[논문리뷰] SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
ICLR 2025. [Paper] [Page] [Github]
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, Song Han
NVIDIA | MIT | Tsinghua University
14 Oct 2024

Introduction
본 논문은 1024$\times$1024에서 4096$\times$4096까지의 해상도에서 고품질 이미지를 효율적으로 학습시키고 생성하도록 설계된 파이프라인인 Sana를 제안하였다. 지금까지 PixArt-Σ를 제외하고는 4K 해상도 이미지 생성을 직접 다룬 논문은 없다. PixArt-Σ는 4K 해상도에 가까운 3840$\times$2160 이미지를 생성하는 데 국한되며 이러한 고해상도 이미지를 생성할 때 비교적 느리다. 저자들은 효율적인 고해상도 이미지 생성 모델을 위해 몇 가지 핵심 설계를 제안하였다.
- Deep Compression Autoencoder
- 기존 모델들의 오토인코더(AE)의 scaling factor는 8이었지만 (AE-F8), scaling factor가 32인 오토인코더(AE-F32)를 사용하였다. AE-F32는 AE-F8에 비해 16배 적은 latent 토큰을 사용하기 때문에, 고해상도 이미지의 효율적인 학습과 생성에 매우 중요하다.
- Linear DiT
- 계산복잡도가 $O(N^2)$인 기존 DiT의 attention 모듈을 모두 $O(N)$인 linear attention으로 변경하였다.
- 3$times3 depth-wise convolution을 MLP에 통합한 Mix-FFN으로 토큰들의 로컬 정보를 집계하였다.
- Mix-FFN의 사용으로 인해 품질의 손실 없이 positional embedding을 제거할 수 있게 되었다 (NoPE).
- 작은 LLM을 텍스트 인코더로 사용
- 기존 모델들이 CLIP이나 T5를 텍스트 인코더로 사용하는 것과 달리, LLM을 텍스트 인코더로 사용하여 프롬프트에 대한 이해 및 추론 능력을 향상시켰다.
- 이미지-텍스트 정렬을 향상시키기 위해, complex human instruction (CHI)을 설계하였여 LLM의 강력한 instruction-following, in-context learning, 추론 능력을 활용하였다.
- 효율적인 학습 및 Inference 전략
- 텍스트와 이미지 간의 일관성을 개선하기 위해, 여러 VLM을 사용하는 자동 레이블링 및 학습 전략을 제안하였다.
- 확률에 따라 각 이미지마다 높은 CLIP score의 캡션을 동적으로 선택하는 CLIP score 기반 학습 전략을 제안하였다.
- 널리 사용되는 Flow-Euler-Solver와 비교하여, inference 시 샘플링 step 수를 2~2.5배 줄이는 동시에 더 나은 결과를 얻는 Flow-DPM-Solver를 제안하였다.
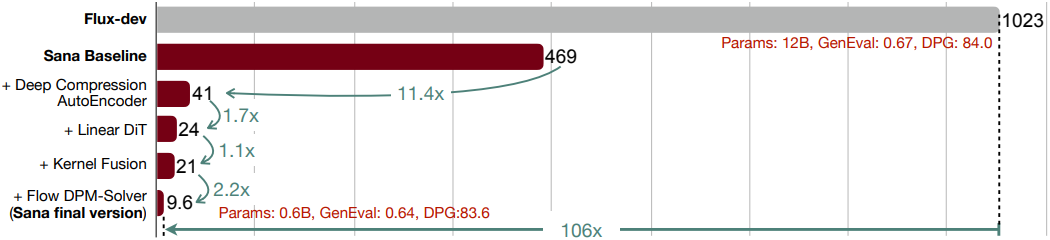
Sana-0.6B는 SOTA 방법인 FLUX보다 4K 이미지 생성의 경우 100배 이상, 1K 해상도의 경우 40배 더 빠른 처리량을 달성하는 동시에, 많은 벤치마크에서 경쟁력 있는 결과를 제공한다. 또한, 저자들은 Sana-0.6B를 quantization하여 edge device에 배포하였으며, NVIDIA 4090 GPU에서 1024$\times$1024 해상도 이미지를 생성하는 데 0.37초만 소요된다.
Methods
1. Deep Compression Autoencoder
Latent diffusion model은 $\mathbb{R}^{H \times W \times 3}$의 이미지를 오토인코더를 통해 $\mathbb{R}^{\frac{H}{F} \times \frac{W}{F} \times 3}$로 압축하며, 여기서 $F$는 down-sampling factor이고 $C$는 채널 수이다. DiT 기반의 diffusion model의 경우, 패치 크기가 $P$이면 latent feature들이 $P \times P$ 크기의 패치들로 그룹화되어, 최종적으로 $\frac{H}{PF} \times \frac{H}{PF}$개의 토큰이 된다 (일반적으로 $P = 2$).
오토인코더 디자인 철학
고해상도 이미지는 자연스럽게 더 많은 중복 정보를 포함하기 때문에, 본 논문은 압축률을 더 공격적으로 높이는 것을 목표로 하였다. 또한, 고해상도 이미지의 효율적인 학습 및 inference는 오토인코더의 높은 압축률을 필요로 한다.
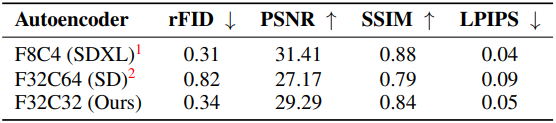
위 표는 MJHQ-30K에서 여러 오토인코더의 재구성 품질을 비교한 결과이다. SDv1.5는 AE-F32C64를 사용하려고 시도했지만, 품질은 AE-F8C4보다 상당히 낮다. Sana의 AE-F32C32는 이러한 품질 격차를 효과적으로 메우고 SDXL의 AE-F8C4와 비슷한 재구성 능력을 달성하였다.
또한, 패치 크기 $P$를 늘려 토큰 수를 줄이는 대신, 오토인코더가 압축에 대한 모든 책임을 지도록 하여 latent diffusion model이 noise 제거에만 집중할 수 있게 하는 것이 중요하다. 따라서 $F = 32$, $C = 32$인 오토인코더를 개발하고 $P = 1$로 diffusion model을 실행한다 (AE-F32C32P1). 이 디자인은 토큰 수를 4배 줄여 GPU 메모리 요구 사항을 낮추고 학습 및 inference 속도를 크게 개선한다.
Ablation
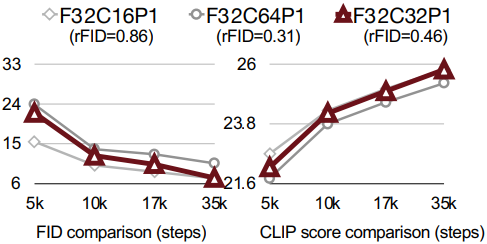
다음은 1024$\times$1024 이미지에 대하여 동일한 토큰 수 32$\times$32로 압축하였을 때의 FID와 CLIP score이다. $P$를 늘렸을 때보다 $F$를 늘렸을 때 재구성 품질이 더 좋다.
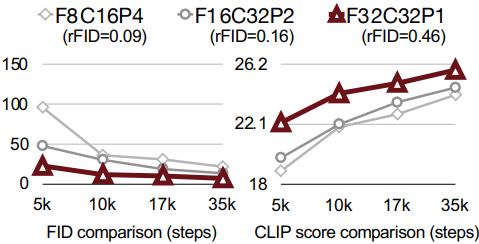
다음은 채널 수에 따른 효과를 나타낸 그래프이다. 채널 수가 적으면 더 빨리 수렴하지만 재구성 품질이 나빠진다. 반대로, 채널 수가 많으면 재구성 품질이 좋지만 수렴이 상당히 느려진다.
2. Efficient Linear DiT Design
Linear Attention block
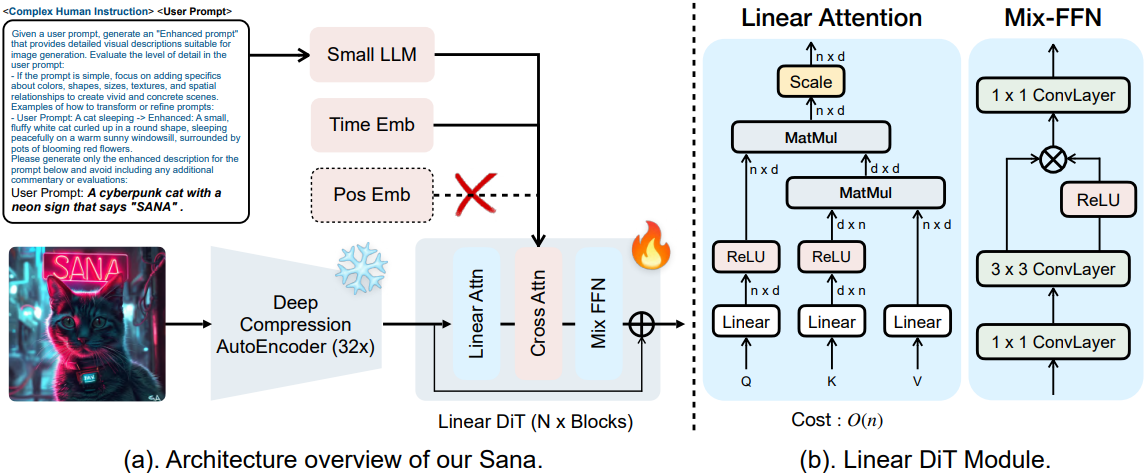
DiT에서 사용하는 self-attention은 $O(N^2)$의 계산 복잡도를 가지므로 고해상도 이미지를 처리할 때 계산 효율성이 낮고 상당한 오버헤드가 발생한다.
저자들은 계산 복잡도를 줄이기 위해 기존의 softmax attention을 ReLU linear attention으로 대체했다. ReLU linear attention은 주로 고해상도 예측 task에서 탐구되었지만, 본 논문에서는 이미지 생성에 linear attention을 사용하였다.
\[\begin{equation} O_i = \sum_{j=1}^N \frac{\textrm{ReLU} (Q_i) \textrm{ReLU} (K_j)^\top V_j}{\sum_{j=1}^N \textrm{ReLU} (Q_i) \textrm{ReLU} (K_j)^\top} = \frac{\textrm{ReLU} (Q_i) (\sum_{j=1}^N \textrm{ReLU} (K_j)^\top V_j)}{\textrm{ReLU} (Q_i) (\sum_{j=1}^N \textrm{ReLU} (K_j)^\top)} \end{equation}\]위 식에서 볼 수 있듯이, 각 query에 대한 attention을 계산하는 대신, 공유 항 \(\sum_{j=1}^N \textrm{ReLU} (K_j)^\top V_j\)와 \(\sum_{j=1}^N \textrm{ReLU} (K_j)^\top\)를 한 번만 계산한다. 이러한 공유 항은 각 query에 재사용될 수 있으므로 메모리와 계산 모두에서 계산 복잡도가 $O(N)$이 된다.
Mix-FFN block
EfficientViT에서 논의한 대로, linear attention 모델은 softmax attention 모델에 비해 계산 복잡도가 낮지만, non-linear similarity function이 없어 성능이 좋지 못할 수 있다. 저자들은 이미지 생성에서도 비슷한 현상을 관찰했는데, linear attention 모델은 결국 비슷한 성능을 달성했지만 수렴 속도가 훨씬 느리다.
저자들은 학습 효율성을 더욱 개선하기 위해, 원래의 MLP-FFN을 Mix-FFN으로 대체했다. Mix-FFN은 inverted residual block, 3$\times$3 depth-wise convolution, Gated Linear Unit (GLU)으로 구성된다. Depth-wise convolution을 통해 ReLU linear attention의 약한 로컬 정보 캡처 능력을 보완한다.
위치 임베딩 없는 DiT (NoPE)
SegFormer 논문에 따르면, zero padding을 사용한 3$\times$3 convolution을 모델에 도입하면 위치 정보를 암시적으로 통합할 수 있다. 위치 임베딩을 사용하는 이전의 DiT 기반 방법과 달리, Sana는 DiT에서 위치 임베딩을 완전히 생략한 최초의 디자인인 NoPE를 사용한다.
Triton을 사용한 학습 및 inference 가속
저자들은 linear attention을 더욱 가속화하기 위해, Triton을 사용하여 linear attention block의 forward pass와 backward pass에 대한 커널을 융합하여 학습 및 inference 속도를 높였다. 모든 element-wise 연산을 행렬 곱셈으로 융합하여 데이터 전송과 관련된 오버헤드를 줄였다.
3. Text Encoder Design
왜 T5를 decoder-only LLM으로 대체하여 텍스트 인코더로 사용할 수 있을까?
2019년에 제안된 방법인 T5와 비교할 때, decoder-only LLM은 강력한 추론 능력을 가지고 있으며, Chain-of-Thought (CoT)과 In-context-learning (ICL)을 사용하여 복잡한 instruction을 따를 수 있다. 또한 Gemma-2와 같은 일부 소규모 LLM은 매우 효율적이면서도 대규모 LLM의 성능에 필적할 수 있다. 따라서 저자들은 Gemma-2를 텍스트 인코더로 채택하였다.
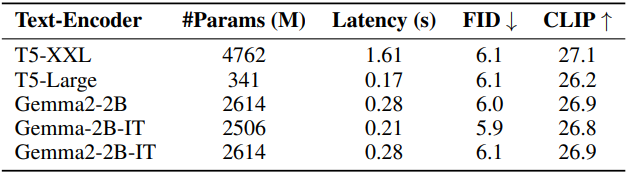
위 표에서 볼 수 있듯이, T5-XXL에 비해 Gemma-2-2B의 inference 속도는 6배 더 빠르고, Gemma-2B의 성능은 Clip Score와 FID 측면에서 T5-XXL과 비슷하다.
LLM을 텍스트 인코더로 사용하여 안정화된 학습
Gemma2 디코더의 마지막 레이어의 feature를 텍스트 임베딩으로 추출한다. 저자들은 T5와 동일한 방법으로 텍스트 임베딩을 key, value, 이미지 토큰(query)으로 cross-attention에 사용하면 극단적인 불안정성이 발생하고 loss가 자주 NaN이 되는 것을 발견했다.
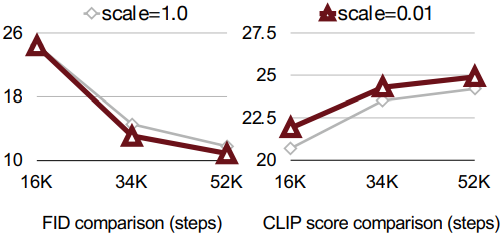
저자들은 T5의 텍스트 임베딩 분산이 decoder-only LLM보다 몇 자릿수 더 작은 것을 발견했는데, 이는 텍스트 임베딩 출력에 큰 절대값이 많이 있음을 나타낸다. 이 문제를 해결하기 위해, 텍스트 인코더 뒤에 normalization layer (RMSNorm)를 추가하여 텍스트 임베딩의 분산을 1.0으로 정규화한다. 또한 저자들은 학습 가능한 scale factor를 0.01로 초기화하고 텍스트 임베딩에 곱하여 모델 수렴을 더욱 가속화하는 유용한 트릭을 발견했다.
텍스트-이미지 정렬 개선을 위한 Complex Human Instruction (CHI)
Gemma는 T5보다 더 나은 instruction following 능력을 가지고 있으며, 이를 더욱 활용하여 텍스트 임베딩을 강화할 수 있다. Gemma는 채팅 모델이므로 프롬프트 자체를 추출하고 향상시키는 데 집중할 수 있도록 instruction을 추가해야 한다.

LiDiT는 간단한 인간 instruction과 사용자 프롬프트를 결합한 최초의 모델이다. 저자들은 LLM의 in-context learning을 사용하여 LiDiT를 더욱 확장하여 complex human instruction (CHI)을 설계하였다. 위 표에서 볼 수 있듯이, 학습하는 동안 CHI를 통합하면 이미지-텍스트 정렬 능력을 더욱 개선할 수 있다.

또한, 위 그림에서 볼 수 있듯이, “a cat”과 같은 짧은 프롬프트가 주어졌을 때 CHI는 모델이 더 안정적인 콘텐츠를 생성하는 데 도움이 된다. 반면, CHI 없이 학습한 모델은 종종 프롬프트와 관련 없는 콘텐츠를 출력한다.
Efficient Training/Inference
1. Data Curation and Blending
다중 캡션 자동 레이블링 파이프라인
각 이미지에 대해 원래 프롬프트가 포함되어 있든 없든, 저자들은 4개의 VLM을 사용하여 레이블을 붙였다 (VILA-3B/13B, InternVL2-8B/26B). 여러 개의 VLM을 사용하면 캡션을 더 정확하고 다양하게 만들 수 있다.
CLIP score 기반 캡션 샘플러
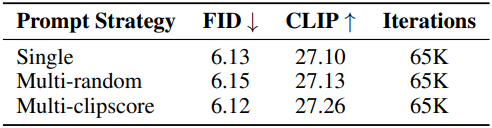
한 이미지에 대해 여러 캡션이 존재하므로 그 중 하나의 캡션을 선택해야 한다. 단순한 접근 방식은 캡션을 무작위로 선택하는 것인데, 이는 낮은 품질의 텍스트를 선택하여 모델 성능에 영향을 미칠 수 있다.
저자들은 CLIP score 기반 샘플러를 제안하였다. 먼저 이미지에 해당하는 모든 캡션에 대한 CLIP score $c_i$를 계산한 다음, 샘플링할 때 $c_i$에 기반한 확률에 따라 샘플링한다.
\[\begin{equation} P(c_i) = \frac{\exp (c_i / \tau)}{\sum_{j=1}^N \exp (c_j / \tau)} \end{equation}\]Temperature $\tau$는 샘플링 강도를 조정하는 데 사용할 수 있다. $\tau$가 0에 가까우면 CLIP score가 가장 높은 텍스트만 샘플링된다. 아래 표는 다양한 캡션이 semantic 정렬을 개선하는 동시에 이미지 품질에 최소한의 영향을 미친다는 것을 보여준다.
계단식 해상도 학습
AE-F32C32P1을 사용하기 때문에, 256px 사전 학습을 건너뛰고 512px에서 사전 학습을 시작하여 모델을 1024px, 2K, 4K 해상도로 점진적으로 fine-tuning한다. 256px의 이미지는 너무 많은 디테일을 잃어버려 이미지-텍스트 정렬 측면에서 모델의 학습 속도가 느려지기 때문에, 256px에서 사전 학습하는 기존 방식은 비용적으로 효율적이지 못하다.
2. FLow-based Training/Inference
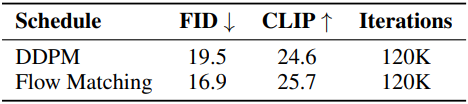
Flow-based Training
Noise 예측에 의존하는 DDPM과 달리 Rectified Flow (RF)와 EDM은 각각 데이터 예측과 velocity 예측을 사용하여 더 빠른 수렴과 향상된 성능을 가져왔다. Noise 예측에서 데이터 또는 velocity 예측으로의 전환은 $t = T$ 근처에서 매우 중요한데, noise 예측은 불안정성을 초래할 수 있는 반면, 데이터 또는 velocity 예측은 보다 정확하고 안정적인 추정치를 제공한다. $t = T$ 근처에서 attention activation이 더 강해 $t = T$에서의 정확한 예측이 중요하다. 이러한 전환은 샘플링 중 누적 오차를 효과적으로 줄여 더 빠른 수렴과 향상된 성능을 가져온다.
Flow-based Inference
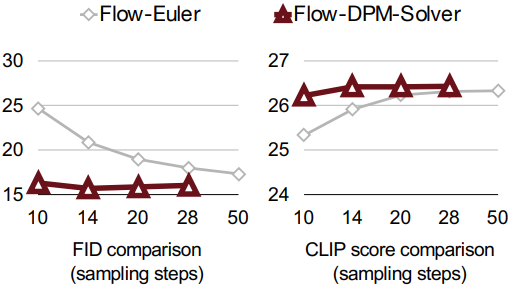
저자들은 원래의 DPM-Solver++를 수정하여 RF 공식을 적용하고 Flow-DPM-Solver라고 명명했다. 주요 변경 사항은 scaling factor \(\alpha_t\)를 \(1 - \sigma_t\)로 대체하는 것이다. 여기서 \(\sigma_t\)는 변경되지 않지만 timestep은 SD3를 따라 더 낮은 SNR을 위해 [1, 1000] 대신 [0, 1]에 대해 재정의된다.
또한 Sana는 원래 DPM-Solver++의 데이터 예측과 다르게 velocity field를 예측한다. 구체적으로, 데이터는 $x_0$는 다음 식을 통해 계산된다.
\[\begin{aligned} x_t &= \alpha_t x_0 + \sigma_t \epsilon \\ &= (1 - \sigma_t) x_0 + \sigma_t (x_0 + v_\theta (x_t, t)) \\ &= x_0 + \sigma_t \cdot v_\theta (x_t, t) \\ \therefore x_0 &= x_t - \sigma_t \cdot v_\theta (x_t, t) \end{aligned}\]결과적으로, Flow-DPM-Solver는 더 나은 성능을 보이면서 14~20 step에서 수렴하는 반면, Flow-Euler 샘플러는 더 나쁜 결과를 보이면서 수렴에 28~50 step이 필요하다.
On-device Deployment
저자들은 edge device를 위해 INT8로 모델을 quantization하였다. Activation에는 per-token symmetric INT8 quantization을 채택하고, 가중치에는 per-channel symmetric INT8 quantization을 채택하였다. 또한, FP16 모델과 높은 semantic 유사성을 유지하기 위해, cross-attention block 내의 normalization layer, linear attention, key-value projection layer들은 FP16로 유지하였다. 또한, kernel fusion을 적용한 커스텀 CUDA 커널을 통해 속도를 향상시켰다.
다음은 quantization 전후에 대하여 노트북 GPU에서 1024px 이미지를 생성하는 경우의 속도와 이미지 품질을 비교한 표이다.

Experiments

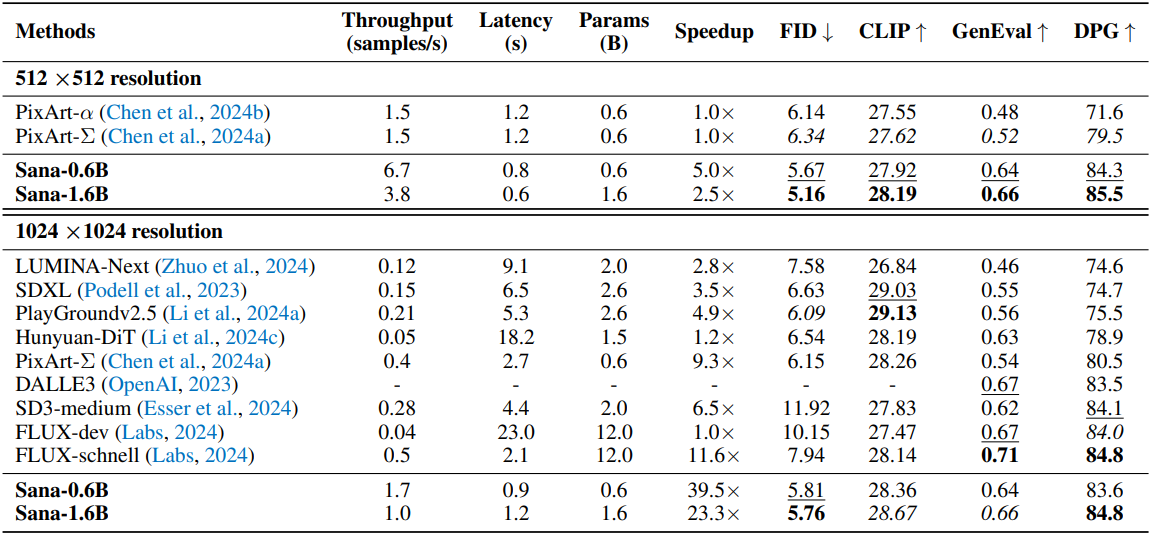
1. Performance comparison
다음은 SOTA 방법들과 성능과 효율성을 비교한 결과이다. (속도는 A100 GPU에서 FP16 모델로 측정)

2. Analysis
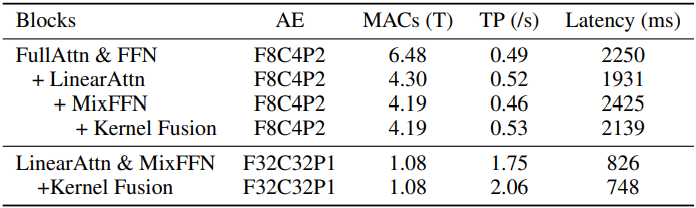
다음은 Sana 블록 디자인에 대한 ablation 결과이다. (MACs는 forward pass 한 번에 대한 multiply-accumulate 연산 수, TP는 처리량)