[논문리뷰] Semantic-Conditional Diffusion Networks for Image Captioning (SCD-Net)
CVPR 2023. [Paper] [Github]
Jianjie Luo, Yehao Li, Yingwei Pan, Ting Yao, Jianlin Feng, Hongyang Chao, Tao Mei
Sun Yat-sen University | JD Explore Academy
6 Dec 2022
Introduction
비전 및 언어 분야의 기본 과제 중 하나인 image captioning은 관심 있는 semantic을 자연스러운 문장으로 기술하는 것을 목표로 한다. 이 task는 장면의 시각적 콘텐츠를 인식하고 인간 언어로 해석하여 인간 지능의 기본 능력을 시뮬레이션함으로써 컴퓨터 비전과 자연어 처리를 자연스럽게 연결한다. 현재 SOTA 기술은 인코딩된 디코더 구조를 활용하고 학습 프로세스를 autoregressive 방식으로 구성하는 것이 지배적이다. 특히 이미지 인코더는 시각적 콘텐츠를 상위 수준의 semantic으로 인코딩하는 역할을 하고, 문장 디코더는 순차적인 문장을 단어별로 디코딩하는 방법을 학습한다. 그럼에도 불구하고 이러한 autoregressive 진행은 단방향 텍스트 메시지 전달만 허용하며 일반적으로 문장 길이의 제곱에 비례하는 상당한 계산 리소스에 의존한다.
이 제한을 완화하기 위해 최근의 발전은 양방향 텍스트 메시지 전달을 가능하게 하고 모든 단어를 병렬로 방출하여 가볍고 확장 가능한 패러다임으로 이어지는 non-autoregressive 솔루션으로 등장하기 시작했다. 그러나 이러한 non-autoregressive 방법은 일반적으로 autoregressive 방법보다 성능이 떨어진다. 성능 저하의 원인은 대부분 단어 반복 또는 누락 문제 때문이며, 순차적 의존성이 제대로 활용되지 않는 경우에 발생한다. 또한 문장 품질이 좋지 않아 autoregressive 방법에 널리 채택된 강력한 self-critical sequence training으로 non-autoregressive 솔루션을 업그레이드하기가 어렵다.
보다 최근에는 diffusion model이라는 우수한 생성 모듈이 시각적 콘텐츠 생성을 위한 개선을 가져왔다. 이것은 image captioning을 위한 diffusion model을 탐구하는 최근의 선구적인 관행에 동기를 부여받아 높은 수준의 병렬 처리에서 non-autoregressive 문장 생성을 추구한다. 각 단어를 이진 비트로 표시하여 이산 단어 시퀀스를 생성하는 연속적인 diffusion process를 가능하게 한다. 이러한 연속적인 diffusion process는 일반적인 single shot에서의 이산 문장 생성과 달리 점차 문장에 Gaussian noise를 추가하는 parameterize된 Markov chain으로 나타낼 수 있다. 따라서 각각의 reverse state transition은 denoising을 통해 noise가 추가된 데이터에서 원래 문장 데이터를 복구하도록 학습된다. 기본 autoregressive model에 대해 비슷한 성능을 보여주고 있음에도 불구하고, 단어 반복이나 생략의 심각한 문제는 여전히 간과되고 있다.
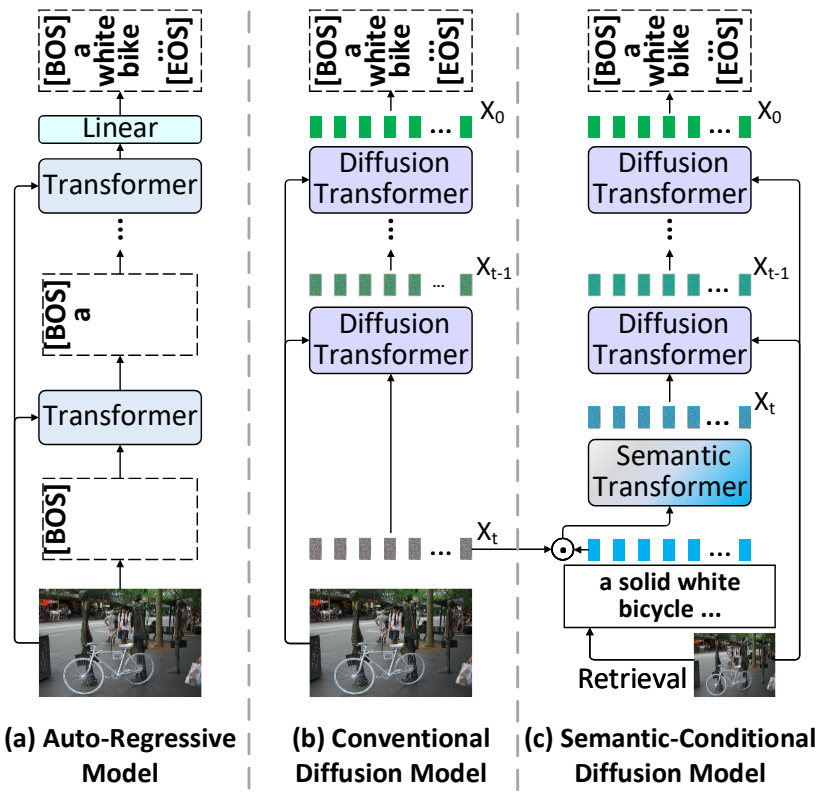
본 논문은 이 문제를 완화하기 위한 노력의 일환으로 Semantic-Conditional Diffusion Network (SCD-Net)라고 하는 non-autoregressive 패러다임 기반의 새로운 diffusion model을 고안했다. 저자들의 출발점은 입력 이미지의 포괄적인 semantic 정보를 지속적인 diffusion process에 도입하는 것인데, 이는 각각의 reverse state transition 학습을 가이드하기 위한 semantic prior 역할을 한다. SCD-Net은 이제 시각적 콘텐츠와 출력 문장 사이의 더 나은 semantic 정렬을 장려할 수 있다. 즉, semantic 단어의 생략을 완화할 수 있다. 부산물로 SCD-Net은 연속적인 diffusion process에서 강력한 self-critical sequence training을 가능하게 한다. 이러한 diffusion process의 문장 레벨 최적화는 출력 문장의 언어적 일관성을 강화하여 단어 반복 문제를 완화한다.
기술적으로 SCD-Net은 출력 문장을 점진적으로 향상시키는 계단식 Diffusion Transformer 구조로 구성된다. 각 Diffusion Transformer는 Transformer 기반 인코더-디코더를 학습하기 위해 semantic 조건부 diffusion process를 활용한다. 특히, 각 입력 이미지에 대해 Diffusion Transformer는 기존 crossmodal 검색 모델을 사용하여 의미론적으로 관련된 단어를 먼저 검색한다. 이러한 의미론적 단어는 연속적인 diffusion process에 추가로 통합되어 semantic 조건으로 reverse state transition을 제한하는 것을 목표로 한다. 더 중요한 것은 새로운 Guided Self-Critical Sequence Training 전략으로 semantic 조건부 diffusion process를 업그레이드한다는 것이다. 이 전략은 문장 레벨 reward를 통해 표준 autoregressive Transformer 모델의 지식을 non-autoregressive Diffusion Transformer로 우아하게 전달하여 안정화되고 강화된 diffusion process로 이어진다.
Method
Semantic-Conditional Diffusion Network (SCD-Net)는 풍부한 semantic prior를 통해 diffusion process 기반 image captioning을 용이하게 한다. 위 그림은 여러 개의 Diffusion Transformer가 적층된 SCDNet의 계단식 프레임워크와 각 Diffusion Transformer의 세부 아키텍처를 보여준다.
1. Problem Formulation
Notation of Diffusion Model
$N_s$개의 단어의 텍스트 문장 $S$로 설명될 $K$개의 관심 대상이 있는 입력 이미지가 있다고 가정하자. \(V = \{v_i\}_{i=1}^K\)는 Faster R-CNN에 의해 감지된 객체 집합을 나타내며, 여기서 \(v_i \in \mathbb{R}^{D_v}\)는 각 객체의 $D_v$ 차원 feature를 나타낸다. 여기에서는 기본적으로 diffusion model을 사용하여 캡션 생성 절차를 공식화한다. 텍스트 문장의 단어가 이산 데이터라는 점을 고려하여 Bit Diffusion을 따르고 각 단어를 $n = \lceil \log_2 \mathcal{W} \rceil$개의 이진 비트로 변환한다. 여기서 $\mathcal{W}$는 vocabulary 크기이다. 이러한 방식으로 텍스트 문장 $S$는 실수 $x_0 \in \mathbb{R}^{n \times N_s}$로 변환되어 diffusion model에 입력된다. 특히 diffusion model은 forward process와 reverse process의 두 가지 과정으로 구성된다.
Forward Process
Forward process는 문장 데이터 $x_0$에 점진적으로 Gaussian noise를 추가하는 Markov chain으로 정의된다. 임의의 $t \in (0, T]$에 대해 $x_0$에서 $x_t$로의 forward state transition은 다음과 같이 계산된다.
\[\begin{equation} x_t = \sqrt{\textrm{sigmoid} (- \gamma (t'))} x_0 + \sqrt{\textrm{sigmoid} (\gamma (t'))} \epsilon \\ \textrm{where} \quad t' = t/T, \quad \epsilon \sim \mathcal{N} (0,I), \quad t \sim \mathcal{U} (0, T) \end{equation}\]$\gamma (t’)$는 단조 증가 함수이다. 그 후, Diffusion Transformer $f(x_t, \gamma (t’), \mathcal{V})$는 $\ell_2$ regression loss에서 denoising을 통해 $\mathcal{V}$를 조건으로 $x_0$를 재구성하도록 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{bit} = \mathbb{E}_{t \sim \mathcal{U} (0, T), \epsilon \sim \mathcal{N} (0, I)} \| f (x_t, \gamma (t'), \mathcal{V}) - x_0 \|^2 \end{equation}\]Reverse Process
주어진 이미지를 기반으로 학습된 Diffusion Transformer에서 문장을 생성하려는 노력의 일환으로 reverse process는 latent state 시퀀스 $x_t$를 $t = T$에서 $t = 0$으로 샘플링한다. 구체적으로, step 수 $T$가 주어지면 폭 $1/T$로 시간을 균일하게 discretize하여
\[\begin{equation} s = t − 1 − \Delta, \quad t' = t/T, \quad s' = s/T \end{equation}\]를 얻는다. 다음으로 reverse state transition $x_{t−1}$은 다음과 같이 측정된다.
\[\begin{aligned} \alpha_s &= \sqrt{\textrm{sigmoid} (- \gamma (s'))} \\ \alpha_t &= \sqrt{\textrm{sigmoid} (\gamma (s'))} \\ c &= 1 - \exp (\gamma (s') - \gamma (t')) \\ u(x_t; s', t') &= \alpha_s (\frac{x_t (1-c)}{\alpha_t} + c f(x_t, \gamma (t') , \mathcal{V})) \\ \sigma^2 (s', t') &= \sigma_s^2 c \\ x_{t-1} &= u (x_t; s', t') + \sigma (s', t') \epsilon \end{aligned}\]여기서 $\Delta$는 시간 차이이다. $x_T$에서 Diffusion Transformer를 반복적으로 실행한 후 추정값을 얻을 수 있으며 quantization 연산을 수행하여 비트 $x_0$로 변환한다.
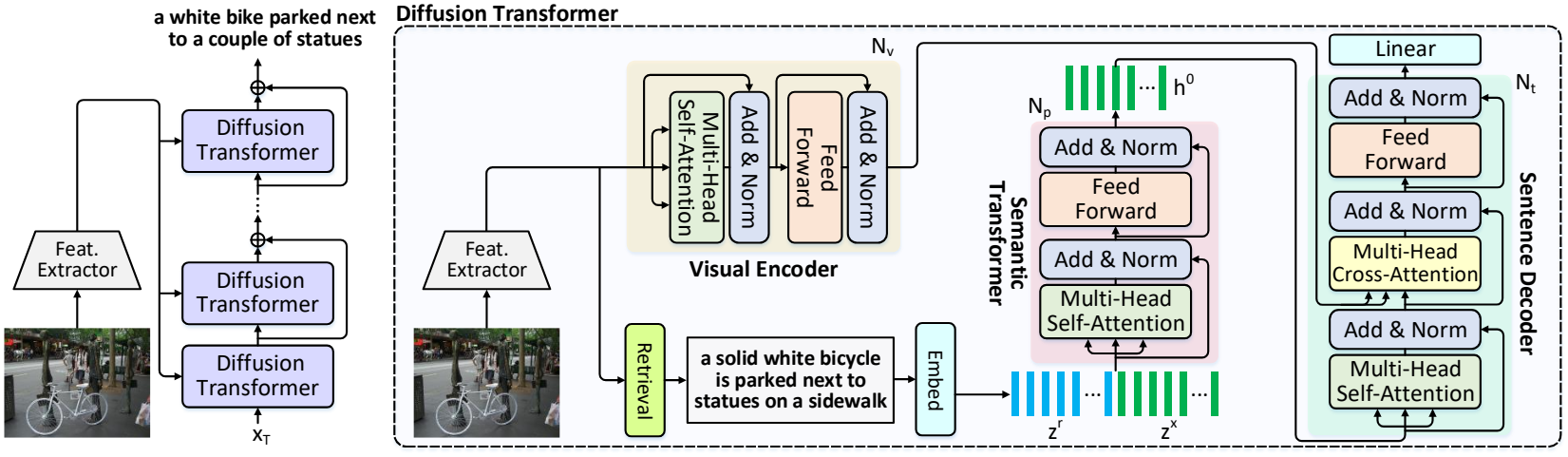
2. Diffusion Transformer
기본적인 Diffusion Transformer는 시각적 인코더와 문장 디코더를 포함하는 전형적인 Transformer 기반의 인코더-디코더 구조로 구성되어 있다. 이미지에서 감지된 객체 \(가 주어지면 시각적 인코더는 self-attention을 통해 이를 시각적 토큰으로 변환한다. 그런 다음 timestep $t$에서 시각적 토큰과 단어 토큰\)x_t = { w_0^t, w_1^t, \ldots, w_{N_s}^t }$$가 캡션 생성을 위해 문장 디코더에 공급된다.
Visual Encoder
시각적 인코더는 $N_v$개의 Transformer 인코더 블록의 스택으로 구성된다. 각 블록은 multi-head self-attention layer와 feed-forward layer로 구성된다. 시각적 인코더의 $i$번째 Transformer 인코더 블록은 다음과 같이 작동한다.
\[\begin{aligned} \mathcal{V}^{i+1} &= \textrm{FFN} (\textrm{norm} (\mathcal{V}^i + \textrm{MultiHead} (\mathcal{V}^i, \mathcal{V}^i, \mathcal{V}^i))) \\ \textrm{FFN} (Z) &= \textrm{norm} (Z + \textrm{FC} (\delta (\textrm{FC} (Z)))) \\ \textrm{MultiHead} (Q, K, V) &= \textrm{Concat} (\textrm{head}_1, \ldots, \textrm{head}_H) W^O \\ \textrm{head}_i &= \textrm{Attention} (QW_i^Q, KW_i^K, VW_i^V) \\ \textrm{Attention} (Q, K, V) &= \textrm{softmax} (\frac{QK^\top}{\sqrt{d}}) V \end{aligned}\]여기서 $\textrm{FFN}$은 feed-forward layer, $\textrm{MultiHead}$는 multi-head self-attention layer, $\textrm{norm}$은 layer normalization, $\textrm{FC}$는 fully-connected layer, $\textrm{Concat}$은 concatenation 연산, $\delta$는 activation function이다. $W_i^Q$, $W_i^K$, $W_i^V$, $W^O$는 $i$번째 head의 가중치 행렬이다. $H$는 head의 수이고 $d$는 각 head의 차원이다. 첫 번째 Transformer 인코더 블록의 입력은 감지된 개체의 기본 집합 $\mathcal{V}^0 = \mathcal{V}$이다. 따라서 $N_v$개의 블록을 쌓은 후 상황에 맞게 향상된 시각적 토큰 $\tilde{V} = V^{N_v}$를 얻는다.
Sentence Decoder
문장 디코더는 $N_t$개의 Transformer 디코더 블록의 스택을 포함한다. 각 블록은 하나의 multi-head self-attention layer, 하나의 multi-head crossattention layer, 그리고 하나의 feed-forward layer로 구성된다. 마스크를 사용하여 위치가 후속 위치에 attend되는 것을 방지하는 기존 Transformer와 달리 Diffusion Transformer의 multi-head self-attention layer는 마스크 없이 양방향이다. 이러한 방식으로 $i$번째 Transformer 디코더 블록은 다음과 같이 작동한다.
\[\begin{aligned} h^{i+1} &= \textrm{FFN} (\textrm{norm} (\tilde{h}^i + \textrm{MultiHead} (\tilde{h}^i, \tilde{\mathcal{V}}, \tilde{\mathcal{V}}))) \\ \tilde{h}^i &= \textrm{norm} (h^i + \textrm{MultiHead} (h^i, h^i, h^i)) \end{aligned}\]Timestep $t$에서 첫 번째 트랜스포머 디코더 블록의 입력은 단어 토큰 \(h^0 = \{ w_0^t, w_1^t, \ldots, w_{N_s}^t\}\)이다. $N_t$개의 블록을 쌓은 후 마지막 블록 $h^{N_t}$에 의해 출력된 hidden state는 각 출력 단어의 확률 분포를 예측하는 데 사용되며 다음과 같이 계산된다.
\[\begin{equation} p_i = \textrm{softmax} (W^\top h_i^{N_t}) \end{equation}\]여기서 $W$는 가중치 행렬, $h_i^{N_t}$와 $p_i \in \mathbb{R}^{\mathcal{W}}$는 각각 $i$번째 단어에 해당하는 hidden state 벡터와 확률 분포이다. 그런 다음 vocabulary의 모든 $\mathcal{W}$개의 비트에 대해 가중 평균을 취하여 $p_i$의 확률 분포를 비트 $b_i$로 매핑한다.
\[\begin{equation} b_i = \sum_{c=1}^\mathcal{W} p_i^c B^c \end{equation}\]여기서 $p_i^c$는 $p_i$의 $c$번째 확률이고 $B^c$는 vocabulary에서 $c$번째 단어의 비트 표현이다. Diffusion Transformer의 수렴 속도를 높이기 위해 학습 중 확률 분포 $p$에 대한 일반적인 cross-entropy loss \(\mathcal{L}_\textrm{XE}\)와 diffusion process 목적 함수 \(\textrm{L}_\textrm{bit}\)를 통합한다. 따라서 최종 목적 함수는 다음과 같이 계산된다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{XE} + \mathcal{L}_\textrm{bit} \end{equation}\]3. Semantic Condition
최근에는 noise 분포 $\mathcal{N} (0,I)$에서 샘플링한 latent state $x_T$에서 $x_0$를 reverse process로 직접 추정하여 image captioning에 diffusion model을 사용하려고 한다. 그럼에도 불구하고 이러한 방식은 diffusion process에서 복잡한 시각-언어 정렬과 단어 간의 고유한 순차적 의존성을 간과하여 단어 반복 또는 누락 문제를 초래한다. 이 제한을 완화하기 위해 diffusion model을 추가 semantic prior로 업그레이드하여 Diffusion Transformer에 대한 semantic으로 컨디셔닝된 diffusion process를 생성한다.
이미지가 주어지면 먼저 기존 crossmodal 검색 모델을 사용하여 학습 문장 풀에서 의미론적으로 관련된 문장을 검색한다. 관련 문장은 포괄적인 semantic 정보를 반영하는 일련의 단어 토큰 $s_r$로 더 표현된다. 그런 다음 $s_r$을 Diffusion Transformer의 diffusion process를 제한하기 위한 semantic 조건으로 사용한다. 특히, 각 timestep $t$에서 semantic prior $s_r$로 현재 latent state $x_t$를 문맥적으로 인코딩하기 위해 $N_p$개의 semantic Transformer 블록이 있는 추가 semantic Transformer를 활용한다. 여기서 채널 차원을 따라 이전 timestep의 예측 \(\tilde{x}_0\)와 $x_t$를 concat한다. 따라서 latent state $x_t$와 semantic prior $s_r$의 텍스트 feature는 다음과 같이 계산된다.
\[\begin{aligned} z^x &= \textrm{FC} (\textrm{Concat} (x_t, \tilde{x}_0)) + \phi (\gamma (t')) \\ z^r &= \textrm{FC} (s_r) \end{aligned}\]여기서 $\phi$는 MLP이다. 단순화를 위해 위치 인코딩이 생략되었다. 다음으로 텍스트 feature는 $z^x$와 $z^r$을 $\mathcal{W}^0 = [z^x, z^r]$로 concat한다. 이는 semantic 조건부 latent state를 달성하기 위해 semantic Transformer에 추가로 공급된다. 이러한 방식으로 $i$번째 semantic Transformer 블록은 다음과 같이 계산된다.
\[\begin{equation} \mathcal{W}^{i+1} = \textrm{FFN} (\textrm{norm} (\mathcal{W}^i + \textrm{MultiHead} (\mathcal{W}^i, \mathcal{W}^i, \mathcal{W}^i))) \end{equation}\]마지막으로 semantic Transformer의 출력을 \(\mathcal{W}^{N_p} = [\mathcal{W}_x^{N_p}, \mathcal{W}_r^{N_p}]\)로 표시한다. \(\mathcal{W}_x^{N_p}\)는 강화된 semantic 조건부 latent state
\[\begin{equation} \mathcal{W}_x^{N_p} = h^0 = \{ w_0^t, w_1^t, \ldots, w_{N_s}^t \} \end{equation}\]로 취한다. 이는 diffusion model에서 캡션 생성을 위해 문장 디코더에 입력된다.
4. Cascaded Diffusion Transformer
이미지 생성을 위한 계단식 diffusion model의 성공에 영감을 받은 SCD-Net은 여러 개의 Diffusion Transformer를 계단식 방식으로 쌓는다. 이러한 계단식 구조는 더 나은 시각-언어 정렬과 언어적 일관성으로 출력 문장을 점진적으로 강화하는 것을 목표로 한다. 이 계단식 diffusion process는 다음과 같이 나타낼 수 있다.
\[\begin{equation} F(x_t, \gamma (t'), \mathcal{V}) = f_M \circ f_{M-1} \circ \cdots \circ f_1 (x_t, \gamma (t'), \mathcal{V}) \end{equation}\]여기서 $M$은 적층된 Diffusion Transformer의 총 개수이고, $f_1$은 앞서 언급한 semantic 조건을 갖춘 첫 번째 Diffusion Transformer이다. 이와 같이 각 Diffusion Transformer $f_i (i \ge 2)$는 이전 Diffusion Transformer $f_{i-1}$의 문장 예측 $x_0^{i-1}$을 조건으로 diffusion process를 수행한다. 따라서 각 Diffusion Transformer $f_i (i \ge 2)$에 대해 $x_0^{i-1}$의 추가 semantic 단서를 고려하기 위해 구조를 약간 수정한다. Latent state $x_t$, 이전 timestep 예측 \(\tilde{x}_0\), 이전 Diffusion Transformer 예측 $x_0^{i-1}$이 주어지면 latent state $z^x$의 텍스트 feature를 다음과 같이 측정한다.
\[\begin{equation} z^x = \textrm{FC} (\textrm{Concat} (x_t, \tilde{x}_0, x_0^{i-1})) + \phi (\gamma (t')) \end{equation}\]그런 다음 텍스트 feature $z^x$는 semantic prior $z^r$과 연결되고 semantic Transformer에 공급된다. Inference할 때, 각 Diffusion Transformer $f_i$의 출력은 각 timestep에서 이전 Diffusion Transformer $f_{i-1}$의 출력과 직접 융합된다.
5. Guided Self-Critical Sequence Training
기존의 autoregressive image captioning 기술은 일반적으로 Self-Critical Sequence Training (SCST)을 활용하여 문장 레벨 최적화로 성능을 향상시킨다.
\[\begin{equation} \mathcal{L}_R (\theta) = - \mathbb{E}_{y_{1:N_s} \sim p_\theta} [R (y_{1:N_s})] \end{equation}\]여기서 $R$은 CIDEr score function을 나타낸다. Loss의 기울기는 다음과 같이 근사화할 수 있다.
\[\begin{equation} \nabla_\theta \mathcal{L}_R (\theta) \approx - (R(y_{1:N_s}^s) - R(\hat{y}_{1:N_s})) \nabla_\theta \log p_\theta (y_{1:N_s}^s) \end{equation}\]여기서 \(y_{1:N_s}^s\) 는 샘플링된 캡션이고 \(R(\hat{y}_{1:N_s})\)는 inference를 greedy하게 디코딩할 때 baseline의 문장 레벨 reward를 나타낸다. 그러나 Diffusion Transformer에서 diffusion process에 SCST를 직접 적용하는 것은 쉬운 일이 아니다. 어려움은 주로 두 가지 측면에서 비롯된다.
첫째, Diffusion Transformer의 non-autoregressive inference 절차는 여러 step (ex. 20개 이상)을 포함하므로 noise $x_T$에서 직접 샘플 문장을 추출하는 것은 비실용적이다. 또한 Diffusion Transformer의 각 출력 단어는 독립적으로 샘플링되기 때문에 단순히 각 단어에 동일한 reward를 할당하면 일반적인 단어 반복 문제가 발생한다. 이러한 제한 사항을 해결하기 위해 표준 autoregressive Transformer 모델에서 파생된 지식으로 SCD-Net 학습을 훌륭하게 가이드하는 새로운 Guided Self-Critical Sequence Training을 제안한다.
먼저 Diffusion Transformer의 동일한 아키텍처를 공유하는 표준 autoregressive Transformer teacher model을 학습한다. 다음으로, 각 학습 이미지에 대해 이 Transformer teacher model은 추가 semantic guidance로 고품질 문장 $S^\textrm{tea}$를 예측한다. 그런 다음 예측된 고품질 문장 $S^\textrm{tea}$를 ground-truth 문장 대신 계단식 Diffusion Transformer에 공급한다. 기존의 SCST에서와 같이 여러 캡션을 무작위로 샘플링하는 대신 샘플링된 문장 중 하나가 예측된 문장과 동일하도록 강제한다. \({y'}_{1:N_s}^{s_j} \vert_{j=0}^{N_y}\)은 $S^\textrm{tea}$를 포함하는 샘플링된 문장을 나타내며, 여기서 $N_y$는 샘플링된 문장의 수이다. 따라서 \(\mathcal{L}_R (\theta)\)의 기울기는 다음과 같이 측정된다.
\[\begin{equation} \nabla_\theta \mathcal{L}_R (\theta) \approx - \frac{1}{N_y} \sum_{j=0}^{N_y} (R({y'}_{1:N_s}^{s_j}) - R(\hat{y}_{1:N_s})) \nabla_\theta \log p_\theta ({y'}_{1:N_s}^{s_j}) \end{equation}\]이와 같이 고품질 문장 $S^\textrm{tea}$의 샘플링은 양의 reward를 받는 경향이 있으며, 이는 Diffusion Transformer가 고품질 문장을 생성하도록 장려한다. 따라서 다른 낮은 품질의 문장 (ex. 단어 반복이 있는 문장)의 가능성이 억제된다. Diffusion model이 포화 상태가 되면 $S’$ (CIDEr에서 측정)의 품질이 $S^\textrm{tea}$보다 높으면 autoregressive Transformer 모델에서 파생된 문장 $S^\textrm{tea}$를 diffusion model에 의해 추정된 $S’$으로 대체한다.
Experiments
- 데이터셋: COCO
- 구현
- ImageNet에서 사전 학습된 Faster-RCNN과 Visual Genome으로 이미지 region feature를 추출
- 2048차원의 region feature를 FC layer를 사용하여 512차원으로 변환
- 각 단어는 14비트로 변환됨
- 시각적 인코더, 문장 디코더, semantic Transformer는 각각 3개의 Transformer 블록으로 구성
($N_v = 3$, $N_t = 3$, $N_p = 3$) - 각 Transformer 블록의 hidden size는 512
- 학습
- 1단계: 전체 아키텍처 최적화
- optimizer: Adam
- $\ell_2$ regression loss, labels smoothing
- epochs: 60
- batch size: 16
- 2단계: guided self-critical sequence training로 최적화
- epochs: 60
- batch size: 16
- learning rate: $10^{-5}$
- 1단계: 전체 아키텍처 최적화
- Inference
- timestep 수: 50
- 시간 차이: $\Delta$ = 0
1. Performance Comparison
다음은 COCO Karpathy test split에서 다른 SOTA 접근 방식과 SCD-Net을 비교한 결과이다.

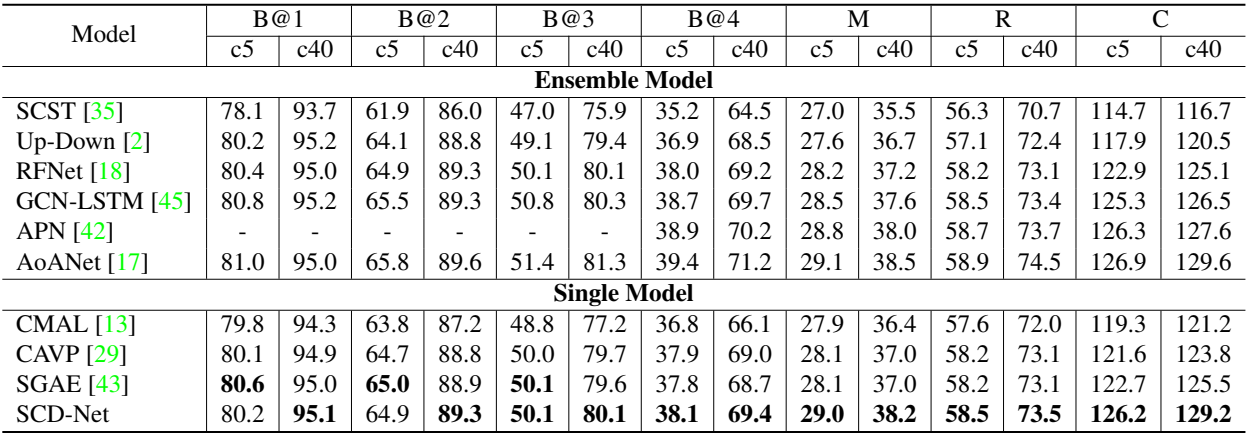
다음은 온라인 테스트 서버에서 다른 SOTA 접근 방식과 SCD-Net을 비교한 결과이다.
다음은 image captioning 결과를 비교한 것이다.

2. Experimental Analysis
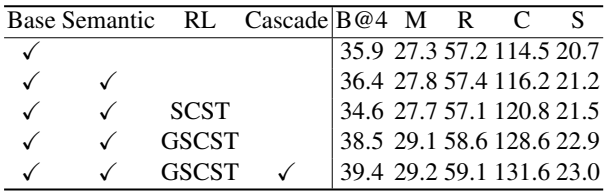
다음은 SCD-Net의 각 디자인에 대한 ablation 결과이다. (COCO Karpathy test split)
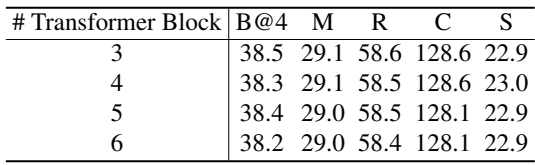
다음은 Diffusion Transformer 1개에 포함된 Transformer 블록 수에 따른 ablation 결과이다.
다음은 Diffusion Transformer 수에 따른 ablation 결과이다.