[논문리뷰] SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
arXiv 2023. [Paper] [Github]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, Robin Rombach
Stability AI
4 Jul 2023

Introduction
본 논문에서는 Stable Diffusion의 대폭 개선된 버전인 SDXL을 공개하였다. Stable Diffusion은 3D 분류, 제어 가능한 이미지 편집, 이미지 개인화, 합성 data augmentation, GUI 프로토타이핑 등의 최근 발전에 대한 기반 역할을 하는 latent text-to-image diffusion model (DM)이다.
본 논문에서는 성능 향상으로 이어지는 다음과 같은 디자인 선택을 제시한다.
- 이전 Stable Diffusion 모델에 비해 3배 더 큰 UNet-backbone
- 어떠한 형태의 추가 supervision도 필요하지 않은 두 가지 간단하지만 효과적인 추가 컨디셔닝 기술
- 샘플의 시각적 품질을 개선하기 위해 SDXL에서 생성된 latent에 noising-denoising process를 적용하는 별도의 diffusion 기반 정제 모델
시각 미디어 제작 분야의 주요 관심사는 블랙박스 모델이 종종 SOTA로 인식되지만 아키텍처의 불투명성으로 인해 성능을 충실하게 평가하고 검증하지 못한다는 것이다. 이러한 투명성의 부족은 재현성을 저해하고 혁신을 억제하며 커뮤니티가 이러한 모델을 기반으로 과학과 예술의 발전을 촉진하는 것을 방해한다. 더욱이 이러한 closed-source 전략은 공정하고 객관적인 방식으로 이러한 모델의 편향과 한계를 평가하는 것을 어렵게 만든다. 이는 책임 있고 윤리적인 배포에 매우 중요하다. 저자들은 SDXL을 통해 블랙박스 이미지 생성 모델과 경쟁력 있는 성능을 구현하는 개방형 모델을 출시하였다.
Improving Stable Diffusion
본 논문은 Stable Diffusion 아키텍처에 대한 개선 사항을 제시한다. 이들은 모듈식이며 개별적으로 또는 함께 사용하여 모든 모델을 확장할 수 있다. 전략들은 LDM에 대한 확장으로 구현되지만 대부분은 픽셀 space의 DM에도 적용할 수 있다.
1. Architecture & Scale
Convolutional UNet 아키텍처는 diffusion 기반 이미지 합성을 위한 지배적인 아키텍처였다. 그러나 기본 DM의 개발과 함께 기본 아키텍처는 self-attention과 개선된 업스케일링 레이어 추가에서 text-to-image 합성을 위한 cross-attention을 넘어 순수한 transformer 기반 아키텍처로 끊임없이 진화했다.
이러한 추세를 따르고 simple diffusion 논문에 따라 transformer 계산의 대부분을 UNet의 하위 레벨 feature로 이동시킨다. 특히 원래의 Stable Diffusion 아키텍처와 달리 UNet 내에서 transformer 블록의 heterogeneous 분포를 사용한다. UNet에서 가장 낮은 레벨 ($8 \times$ 다운샘플링)을 모두 제거한다.

위 표는 Stable Diffusion 1.x 및 2.x와 SDXL의 아키텍처를 비교한 것이다. 텍스트 컨디셔닝에 사용하는 보다 강력한 사전 학습된 텍스트 인코더를 선택한다. 특히 OpenCLIP ViT-bigG를 CLIP ViT-L과 함께 사용하여 채널 축을 따라 두 번째 텍스트 인코더 출력을 concat한다. Cross-attention 레이어를 사용하여 텍스트 입력으로 모델을 컨디셔닝하는 것 외에도 OpenCLIP 모델의 풀링된 텍스트 임베딩으로 추가로 컨디셔닝한다. 이러한 변경으로 인해 UNet에서 26억 파라미터의 모델 크기가 생성된다. 텍스트 인코더는 총 8.17억 개의 파라미터로 이루어져 있다.
2. Micro-Conditioning
Conditioning the Model on Image Size
LDM 패러다임의 악명 높은 단점은 2단계 아키텍처로 인해 모델 학습에 최소 이미지 크기가 필요하다는 사실이다. 이 문제를 해결하기 위하여 두 가지 주요 접근 방식이 있다.
첫번째 방법은 특정 최소 해상도 미만의 모든 학습 이미지를 폐기하거나 또는 너무 작은 업스케일 이미지를 폐기하는 것이다. 그러나 원하는 이미지 해상도에 따라 전자의 방법은 학습 데이터의 상당 부분이 폐기될 수 있으며 이는 성능 저하 및 일반화 손상으로 이어질 수 있다.
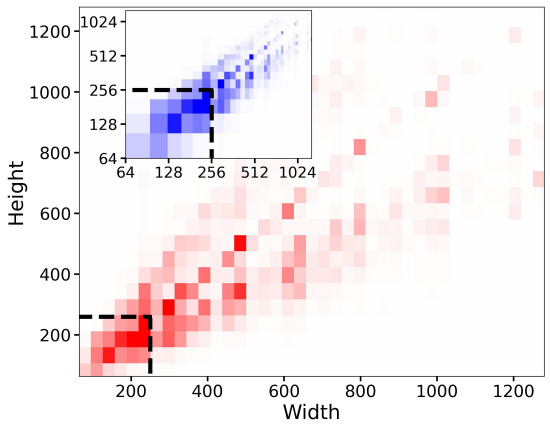
사전 학습 데이터셋의 높이와 너비 분포는 위 그래프와 같다. 사전 학습 해상도 $256^2$픽셀 미만의 모든 샘플을 폐기하면 39%의 상당한 데이터가 폐기된다. 반면에 두 번째 방법은 일반적으로 업스케일링 아티팩트를 도입하는 것으로, 최종 모델 출력으로 아티팩트가 누출될 수 있어 예를 들어 흐릿한 샘플이 생성될 수 있다.
위 두 방법 대신, 본 논문은 학습 중에 쉽게 사용할 수 있는 원본 이미지 해상도에서 UNet 모델을 컨디셔닝할 것을 제안한다. 특히 모델에 대한 추가 컨디셔닝으로 rescaling 전 이미지의 원래 높이와 너비 $c_\textrm{size} = (h_\textrm{original}, w_\textrm{original})$를 제공한다. 각 구성 요소는 Fourier feature encoding을 사용하여 독립적으로 임베딩되며 이러한 인코딩은 timestep 임베딩에 concat되어 모델에 공급하는 단일 벡터가 된다.
inference 시 사용자는 이 크기 컨디셔닝을 통해 이미지의 원하는 겉보기 해상도를 설정할 수 있다. 분명히, 모델은 컨디셔닝 $c_\textrm{size}$를 주어진 프롬프트에 해당하는 출력의 모양을 수정하는 데 활용할 수 있는 해상도에 의존하는 이미지 feature와 연결하는 방법을 배웠다.

위 그림에 표시된 시각화의 경우 512$\times$512 모델에 의해 생성된 샘플을 시각화한다. 크기 컨디셔닝의 효과는 최종 SDXL 모델에 사용하는 이어지는 multi-aspect (ratio) fine-tuning 후에 명확하게 보이지 않기 때문이다.
저자들은 $512^2$의 클래스 조건부 ImageNet에서 3개의 LDM을 학습시키고 평가하여 이 간단하지만 효과적인 컨디셔닝 기술의 효과를 정량적으로 평가하였다.
- CIN-512-only: 높이나 너비가 하나라도 512픽셀보다 작은 모든 학습 예제를 폐기하여 7만 개의 이미지의 학습 데이터셋만 생성
- CIN-nocond: 모든 학습 예제를 사용하지만 크기 컨디셔닝은 사용하지 않는다.
- CIN-size-cond: $c_\textrm{size} = (512, 512)$로 컨디셔닝된 샘플을 생성한다.
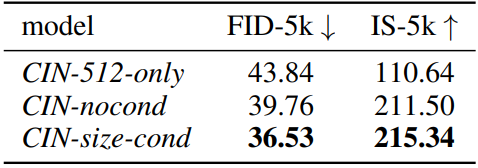
위 표는 결과를 요약하고 CIN-size-cond가 두 메트릭 모두에서 기본 모델을 개선하는지 확인한다. CIN-512-only의 성능 저하는 작은 학습 데이터셋에 대한 overfitting으로 인한 나쁜 일반화 때문이며, CIN-nocond의 샘플 분포에서 흐릿한 샘플 모드의 영향으로 인해 FID 점수가 감소했다. 이러한 고전적인 정량적 점수가 기본 DM의 성능을 평가하는 데 적합하지 않지만, FID와 IS의 backbone이 ImageNet에서 학습되었기 때문에 ImageNet에서 합리적인 메트릭으로 유지된다.
Conditioning the Model on Cropping Parameters

위 그림의 처음 두 행은 이전 SD 모델의 일반적인 실패 모드를 보여준다. 합성된 개체는 SD 1-5와 SD 2-1의 왼쪽 예에서 잘린 고양이 머리와 같이 잘릴 수 있다. 이 동작에 대한 직관적인 설명은 모델 학습 중 random cropping을 사용하는 것이다. PyTorch와 같은 DL 프레임워크에서 batch를 조합하려면 동일한 크기의 텐서가 필요하므로 일반적인 처리 파이프라인은 높이와 너비 중 짧은 것의 크기는 원하는 타겟 크기와 일치하고 더 긴 축을 따라 이미지를 무작위로 자른다. Random cropping은 data augmentation의 자연스러운 형태이지만 생성된 샘플로 유출되어 위에 표시된 악의적인 효과를 일으킬 수 있다.
본 논문은 이 문제를 해결하기 위해 간단하면서도 효과적인 또 다른 컨디셔닝 방법을 제안한다. 데이터를 로드하는 동안 crop 좌표 $c_\textrm{top}$과 $c_\textrm{left}$를 균일하게 샘플링하고 위에서 설명한 크기 컨디셔닝과 유사하게 Fourier feature embedding을 통해 컨디셔닝 파라미터로 모델에 입력한다. 그런 다음 concat된 임베딩 $c_\textrm{crop}$이 추가 컨디셔닝 파라미터로 사용된다. 이 기술은 LDM에 국한되지 않으며 모든 DM에 사용할 수 있다. Crop 컨디셔닝과 크기 컨디셔닝을 쉽게 결합할 수 있다. 이러한 경우 UNet의 timestep 임베딩에 추가하기 전에 채널 차원을 따라 feature 임베딩을 concat한다. Algorithm 1은 이러한 조합이 적용되는 경우 학습 중에 $c_\textrm{crop}$과 $c_\textrm{size}$를 샘플링하는 방법을 보여준다.

대규모 데이터셋이 평균적으로 개체 중심이라는 점을 감안할 때 inference 중에 $(c_\textrm{top}, c_\textrm{left}) = (0, 0)$을 설정하여 학습된 모델에서 개체 중심 샘플을 얻는다.

위 그림에서 볼 수 있듯이 $(c_\textrm{top}, c_\textrm{left})$을 튜닝하여 inference 중에 잘리는 양을 성공적으로 시뮬레이션할 수 있다. 이것은 conditioning-augmentation의 한 형태이며 autoregressive model과 함께 다양한 형태로 사용되어 왔으며 최근에는 diffusion model과 함께 사용되었다.
본 논문의 방법은 여전히 cropping으로 인한 data augmentation의 이점을 얻는 동시에 생성 프로세스로 유출되지 않도록 한다. 실제로 이미지 합성 프로세스를 더 잘 제어하기 위해 이를 유리하게 사용한다. 또한 구현하기 쉽고 추가 데이터 전처리 없이 학습 중에 온라인 방식으로 적용할 수 있다.
3. Multi-Aspect Training
실제 데이터셋에는 다양한 크기와 종횡비의 이미지가 포함된다. Text-to-image 모델의 일반적인 출력 해상도는 512$\times$512 또는 1024$\times$1024의 정사각형 이미지이다. 저자들은 이것이 화면의 광범위한 분포와 사용을 고려할 때 (ex. 16:9) 다소 부자연스러운 선택이라고 주장한다.
이것에 동기를 부여하여 여러 종횡비를 동시에 처리하도록 모델을 fine-tuning한다. 일반적인 관행에 따라 데이터를 다양한 종횡비의 버킷으로 분할한다. 여기서 픽셀 수는 가능한 한 $1024^2$픽셀에 가깝게 유지하고 그에 따라 64의 배수로 높이와 너비를 변경한다. 최적화 중에 학습 batch는 동일한 버킷의 이미지로 구성되며 각 학습 단계에 대해 버킷 크기를 번갈아 가며 사용한다. 또한 모델은 위에서 설명한 크기 컨디셔닝과 crop 컨디셔닝과 유사하게 Fourier space에 임베딩된 정수 $c_\textrm{ar} = (h_\textrm{tgt}, w_\textrm{tgt})$의 튜플로 표현되는 컨디셔닝으로 버킷 크기 (또는 타겟 크기)를 받는다.
실제로 고정된 종횡비 및 해상도에서 모델을 사전 학습한 후 fine-tuning 단계로 multi-aspect 학습을 적용하고 채널 축을 따라 concatenation을 통해 컨디셔닝 기술과 결합한다. Crop 컨디셔닝과 multi-aspect 학습은 보완 작업이며 crop 컨디셔닝은 버킷 경계 (일반적으로 64픽셀) 내에서만 작동한다. 그러나 구현의 용이성을 위해 multi-aspect 모델에 대해 이 제어 파라미터를 유지하도록 선택한다.
4. Improved Autoencoder
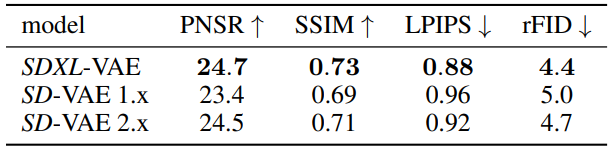
Stable Diffusion은 오토인코더의 사전 학습된 latent space에서 작동하는 LDM이다. Semantic 구성의 대부분은 LDM에 의해 수행되지만 오토인코더를 개선하여 생성된 이미지에서 로컬한 고주파 디테일을 개선할 수 있다. 이를 위해 더 큰 batch size에서 원본 Stable Diffusion에 사용된 것과 동일한 오토인코더 아키텍처를 학습시키고 exponential moving average로 가중치를 추가로 추적한다. 위 표에서 볼 수 있듯이 결과 오토인코더는 평가된 모든 재구성 메트릭에서 원래 모델보다 성능이 뛰어나다.
5. Putting Everything Together
저자들은 최종 모델인 SDXL을 다단계 절차로 학습하였다. SDXL은 위의 오토인코더와 1000 step의 discrete-time diffusion schedule을 사용한다. 먼저 크기 컨디셔닝과 자르기 컨디셔닝을 사용하여 256$\times$256 픽셀의 해상도와 2048의 배치 크기에서 60만 개의 최적화 step에 대해 내부 데이터셋에서 기본 모델을 사전 학습한다. 또 다른 20만 개의 최적화 step을 위해 512$\times$512 이미지에 대한 학습을 계속하고 마지막으로 0.05의 offset-noise level과 함께 multi-aspect 학습을 활용하여 1024$\times$1024 까지의 다양한 종횡비에서 모델을 학습한다.
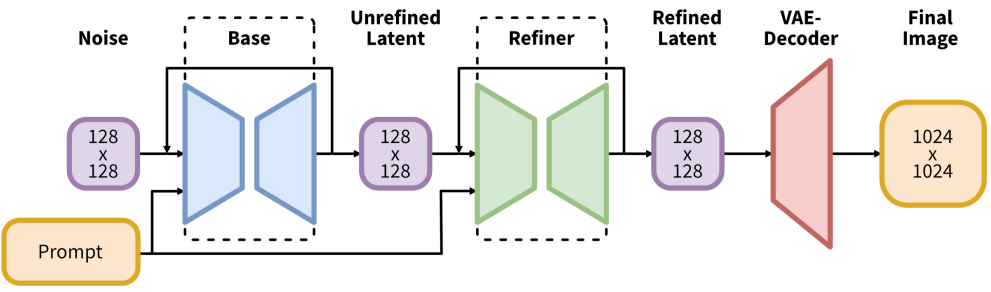
Refinement Stage
경험적으로 결과 모델이 때때로 낮은 로컬 품질의 샘플을 생성한다. 샘플 품질을 개선하기 위해 동일한 latent space에서 고품질, 고해상도 데이터에 특화된 별도의 LDM을 학습시키고 기본 모델의 샘플에서 SDEdit에 의해 도입된 noising-denoising process를 적용한다. eDiff-I를 따르고 처음 200개의 noise 스케일에서 이 개선 모델을 전문화한다. Inference하는 동안 base SDXL에서 latent를 렌더링하고 동일한 텍스트 입력을 사용하여 정제 모델로 latent space에서 직접 diffuse하고 denoise한다. 이 단계는 선택 사항이지만 자세한 배경 및 사람 얼굴에 대한 샘플 품질을 향상시킨다.

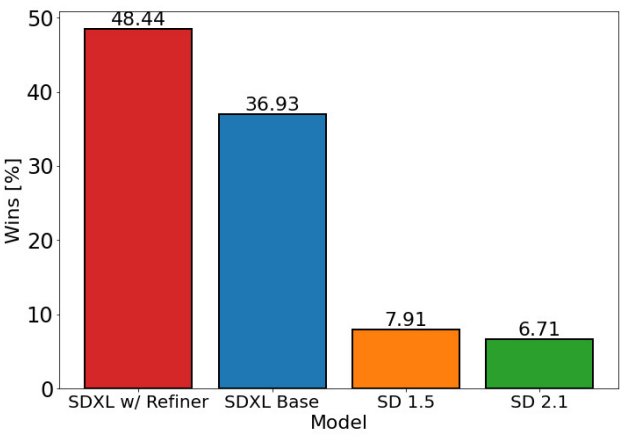
저자들은 SDXL의 성능을 평가하기 위해 정제 단계 유무에 관계없이 user study를 수행하고 다음 4가지 모델 중에서 가장 좋아하는 생성 결과를 선택할 수 있도록 하였다.
- SDXL
- SDXL (정제 모델 포함)
- Stable Diffusion 1.5
- Stable Diffusion 2.1
User study의 결과는 다음과 같다.
Limitations

- 모델은 인간의 손과 같은 복잡한 구조를 합성할 때 문제에 직면할 수 있다. 다양한 범위의 데이터에 대해 학습을 받았지만 인체의 복잡성으로 인해 지속적으로 정확한 표현을 달성하는 데 어려움이 있다. 이러한 현상이 발생하는 이유는 손과 유사한 물체가 사진에서 매우 높은 분산으로 나타나며 이 경우 모델이 실제 3D 모양 및 물리적 한계에 대한 지식을 추출하기 어렵기 때문일 수 있다.
- 이 모델은 생성된 이미지에서 놀라운 수준의 사실감을 달성하지만 완벽한 포토리얼리즘을 달성하지는 못한다. 미묘한 조명 효과 또는 미세한 질감 변화와 같은 특정 뉘앙스가 생성된 이미지에 여전히 없거나 덜 충실하게 표현될 수 있다.
- 모델의 학습 프로세스는 대규모 데이터셋에 크게 의존하므로 실수로 사회적 및 인종적 편견을 도입할 수 있다.
- 길고 읽기 쉬운 텍스트를 렌더링할 때 여전히 어려움에 직면한다. 때때로 생성된 텍스트는 임의의 문자를 포함하거나 불일치를 나타낼 수 있다.
- 샘플에 여러 개체 또는 주제가 포함된 특정 경우 모델에서 “concept bleeding”이라는 현상이 나타날 수 있다. 이 문제는 의도하지 않은 병합 또는 고유한 시각적 요소의 겹침으로 나타난다.
아래 그림은 “concept bleeding”의 예시이다.

‘A portrait photo of a kangaroo wearing an orange hoodie and blue sunglasses standing on the grass in front of the Sydney Opera House holding a sign on the chest that says “SDXL”!.’
그림에서는 파란색 선글라스 대신 주황색 선글라스가 관찰되는데 이는 주황색 스웨터에서 개념이 번진 것이다. 이것의 근본 원인은 사용된 사전 학습된 텍스트 인코더에 있을 수 있다. 텍스트 인코더는 모든 정보를 단일 토큰으로 압축하도록 학습되어 올바른 속성과 객체만 바인딩하는 데 실패할 수 있다. 또한 contrastive loss도 이에 기여할 수 있다. 동일한 batch 내에서 바인딩이 다른 부정적인 예가 필요하기 때문이다.
Comparison to the State of the Art

Comparison to Midjourney v5.1
Overall Votes
다음은 SDXL v0.9와 Midjourney v5.1에 대한 17,153명의 선호도 조사 결과이다.

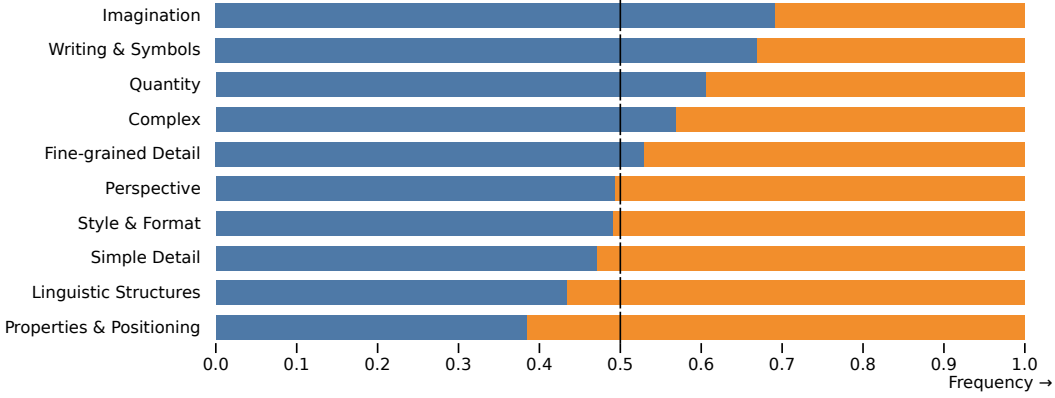
Category & challenge comparisons on PartiPrompts (P2)
다음은 SDXL (정제 모델 미포함)과 Midjourney v5.1에 대한 선호도 조사 결과이다.
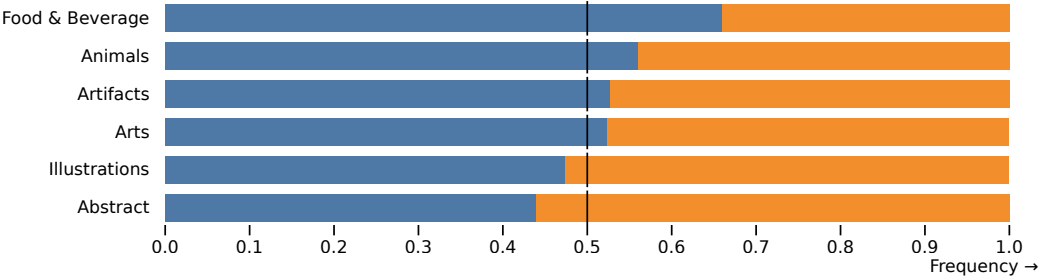
다음은 SDXL (정제 모델 포함)과 Midjourney v5.1에 대한 선호도 조사 결과이다.