[논문리뷰] SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
ECCV 2024. [Paper] [Page]
Armen Avetisyan, Christopher Xie, Henry Howard-Jenkins, Tsun-Yi Yang, Samir Aroudj, Suvam Patra, Fuyang Zhang, Duncan Frost, Luke Holland, Campbell Orme, Jakob Engel, Edward Miller, Richard Newcombe, Vasileios Balntas
Meta Reality Labs | Simon Fraser University
19 Mar 2024
Introduction
수년에 걸쳐 연구자들은 복잡한 실제 장면을 충실도 있게 표현하는 것을 목표로 메쉬, 복셀 그리드, 포인트 클라우드, 암시적 표현과 같은 다양한 장면 표현들을 탐색해 왔다. 각각의 장면 표현들은 장점과 한계점을 가지기 때문에 다양한 task에 적용하기 어렵다. 본 논문에서는 보다 효율적이고 다재다능한 구조화된 언어 커맨드를 기반으로 하는 새로운 장면 표현을 제안하였다.
본 논문의 동기는 LLM과 autoregressive 방법의 최근 발전과 기하학적 구조를 표현하기 위한 시퀀스 생성 탐색에 대한 최근 연구들에서 비롯되었다. 예를 들어, PolyGen은 Transformer를 사용하여 생성된 일련의 vertex와 face로 3D 메쉬를 설명하였다. CAD-as-Language는 2D CAD 스케치를 표현하기 위한 CAD primitives 생성의 효율성을 보여주었다. 본 논문의 주요 목표는 전문적인 구조화된 언어 커맨드의 텍스트 기반 시퀀스로 전체 장면의 정확한 표현을 직접 추론하는 것이다.
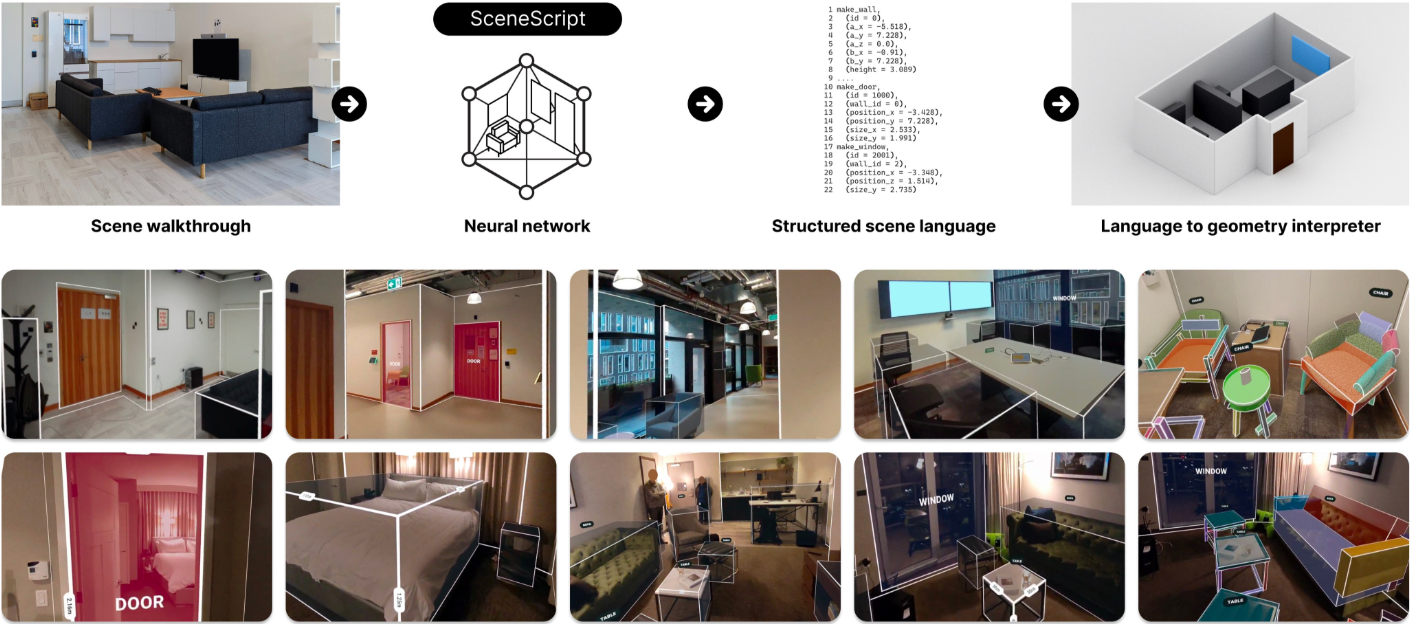
SceneScript라고 하는 본 논문의 방법은 순수 텍스트 형식으로 직접 디자인한 구조화된 언어 커맨드를 autoregressive하게 예측한다. 이 언어는 몇 가지 뚜렷한 이점을 제공한다.
- 순수 텍스트이므로 크기가 작고 대규모 장면의 메모리 요구 사항을 단 몇 바이트로 줄인다.
- 커맨드가 선명하고 잘 정의된 형상을 생성하도록 설계되었으므로 명확하고 완전하다 (SVG와 유사)
make_door(*door_parameters)와 같은 커맨드를 사용하여 설계상 해석 가능하고 편집 가능하며 의미가 풍부하다.- 새로운 구조화된 커맨드를 언어에 추가하기만 하면 새로운 개체를 원활하게 통합할 수 있다.
- 장면 표현이 유사한 일련의 언어 토큰이라는 사실은 수많은 잠재적인 응용 가능성을 열어준다.
저자들은 주로 장면 표현으로서 SceneScript 언어의 효율성을 테스트하기 위해 아키텍처 레이아웃 추정 및 object detection 문제에 중점을 두었다. 벽, 문, 창문과 같은 건축 개체는 고도로 구조화된 개체이므로 이상적이다. 그러나 언어 모델의 한 가지 주목할만한 단점은 학습을 위해 방대한 양의 데이터가 필요하다는 것이다.
장면 탐색 및 구조화된 언어 커맨드에 대한 기존 데이터셋이 없기 때문에 저자들은 10만 개의 고유한 내부 장면에 대한 합성 데이터셋인 Aria Synthetic Environments (ASE)를 공개적으로 출시했다. 각 장면에 대해 Project Aria의 전체 센서 데이터셋을 사용하여 궤적을 시뮬레이션하였다. 또한 깊이 및 instance segmentation를 포함한 다양한 ground-truth 소스를 공개하였다. 또한 렌더링된 각 시퀀스에 대해 제안된 SceneScript 언어에 아키텍처 레이아웃 ground-truth 정보가 제공된다.
저자들은 시각적 입력과 네트워크 아키텍처를 모두 고정한 상태로 유지하면서 SceneScript 언어에 대한 간단한 확장을 통해 SceneScript 방법을 새로운 task로 쉽게 확장할 수 있음을 보여주었다. 이를 통해 아키텍처 레이아웃과 3D bounding box를 공동으로 추론하는 방법이 탄생하였다.
Structured Language Commands
1. Commands and Parameters
가장 일반적인 레이아웃 요소를 캡처하는 parameterization을 위해 make_wall, make_door, make_window의 세 가지 커맨드를 사용한다. 각 커맨드에는 잘 정의된 형상을 생성하는 파라미터들이 함께 제공된다. 이 parameterization은 임의적이며 SceneScript 시스템을 제시하는 맥락에서만 수행된다. Parameterization 방식은 무한히 많지만 본 논문에서는 사용 편의성과 연구 반복 속도를 우선시하는 방식을 선택하였다.
이러한 세 가지 주요 레이아웃 엔터티를 나타내는 것 외에도 개체를 bounding box로 공동으로 추론하는 것을 목표로 한다. 따라서 네 번째 커맨드인 make_bbox를 도입한다. make_bbox의 간단한 parameterization은 -z 방향을 가리키는 3D bounding box를 나타낸다. 커맨드들과 파라미터에 대한 요약은 아래 표에 나와 있다.

실내 환경에서 구조와 객체를 캡처하기 위한 네 가지 커맨드만 설명했지만 중요한 점은 이 텍스트 기반 parameterization은 상태나 기타 기능적 측면을 포함하도록 쉽게 확장될 수 있다. 예를 들어 make_door 커맨드에 open_degree와 같은 파라미터를 포함하여 문 상태를 나타낼 수도 있다.
2. Scene Definition
하나의 장면은 제안된 구조화된 언어 커맨드의 시퀀스로 설명할 수 있다. 시퀀스에는 특별한 순서가 필요하지 않으며 임의의 길이를 갖는다. 이 정의에서 간단한 해석기를 통해 커맨드를 파싱하여 3D 장면을 쉽게 얻을 수 있다.
3. Training Dataset

저자들은 구조화된 언어 커맨드를 기반으로 실용적인 실내 장면 재구성을 위해 Aria Synthetic Environments (ASE)라는 새로운 데이터셋을 공개적으로 출시했다. 이는 ground-truth 커맨드 시퀀스와 연결된 장면의 다수의 학습 쌍으로 구성된다.
Transformer 학습에는 막대한 양의 데이터가 필요하기 때문에 10만 개의 합성 장면을 생성했는데 이는 실제 데이터로는 불가능하다. 각 합성 장면에는 평면도 모델, 완전한 3D 장면, 시뮬레이션된 에이전트 궤적, 이 궤적의 사실적인 렌더링이 함께 제공된다.
Network Architecture

본 논문의 아키텍처는 동영상 시퀀스를 사용하고 토큰화된 형식으로 SceneScript 언어를 반환하는 간단한 인코더-디코더 아키텍처이다.
포인트 클라우드 인코더, 이미지 세트 인코더, 결합 인코더의 세 가지 인코더 변형이 있으며, 디코더는 모든 경우에 동일하다.
1. Input Modalities and Encoders
인코더는 장면의 동영상에서 1D 시퀀스 형태로 latent code를 계산한다. 디코더는 이러한 1D 시퀀스를 입력으로 사용하도록 설계되었다. 이를 통해 통합 프레임워크 내에서 다양한 입력 양식을 통합할 수 있다. 각 장면에 대해 $M$개의 포즈를 아는 카메라의 이미지 \(\{\textbf{I}_1, \ldots, \textbf{I}_M\}\)를 사용할 수 있다고 가정하자 (ex. SLAM 출력).
Point Clouds
포인트 클라우드 $\textbf{P} = {\textbf{p}_1, \ldots, \textbf{p}_N}$는 $N$개의 포인트로 구성되며, SLAM, SfM, RGB-D / Lidar 센서로부터 얻을 수 있다.
저자들은 Aria의 흑백 카메라와 IMU를 사용하는 SLAM 시스템에서 얻은 Project Aria의 Machine Perception Services의 포인트 클라우드를 사용하였다. 포인트 클라우드를 5cm 해상도로 분리한 다음 sparse 3D convolution 라이브러리를 사용하여 풀링된 feature를 생성한다. 인코더 \(\mathcal{E}_\textrm{geo}\)는 일련의 down convolution을 적용하여 최하위 레벨의 포인트 수를 줄인다.
\[\begin{equation} \textbf{F}_\textrm{geo} = \mathcal{E}_\textrm{geo} (\textbf{P}), \quad \textbf{P} \in \mathbb{R}^{N \times 3}, \; \textbf{F}_\textrm{geo} \in \mathbb{R}^{K \times 512} \end{equation}\]여기서 $K \ll N$이다. \(\textbf{F}_\textrm{geo}\)는 필요한 장면 컨텍스트를 포함하는 포인트 클라우드의 압축된 latent 표현이다. 나중에 Transformer 디코더에서 사용하기 위해 \(\textbf{F}_\textrm{geo}\)를 \(\textbf{f}_i\) $(i \in 1, \ldots, K)$가 active site의 좌표 \(\textbf{c}_i\)에 따라 사전순으로 정렬되는 일련의 feature 벡터로 처리한다. 위치 인코딩을 통합하기 위해 \(\textbf{c}_i\)를 \(\textbf{f}_i\)에 concatenate한다.
\[\begin{equation} \textbf{f}_i \leftarrow \textrm{concat} (\textbf{f}_i, \textbf{c}_i) \end{equation}\]Point Clouds with Lifted Features
이미지 feature를 사용하여 포인트 클라우드를 강화할 수 있다. 원래의 시퀀스와 연관된 궤적에서 $M$개의 키프레임 \(\textbf{I}_i\)를 샘플링하고 각각에 대한 이미지 feature \(\textbf{F}_i\)를 계산한다. 그런 다음 각 포인트를 키프레임 카메라들에 투영하고 해당 픽셀 위치에서 feature 벡터를 검색한다.
\[\begin{equation} \textbf{f}_{ip} = F_i (\pi (\textbf{p})), \quad \textbf{p} \in \textbf{P}, \; i \in 1, \ldots, M \end{equation}\]여기서 $\pi$는 카메라에 대한 projection function이다. $\pi(\textbf{p})$가 이미지 경계를 벗어나면 feature가 검색되지 않는다. 한 포인트에 대한 lifted feature들을 평균내어 각 포인트에 대한 하나의 feature 벡터를 생성한다.
\[\begin{equation} \textbf{f}_p = \frac{1}{M} \sum_{i=1}^M \textbf{f}_{ip} \end{equation}\]각 포인트의 lifted feature를 원래 XYZ 위치와 concatenate하여 lifted-feature 포인트 클라우드 \(\textbf{P}^\prime = \{\textbf{p}_1^\prime, \ldots, \textbf{p}_M^\prime\}\)을 형성한다.
\[\begin{equation} \textbf{p}^\prime = \textrm{concat} (\textbf{f}_p, \textbf{p}) \end{equation}\]그런 다음 $\textbf{P}^\prime$는 sparse 3D convolution을 사용하여 컨텍스트 시퀀스로 인코딩되며, 입력 feature 채널만 새 포인트 feature 차원과 일치하도록 조정된다.
End-to-end Encoding of Posed Views
미리 계산된 포인트 클라우드 없이 시퀀스를 보다 직접적으로 인코딩하기 위해 RayTran에서 정의한 형식을 따르는 2D $\leftrightarrow$ 3D 양방향 Transformer 인코더를 채택한다.
장면 형상과 일치하는 dense한 feature voxel grid $\textbf{V}$로 장면의 볼륨 표현을 초기화한다. 그런 다음 포즈를 아는 전체 이미지들에서 $M$개의 키프레임 \(\textbf{I}_i\)를 샘플링한다. 각 키프레임에 대해 CNN에서 이미지 feature \(\textbf{F}_i\)를 계산한다. 양방향 attention layer를 반복적으로 사용하면 시점 및 글로벌 장면 정보의 집계를 통해 Transformer block들에서 이미지와 feature voxel grid를 반복적으로 개선할 수 있다.
이러한 Transformer block의 attention은 이미지 패치와 voxel ray의 교집합으로 제한된다. 즉, 각 이미지 패치는 관찰하는 voxel과 attention 계산을 하고 각 voxel 위치는 이를 관찰하는 모든 패치와 attention 계산을 한다. 결과적인 feature의 voxel grid는 flatten되고 XYZ 위치의 인코딩된 표현과 concatenate되어 디코더로 전달된다.
2. Language Decoder
장면 latent code를 일련의 구조화된 언어 커맨드로 디코딩하기 위해 Transformer 디코더를 활용한다. 토큰 시퀀스는 임베딩 레이어를 통과한 다음 위치 인코딩 레이어를 통과한다. 임베딩된 토큰은 인코딩된 장면 코드와 함께 autoregressive한 생성을 위해 causal attention mask가 사용되는 여러 Transformer 디코더 레이어로 전달된다.
3. Language Tokenization
Tokenization의 목표는 구조화된 언어 커맨드 시퀀스와 Transformer 디코더 아키텍처에서 예측할 수 있는 정수 토큰 시퀀스 간의 전단사 매핑을 구성하는 것이다. 따라서 다음과 같은 스키마를 사용한다.
[START, PART, CMD, PARAM_1, PARAM_2, …, PARAM_N, PART, …, STOP]
예를 들어, make_door 커맨드는 다음과 같이 구성된다.
[START, PART, MAKE_DOOR, POSITION_X, POSITION_Y, POSITION_Z, WALL0_IDX, WALL1_IDX, WIDTH, HEIGHT, PART, …, STOP]
이 스키마를 사용하면 고정 크기 슬롯이나 패딩 없이도 토큰의 1D 패킹이 가능하다. 또한 PART 토큰으로 유연하게 구분되므로 하위 시퀀스의 수나 계층 구조에 제한을 두지 않는다. 이를 통해 임의의 복잡한 장면 표현이 가능해진다.
토큰화된 시퀀스는 5cm 해상도의 정수로 분리된 다음 학습 가능한 lookup table을 통해 임베딩 시퀀스로 변환된다. 이 tokenization 방식은 Byte-Pair Encoding (BPE)과 같은 NLP tokenization과 현저히 다르다.
Results
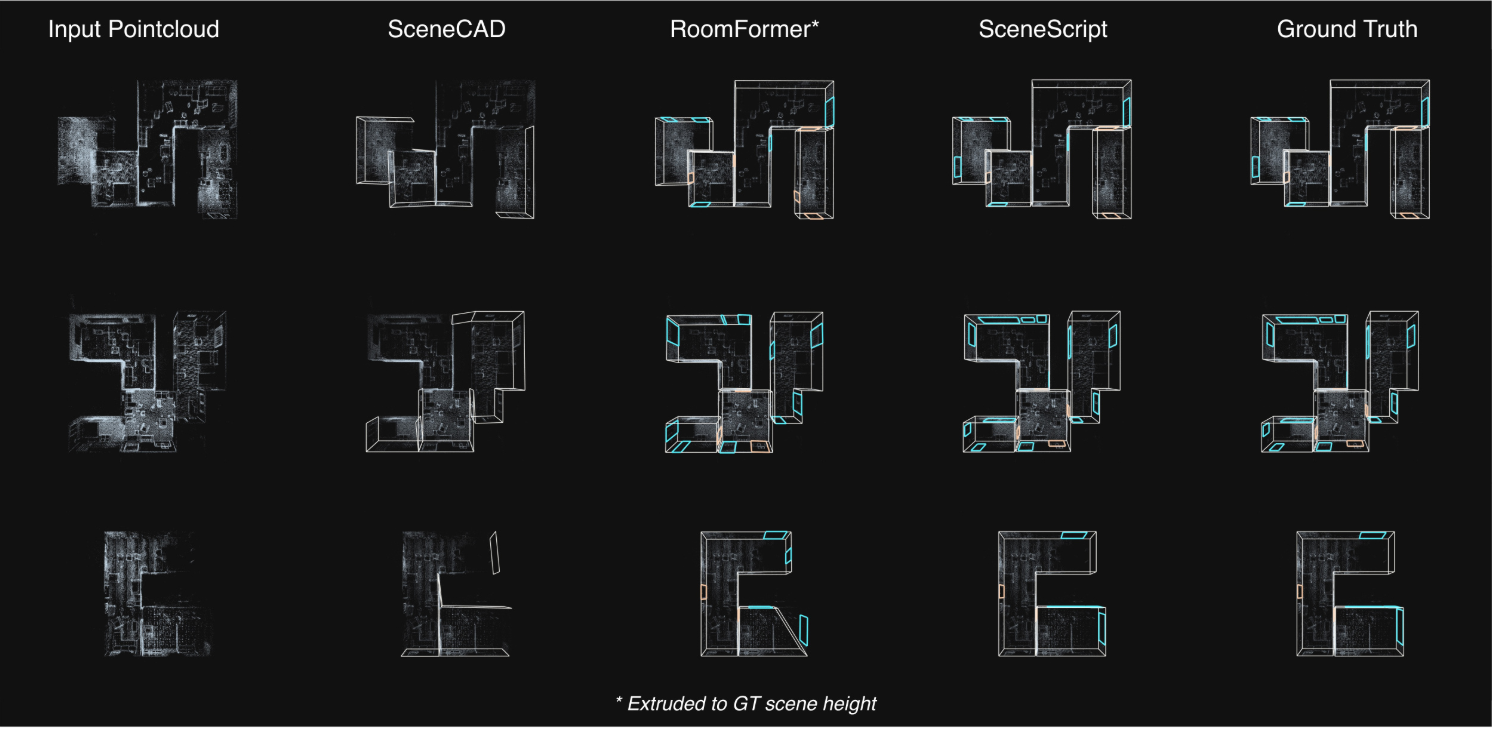
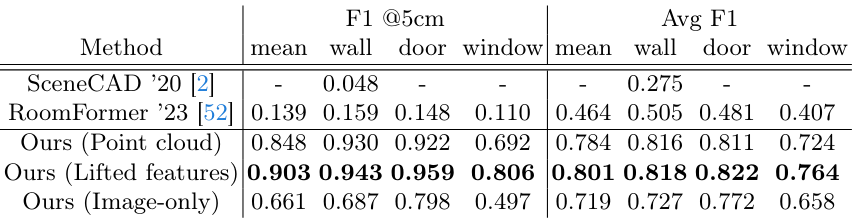
1. Layout Estimation
다음은 Aria Synthetic Environments에서 기존 방법들과 비교한 결과이다.
2. Object Detection
다음은 3D Object Detection 성능을 SOTA 방법들과 비교한 표이다.

3. Extending the SceneScript Structured Language
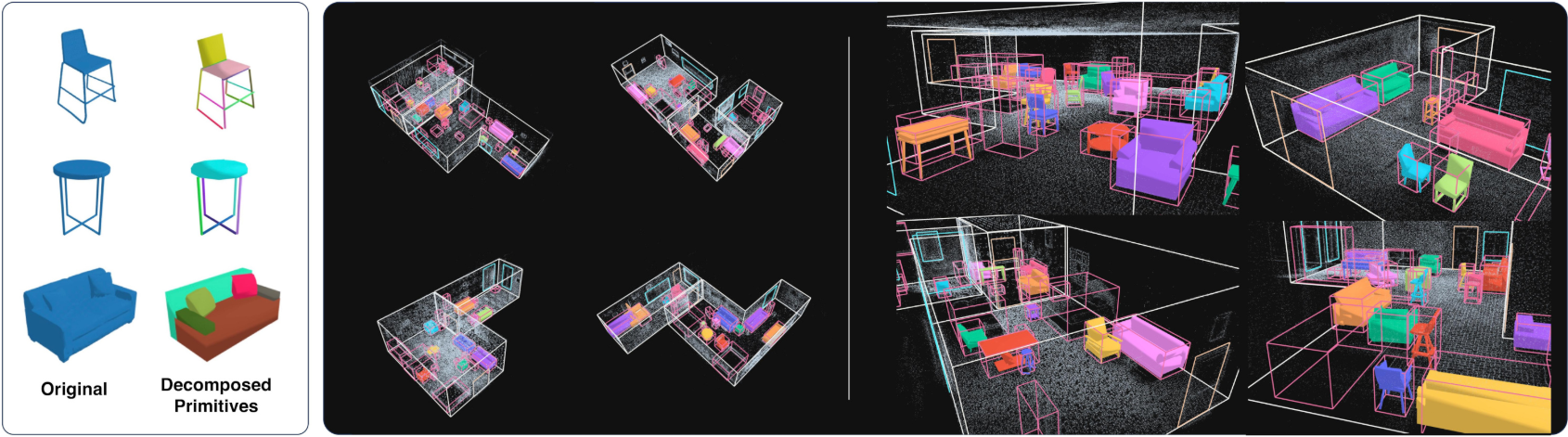
저자들은 primitives (직육면체, 원통)들을 설명하기 위해 make_prim이라는 커맨드를 추가했다.
make_prim: bbox_id, prim_num, class, center_x, center_y, center_z, angle_x, angle_y, angle_z, scale_x, scale_y, scale_z
prim_num 파라미터는 semantics와 연관될 수 있다. 즉, 같은 semantic의 개체는 동일한 prim_num을 갖는다.
make_prim 커맨드를 포함한 학습을 위해 저자들은 3가지 카테고리 (테이블, 의자, 소파)를 primitives로 분해하여 데이터셋을 구성했다.
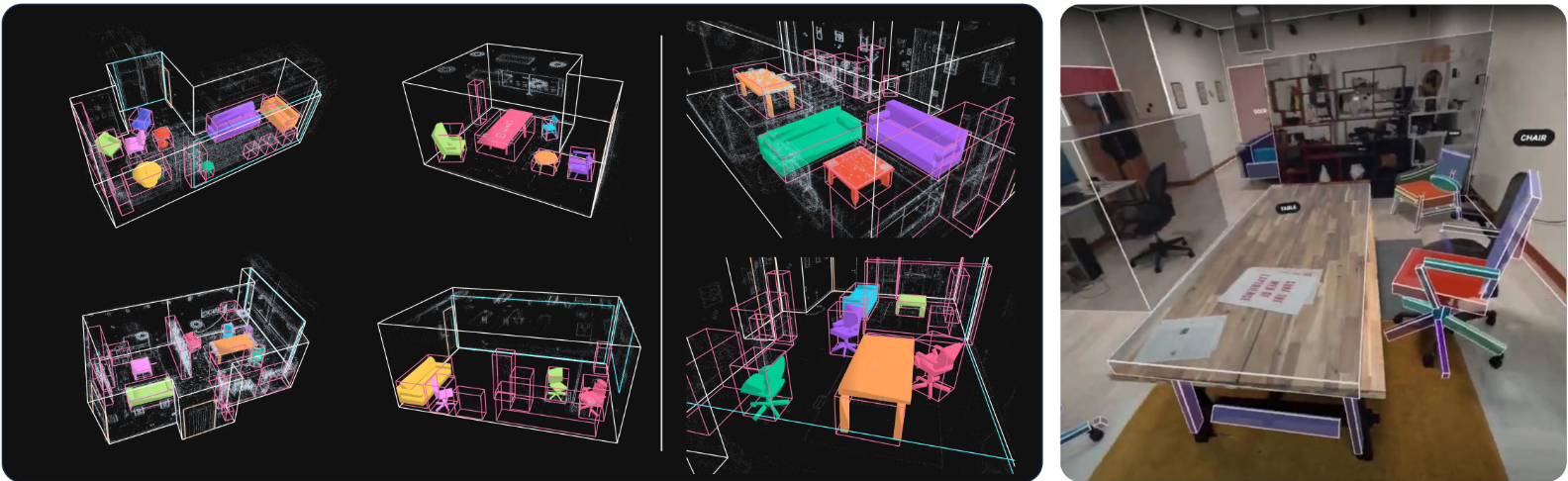
다음은 (왼쪽) make_prim 학습 쌍을 생성하기 위해 사용된 분해된 메쉬들과 (오른쪽) Aria Synthetic Environments에서의 장면 재구성 예시이다.
다음은 실제 장면들에서의 장면 재구성 예시이다.