[논문리뷰] SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory
arXiv 2024. [Paper] [Page] [Github]
Cheng-Yen Yang, Hsiang-Wei Huang, Wenhao Chai, Zhongyu Jiang, Jenq-Neng Hwang
University of Washington
18 Nov 2024
Introduction
Segment Anything Model (SAM)은 segmentation task에서 인상적인 성능을 보여주었다. 최근 SAM 2는 스트리밍 메모리 아키텍처를 통합하여 긴 시퀀스에서 컨텍스트를 유지하면서 동영상 프레임을 순차적으로 처리할 수 있게 해준다. SAM 2는 Video Object Segmentation (VOS) task에서 놀라운 성능을 보여주었지만, Visual Object Tracking (VOT) 시나리오에서는 여전히 어려움에 직면해 있다.
VOT의 주요 관심사는 가려짐(occlusion), 모양 변화, 유사한 object의 존재에도 불구하고 일관된 object identity와 위치를 유지하는 것이다. 그러나 SAM 2는 후속 프레임의 마스크를 예측할 때 종종 모션 신호를 무시하여 빠른 이동이나 복잡한 상호 작용이 있는 시나리오에서 부정확성을 초래한다. 이러한 한계점은 특히 혼잡한 장면에서 두드러지는데, SAM 2는 공간적 및 시간적 일관성보다 외형 유사성을 우선시하는 경향이 있어 추적 오류가 발생한다.

위 그림에서 볼 수 있듯이 두 가지 일반적인 실패 패턴이 있다.
- 혼잡한 장면에서의 혼란
- Occlusion 중 비효율적인 메모리 활용
이러한 한계를 해결하기 위해, 본 논문은 SAM 2의 예측 프로세스에 모션 정보를 통합하는 것을 제안하였다. Object 궤적의 이력을 활용함으로써, 시각적으로 유사한 object를 구별하고 가려짐이 있는 경우에도 추적 정확도를 유지하는 모델의 능력을 향상시킬 수 있다.
또한, SAM 2의 메모리 관리를 최적화하는 것이 중요하다. 메모리 뱅크에 최근 프레임을 무차별적으로 저장하는 현재 접근 방식은 object가 가려졌을 때에 해당하는 관련 없는 feature를 추가하여 추적 성능을 저하시킨다. 이러한 과제를 해결하는 것은 강력한 VOT를 위해 SAM 2의 풍부한 마스크 정보를 적용하는 데 필수적이다.
이를 위해, 본 논문은 SAMURAI (SAM-based Unified and Robust zero-shot visual tracker with motion-Aware Instance-level memory)를 제안하였다. 제안된 방법은 두 가지 주요 발전을 통합하였다.
- 마스크 선택을 개선하여 복잡한 시나리오에서 더 정확한 object 위치 예측을 가능하게 하는 모션 모델링 시스템
- 하이브리드 스코어링 시스템을 활용한 최적화된 메모리 선택 메커니즘: mask affinity score, object score, motion score의 결합으로 추적 신뢰성 향상
Segment Anything Model 2
프롬프트 인코더
프롬프트 인코더는 SAM을 따르며, 여기서는 sparse(점, bounding box)와 dense(마스크)의 두 가지 유형의 프롬프트를 사용한다. 프롬프트 인코더에서 출력되는 프롬프트 토큰은 \(x_\textrm{prompt} \in N_\textrm{tokens} \times d\)로 표현할 수 있다. 첫 번째 프레임 $t_0$의 대상 object의 GT bounding box가 제공되는 VOT의 경우, 왼쪽 위와 오른쪽 아래 점에 대한 위치 인코딩을 프롬프트 인코더의 입력으로 사용하는 반면 나머지 시퀀스는 이전 프레임의 예측 마스크 \(\bar{\mathcal{M}}_{t-1}\)을 입력으로 사용한다.
마스크 디코더
메모리 디코더는 프롬프트 인코더의 프롬프트 토큰과 함께 memory attention layer에서 생성된 메모리 조건부 이미지 임베딩을 입력으로 받도록 설계되었다. 그런 다음 multi-head branch는 예측 마스크 집합과 해당 mask affinity score \(s_\textrm{mask}\), 프레임에 대한 하나의 object score \(s_\textrm{obj}\)를 출력으로 생성할 수 있다.
\[\begin{equation} \mathbb{M} = \{(\mathcal{M}_0, s_{\textrm{mask},0}), (\mathcal{M}_1, s_{\textrm{mask},1}), \ldots\} \end{equation}\]SAM 2의 affinity score 예측은 마스크의 전반적인 신뢰도를 나타낼 수 있으므로 MAE loss로 학습되는 반면, object 예측은 마스크가 프레임에 존재해야 하는지 여부를 결정하기 위해 cross-entropy loss로 학습된다. 원래 구현에서 최종 출력 마스크 \(\bar{\mathcal{M}} = \mathcal{M}_i\)는 \(N_\textrm{mask}\)개의 출력 마스크 중 가장 높은 affinity score를 기반으로 선택된다.
\[\begin{equation} i = \underset{i \in [0, N_\textrm{mask}-1]}{\arg \max} s_{\textrm{mask}, i} \quad \textrm{where} \; s_{\textrm{obj}, i} > 0 \end{equation}\]그러나 affinity score는 visual tracking의 경우 매우 강력한 지표가 아니며, 특히 유사한 object가 서로 가려지는 혼잡한 시나리오에서는 그렇다. 본 논문은 대상의 모션을 추적하기 위해 추가적인 모션 모델링을 도입하고 예측 선택을 돕기 위해 motion score를 추가로 제공하였다.
Memory Attention Layer
Memory attention block은 먼저 프레임 임베딩으로 self-attention을 수행한 다음 이미지 임베딩과 memory bank의 콘텐츠 간에 cross-attention을 수행한다. 따라서 unconditional한 이미지 임베딩은 이전 출력 마스크, 이전 입력 프롬프트, object pointer들과 contextualize된다.
메모리 인코더 & Memory Bank
마스크 디코더가 출력 마스크를 생성한 후, 출력 마스크는 메모리 인코더에 전달되어 메모리 임베딩을 얻는다. 각 프레임이 처리된 후 새 메모리가 생성된다. 이러한 메모리 임베딩은 동영상 디코딩 중에 생성된 최신 메모리의 FIFO queue인 memory bank에 추가된다. 시간 $t$에서의 memory bank $B_t$를 다음과 같이 형성할 수 있다.
\[\begin{equation} B_t = [m_{t-1}, m_{t-2}, \ldots, m_{t-N_\textrm{mem}}] \end{equation}\]즉, 과거 \(N_\textrm{mem}\)개의 프레임들의 출력 $m$을 memory bank의 구성 요소로 사용한다.
이 간단한 고정 window 메모리 구현은 잘못된 또는 낮은 신뢰도 object를 인코딩하는 데 어려움을 겪을 수 있으며, 이로 인해 긴 시퀀스의 VOT task에서 오차가 상당히 전파된다. 제안된 motion-aware memory selection은 더 나은 memory feature를 유지하고 이미지 feature에 컨디셔닝할 수 있도록 원래 memory bank 구성을 대체한다.
Method
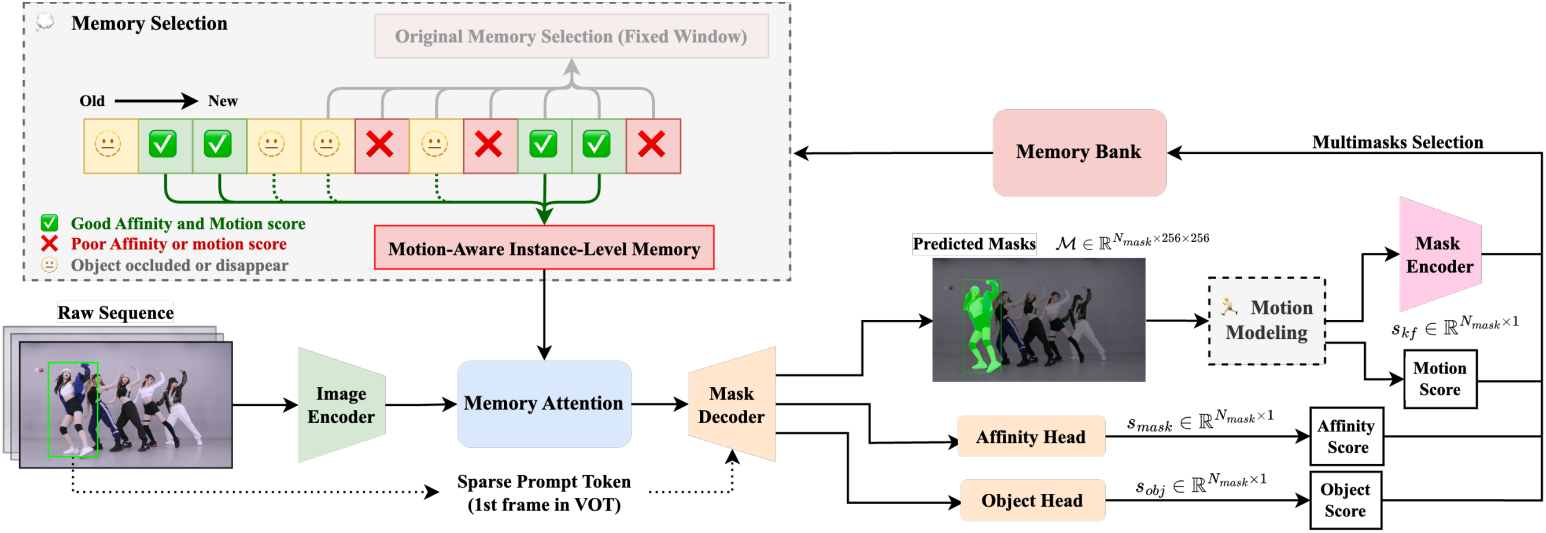
SAM 2는 Visual Object Tracking (VOT)과 Video Object Segmentation (VOS) task에서 강력한 성능을 보였다. 그러나 잘못되거나 신뢰도가 낮은 object를 실수로 인코딩하여 긴 시퀀스의 VOT에서 상당한 오차 전파를 초래할 수 있다.
위의 문제를 해결하기 위해 본 논문은 칼만 필터 (KF) 기반의 모션 모델링과, affinity score와 motion score를 결합한 하이브리드 스코어링 시스템을 기반으로 한 향상된 메모리 선택을 제안하였다. 이러한 향상은 복잡한 동영상에서 object를 정확하게 추적하는 모델의 능력을 강화하도록 설계되었다.
중요한 점은 이 접근 방식이 fine-tuning이나 추가 학습이 필요하지 않으며 기존 SAM 2 모델에 직접 통합할 수 있다는 것이다.
1. Motion Modeling
모션 모델링은 연관 모호성을 해결하는 Visual Object Tracking (VOT)와 Multiple Object Tracking (MOT)에 대한 효과적인 접근 방식이었다. 본 논문은 추적 정확도를 개선하는 데 선형 칼만 필터를 사용한 모션 모델링을 통합하였다.
VOT 프레임워크에서는 칼만 필터를 통합하여 bounding box 위치 및 차원 예측을 향상시키고, 이는 $N$개의 마스크 후보 중에서 가장 신뢰할 수 있는 마스크를 선택하는 데 도움이 된다.
State 벡터 $x$를 다음과 같이 정의한다.
\[\begin{equation} \mathbf{x} = [x, y, w, h, \dot{x}, \dot{y}, \dot{w}, \dot{h}]^\top \end{equation}\]($x$, $y$는 bounding box의 중심 좌표, $w$와 $h$는 각각 너비와 높이)
각 마스크 \(\mathcal{M}_i\)에 대해 해당 bounding box \(\mathbf{d}_i\)는 마스크의 0이 아닌 픽셀의 최대/최소 $x$ 좌표와 $y$ 좌표를 계산하여 도출된다. 칼만 필터는 예측-보정 사이클로 작동하며, 여기서 state 예측 \(\hat{\mathbf{x}}_{t+1 \vert t}\)는 다음과 같다.
\[\begin{equation} \hat{\mathbf{x}}_{t+1 \vert t} = \mathbf{F} \hat{\mathbf{x}}_{t \vert t} \end{equation}\]그런 다음 예측 마스크 $\mathcal{M}$과 칼만 필터의 예측 state에서 파생된 bounding box 사이의 IoU를 계산하여 KF-IoU score \(s_\textrm{kf}\)를 계산한다.
\[\begin{equation} s_\textrm{kf} = \textrm{IoU} (\hat{\mathbf{x}}_{t+1 \vert t}, \mathcal{M}) \end{equation}\]그런 다음 KF-IoU score와 원래 affinity score의 가중 합을 최대화하는 마스크를 선택한다.
\[\begin{equation} \mathcal{M}^\ast = \underset{\mathcal{M}_i}{\arg \max} (\alpha_\textrm{kf} \cdot s_\textrm{kf} (\mathcal{M}_i) + (1 - \alpha_\textrm{kf}) \cdot s_\textrm{mask} (\mathcal{M}_i)) \end{equation}\]마지막으로 업데이트는 다음과 같이 수행된다.
\[\begin{equation} \hat{\mathbf{x}}_{t \vert t} = \hat{\mathbf{x}}_{t \vert t-1} + \mathbf{K}_t (\mathbf{z}_t - \mathbf{H} \hat{\mathbf{x}}_{t \vert t-1}) \end{equation}\]여기서 \(\mathbf{z}_t\)는 측정값이며, 업데이트에 사용된 선택한 마스크에서 파생된 bounding box이다. $\mathbf{F}$는 linear state transition matrix이고, \(\mathbf{K}_n\)은 Kalman gain이며, $\mathbf{H}$는 observation matrix이다.
또한 대상 object가 다시 나타나거나 일정 기간 동안 마스크 품질이 좋지 않은 경우 모션 모델링의 robustness를 보장하기 위해 추적된 object가 과거 \(\tau_\textrm{kf}\)개의 프레임에서 성공적으로 업데이트되는 경우에만 모션 모듈을 고려한다.
2. Motion-Aware Memory Selection
SAM 2는 이전 프레임에서 \(N_\textrm{mem}\)개를 선택하여 현재 프레임의 visual feature를 준비한다. SAM 2에서는 단순히 대상의 품질에 따라 \(N_\textrm{mem}\)개의 가장 최근 프레임을 선택한다. 그러나 이 접근 방식은 VOT task에서 흔히 발생하는 길게 가려지는 경우나 object의 변형을 처리할 수 없다는 약점이 있다.
모션을 고려한 효과적인 memory bank를 구성하기 위해 mask affinity score, object score, motion score의 세 가지 score에 따라 이전 timestep에서 프레임을 선택하는 선택적 접근 방식을 사용한다. 세 가지 score가 모두 각각에 해당하는 threshold \(\tau_\textrm{mask}\), \(\tau_\textrm{obj}\), \(\tau_\textrm{kf}\)를 충족하는 경우에만 프레임을 메모리의 이상적인 후보로 선택한다.
현재 프레임에서 시간을 거슬러 올라가 검증을 반복한다. \(N_\textrm{mem}\)개의 메모리를 선택하고 motion-aware memory bank $B_t$를 얻는다.
\[\begin{equation} B_t = \{ m_i \vert f (s_\textrm{mask}, s_\textrm{obj}, s_\textrm{kf}) = 1, t - N_\textrm{max} \le i < t \} \end{equation}\](\(N_\textrm{max}\)는 되돌아볼 최대 프레임 수)
$B_t$는 이후 memory attention layer를 통과한 다음 마스크 디코더 \(D_\textrm{mask}\)로 전달되어 현재 타임스탬프에서 마스크 디코딩을 수행한다. SAM 2의 설정을 따라 \(N_\textrm{mem} = 7\)이다.
제안된 모션 모델링 및 메모리 선택 모듈은 재학습 없이도 VOT를 크게 향상시킬 수 있으며 기존 파이프라인에 어떠한 계산 오버헤드도 추가하지 않는다. 또한 모델에 구애받지 않으며 SAM 2를 넘어 다른 프레임워크에도 잠재적으로 적용할 수 있다.
Experiments
1. Quantitative Results
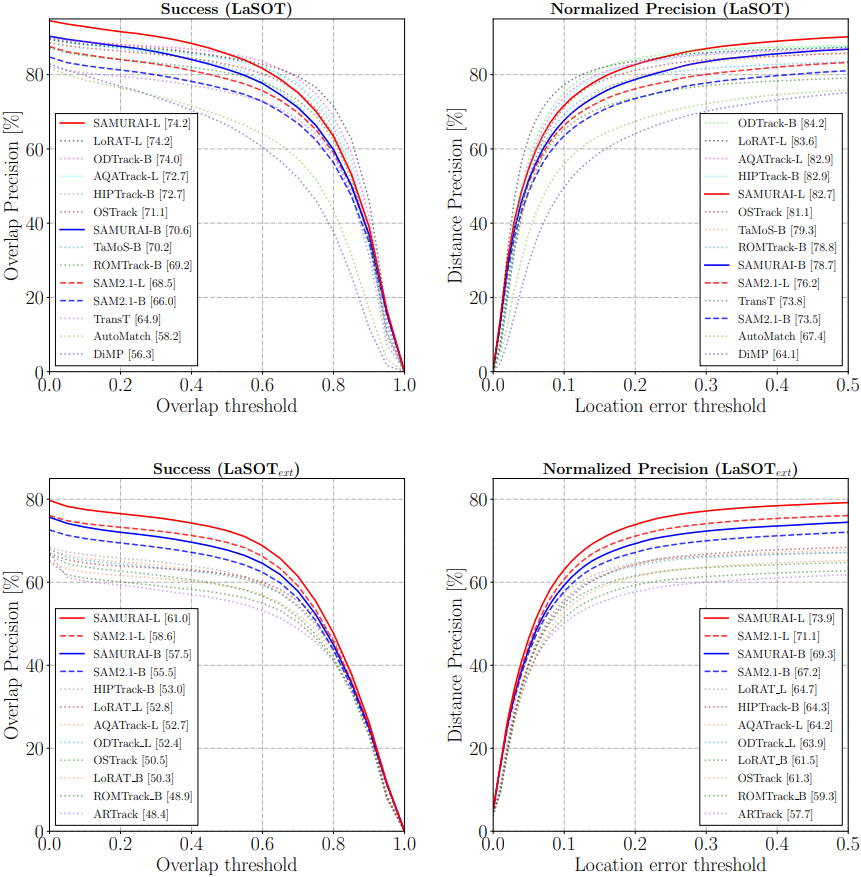
다음은 성공률과 정규화된 precision을 LaSOT과 LaSOText에서 비교한 그래프이다.
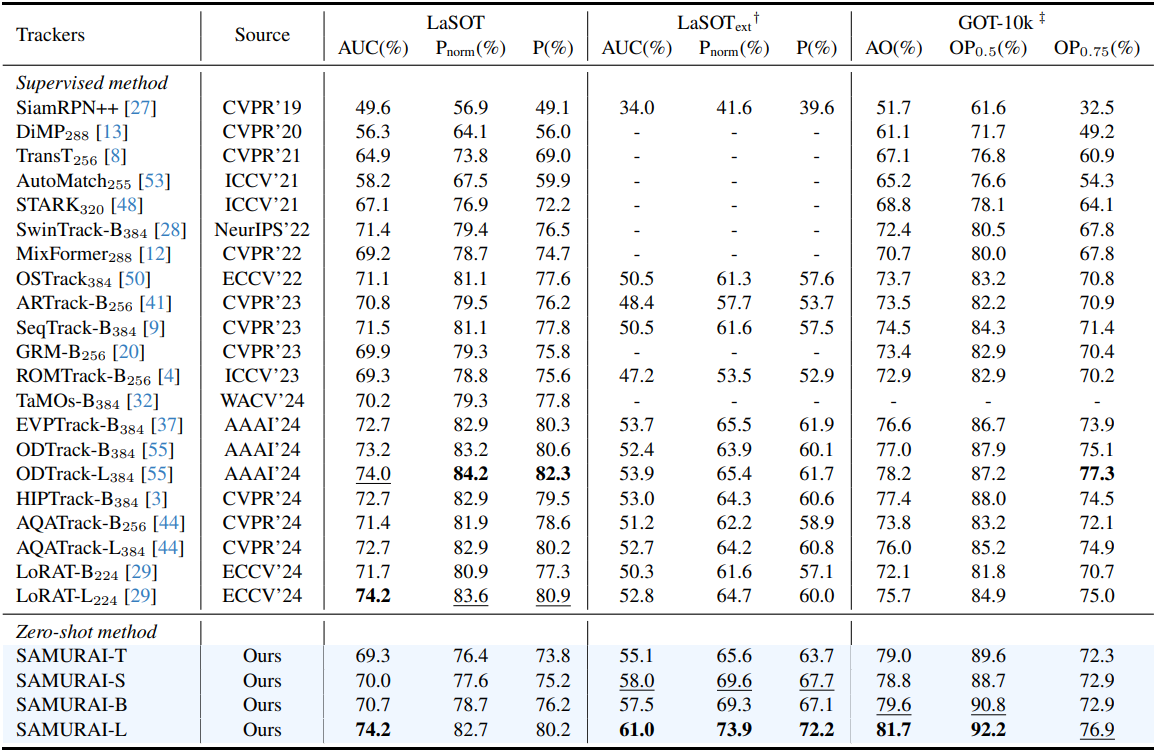
다음은 SAMURAI와 기존 VOT 방법들의 AUC(%)를 LaSOT, LaSOText, GOT-10k 데이터셋에서 비교한 표이다.
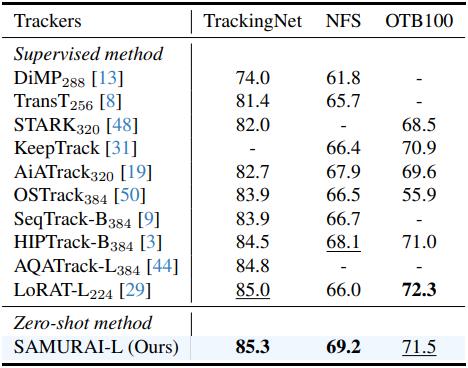
다음은 SAMURAI와 기존 VOT 방법들의 AUC(%)를 TrackingNet, NFS, OTB100 데이터셋에서 비교한 표이다.
2. Ablation Studies
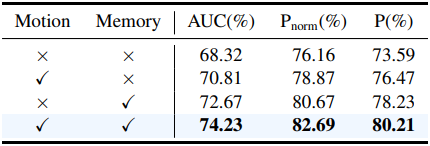
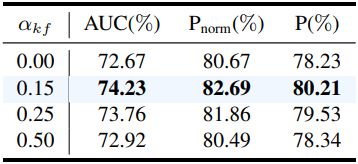
다음은 (왼쪽) 제안된 모듈들과 (오른쪽) 모션 가중치 \(\alpha_\textrm{kf}\)에 대한 ablation 결과이다.
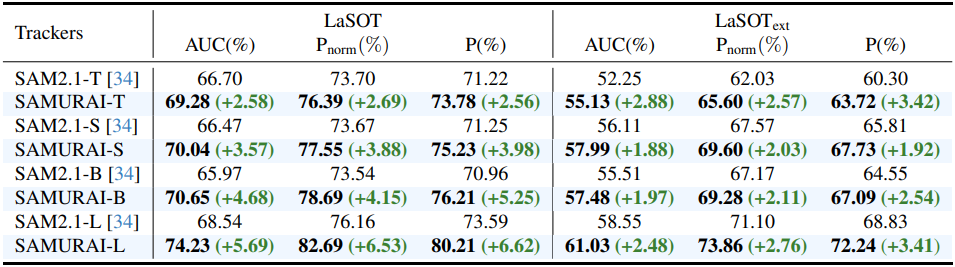
다음은 VOT에 대하여 SAM 기반 tracking 방법과 SAMURAI를 비교한 표이다.
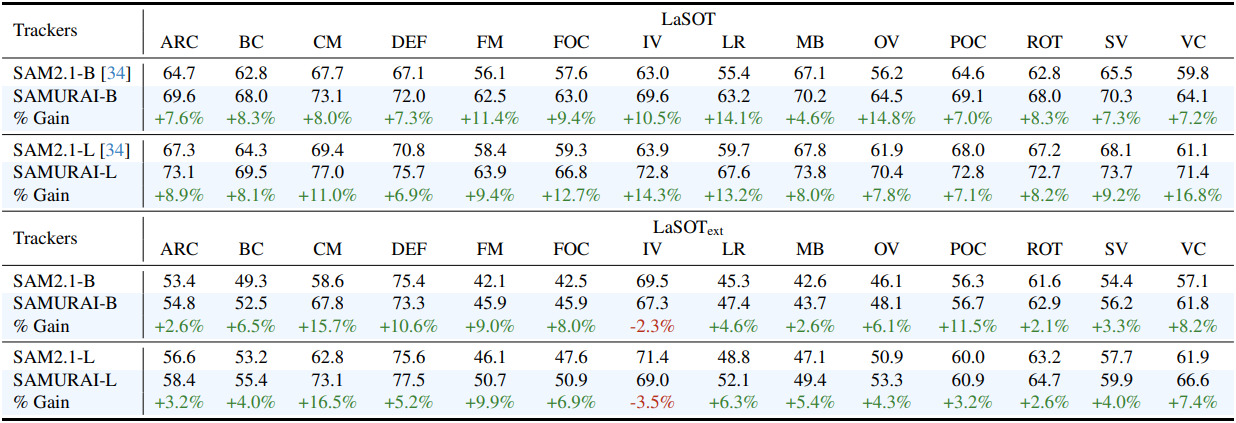
다음은 동영상 속성에 따른 AUC(%)를 분석한 표이다.
3. Qualitative Results
다음은 SAMURAI와 기존 방법들의 tracking 결과를 시각화한 것이다.
