[논문리뷰] SANA 1.5: Efficient Scaling of Training-Time and Inference-Time Compute in Linear Diffusion Transformer
ICML 2025. [Paper] [Page] [Github]
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Chengyue Wu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, Han Cai, Bingchen Liu, Daquan Zhou, Song Han
NVIDIA | MIT | Tsinghua University | Playground | Peking University | The University of Hong Kong
30 Jan 2025
Introduction
SANA 1.0은 계산량을 크게 줄이면서도 경쟁력 있는 성능을 달성하는 효율적인 linear diffusion transformer (DiT)를 도입했다. 이를 바탕으로 본 논문은 두 가지 근본적인 질문을 탐구하였다.
- Linear DiT의 scalability는 어떠한가?
- 대규모 linear DiT를 어떻게 scaling하고 학습 비용을 줄일 수 있는가?
본 논문에서는 학습과 inference 모두에서 효율적인 모델 scaling을 위한 세 가지 핵심 혁신을 도입한 SANA-1.5를 소개한다.
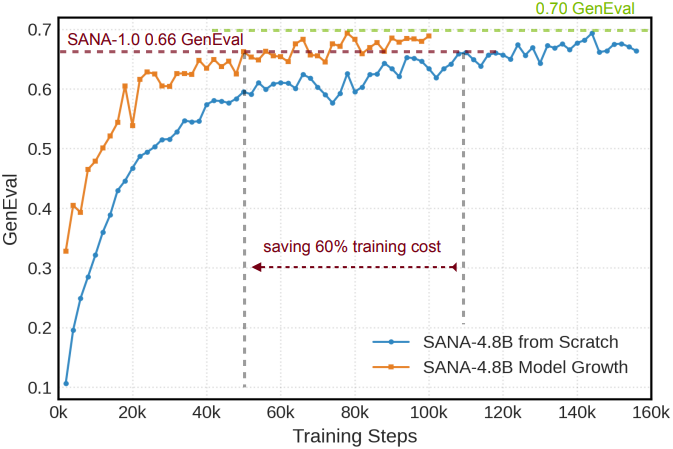
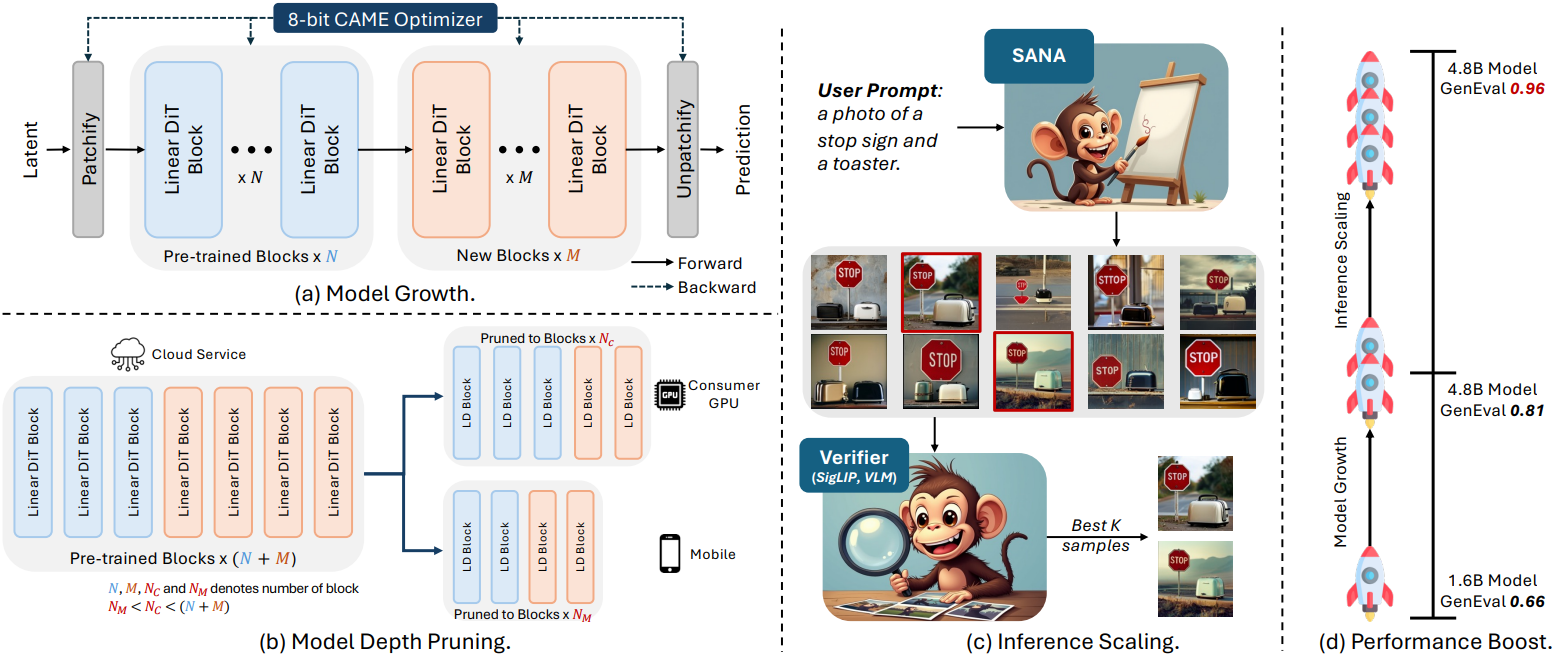
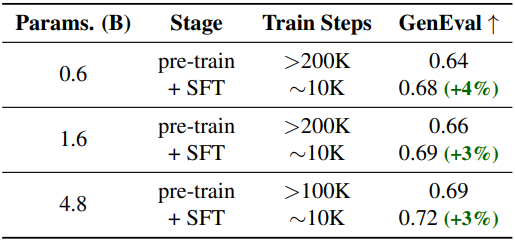
- 모델 성장 전략: 작은 모델에서 학습한 지식을 재사용하면서 SANA 파라미터를 1.6B에서 4.8B로 scaling하였다 (block 개수는 20개에서 60개로). 큰 모델을 처음부터 학습시키는 기존의 scaling 방식과 달리, 본 논문에서는 추가 블록을 전략적으로 초기화하여 큰 모델이 작은 모델의 사전 지식을 유지할 수 있도록 하였다. 이 방식은 처음부터 학습하는 방식보다 학습 시간을 60% 단축시킨다.
- 모델 depth pruning: DiT에서 입출력 유사성 패턴을 통해 block 중요도를 분석하여, 덜 중요한 block을 pruning하고 fine-tuning을 통해 모델 품질을 빠르게 회복시킨다 (GPU 1개에서 5분 소요). 본 논문의 grow-then-prune 방식은 60-block 모델을 다양한 구성(40/30/20 block)으로 효과적으로 압축하는 동시에 경쟁력 있는 품질을 유지하여, 다양한 컴퓨팅 예산에 걸쳐 유연한 모델 배포를 위한 효율적인 경로를 제공한다.
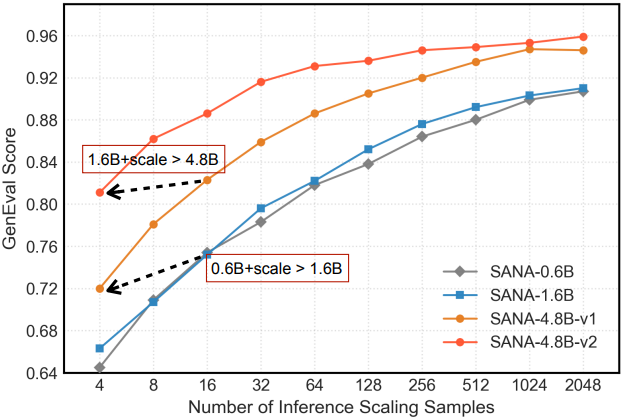
- Inference-time scaling 전략: 파라미터 scaling이 아닌 연산을 통해 작은 모델이 더 큰 모델 품질에 맞춰질 수 있도록 한다. 여러 샘플을 생성하고 VLM 기반 선택 메커니즘을 활용함으로써, GenEval 점수를 0.81에서 0.96으로 향상시켰다. 이러한 향상은 LLM에서 관찰되는 유사한 log-linear scaling 패턴을 따르며, 연산 리소스를 모델 용량과 효과적으로 교환할 수 있다.
모델 성장 전략은 먼저 더 넓은 최적화 공간을 탐색하여 더 나은 feature 표현을 발견한다. 그런 다음 모델 depth prune은 필수 feature를 식별하고 보존하여 효율적인 배포를 가능하게 한다. 한편, inference-time scaling은 보완적인 관점을 제공한다. 모델 용량이 제한적인 경우, inference 연산 리소스를 추가로 활용하여 더 큰 모델과 유사하거나 더 나은 결과를 얻을 수 있다.
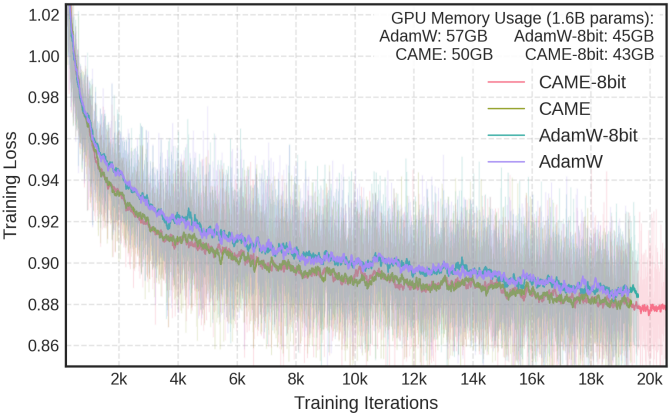
저자들은 효율적인 학습과 대규모 모델의 fine-tuning을 위해, AdamW-8bit를 통해 CAME를 확장하여 메모리 효율적인 optimizer인 CAME-8bit를 구현했다. CAME-8bit는 학습 안정성을 유지하면서 AdamW-32bit에 비해 메모리 사용량을 약 8배 줄였다. 이 최적화는 사전 학습뿐만 아니라 단일 GPU fine-tuning 시나리오에서도 효과적이며, RTX 4090 GPU에서 SANA-4.8B를 fine-tuning할 수 있도록 지원하였다.
SANA-1.5는 처음부터 학습하는 방식보다 2.5배 빠른 학습 수렴을 달성하였다. 학습 scaling 전략을 통해 GenEval 점수를 0.66에서 0.81로 향상시켰으며, inference scaling을 통해 0.96까지 더욱 높일 수 있어 GenEval 벤치마크에서 새로운 SOTA를 달성하였다. 저자들은 소규모 모델에서 얻은 지식을 활용하고 성장-pruning 프로세스를 신중하게 설계함으로써, 더 나은 품질을 얻기 위해 항상 더 큰 모델이 필요한 것은 아니라는 것을 보여주었다.
Methods
1. Efficient Model Growth
대규모 모델을 처음부터 학습하는 대신, $N$개의 layer를 가진 사전 학습된 DiT를 $N+M$개의 layer로 확장하는 동시에 학습된 지식을 보존한다.
초기화 전략
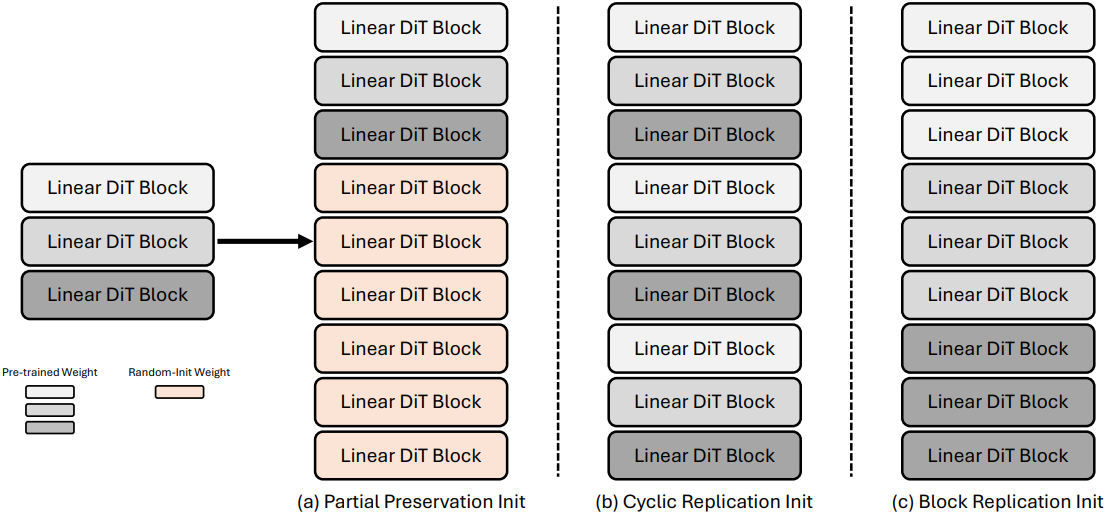
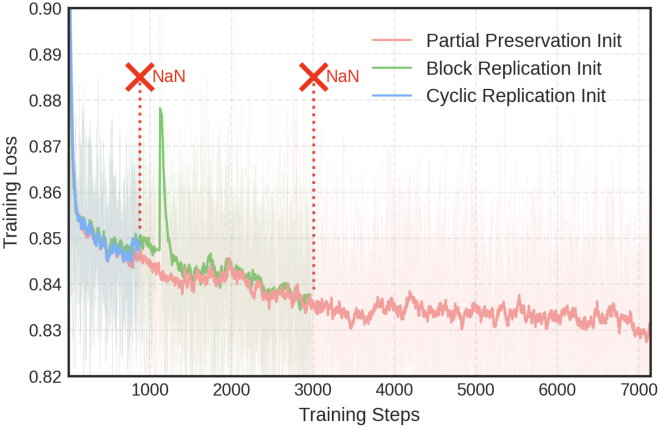
사전 학습된 모델과 확장된 모델의 $i$번째 layer의 파라미터를 각각 \(\theta_i \in \mathbb{R}^d\)와 \(\theta_i^\textrm{pre} \in \mathbb{R}^d\)라고 하자. 저자들은 파라미터 초기화를 위해 세 가지 접근 방식을 살펴보았다.
Partial Preservation Init은 사전 학습된 처음 $N$개의 layer를 보존하고, 추가 $M$개의 layer를 무작위로 초기화하는 방식이다. 이때 핵심 구성 요소는 특별히 처리된다. $i$번째 layer에 대해 다음과 같다.
\[\begin{equation} \theta_i = \begin{cases} \theta_i^\textrm{pre} & \textrm{if} \; i < N \\ \mathcal{N}(0, \sigma^2) & \textrm{if} \; i \ge N \end{cases} \end{equation}\]Cyclic Replication Init은 사전 학습된 layer를 주기적으로 반복한다. 확장된 모델의 $i$번째 layer에 대해 다음과 같이 초기화한다.
\[\begin{equation} \theta_i = \theta_{i \textrm{ mod } N}^\textrm{pre} \end{equation}\]Block Replication Init은 사전 학습된 각 layer를 연속된 layer로 확장한다. 확장 비율이 $r = M/N$일 때, 사전 학습된 $i$번째 layer에 대해 $r$개의 연속된 layer를 초기화한다.
\[\begin{equation} \theta_{ri+j} = \theta_i^\textrm{pre}, \quad \textrm{for} \; j \in [0, r-1], \, i \in [0, N-1] \end{equation}\]안정성 향상
모든 초기화 전략에서 학습 안정성을 보장하기 위해, linear self-attention 및 cross-attention 모듈 모두에서 query 및 key 성분에 대한 layer normalization를 통합했다. 이 정규화 기법은 다음과 같은 이유로 매우 중요하다.
- 학습 초기 단계에서 어텐션 계산을 안정화한다.
- 새로운 layer를 통합할 때 발생할 수 있는 gradient 불안정성을 방지한다.
- 모델 품질을 유지하면서 빠른 적응을 가능하게 한다.
항등 매핑 초기화
새로운 layer에 대하여 self-attention과 cross-attention의 output projection, 그리고 MLP block의 마지막 point-wise convolution을 0으로 초기화한다. 이러한 초기화는 새로운 transformer block이 초기에 항등 함수처럼 동작하도록 보장한다. 이를 통해, 학습 시작 시 사전 학습된 모델의 동작을 정확하게 보존하고, 알려진 좋은 해로부터 안정적인 최적화 경로를 확보한다.
디자인 선택
이러한 전략들 중에서, 저자들은 단순성과 안정성을 고려하여 Partial Preservation Init을 채택했다. 이러한 선택은 자연스러운 작업 분담을 가능하게 한다. 사전 학습된 $N$개의 layer는 feature 추출 능력을 유지하는 반면, 무작위로 초기화된 $M$개의 layer는 항등 매핑부터 시작하여 이러한 표현을 점진적으로 개선하는 방법을 학습한다.
2. Memory-Efficient CAME-8bit Optimizer
저자들은 CAME와 AdamW-8bit를 기반으로 효율적인 대규모 모델 학습을 위한 CAME-8bit를 제안하였다. CAME은 2차 모멘텀의 행렬 분해를 통해 AdamW 대비 메모리 사용량을 절반으로 줄여 특히 linear layer와 convolution layer에서 효율적이다. 1차 모멘텀에 대해 block-wise 8-bit quantization을 적용하여 CAME을 더욱 확장하는 동시에, 최적화 안정성을 유지하기 위해 중요 통계에 대한 32비트 정밀도를 유지한다. 이러한 하이브리드 방식은 optimizer의 메모리 사용량을 AdamW의 약 1/8로 줄여 수렴 특성 저하 없이 큰 모델의 학습을 가능하게 한다.
Block-wise Quantization Strategy
Linear layer와 1$\times$1 convolution layer에서 16K 이상의 파라미터를 갖는 큰 행렬만 quantization하는 선택적 방식을 채택하였다. 이러한 layer들은 optimizer의 메모리 사용량을 크게 차지하기 때문이다. 크기가 2,048인 각 block에 대해 로컬한 통계적 속성을 유지하기 위해 독립적인 scaling factor를 계산한다. 1차 모멘텀 값을 나타내는 텐서 블록 $x \in \mathbb{R}^n$이 주어지면, quantization function $q(x)$는 각 값을 8비트 정수로 매핑한다.
\[\begin{equation} q(x) = \textrm{round} \left( \frac{x - \textrm{min}(x)}{\textrm{max}(x) - \textrm{min}(x)} \times 255 \right) \end{equation}\]($\textrm{min}(x)$과 $\textrm{max}(x)$는 각각 block의 최소값과 최대값, $\textrm{round}(\cdot)$는 정수로 반올림)
이 linear quantization은 각 block 내 값의 상대적인 크기를 보존하는 동시에 값당 8비트로 압축한다.
Hybrid Precision Design
최적화 안정성을 유지하기 위해 2차 통계량을 32비트 정밀도로 유지한다. 이는 적절한 gradient scaling에 필수적이기 때문이다. CAME의 행렬 분해를 활용하면 이러한 통계량은 이미 메모리 효율적이다. 입력 차원이 \(d_\textrm{in}\)이고 출력 차원이 \(d_\textrm{out}\)인 linear layer의 경우, 2차 모멘텀 저장량이 \(O(d_\textrm{in} \times d_\textrm{out})\)에서 \(O(d_\textrm{in}+d_\textrm{out})\)으로 줄어들어 전체 메모리 사용량에 대한 정밀도의 중요성이 줄어든다.
이러한 하이브리드 방식은 CAME의 수렴 특성을 유지하면서 메모리 사용량을 줄인다. 메모리 절감은 다음과 같이 공식화할 수 있다.
\[\begin{equation} M_\textrm{saved} = \sum_{l \in \mathcal{L}} (n_l \times 24) \textrm{bytes} \end{equation}\]($\mathcal{L}$은 quantization이 적용된 layer 집합, $n_k$은 layer $l$의 파라미터 개수)
실제로는 작은 layer는 32비트 정밀도를 유지하고, 2차 통계량도 32비트 정밀도로 유지되며, quantization 메타데이터로 인한 추가 오버헤드가 있기 때문에 실제 메모리 절약량은 \(M_\textrm{saved}\)보다 약간 더 낮다.
3. Model Depth Pruning
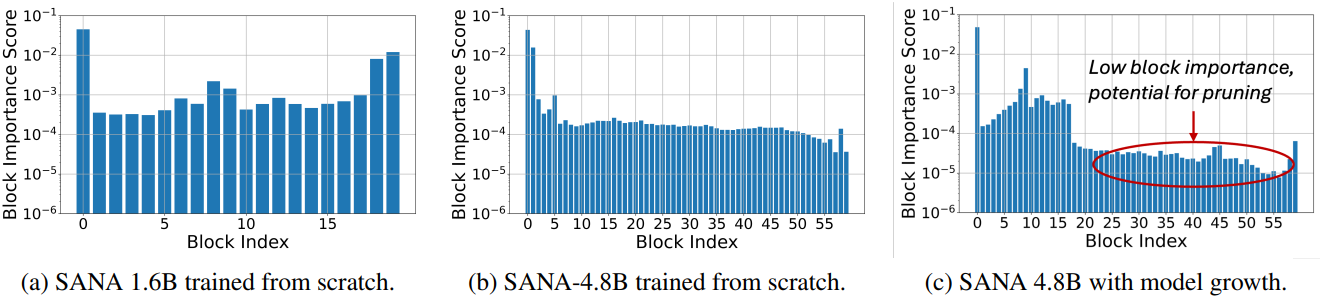
대규모 모델에서 효과성과 효율성의 균형을 맞추기 위해, 대규모 모델을 다양한 작은 구성으로 효율적으로 압축하면서도 비슷한 품질을 유지하는 모델 depth pruning 방식을 도입하였다. 저자들은 LLM용 transformer 압축 기술인 Minitron에서 영감을 받아, 입출력 유사성 패턴을 통해 block 중요도를 분석하였다.
\[\begin{equation} \textrm{BI}_i = 1 - \mathbb{E}_{X, t} \frac{\textbf{X}_{i,t}^\top \textbf{X}_{i+1, t}}{\| \textbf{X}_{i,t} \|_2 \| \textbf{X}_{i+1, t} \|_2} \end{equation}\](\(\textbf{X}_{i,t}\)는 $i$번째 transformer block의 입력)
Diffusion timestep과 100개의 다양한 프롬프트를 포함하는 calibration 데이터셋에 대하여 block 중요도를 계산하고 평균화한다. 그림 5c에서 볼 수 있듯이, block 중요도는 앞쪽 block과 뒷쪽 block에서 더 높으며, 앞쪽 block은 latent 분포를 diffusion 분포로 바꾸고 뒷쪽 block은 다시 원래대로 분포를 바꾼다. 중간 block은 일반적으로 입력 feature와 출력 feature 간의 유사도가 더 높다. 정렬된 block 중요도를 기반으로 transformer block을 pruning한다.
Block을 pruning하면 고주파 디테일이 점차 손상된다. 따라서 pruning 후에는 정보 손실을 보상하기 위해 모델을 더욱 fine-tuning한다. 구체적으로, pruning된 모델에 큰 모델과 동일한 학습 loss를 사용한다. Pruning된 모델을 100 step만 fine-tuning해도, pruning된 1.6B 모델은 원래 4.8B 모델과 비슷한 품질을 달성하고 SANA-1.0 1.6B 모델보다 더 우수한 성능을 보인다.
4. Inference-Time Scaling
Scaling Denoising Steps v.s. Scaling Samplings
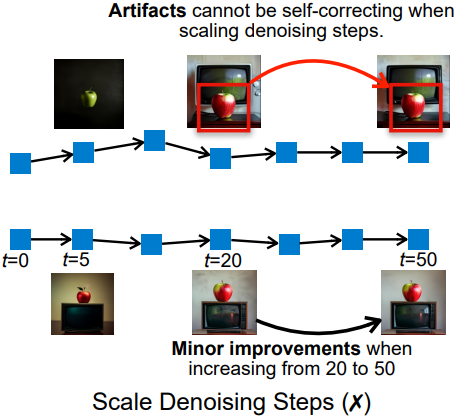
SANA 및 기타 여러 diffusion model의 경우, inference-time 계산을 scaling하는 자연스러운 방법은 denoising step 수를 늘리는 것이다. 그러나 denoising step을 늘리는 것은 두 가지 이유로 scaling에 적합하지 않다.
- Denoising step을 추가해도 오류를 자체적으로 수정할 수 없다. 위 그림에서 볼 수 있듯이, 초기 step에서 잘못 배치된 물체는 이후 step에서는 변경되지 않는다.
- 생성 품질이 빠르게 정체기에 도달한다. SANA는 단 20 step만으로 시각적으로 만족스러운 결과를 생성하며, step 수를 2.5배 증가시켜도 시각적으로 큰 개선이 나타나지 않는다.
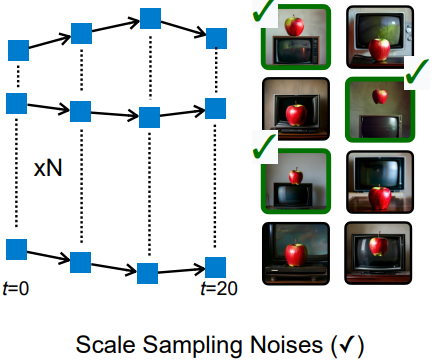
반면, 샘플링 후보 수를 scaling하는 것이 더 유망한 방향이다. 위 그림에서 볼 수 있듯이, SANA 1.6B는 여러 번 시도했을 때 어려운 문제에 대해 정확한 결과를 생성할 수 있다. 충분한 시도 기회가 주어지면 여전히 만족스러운 답을 제공할 수 있다. 따라서 더 많은 이미지를 생성하고 결과의 점수를 매길 VLM을 도입하였다.
Visual Language Model (VLM) as the Judge
주어진 프롬프트에 가장 잘 맞는 이미지를 찾으려면 텍스트와 이미지를 모두 이해하는 모델이 필요하다. CLIP이나 SigLIP과 같은 인기 모델은 멀티모달 기능을 제공하지만, context window가 작기 때문에 (CLIP은 77, SigLIP은 66) 효과가 제한적이다. 이러한 제한은 SANA가 일반적으로 길고 자세한 설명을 입력으로 사용하기 때문에 문제가 된다.

저자들은 이 문제를 해결하기 위해, 생성된 이미지에 대한 프롬프트 매칭을 평가하기 위해 Visual Language Model (VLM)을 탐색했다. 기존 모델이나 API를 적용하는 대신, 이미지 점수를 매기도록 NVILA-2B를 학습시킨 VILA-Judge를 사용하였다. 저자들은 GenEval 스타일로 생성된 프롬프트를 사용하여 200만 개의 프롬프트 매칭 데이터셋을 생성했다. GenEval evalset에 이미 존재하는 프롬프트는 제외하고, overfitting을 방지하기 위해 Flux-Schnell을 사용하여 이미지를 생성했다. 그런 다음, 이 이미지들을 다음과 같은 멀티모달 대화 형식으로 변환했다.
User: You are an AI assistant specializing in image analysis and ranking. Your task is to analyze and compare image based on how well they match the given prompt. <image> The given prompt is: <prompt>. Please consider the prompt and the image to make a decision and response directly with ‘yes’ or ‘no’
VILA-Judge: ‘yes’ / ‘no’.
Fine-tuning된 VILA-Judge는 이미지가 프롬프트와 얼마나 잘 일치하는지 효과적으로 평가하고 프롬프트와 일치하지 않는 이미지를 강력하게 필터링한다. Inference 시에는 각 라운드에서 두 이미지를 비교하여 상위 $N$개의 후보를 결정한다.
- VILA-Judge가 ‘yes’와 ‘no’로 하나씩 대답하면, ‘yes’로 대답한 이미지를 선택한다.
- VILA-Judge가 ‘yes’ 또는 ‘no’로 모두 응답하면 더 높은 신뢰도(logprob)의 이미지를 선택한다.
이러한 토너먼트 스타일 비교는 프롬프트 불일치 이미지를 강력하게 걸러내고 GenEval 점수를 높인다.
Experiments
- 모델 아키텍처
- layer 수: 60
- 채널 차원: layer당 2240 (SANA 1.6B와 동일)
- FFN 차원: 5600 (SANA 1.6B와 동일)
- 학습 디테일
- GPU: NVIDIA A100 64개
- learning rate: 사전 학습 $1 \times 10^{-4}$, fine-tuning $2 \times 10^{-5}$
- global batch size: 1024 ~ 4096
1. Main Results
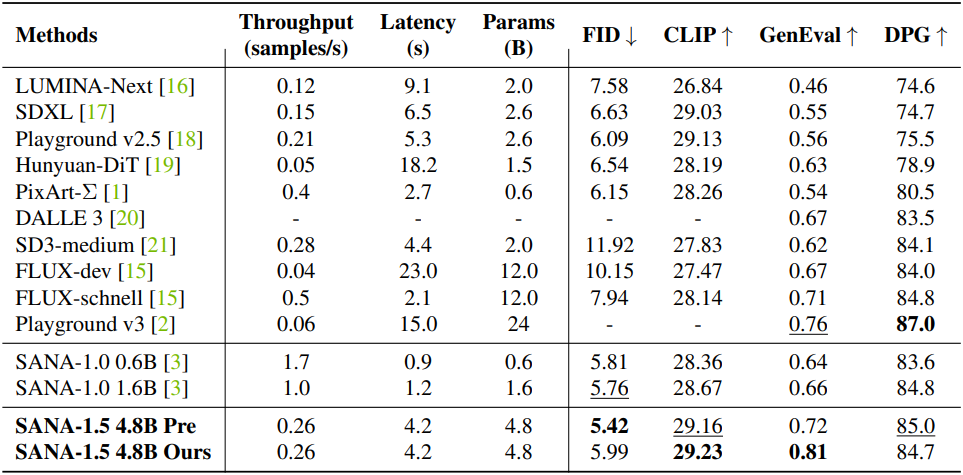
다음은 SOTA 방법들과 효율성 및 성능을 비교한 결과이다.
다음은 pruning한 SANA 모델에 대한 성능을 비교한 결과이다.


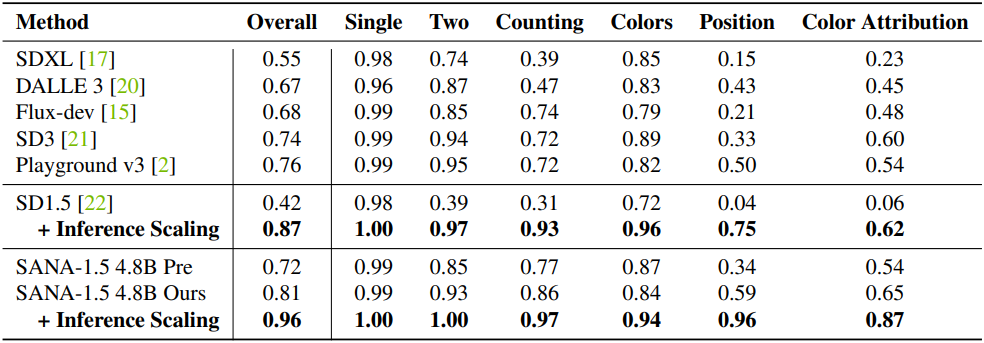
다음은 GenEval 벤치마크에 대한 디테일한 평가 결과이다.
다음은 SOTA 방법들과 생성 결과를 비교한 것이다.

2. Analysis
다음은 optimizer에 따른 학습 loss 변화를 비교한 결과이다.
다음은 초기화 전략에 따른 학습 loss 변화를 비교한 결과이다.
다음은 block importance (BI)를 분석한 결과이다.
다음은 모델 스케일에 따른 성능을 비교한 결과이다.
다음은 inference-time scaling 결과이다.