[논문리뷰] Self-Adapting Language Models
arXiv 2025. [Paper] [Page] [Github]
Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, Pulkit Agrawal
MIT CSAIL
12 Jun 2025
Introduction
방대한 텍스트 코퍼스를 기반으로 사전 학습된 강력한 LLM을 특정 task에 적용하거나, 새로운 정보를 통합하거나, 새로운 추론 기술을 습득하는 것은 task별 데이터의 제한적인 가용성으로 인해 여전히 어려운 과제이다. 본 논문에서는 LLM이 자체 학습 데이터와 학습 절차를 변환하거나 생성하여 스스로 적응할 수 있을지에 대하여 탐구하였다.
학습 과정의 일부로서 데이터를 재구성 또는 재작성하는 것은 LLM이 일반적으로 학습되는 방식과 대조된다. 새로운 task가 주어지면, 현재의 LLM은 fine-tuning 또는 in-context learning을 통해 task 데이터를 있는 그대로 활용하고 학습한다. 그러나 이러한 데이터는 학습에 최적의 형식 또는 최적의 양이 아닐 수 있으며, 현재의 방식으로는 모델이 학습 데이터를 가장 효과적으로 변환하고 학습하는 방법에 대한 맞춤형 전략을 개발할 수 없다.
본 논문은 언어 모델의 확장 가능하고 효율적인 적응을 위하여, LLM이 자체 학습 데이터를 생성하고 이러한 데이터를 활용하기 위한 fine-tuning 지침을 제공할 수 있도록 하는 것을 제안였다. 특히, LLM이 self-edits(SE)를 생성하도록 학습시키는 강화 학습(RL) 알고리즘을 도입하였다. SE는 데이터와 모델의 가중치를 업데이트하기 위한 최적화 hyperparameter를 지정하는 자연어 instruction이다. 이러한 모델을 Self-Adapting LLM (SEAL)이라고 한다.
저자들은 SEAL을 두 가지 응용 사례에서 평가하였다. 먼저 새로운 사실적 지식을 LLM에 통합하는 task를 고려하였다. 지문 텍스트로 직접 fine-tuning하는 대신, SEAL 모델에서 생성된 합성 데이터로 fine-tuning한다. 자가 생성 합성 데이터로 fine-tuning한 결과, in-context 지문이 없는 SQuAD에 대한 질의 응답 성능이 33.5%에서 47.0%로 향상되었다. 특히, SEAL에서 자가 생성한 데이터는 GPT-4.1에서 생성된 합성 데이터보다 성능이 우수하였다.
저자들은 ARC-AGI 벤치마크의 단순화된 부분집합에서 SEAL을 few-shot learning 방식으로 추가로 평가하였다. 이 모델은 합성 데이터 augmentation과 최적화 hyperparameter를 자율적으로 선택하는 도구들을 활용한다. SEAL을 사용하여 이러한 도구를 자동으로 선택하고 구성하면 in-context learning과 RL을 사용하지 않는 self-editing 방식보다 성능이 향상되어 도구를 효과적으로 사용할 수 있음을 보여주었다. 이러한 결과는 SEAL이 언어 모델의 자가 적응을 지원하는 다재다능한 프레임워크임을 보여준다.
Methods
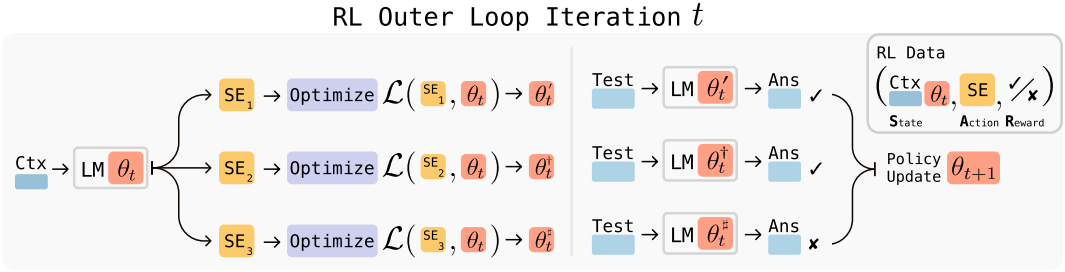
본 논문에서는 언어 모델이 새로운 데이터에 대응하여 자체 합성 데이터 및 최적화 hyperparameter, 즉 self-edits(SE)를 생성하여 스스로를 개선할 수 있도록 하는 프레임워크인 Self-Adapting LLM (SEAL)을 제안하였다. 모델은 모델의 컨텍스트에서 제공된 데이터를 사용하여 토큰 생성을 통해 이러한 SE를 직접 생성하도록 학습된다. Self-edits 생성은 RL을 통해 학습되며, 모델은 SE을 생성할 때마다 reward를 받는다. SE는 적용 시 타겟 task에서 모델의 성능을 향상시킨다. 따라서 SEAL은 두 개의 중첩 루프를 갖는 알고리즘으로 해석될 수 있다. RL 루프는 SE 생성을 최적화하고, 업데이트 루프는 생성된 SE를 사용하여 gradient descent를 통해 모델을 업데이트한다.
1. General Framework
$\theta$를 언어 모델 \(\textrm{LM}_\theta\)의 파라미터라 하자. SEAL은 개별 task 인스턴스 $(C, \tau)$에서 동작한다. 여기서 $C$는 task와 관련된 정보를 포함하는 컨텍스트이고, $\tau$는 모델의 적응을 평가하는 데 사용되는 후속 평가이다. 예를 들어, 지식 통합에서 $C$는 모델의 내부 지식에 통합될 문장들이고, $\tau$는 해당 문장들에 대한 질문과 관련 답변의 집합이다. Few-shot learning에서 $C$는 새로운 task에 대한 few-shot 데모를 포함하고, $\tau$는 질의 입력과 실제 출력이다. $C$가 주어지면, 모델은 도메인에 따라 형태가 다른 self-edit $\textrm{SE}$를 생성하고 supervised fine-tuning을 통해 파라미터를 업데이트한다.
\[\begin{equation} \theta^\prime \leftarrow \textrm{SFT} (\theta, \textrm{SE}) \end{equation}\]RL을 사용하여 SE 생성 프로세스를 최적화한다. 모델은 SE를 생성하고 (action), $\tau$에 대한 \(\textrm{LM}_{\theta^\prime}\)의 성능에 따라 reward $r$을 받고 reward 기대값을 최대화하도록 policy를 업데이트한다.
\[\begin{equation} \mathcal{L}_\textrm{RL} (\theta_t) := - \mathbb{E}_{(C, \tau) \sim \mathcal{D}} \left[ \mathbb{E}_{\textrm{SE} \sim \textrm{LM}_{\theta_t}} [r(\textrm{SE}, \tau, \theta_t)] \right] \end{equation}\]표준 RL과 달리, 이 설정에서는 주어진 action에 할당되는 reward가 action이 수행될 당시의 모델 파라미터 $\theta$에 따라 달라진다 ($\theta$가 $\theta^\prime$으로 업데이트된 후 평가되기 때문). 결과적으로, RL state는 policy 파라미터를 포함해야 하며 $(C, \theta)$로 주어지지만, policy의 observation은 C로 제한된다 ($\theta$를 컨텍스트에 직접 배치하는 것은 불가능). 이는 이전 버전의 모델 \(\theta_\textrm{old}\)를 사용하여 수집된 (state, action, reward)가 현재 모델 \(\theta_\textrm{current}\)에 대해 오래되고 정렬이 잘못될 수 있음을 의미한다. 이러한 이유로, 본 논문에서는 SE를 현재 모델에서 샘플링하고, reward를 현재 모델을 사용하여 계산하는 on-policy 방식을 채택하였다.
저자들은 GRPO, PPO와 같은 다양한 on-policy 기법을 실험해 보았지만, 학습이 불안정하다는 것을 발견했다. 따라서 더 간단한 접근법인 \(\textrm{ReST}^\textrm{EM}\) (rejection sampling + SFT)을 채택했다.
\(\textrm{ReST}^\textrm{EM}\)은 expectation-maximization (EM) 절차로 볼 수 있다. E-step은 현재 모델 policy의 후보 출력값을 샘플링하고, M-step은 supervised fine-tuning을 통해 긍정적인 reward를 받은 샘플만 강화한다. 이 접근법은 다음과 같은 binary reward 하에서 \(\mathcal{L}_\textrm{RL} (\theta_t)\)의 근사값을 최적화한다.
\[\begin{equation} r(\textrm{SE}, \tau, \theta_t) = \begin{cases} 1 & \textrm{if on } \tau, \textrm{adaptation using SE improves } \textrm{LM}_{\theta_t} \textrm{’s performance} \\ 0 & \textrm{otherwise} \end{cases} \end{equation}\]더 정확하게 말하면, \(\mathcal{L}_\textrm{RL} (\theta_t)\)을 최적화할 때 gradient \(\nabla_{\theta_t} \mathcal{L}_\textrm{RL}\)을 계산해야 한다. 그러나, reward 항 \(r(\textrm{SE}, \tau, \theta_t)\)는 \(\theta_t\)에 의존하지만 미분 가능하지 않다. 이 문제를 해결하기 위해 reward를 \(\theta_t\)에 대해 고정된 것으로 간주한다. $N$개의 컨텍스트와 각 컨텍스트당 $M$개의 샘플링된 SE로 구성된 mini-batch에 대한 몬테카를로 추정량은 다음과 같다.
\[\begin{aligned} \nabla_{\theta_t} \mathcal{L}_\textrm{RL} &\approx -\frac{1}{NM} \sum_{i=1}^N \sum_{j=1}^M r_{ij} \nabla_{\theta_t} \log p_{\theta_t} (\textrm{SE}_{ij} \, \vert \, C_i) \\ &= -\frac{1}{NM} \sum_{i=1}^N \sum_{j=1}^M r_{ij} \sum_{s=1}^T \nabla_{\theta_t} \log p_{\theta_t} (y_s^{(i,j)} \, \vert \, y_{<s}^{(i,j)}, C_i) \end{aligned}\](\(p_{\theta_t}\)는 모델의 autoregressive 분포, \(y_s^{(i,j)}\)는 \(\textrm{SE}_{ij}\)의 $s$번째 토큰이며 컨텍스트 $C_i$에 대한 $j$번째 샘플)
$r = 0$인 시퀀스는 위 식에서 무시할 수 있으므로, 양호한 SE에 대한 SFT를 적용한 \(\textrm{ReST}^\textrm{EM}\)이 binary reward 하에서 \(\mathcal{L}_\textrm{RL} (\theta_t)\)을 실제로 최적화한다. SEAL 학습 루프는 Algorithm 1에 요약되어 있다.

본 논문에서는 SE를 생성하고 이를 통해 학습하는 하나의 모델을 사용하지만, 이러한 역할을 분리하는 것도 가능하다. 이러한 “teacher-student” 구조에서는 별도의 teacher 모델이 제안하는 수정을 사용하여 student 모델을 업데이트한다. 그런 다음 teacher는 RL을 통해 student의 향상을 극대화하는 수정을 생성하도록 학습된다.
2. Domain Instantiations
저자들은 SEAL 프레임워크를 knowledge incorporation과 few-shot learning이라는 두 가지 서로 다른 도메인에서 구현하였다. 이 도메인들은 모델 적응의 두 가지 상호 보완적인 형태를 강조하기 위해 선택되었다.
- 새로운 정보를 모델의 가중치에 통합하여 컨텍스트에 의존하지 않고도 기억할 수 있도록 하는 능력
- 적은 수의 사례만 보고도 새로운 task로 일반화하는 능력
Knowledge Incorporation

Knowledge incorporation의 목표는 지문(passage)에 제공된 정보를 모델의 가중치에 효율적으로 통합하는 것이다. 최근 유망한 접근법은 언어 모델을 사용하여 구절에서 파생된 내용을 생성한 다음 원래 지문과 생성된 내용 모두에 대한 fine-tuning을 한다. 저자들은 이 접근법을 채택하여 모델을 “List several implications derived from the content.”로 프롬프팅하여 주어진 컨텍스트 $C$를 implication의 집합 \(\textrm{SE} = \{s_1, \ldots, s_n\}\)으로 변환하였다. 출력에는 추론, 논리적 결과, 원래 지문의 재진술이 포함될 수 있다.
이러한 자체 생성 문장들은 supervised fine-tuning (SFT) 업데이트를 위한 학습 데이터를 형성한다. 각 시퀀스 $s_i$에 대한 표준 causal language-modeling loss를 계산하고 모델 파라미터를 업데이트하여 $\theta^\prime$을 구한다. 업데이트당 데이터 양은 적고 전체 업데이트 횟수는 많기 때문에 효율적이고 가벼운 튜닝을 위해 LoRA를 사용한다. 마지막으로, 수정된 모델 \(\textrm{LM}_{\theta^\prime}\)을 task $\tau$에 대해 평가한다.
RL 학습 과정에서, 적응된 모델의 $\tau$에 대한 정확도는 외부 RL 최적화를 구동하는 reward $r$을 정의한다. 이를 통해 모델은 fine-tuning을 통해 가장 효과적인 방식으로 지문을 재구성하도록 학습한다.
Few-Shot Learning
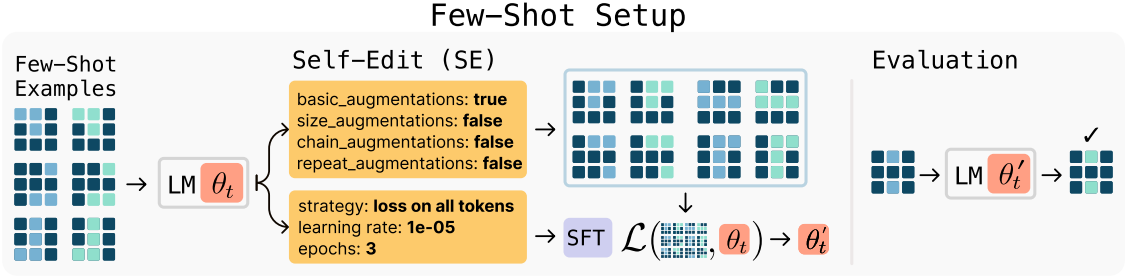
Abstraction and Reasoning Corpus (ARC)는 매우 제한된 예제를 통해 추상 추론과 일반화를 테스트하도록 설계된 벤치마크이다. 각 task에는 몇 가지 입출력 데모와 정확한 출력을 예측해야 하는 테스트 입력이 포함된다.
본 논문에서는 test-time training (TTT) 프로토콜을 채택하였다. 이 프로토콜에서는 few-shot 예제의 augmentation을 통해 gradient 기반 적응을 수행한다. Augmentation 및 최적화 설정을 선택하기 위해 수동으로 조정된 휴리스틱에 의존하는 대신, SEAL이 이러한 결정을 학습하도록 한다. 이 설정은 SEAL이 적응 파이프라인을 자율적으로 구성할 수 있는지, 즉 어떤 augmentation을 적용할지, 어떤 최적화 파라미터를 사용할지 결정할 수 있는지 테스트한다.
이를 구현하기 위해, 미리 정의된 함수인 도구의 집합을 정의하여 데이터를 변환하거나 학습 파라미터를 지정한다.
- 데이터 augmentation: rotation, flip, reflection, transpose, resizing 연산, 반복적인 변환
- 최적화 파라미터: learning rate, 학습 epoch 수, loss가 모든 토큰에 대해 계산되는지 아니면 출력 토큰에만 계산되는지
모델은 task의 few-shot 데모를 통해 프롬프팅되고 SE를 생성한다. 이 경우, SE는 호출할 도구와 구성 방법을 명시한다. 이 SE는 LoRA 기반 fine-tuning을 통해 모델을 튜닝하는 데 적용된다. 튜닝된 모델은 테스트 입력에 대해 평가되며, 그 결과에 따라 SE 생성 policy 학습에 대한 reward가 결정된다.
Results
1. Few-Shot Learning
다음은 Llama-3.2-1B-Instruct 모델을 이용한 few-shot 추상 추론 결과이다.

2. Knowledge Incorporation
다음은 Qwen2.5-7B 모델을 이용한 knowledge incorporation 결과이다. (mean no-context SQuAD accuracy)
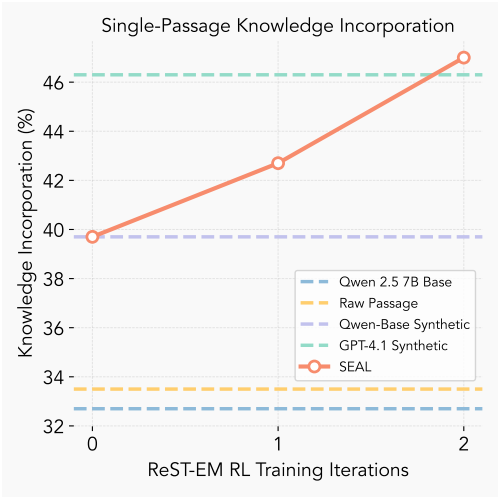
다음은 RL iteration에 대한 knowledge incorporation 정확도를 비교한 그래프이다. 각 iteration은 50개의 컨텍스트를 가진 mini-batch로 구성되며, 각 컨텍스트마다 SE 5개가 샘플링되었다.
다음은 각 RL iteration에서의 knowledge incorporation에 대한 SE의 예시이다.

Limitations
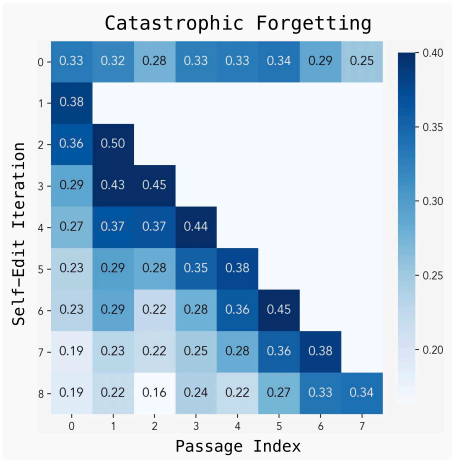
- Catastrophic forgetting: 새로운 지문에 대하여 모델을 업데이트하면 이전 task에 대한 성능이 저하된다.
- 계산 오버헤드: Reward를 계산하기 위해 전체 모델을 fine-tuning하고 평가해야 한다. 각 SE 평가에는 약 30~45초가 소요되어 상당한 오버헤드가 발생한다.
- 컨텍스트에 의존한 평가: 현재는 모든 컨텍스트가 명시적인 하위 task와 쌍을 이룬다고 가정한다. 즉, few-shot 데모는 질문 쌍과 함께 제공되며, 각 지문에는 레퍼런스 QA가 함께 제공된다. 이러한 결합은 reward 계산을 단순화하지만, SEAL의 RL이 레이블이 없는 코퍼스로 확장되는 것을 방지한다.