음은 Fine-grained MOS에 대한 비교 결과이다.

3. Ablation Study
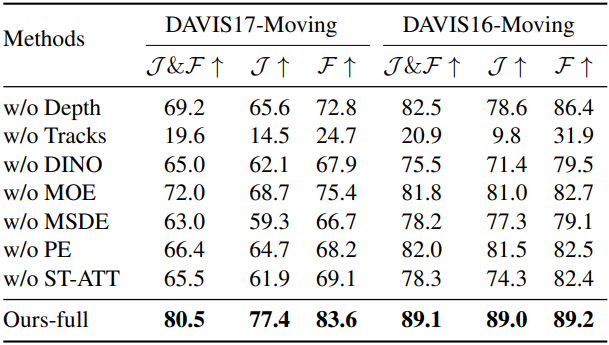
다음은 ablation study 결과이다.

Limitation
- Tracking 모델에 대한 의존한다.
- 잠깐 나타나는 빠르게 움직이는 물체에 실패할 가능성이 높다.
- 더 뚜렷한 움직임을 보이는 물체가 있는 경우, 덜 역동적인 물체가 간과될 수 있다.
- SAM2에 제공된 프롬프트애 따라 전체 물체에 대한 결과가 아닌 부분적이거나 단편적인 결과를 초래할 수 있다.
- 대부분의 물체가 유사한 동작 상태를 공유하는 경우, 개별 물체를 효과적으로 구분하지 못한다.