[논문리뷰] Segment Everything Everywhere All at Once (SEEM)
NeurIPS 2023. [Paper] [Github]
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Gao, Yong Jae Lee
University of Wisconsin-Madison | Microsoft Research at Redmond | HKUST | Microsoft Cloud & AI
13 Apr 2023

Introduction
ChatGPT와 같은 Large Language Models (LLM)의 성공은 인간과 상호 작용하는 현대 AI 모델의 중요성을 보여주었고 AGI를 엿볼 수 있게 해주었다. 인간과 상호 작용할 수 있으려면 가능한 한 많은 유형의 인간 입력을 받아들이고 인간이 쉽게 이해할 수 있는 응답을 생성할 수 있는 사용자 친화적인 인터페이스가 필요하다. NLP에서 이러한 범용 상호 작용 인터페이스는 GPT, T5와 같은 초기 모델에서 prompting과 chain-of-thought과 같은 일부 고급 기술로 한동안 등장하고 발전했다. 이미지 생성 영역에서 최근 몇 가지 연구들을 텍스트 프롬프트를 스케치 또는 레이아웃과 같은 다른 유형과 결합하여 사용자 의도를 보다 정확하게 캡처하고 새로운 프롬프트를 구성하며 multi-round 인간-AI 상호 작용을 지원하려고 시도하였다.
Interactive image segmentation은 오랜 역사를 가지고 있지만 입력으로 여러 유형의 프롬프트(ex. 텍스트, 클릭, 이미지)를 취할 수 있는 범용 인터페이스를 통해 인간과 상호 작용할 수 있는 segmentation model은 잘 탐색되지 않았다. 기존의 interactive segmentation 방법은 클릭이나 낙서와 같은 공간적 힌트를 사용하거나 언어를 사용하여 segmentation을 참조한다. 가장 최근에는 텍스트 프롬프트와 박스 프롬프트를 결합한 몇 가지 연구들이 있었다. 그러나 실제 애플리케이션의 요구 사항에 도달하기에는 1~2개의 프롬프트 유형만 사용할 수 있다.
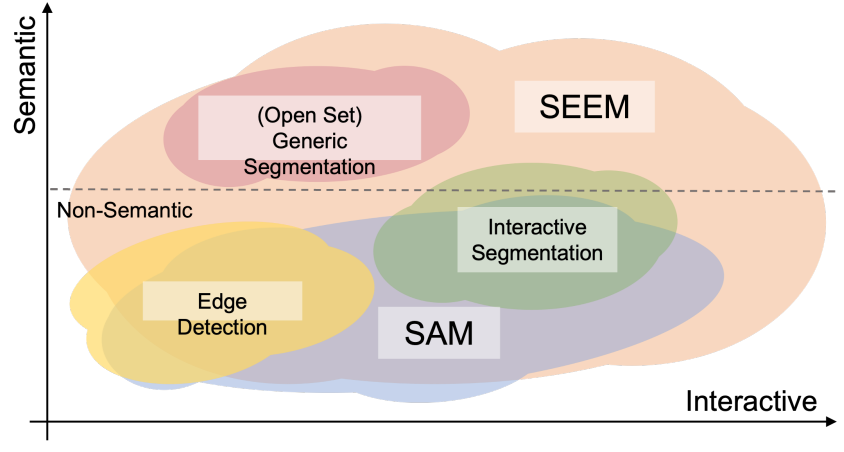
SAM은 여러 프롬프트를 지원하지만, 본 논문은 위 그림과 같이 SAM과 매우 다르다. 예를 들어 SAM은 점과 박스와 같은 제한된 상호 작용 유형만 지원하고 semantic 레이블을 출력하지 않기 때문에 높은 수준의 semantic task를 지원하지 않는다.
본 논문에서는 multi-modal 프롬프트를 사용하여 모든 곳에서 모든 것을 분할하기 위한 범용 인터페이스를 목표로 한다. 이 목표를 달성하기 위해 네 가지 중요한 속성을 가진 새로운 프롬프트 체계를 사용한다.
- Versatility (다재다능성)
- Compositionality (합성성)
- Interactivity (상호작용성)
- Semantic-awareness (의미 인식)
Versatility를 위해 본 논문은 점, 마스크, 텍스트, 상자, 심지어 이질적으로 보이는 다른 이미지의 참조 영역을 동일한 joint visual-semantic space에서 프롬프트로 인코딩한다. 이와 같이 본 논문의 모델은 입력 프롬프트의 모든 조합을 처리할 수 있으므로 강력한 compositionality을 제공한다. Interactivity을 위해 이전 segmentation 정보를 압축한 다음 다른 프롬프트와의 통신을 위한 메모리 프롬프트를 추가로 도입한다. Semantic-awareness의 경우, 본 논문의 모델은 모든 출력 segmentation에 열린 집합의 semantic을 제공한다.
제안된 프롬프팅 체계와 함께 추가 텍스트 인코더가 있는 간단한 Transformer 인코더-디코더 아키텍처를 따르는 segment-everything-everywhere (SEEM) model을 구축한다. SEEM에서 디코딩 프로세스는 생성 LLM과 유사하게 작동하지만 multimodality-in-multimodality-out을 사용한다. 모든 쿼리는 프롬프트로 받아 디코더에 입력되며 이미지 및 텍스트 인코더는 모든 유형의 쿼리를 인코딩하는 프롬프트 인코더로 사용된다. 구체적으로, 텍스트 인코더를 사용하여 텍스트 쿼리를 텍스트 프롬프트로 변환하는 동안 이미지 인코더에서 해당 시각적 feature를 풀링하여 점, 박스, 낙서와 같은 모든 공간 쿼리를 시각적 프롬프트로 인코딩한다. 이렇게 하면 시각적 프롬프트와 텍스트 프롬프트가 항상 서로 정렬된다. 예제 이미지 세그먼트를 쿼리로 채택할 때 동일한 이미지 인코더로 이미지를 인코딩하고 그에 따라 이미지 feature를 풀링한다.
결국 5가지 유형의 프롬프트가 모두 joint visual-semantic space에 매핑되어 zero-shot adaptation을 통해 보지 못는 사용자 프롬프트를 활성화한다. 다양한 segmentation task에 대한 학습을 통해 모델은 다양한 프롬프트를 처리할 수 있다. 또한 서로 다른 유형의 프롬프트는 프롬프트 간의 cross-attention을 통해 서로 도움이 될 수 있다. 따라서 더 나은 segmentation 결과를 얻기 위해 프롬프트를 합성할 수 있다. 마지막으로 사전 학습된 단일 모델로 모든 개체를 semantic 체계로 분할하고 (everything), 이미지의 모든 픽셀을 커버하고 (everywhere), 프롬프트의 모든 구성을 지원할 수 있는 segmentation 인터페이스를 구축한다 (all at once).
강력한 일반화 기능 외에도 SEEM은 효율적으로 실행할 수 있다. 프롬프트를 디코더에 대한 입력으로 사용한다. 따라서 인간과 multi-round 상호 작용을 수행할 때 모델은 처음에 feature extractor를 한 번만 실행하면 된다. 반복할 때마다 새 프롬프트로 가벼운 디코더를 다시 실행하기만 하면 된다. 모델을 배포할 때 일반적으로 서버에서 무거운 feature extractor를 실행하고 사용자 컴퓨터에서 가벼운 디코더를 실행하여 여러 원격 호출에서 네트워크 지연을 줄일 수 있다.
Method
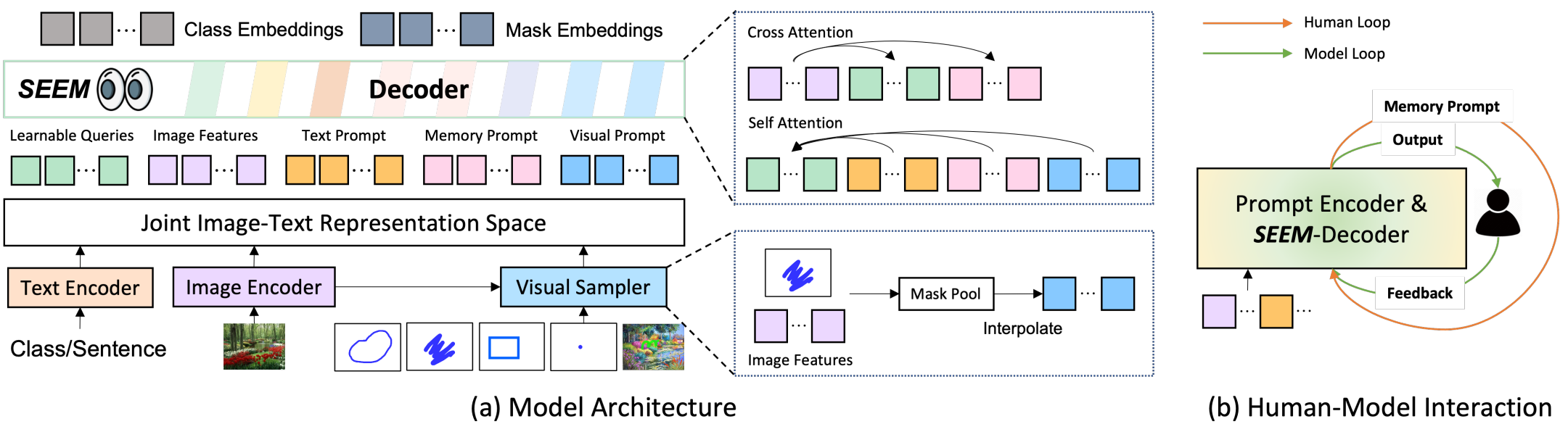
SEEM은 일반적인 인코더-디코더 아키텍처를 사용하지만 특히 위 그림의 (a)에 표시된 것처럼 쿼리와 프롬프트 간의 정교한 상호 작용을 특징으로 한다. 입력 이미지 $I \in \mathbb{R}^{H \times W \times 3}$가 주어지면 이미지 인코더는 먼저 이미지 feature $Z$를 추출하는 데 사용된다. 그런 다음, seem-decoder는 쿼리 출력 $O_h^m$(마스크 임베딩)과 $O_h^c$(클래스 임베딩)를 기반으로 마스크 $M$과 semantic 개념 $C$를 예측한다. 임베딩들은 텍스트, 비주얼, 메모리 프롬프트 $\langle P_t, P_v, P_m \rangle$과 상호 작용한다.
여기서 $Q_h$는 학습 가능한 쿼리들이고, $P_t$, $P_v$, $P_m$은 각각 텍스트 프롬프트, 비주얼 프롬프트, 메모리 프롬프트이다.
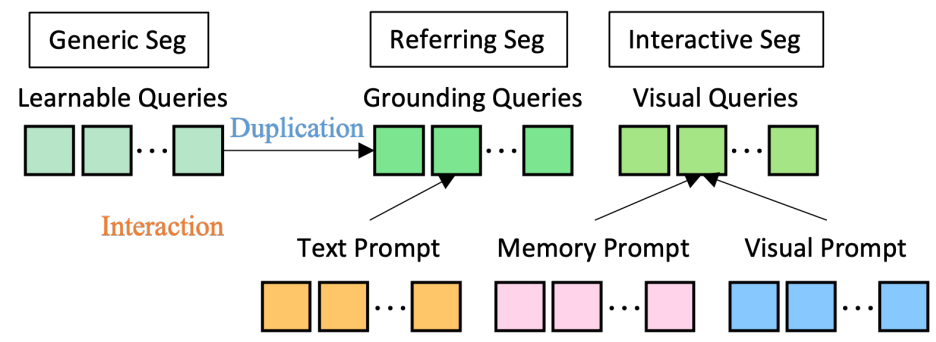
학습 중에 $Q_h$는 위 그림과 같이 generic segmentation, referring segmentation, interactive segmentation을 위해 복제된다. 그리고 해당 프롬프트는 self-attention 모듈을 통해 쿼리와 상호 작용한다. Inference 시 학습 가능한 쿼리들은 모든 프롬프트와 자유롭게 상호 작용하므로 zero-shot 구성이 가능하다.
이 디자인은 X-Decoder의 성공적인 사례에서 영감을 받았다. 그러나 비주얼 프롬프트와 메모리 프롬프트를 추가하여 다음 속성들을 가진 이미지 segmentation을 위한 범용 모델이 가능해졌다.
Versatile
SEEM에서는 점, 박스, 낙서 및 다른 이미지의 참조 영역과 같은 텍스트가 아닌 모든 입력을 처리하기 위해 시각적 프롬프트 $P_v$를 도입했다. 이러한 비텍스트 쿼리는 텍스트 프롬프트가 올바른 세그먼트를 식별하지 못할 때 사용자의 의도를 명확하게 하는 데 유용하다.
Interactive segmentation을 위해 이전 연구들은 공간적 쿼리를 마스크로 변환하고 이미지 backbone에 공급하거나 각 입력 유형(점, 박스)에 대해 다른 프롬프트 인코더를 사용하였다. 첫 번째 접근 방식은 각 상호 작용에서 이미지가 feature extractor를 통과해야 하기 때문에 애플리케이션에서 너무 무겁다. 두 번째 접근 방식은 보지 못한 프롬프트로 일반화하기 어렵다. 이러한 제한 사항을 해결하기 위해 모든 종류의 비텍스트 쿼리를 동일한 시각적 임베딩 space에 있는 시각적 프롬프트로 변환하는 시각적 샘플러를 사용한다.
\[\begin{equation} P_v = \textrm{VisualSampler} (s, \hat{Z}) \end{equation}\]여기서 $\hat{Z}$는 타겟 이미지 $Z$나 참조된 이미지에서 추출한 feature map이고 \(s \in \{\textrm{points}, \textrm{box}, \textrm{scribbles}, \textrm{polygons}\}\)는 사용자가 정한 샘플링 위치이다. 먼저 점 샘플링을 통해 이미지 feature에서 해당 영역을 풀링했다. 모든 시각적 프롬프트에 대해 프롬프트에 지정된 영역에서 균일하게 최대 512개의 점 feature vector를 보간한다. 참조된 이미지의 경우에도 샘플링 방식은 샘플 이미지가 예제 이미지인 경우와 동일하다. 이 방법의 또 다른 장점은 모델이 panoptic 및 referring segmentation을 통해 joint visual-semantic space을 지속적으로 학습하므로 시각적 프롬프트가 텍스트 프롬프트와 자연스럽게 잘 정렬된다는 것이다.
Compositional
실제로 사용자는 서로 다른 입력 유형 또는 결합된 입력 유형을 사용하여 의도를 전달할 수 있다. 따라서 프롬프트에 대한 구성 접근 방식은 실제 애플리케이션에 필수적이다. 그러나 모델 학습 중에 두 가지 문제에 직면한다.
- 학습 데이터는 일반적으로 단일 유형의 상호 작용(ex. 없음, 텍스트, 비주얼)만 다룬다.
- 모든 비텍스트 프롬프트를 통합하고 텍스트 프롬프트와 정렬하기 위해 시각적 프롬프트를 사용했지만 임베딩 space는 본질적으로 다르다.
이 문제를 해결하기 위해 서로 다른 유형의 프롬프트를 서로 다른 출력과 매칭시킨다. 시각적 프롬프트는 이미지 feature에서 나오고 텍스트 프롬프트는 텍스트 인코더에서 나온다는 점을 고려하여 각각 마스크 임베딩 $O_h^m$ 또는 클래스 임베딩 $O_h^c$와 매칭시켜 시각적 및 텍스트 프롬프트에 대해 일치하는 출력 인덱스를 선택한다.
\[\begin{aligned} ID_v &\leftarrow \textrm{Match} (O_h^m \cdot P_v + \textrm{IoU}_{mask}) \\ ID_t &\leftarrow \textrm{Match} (O_h^c \cdot P_t + \textrm{IoU}_{mask}) \end{aligned}\]여기서 \(\textrm{IoU}_{mask}\)는 ground-truth 마스크들과 예측된 마스크들 사이의 IoU이다. 제안된 별도의 매칭 방법은 모든 프롬프트에 대해 $O_h^m$ 또는 $O_h^c$와만 매칭하는 접근 방식보다 우수한 것으로 나타났다.
학습 후에 모델은 모든 프롬프트 유형에 익숙해지고 동일한 모델과 가중치를 사용하여 프롬프트가 없는 경우, 하나의 프롬프트 유형을 사용하는 경우, 시각적 및 텍스트 프롬프트 모두를 사용하는 경우와 같은 다양한 구성 방법을 지원한다. 특히 시각적 및 텍스트 프롬프트는 그렇게 학습된 적이 없더라도 단순히 concat하여 SEEM 디코더에 공급할 수 있다.
Interactive
Interactive segmentation는 일반적으로 한 번에 완료할 수 없으며 ChatGPT와 같은 대화형 에이전트와 유사하게 개선을 위해 여러 번의 상호작용 라운드가 필요하다. SEEM에서는 메모리 프롬프트 $P_m$이라는 새로운 유형의 프롬프트를 제안하고 이를 사용하여 이전 iteration에서 현재 iteration으로 마스크에 대한 지식을 전달한다. 네트워크를 사용하여 mask를 인코딩하는 이전 연구들과 달리 추가 모듈을 도입하지 않고 몇 가지 메모리 프롬프트만 도입한다. 이러한 메모리 프롬프트는 mask-guided cross-attention layer을 사용하여 이전 정보들을 인코딩하는 역할을 한다.
\[\begin{equation} P_m^l = \textrm{MaskedCrossAtt} (P_m^{l-1}; M_p \vert Z) \end{equation}\]여기서 $M_p$는 이전 마스크이고 $Z$는 이미지 feature map이다. 따라서 Cross-Attention은 이전 마스크에 지정된 영역 내에서만 적용된다. 업데이트된 메모리 프롬프트 $P_m^l$은 self-attention을 통해 다른 프롬프트와 상호 작용하여 현재 라운드를 위해 이전 정보들을 전달한다.
Semantic-aware
SAM과 같은 이전의 클래스에 구애받지 않는 interactive segmentation task와 달리 본 논문의 모델은 zero-shot 방식으로 모든 종류의 프롬프트 조합에서 마스크에 semantic 레이블을 제공한다. 시각적 프롬프트 feature는 joint visual-semantic space에서 텍스트 feature과 정렬되기 때문이다. Semantic 레이블은 $O_h^c$(시각적 쿼리의 출력)와 vocabulary text embedding에 의해 직접 계산된다. Interactive segmentation을 위해 semantic 레이블을 학습하지 않았지만 계산된 로짓은 잘 정렬되어 joint visual-semantic space의 이점을 얻는다.
Experiments
- 데이터셋
- Panoptic segmentation: COCO2017
- Referring segmentation: Ref-COCO, Ref-COCOg, RefCOCO+
- Interactive segmentation: COCO2017
- Implementation Details
- 모델 프레임워크는 디코더 부분을 제외하고 X-Decoder를 따름
- 디코더 부분은 vision backbone, language backbone, encoder, seem-decoder로 구성
- vision backbone: FocalT, DaViT-d3 (B)
- language encoder: UniCL, Florence text encoder
- Evaluation Metrics:
- Panoptic segmentation: PQ (Panoptic Quality)
- Instance segmentation: AP (Average Precision)
- Semantic segmentation: mIoU (mean Intersection over Union)
1. Quantitative Results
다음은 동일한 가중치로 다양한 범위의 segmentation task을 수행한 결과이다.
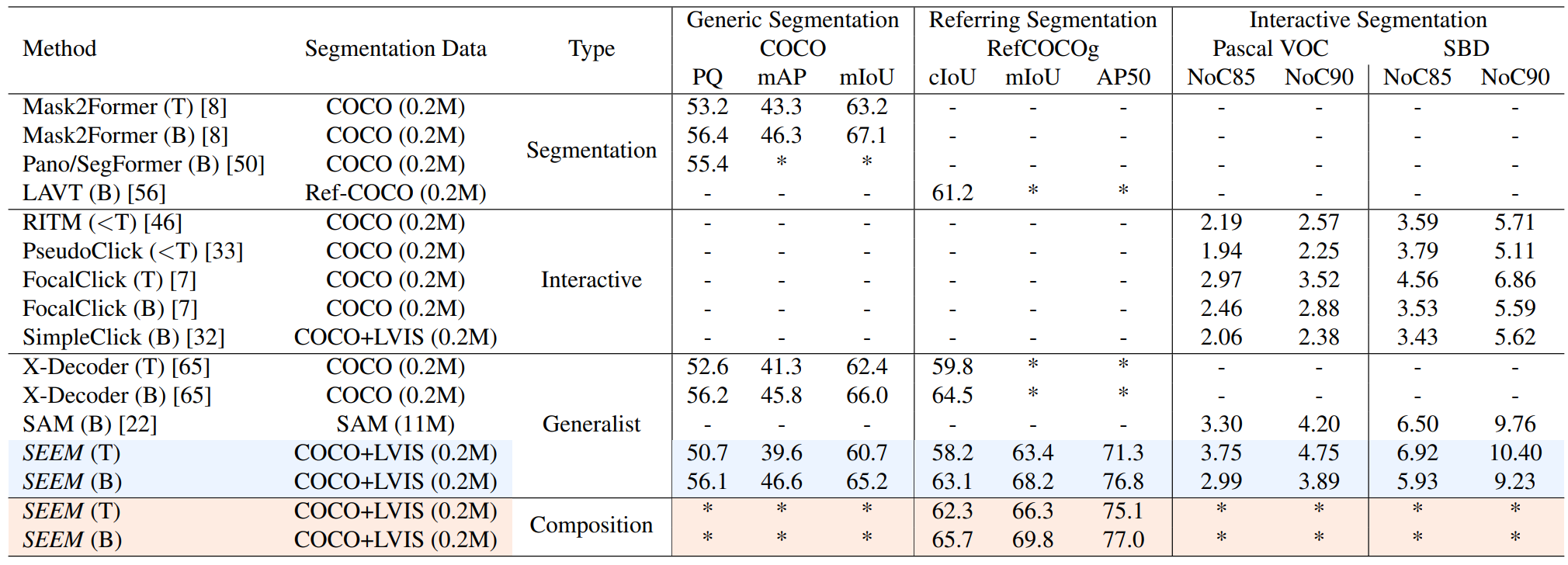
다음은 텍스트 프롬프트와 비주얼 프롬프트로 referring segmentation을 한 결과이다. $P$는 프롬프트, $Q$는 쿼리를 뜻한다.
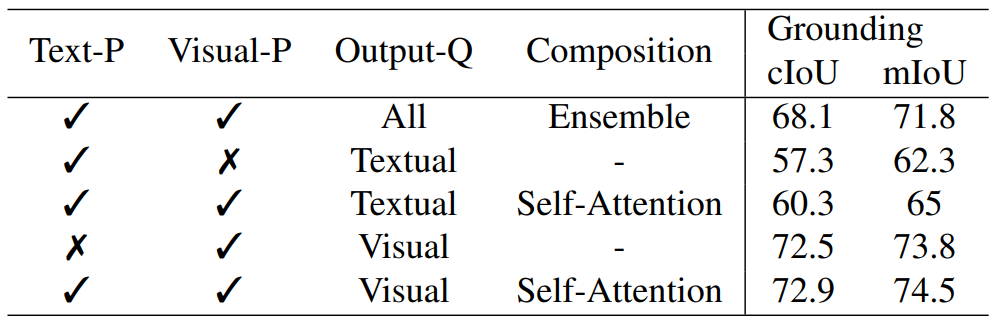
2. Ablation Study
다음은 interactive segment 전략에 대한 ablation study 결과이다.

- “Iter”: segmentation을 여러 라운드에 대하여 반복
- “Negative”: interactive segmentation 중에 negative point를 추가
3. Qualitative Results
Visual prompt interactive segmentation
다음은 사용자의 임의의 형태의 클릭이나 낙서로 segmentation을 수행한 예시이다.

SAM에서는 불가능한 분할된 마스크에 대한 semantic 레이블을 동시에 제공한다.
Text referring segmentation
다음은 text referring segmentation을 수행한 예시이다. 참조된 텍스트가 마스크에 표시된다.

SEEM은 만화, 영화, 게임 영역에서 다양한 유형의 입력 이미지에 적응한다.
Visual referring segmentation
다음은 visual referring segmentation을 수행한 예시이다.
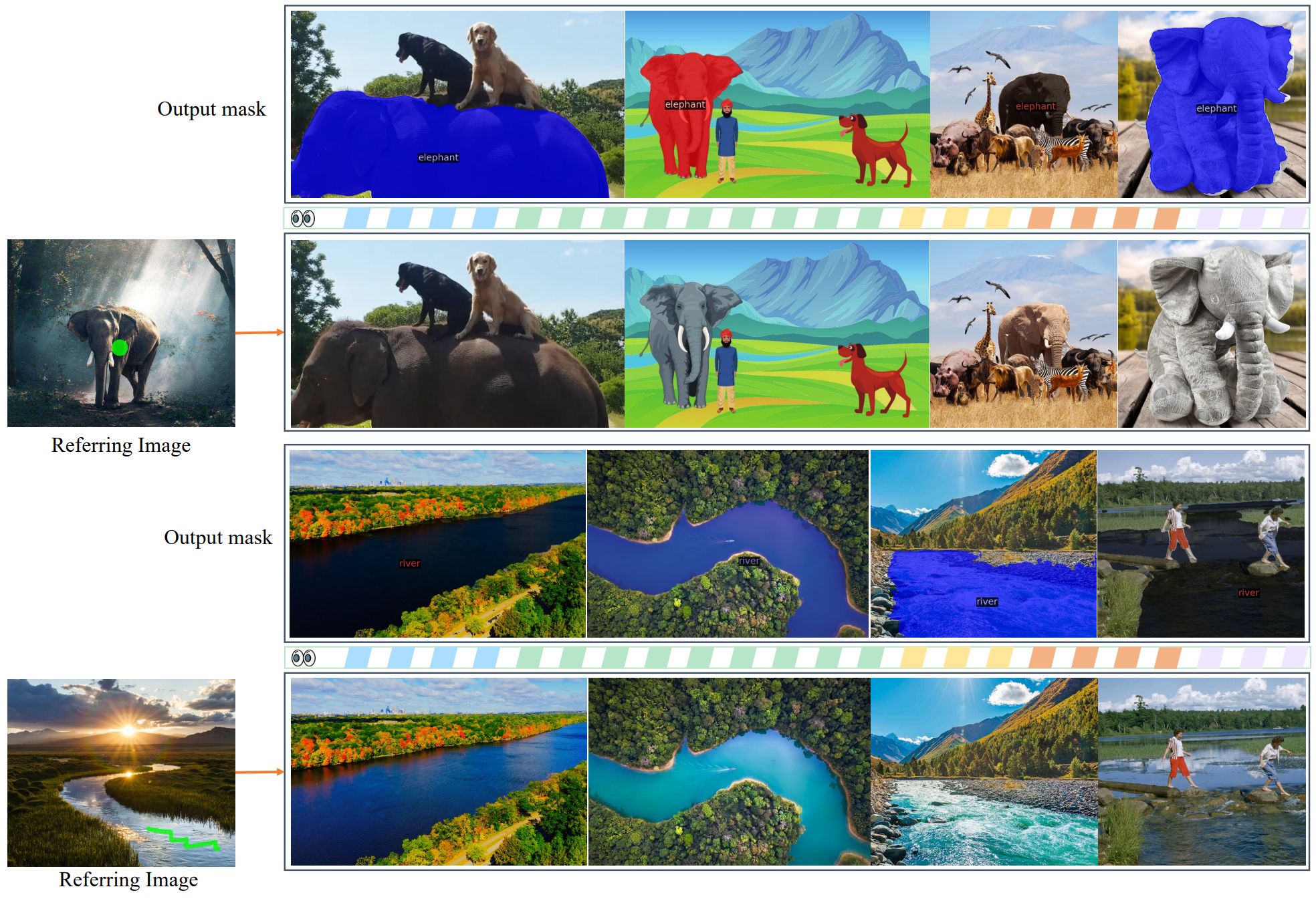
간단한 공간적 힌트가 있는 참조 이미지가 주어지면 SEEM은 다른 타겟 이미지에서 의미적으로 유사한 콘텐츠를 분할할 수 있다.
다음은 첫번째 프레임과 하나의 스트로크를 사용하여 zero-shot으로 동영상 객체 segmentation을 수행한 결과이다.

Zero-shot 방식의 동영상 객체 segmentation에 대한 referring segmentation 능력을 보여준다.
Limitations
- SEEM은 작은 규모의 segmentation 데이터(대부분 COCO)에서 학습된다.
- SEEM은 주로 객체 수준 마스크 주석으로 학습되었기 때문에 부분 기반 segmentation을 지원하지 않는다.