[논문리뷰] SAM 3D: 3Dfy Anything in Images
[Paper] [Page] [Github]
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li⚬, Aohan Lin, Jia-Wei Liu, Ziqi Ma⚬, Anushka Sagar, Bowen Song⚬, Xiaodong Wang, Jianing Yang⚬, Bowen Zhang⚬, Piotr Dollár, Georgia Gkioxari, Matt Feiszli, Jitendra Malik
Meta Superintelligence Labs
19 Nov 2025

Introduction
본 논문에서는 단일 이미지로부터 3D 재구성을 위한 생성 신경망인 SAM 3D를 제시하였다. 이 모델은 clutter와 occlusion이 심한 복잡한 장면에서도 모든 object의 3D shape과 텍스처, 그리고 카메라에 대한 object의 레이아웃을 재구성할 수 있다. 보이는 표면뿐만 아니라 완전한 3D shape을 재구성하므로, 원하는 시점에서 object를 다시 렌더링할 수 있다.
이러한 모델을 학습하는 데 있어 근본적인 어려움은 데이터 부족이다. 특히, 3D GT 데이터와 결합된 이미지는 대규모로 얻기 어렵다. 최근 단일 이미지로부터 강력한 재구성을 보여준 모델들은 독립된 object를 기반으로 학습되며, 멀리 있거나 심하게 가려진 object를 처리하는 데 어려움을 겪는다. 이러한 이미지를 학습 세트에 추가하려면 해당 이미지의 특정 object를 3D shape 모델과 연관시키는 방법을 찾아야 하며, 인간은 이를 수행하기 어렵다. 이를 가능하게 한 두 가지 통찰력은 다음과 같다.
- 3D object 모델들이 렌더링되어 이미지에 붙여지는 합성 장면을 만들 수 있다.
- 사람이 object에 대한 3D shape 모델을 쉽게 생성할 수는 없지만, 제시된 선택 사항 중에서 가장 가능성이 높은 3D 모델을 선택하고 포즈를 이미지에 맞출 수 있다.
저자들은 다단계 학습 레시피를 적용하여 학습 파이프라인과 데이터 엔진을 설계하였다. 먼저 렌더링된 합성 object의 대량 컬렉션을 사용하여 학습시킨다. 모델은 object의 shape과 텍스처에 대한 풍부한 vocabulary를 학습하여 현실 재구성에 대비한다. 다음으로, 렌더링된 모델을 이미지에 붙여넣어 생성된 반합성 데이터로 중간 학습을 진행한다. 마지막으로, 사후 학습에서는 새로운 model-in-the-loop (MITL) 파이프라인과 3D 아티스트를 활용하여 모델을 실제 이미지에 적용하고, 인간의 선호도에 맞춰 조정한다.
MITL 데이터 파이프라인에서 얻은 사후 학습 후 데이터는 실제 이미지에서 우수한 성능을 얻는 데 핵심적인 요소이다. 인간은 3D shape GT를 생성할 수 없다. 따라서 인간은 여러 개의 초기 3D shape 제안에서 3D 모델을 선택하고 이미지의 object에 맞춰 정렬하며, 일부 어려운 인스턴스에 대해서는 아티스트에게 전달한다. 검증된 주석은 모델 학습에 다시 반영되고, 개선된 모델은 데이터 엔진에 다시 통합되어 주석 품질을 더욱 향상시킨다. 이러한 선순환은 3D 주석의 품질, 레이블링 속도, 그리고 모델 성능을 꾸준히 향상시킨다.
실제 object의 shape과 레이아웃을 3D로 재구성하기 위한 기존 벤치마크가 부족하기 때문에, 저자들은 1,000개의 이미지와 3D 쌍으로 구성된 새로운 평가 세트인 SAM 3D Artist Objects (SA-3DAO)를 제안하였다. 벤치마크에 포함된 object는 굉장히 다양하며, 해당 object가 자연스럽게 나타나는 실제 이미지와 쌍을 이룬다. 전문 3D 아티스트는 입력 이미지에서 3D shape을 생성하며, 이는 시각적으로 근거를 둔 3D 재구성에 대한 전문가 수준의 상한값을 나타낸다.
The SAM 3D Model
1. Problem Formulation
Object의 shape을 $S$, 텍스처를 $T$, 카메라 좌표에서의 rotation, translation, sclae을 $(R, t, s)$라 하자. 3차원에서 2차원으로의 매핑은 손실이 있으므로, 재구성 문제를 주어진 이미지 $I$와 마스크 $M$에 대한 조건부 분포 $p(S, T, R, t, s \vert I, M)$로 모델링한다. 목표는 $p$에 최대한 근접하는 생성 모델 $q(S, T, R, t, s \vert I, M)$을 학습시키는 것이다.
2. Architecture

본 논문에서는 2단계 latent flow matching 아키텍처인 TRELLIS를 기반으로 한다. SAM 3D는 먼저 object의 포즈와 대략적인 shape을 공동으로 예측한 후, shape을 정교화한다. TRELLIS가 분리된 하나의 object를 재구성하는 것과 달리, SAM 3D는 object의 레이아웃을 예측하여 object가 여러 개인 장면을 생성한다.
Input encoding
저자들은 두 쌍의 이미지에서 feature를 추출하기 위해 인코더로 DINOv2를 사용했고, 그 결과 4개의 컨디셔닝 토큰 세트가 생성된다.
- Crop된 object: 마스크 $M$으로 crop된 이미지 $I$와 crop된 binary mask를 인코딩하여 object에 대한 초점이 맞춰진 고해상도 뷰를 제공한다.
- 전체 이미지: 전체 이미지 $I$와 전체 이미지 binary mask를 인코딩하여 crop된 뷰에는 없는 글로벌한 장면 컨텍스트와 단서를 제공한다.
선택적으로, 하드웨어 센서나 monocular depth estimation을 통해 얻은 coarse한 장면 point map $P$를 조건으로 지원하여 SAM 3D가 다른 파이프라인과 통합될 수 있도록 하였다.
The Geometry Model
Geometry Model은 조건부 분포 $p(O, R, t, s \vert I, M)$을 모델링한다. 여기서 $O \in \mathbb{R}^{64^3}$는 대략적인 shape이고, $R \in \mathbb{R}^6$은 6D rotation, $t \in \mathbb{R}^3$은 translation, $s \in \mathbb{R}^3$은 scale이다. 입력 이미지와 마스크 인코딩을 조건으로, Mixture-of-Transformers (MoT) 아키텍처를 사용하는 flow transformer (1.2B)를 사용한다. 또한 multi-modal에 대한 attention mask를 사용하여 대략적인 shape $O$와 레이아웃 $(R, t, s)$를 모델링한다.
The Texture & Refinement Model
Texture & Refinement Model은 조건부 분포 $p(S, T \vert I, M, O)$를 학습한다. 먼저 Geometry Model에서 예측한 $O$에서 active voxel을 추출한다. Sparse latent flow transformer (600M)를 통해 기하학적 디테일을 정밀화하고 텍스처를 합성한다.
3D Decoders
Texture & Refinement Model의 latent 표현은 한 쌍의 VAE 디코더 \(\mathcal{D}_m\)과 \(\mathcal{D}_g\)를 통해 메쉬 또는 3D Gaussian splat으로 디코딩될 수 있다. 이렇게 별도로 학습된 디코더는 동일한 VAE 인코더를 공유하므로 동일한 latent space를 갖는다.
Training SAM 3D
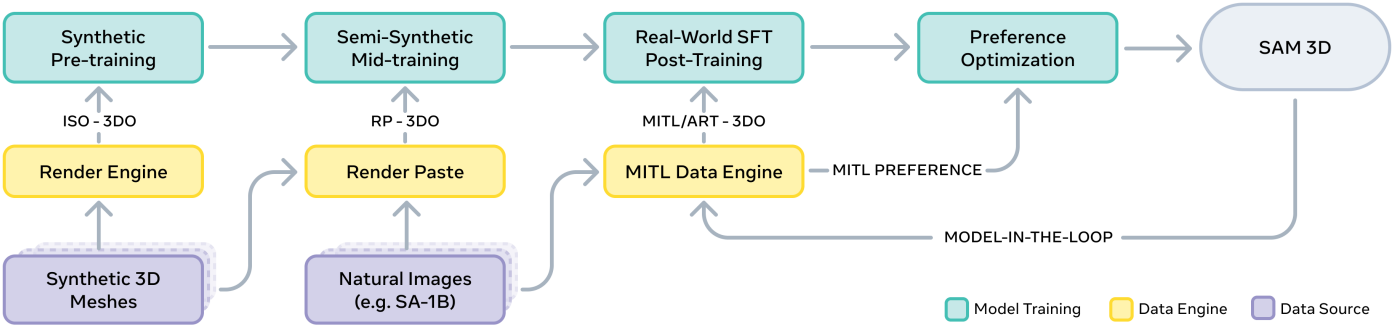
사전 학습과 중간 학습에서 다양한 학습 전략을 중첩하여 역량을 구축한 후, 사후 학습 데이터를 통해 모델을 실제 데이터와 인간이 선호하는 행동에 맞춰 조정한다. SAM 3D는 다음과 같은 접근 방식을 사용한다.
- Step 1: Pretraining. Shape 생성과 같은 기본 기능을 기본 모델로 구축한다.
- Step 1.5: Mid-Training. Occlusion robustness, mask-following, 시각적 신호 사용과 같은 일반적인 기술을 전수한다.
- Step 2: Post-Training. 합성 데이터에서 실제 데이터로 모델을 조정하거나 인간의 미적 선호도를 따르는 것과 같은 목표 행동을 유도한다.
이러한 Step 2의 정렬은 반복될 수 있으며, 먼저 현재 모델로 데이터를 수집한 다음 새로운 데이터로 모델을 개선한다. 이렇게 하면 사람이 감독하는 선순환이 형성된다. 이러한 정렬의 부산물로 데이터셋이 생성된다.

1. Pre & Mid-Training: Building a Base Model
학습은 합성 데이터에 대한 사전 학습과 중간 학습으로 시작하며, 이용 가능한 대규모 데이터셋을 활용하여 shape과 텍스처에 대한 강력한 prior와 마스크 추적, occlusion 처리, 포즈 추정과 같은 기술을 학습한다. 이렇게 학습된 풍부한 feature들은 사후 학습에 필요한 실제 샘플 수를 크게 줄여준다. 사전 학습과 중간 학습에서 모델은 rectified flow matching을 사용하여 학습되어 여러 3D 모달리티를 생성한다.
1.1 Pretraining: Single Isolated 3D Assets

사전 학습 단계에서는 독립적인 합성 object의 렌더링으로부터 정확한 3D shape과 텍스처를 재구성하도록 모델을 학습시킨다. 구체적으로, Objaverse-XL과 라이선스 데이터셋에서 270만 개의 object 메쉬를 사용하여 $(I, S, T)$ triplet 세트를 수집하고, 24개 시점에서 렌더링하여 중앙에 위치한 단일 object의 고해상도 이미지를 생성한다. 이 데이터셋을 Iso-3DO라고 부르며, 2.5조 개의 학습 토큰을 사용하여 학습되었다.
1.2 Mid-Training: Semi-Synthetic Capabilities

다음으로, 중간 학습에서는 모델이 실제 이미지의 object를 처리할 수 있도록 하는 기본 기술을 구축한다.
- Mask-following: 입력 이미지의 binary mask로 정의된 대상 object를 재구성하도록 모델을 학습시킨다.
- Occlusion robustness: 데이터셋의 인공적인 occluder를 통해 shape 완성을 학습하도록 유도한다.
- Layout estimation: 정규화된 카메라 좌표에서 translation과 scale을 생성하도록 모델을 학습시킨다.
알파 합성을 사용하여 텍스처 메쉬를 이미지 위에 렌더링하여 데이터를 구성한다. 이 데이터셋을 RP-3DO라고 부르며, 6,100만 개의 샘플과 280만 개의 고유 메쉬를 포함한다. 이 데이터셋은 부분 집합으로 구성된다.
- 가리는 물체 (occluder) & 가려지는 물체 (occludee) 쌍
- 실제 object를 유사한 위치와 크기의 합성 object로 대체
중간 단계는 2.7조 개의 학습 토큰을 사용하여 학습되었다. 중간 단계에서 사용된 모든 데이터는 (반)합성 데이터였기 때문에, 도메인 간 격차를 해소하고 실제 단서를 최대한 활용하려면 실제 이미지가 필요하다.
2. Post-Training: Real-World Alignment
사후 학습에서는 두 가지 목표를 가지고 있다.
- (반)합성 데이터와 실제 이미지 간의 도메인 간 격차를 해소
- 인간의 선호도에 맞춰 조정
저자들은 데이터 엔진을 반복적으로 사용하여 모델을 조정한다. 먼저 현재 모델로 학습 데이터를 수집하고, 수집된 데이터에 대한 다단계 사후 학습을 통해 모델을 업데이트한다. 그리고 이 과정을 반복한다.
2.1 Post-Training: Collection Step
3D visual grounding을 위한 데이터 수집의 핵심 과제는 대부분의 사람들이 메쉬를 직접 생성할 수 없다는 것이다. 이를 위해서는 숙련된 3D 아티스트가 필요하며, 그렇게 하더라도 몇 시간이 걸릴 수 있다. 그러나 옵션이 주어지면 대부분의 사람들은 이미지의 object와 가장 유사한 메쉬를 선택할 수 있다. 이러한 사실이 SAM 3D를 위한 데이터 수집의 기반이 된다.
저자들은 선호도를 다음과 같은 방식으로 학습 데이터로 변환하였다. 학습 후 모델에서 샘플링하고, 인간이 가장 적합한 후보를 선택한 다음, 기준에 따라 전반적인 품질을 평가한다. 품질이 기준을 충족하면 후보는 학습 샘플이 된다.
안타깝게도 첫 번째 iteration에서는 초기 모델이 고품질 후보를 거의 생성하지 못한다. 이는 첫 번째 수집 단계 이전에는 3D visual grounding을 위한 실제 데이터가 거의 없기 때문이다. 저자들은 기존 학습 및 검색 기반 모델을 활용하여 후보를 생성함으로써 이러한 cold start 문제를 해결하였다. 초기 단계에서는 앙상블에서 대부분 데이터를 추출하지만, 학습이 진행됨에 따라 최적의 모델이 우위를 점하게 되어 결국 SAM 3D에서 확인되는 주석 데이터의 약 80%를 생성한다.
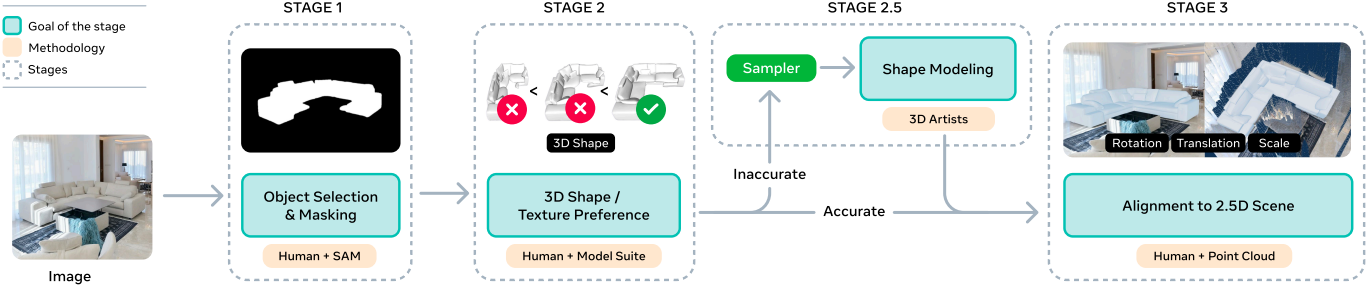
주석 파이프라인은 실제 이미지에서 3D object의 shape $S$, 텍스처 $T$, 방향 $R$, 3D 위치 $t$, scale $s$를 수집한다. 저자들은 총 100만 개에 가까운 이미지에 텍스처가 없는 메쉬 314만 개, 텍스처가 있는 메쉬 10만 개를 주석으로 처리했다. 이는 실제 이미지와 결합된 3D 데이터로는 전례 없는 규모이다.
Stage 1: Choosing target objects $(I, M)$
이 단계의 목표는 다양하고 많은 이미지 $I$와 object mask $M$을 식별하여 3D로 변환하는 것이다. Object와 장면 전반에 걸친 일반화를 보장하기 위해, 여러 다양한 실제 데이터셋에서 이미지를 샘플링하고 3D 기반 분류법을 활용하여 object 분포의 균형을 맞춘다. Object mask를 얻기 위해 SAM으로 마스크를 만들고 사람이 관심 object를 선택한다.
Stage 2: Object model ranking and selection $(S, T)$
이 단계의 목표는 이미지 기반 3D shape $S$와 텍스처 $T$를 수집하는 것이다. 사람이 입력 이미지 및 마스크와 가장 잘 일치하는 shape 및 텍스처 후보를 선택한다. 구체적으로, 사람이 예시를 평가하고 미리 정의된 품질 threshold를 충족하지 않는 예시를 제외한다. 불량 후보는 선호도 정렬을 위한 negative 예시가 된다.
데이터 엔진은 사람에게 $N = 8$개의 후보 중 가장 좋은 하나를 선택하도록 요청함으로써 성공적인 주석 생성 확률을 극대화한다. 이 최적 후보의 기대 품질은 $N$에 따라 향상되며, 먼저 모델을 사용하여 필터링한 후 사람이 필터링하여 $N$을 더욱 증가시킨다.
Stage 2.5: Hard example triage (Artists)
어떤 모델도 적절한 shape을 생성하지 못하는 경우, 비전문가는 메쉬를 수정할 수 없어 모델에 가장 필요한 정확한 위치에 데이터가 부족하게 된다. 이러한 까다로운 사례 중 일부는 전문 3D 아티스트가 직접 처리하며, 이 데이터셋을 Art-3DO라 부른다.
Stage 3: Aligning objects to 2.5D scene $(R, t, s)$
이전 단계에서는 object의 3D shape을 생성하지만, 장면 내 레이아웃은 생성하지 않는다. 2단계에서 나온 shape에 대해, 사람이 3D object의 translation, rotation, 그리고 포인트 클라우드를 기준으로 한 scale을 조정하여 object의 포즈에 레이블을 지정한다. 포인트 클라우드는 일관된 shape 배치 및 방향을 가능하게 하는 충분한 구조를 제공한다.
데이터 수집을 현재 가장 좋은 모델 $q(S, T, R, t, s \vert I,M)$을 입력 받고, 학습 샘플 $D^{+} = (I, M, S, T, R, t, s)$, 품질 평가 $r \in [0, 1]$, 덜 선호되는 후보 집합 $D^{-} = (I, M, S^\prime, T^\prime, R^\prime, t^\prime, s^\prime)$을 반환하는 API로 생각할 수 있다.
2.2 Post-Training: Model Improvement Step
SAM 3D의 모델 개선 단계에서는 이러한 학습 샘플과 선호도 결과를 사용하여 여러 단계의 fine-tuning 및 선호도 정렬을 통해 기본 모델을 업데이트한다. 각 사후 학습 iteration에서는 이전 모든 수집 단계의 데이터를 집계하고, $D^{+}$가 특정 품질 threshold $\alpha$를 초과하는 샘플만 유지한다. 학습이 진행됨에 따라 $\alpha$는 시간이 지남에 따라 증가할 수 있다. 최종 사후 학습 iteration에서는 0.5조 개의 학습 토큰을 사용한다.
Supervised Fine-Tuning (SFT)
사후 학습이 시작될 때, 기본 모델은 합성 데이터만 인식한다. 합성 데이터와 실제 데이터 간의 도메인 간 차이가 크기 때문에, 3단계에서 정렬된 메쉬를 fine-tuning하는 것으로 시작한다.
노이즈가 더 많은 비전문가 레이블(MITL-3DO)로 SFT를 시작한 후, 3D 아티스트의 더 작고 고품질인 레이블(Art-3DO)로 SFT를 진행한다. 고품질 Art-3DO 데이터는 아티스트의 미적 선호도에 맞춰 출력을 정렬하여 모델 품질을 향상시킨다. 이를 통해 floater, 바닥 없는 메쉬, 대칭 누락과 같은 일반적인 오류를 억제하는 데 도움이 된다.
Preference optimization (alignment)
Fine-tuning 후, 모델은 다양한 object와 실제 이미지에 대한 shape과 레이아웃을 robust하게 생성할 수 있다. 그러나 인간은 대칭, 폐쇄성 등과 같은 속성에 민감하며, 이러한 속성은 일반적인 loss로는 포착하기 어렵다. 따라서 데이터 엔진 2단계의 $D^{+}$/$D^{-}$ 쌍을 사용하여 direct preference optimization (DPO)를 SFT 후에 수행한다. 이 off-policy 데이터는 Art-3DO에서 SFT를 수행한 후에도 바람직하지 않은 모델 출력을 제거하는 데 효과적이다.
Distillation
마지막으로, Geometry Model에서 1초 미만으로 shape과 레이아웃 생성하게 하기 위해 inference하는 동안 필요한 함수 평가 수(NFE)를 25에서 4로 줄인다. 이를 위해 shortcut model을 적용하여 짧은 distillation 단계를 수행한다.
Experiments
1. Comparison with SOTA
다음은 장면 수준 및 object 수준의 재구성 선호도를 1:1로 비교한 결과이다.
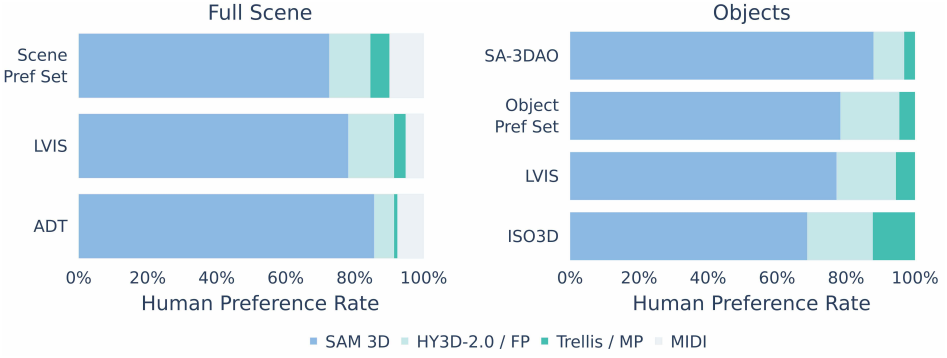
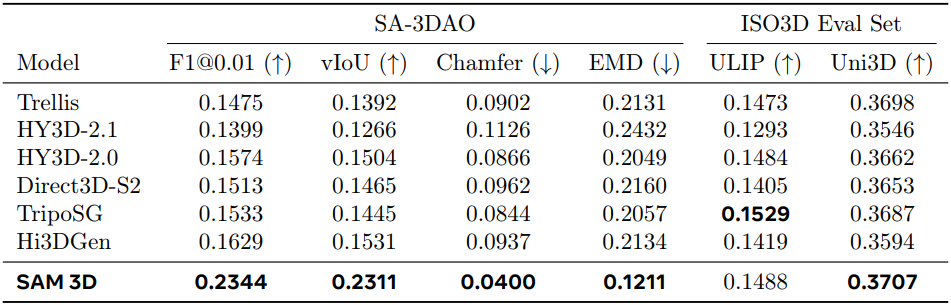
다음은 3D shape에 대하여 image-to-3D 방법들과 비교한 결과이다.
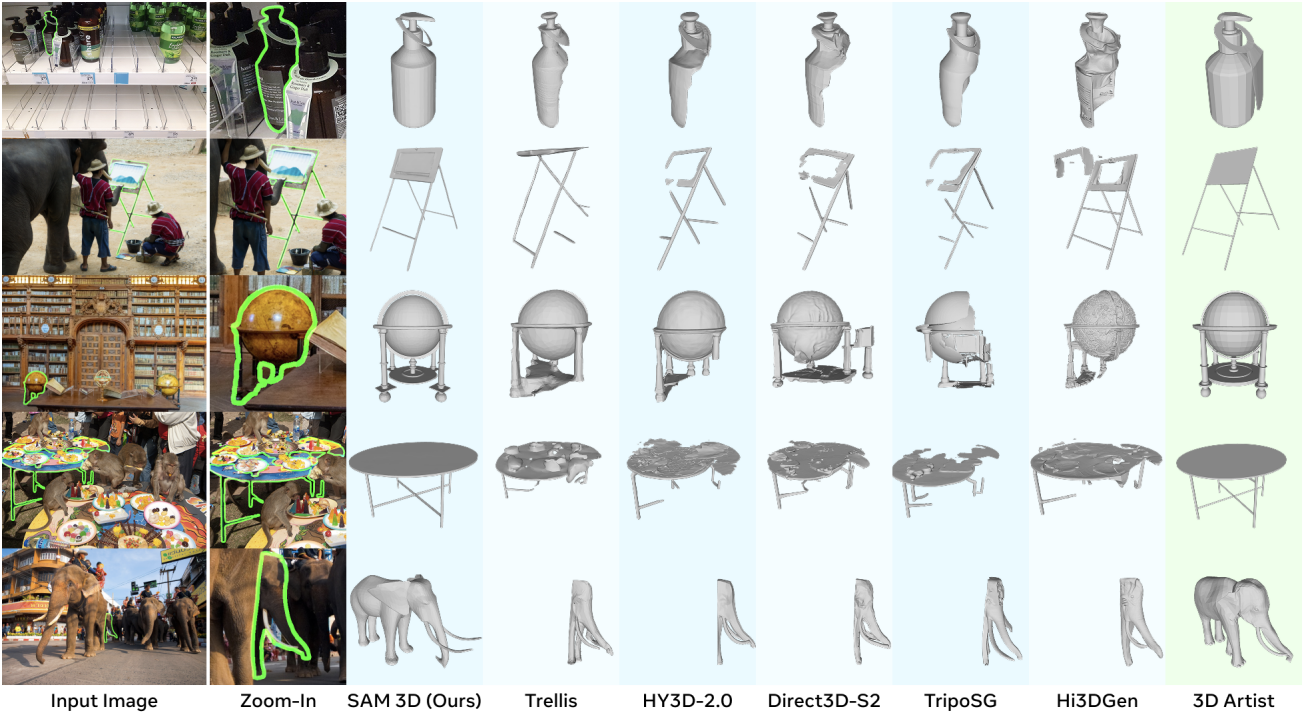
다음은 동일한 장면에 대한 재구성 결과를 비교한 것이다.
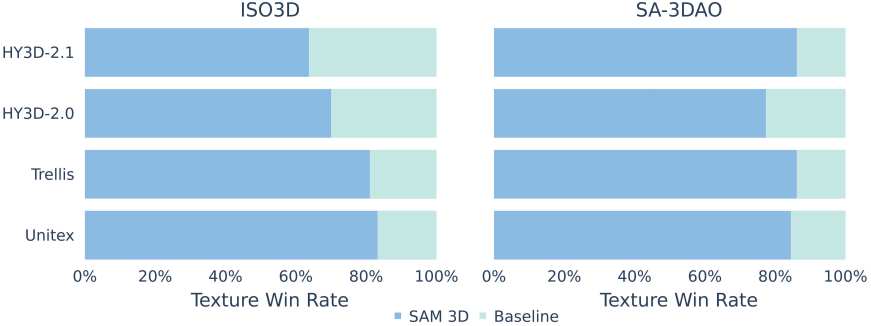
다음은 텍스처에 대한 선호도를 1:1로 비교한 결과이다.
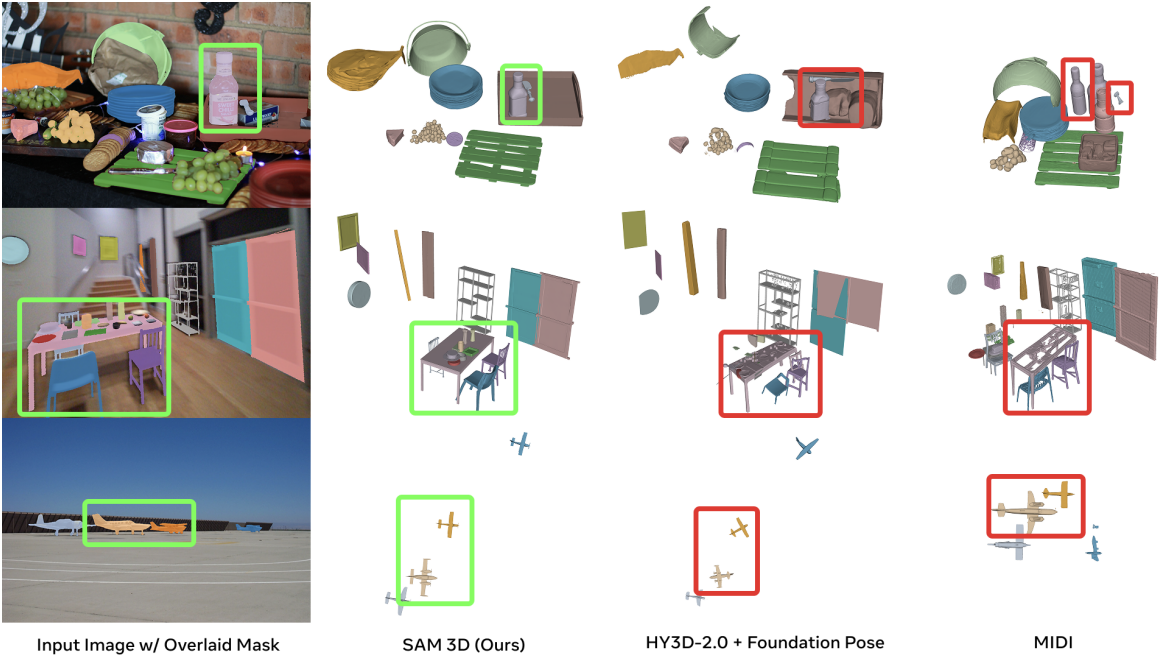
다음은 3D 레이아웃에 대한 비교 결과이다.

2. Analysis Studies
다음은 데이터 엔진의 진화에 따른 ELO 점수를 비교한 결과이다.
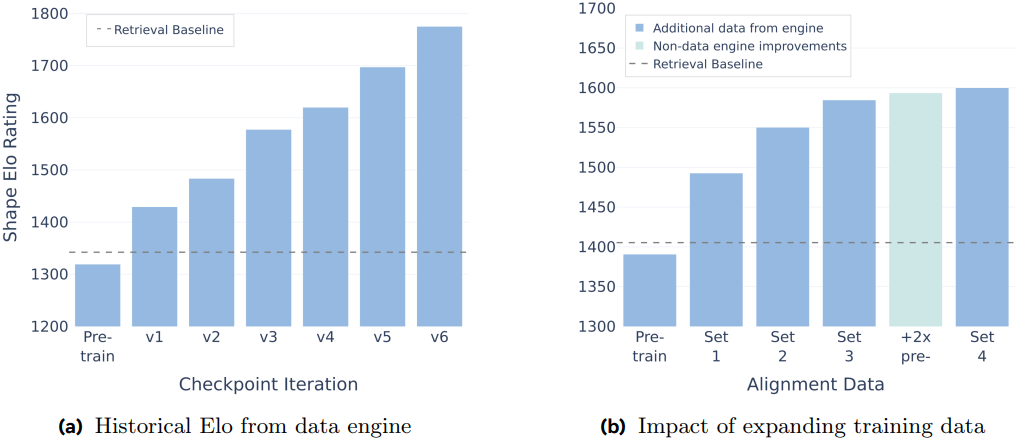
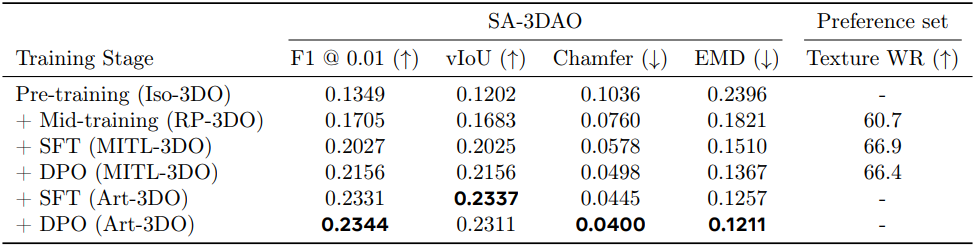
다음은 다단계 학습에 따른 모델 성능을 비교한 결과이다.