[논문리뷰] SAM 3: Segment Anything with Concepts
ICLR 2026. [Paper] [Page] [Github]
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane Momeni, Rishi Hazra, Shuangrui Ding, Sagar Vaze, Francois Porcher, Feng Li, Siyuan Li, Aishwarya Kamath, Ho Kei Cheng, Piotr Dollar, Nikhila Ravi, Kate Saenko, Pengchuan Zhang, Christoph Feichtenhofer
Meta Superintelligence Labs
19 Nov 2025

Introduction
SAM과 SAM 2는 이미지와 동영상에 대한 promptable segmentation task를 도입했으며, 점, 박스, 마스크를 사용하여 프롬프트당 하나의 object를 분할하는 Promptable Visual Segmentation (PVS)에 중점을 두었다. 이러한 방법들은 획기적인 발전을 이루었지만, 입력의 어느 곳에나 나타나는 모든 개념의 인스턴스를 찾고 분할하는 일반적인 task는 다루지 못했다.
본 논문은 이러한 간극을 메우기 위해 SAM 3를 제시하였다. SAM 2에 비해 PVS를 개선하고 Promptable Concept Segmentation (PCS)의 새로운 기준을 제시하였다. PCS는 텍스트 및/또는 image exemplar를 입력으로 받고, 개념과 일치하는 모든 object에 대해 인스턴스 및 semantic mask를 예측하는 동시에 동영상 프레임 전체에서 object identity를 유지하는 task이다. 저자들은 텍스트를 “빨간 사과” 또는 “줄무늬 고양이”와 같은 간단한 명사구(NP)로 제한하였다. SAM 3는 추론을 필요로 하는 긴 참조 표현을 위해 설계되지 않았지만, multimodal LLM (MLLM)과 간단히 결합하여 더 복잡한 언어 프롬프트를 처리할 수 있다. 이전 SAM 버전과 마찬가지로, SAM 3는 완전한 상호작용을 지원하며, 사용자는 모델을 의도한 출력으로 유도하는 정제 프롬프트를 추가하여 모호성을 해결할 수 있다.
SAM 3는 비전 인코더를 공유하는 detector와 tracker로 구성된다. Detector는 텍스트, geometry, image exemplar를 기반으로 하는 DETR 기반 모델이다. Open-vocabulary 개념에 대한 detection의 어려움을 해결하기 위해, 저자들은 object 인식과 localization을 분리하는 별도의 presence head를 도입했다. 이는 특히 어려운 부정문을 학습할 때 효과적이다. Tracker는 SAM 2 transformer 인코더-디코더 아키텍처를 계승하여 동영상 segmentation 및 대화형 정제를 지원한다. Detector는 identity에 독립적이어야 하는 반면 tracker는 동영상에서 identity를 분리해야 하기 때문에, 이러한 detector와 tracker로 분리된 설계를 통해 task 충돌을 방지한다.
저자들은 방대하고 다양한 학습 데이터셋에 주석을 추가하는 human-in-the-loop 데이터 엔진을 구축하였다. 기존 데이터 엔진을 세 가지 핵심 방식으로 혁신하였다.
- 미디어 큐레이션: 기존 방식보다 더욱 다양한 미디어 도메인을 큐레이션하였다.
- 레이블 큐레이션: 명사구와 부정문을 생성하는 AI annotator로서 MLLM을 활용하여 레이블의 다양성과 난이도를 크게 높였다.
- 레이블 검증: MLLM을 fine-tuning하여 인간에 가까운 정확도를 달성하는 효과적인 AI verifier로 만들어 주석 처리량을 두 배로 높였다.
본 논문의 데이터 엔진은 노이즈가 많은 미디어-구문-마스크 pseudo-label로부터 시작하여, 인간 및 AI verifier를 모두 사용하여 마스크 품질과 완전성을 검사하고, 올바르게 레이블이 지정된 예시들을 필터링하고 까다로운 오류 사례를 식별한다. 그런 다음, 인간은 마스크를 수동으로 수정하여 이러한 오류를 수정하는 데 집중한다. 이를 통해 400만 개의 고유 구문과 5,200만 개의 마스크로 구성된 고품질 학습 데이터와, 3800만 개의 구문과 14억 개의 마스크로 구성된 합성 데이터셋에 주석을 달았다. 또한, 저자들은 PCS에 대한 Segment Anything with Concepts (SA-Co) 벤치마크를 생성했다. 이 벤치마크는 12만 개의 이미지와 1.7만 개의 동영상에서 철저한 마스크를 가진 20.7만 개의 고유 개념을 포함하고 있으며, 이는 기존 벤치마크보다 50배 이상 많은 개념이다.
Promptable Concept Segmentation (PCS)

모든 프롬프트는 카테고리 정의에서 일관성을 유지해야 하며, 그렇지 않으면 모델의 동작이 정의되지 않는다. 예를 들어, “물고기”는 꼬리만 있는 후속 image exemplar로 정제할 수 없다. 대신 텍스트 프롬프트를 업데이트해야 한다. Image exemplar는 모델이 처음에 일부 인스턴스를 놓치거나 해당 개념이 드물 때 특히 유용하다. 저자들은 Promptable Concept Segmentation을 다음과 같이 정의하였다. 이미지 또는 30초 이하의 짧은 동영상이 주어졌을 때, 짧은 텍스트 구문, image exemplar, 또는 이 둘의 조합으로 지정된 시각적 개념의 모든 인스턴스를 감지, 분할, 추적한다. 개념은 명사와 선택적 수식어로 구성된 단순 명사구(NP)로 정의된 개념으로 제한된다. 명사구 프롬프트는 이미지/동영상의 모든 프레임에 글로벌하게 적용되는 반면, image exemplar는 개별 프레임에 positive/negative bounding box로 제공하여 대상 마스크를 반복적으로 개선할 수 있다.
Vocabulary에는 시각적 장면에서 근거로 삼을 수 있는 간단한 명사구가 모두 포함되어 있어, task가 본질적으로 모호해진다. 다의성, 주관적인 설명어, 근거조차 없는 모호하거나 맥락에 따라 달라지는 문구, 경계 모호성, object의 범위를 가리는 occlusion 및 blur와 같은 요소로 인해 문구에 대한 여러 해석이 있을 수 있다. Vocabulary를 신중하게 선별하고 모든 관심 클래스에 대한 명확한 정의를 설정함으로써 이러한 문제를 완화할 수 있다. 저자들은 세 명의 전문가로부터 테스트 주석을 수집하고, 여러 가지 유효한 해석을 허용하도록 평가 프로토콜을 조정하고, 주석의 모호성을 최소화하기 위한 데이터 파이프라인 및 가이드라인을 설계하고, 모델에 모호성 모듈을 추가함으로써 모호성 문제를 해결하였다.
Model
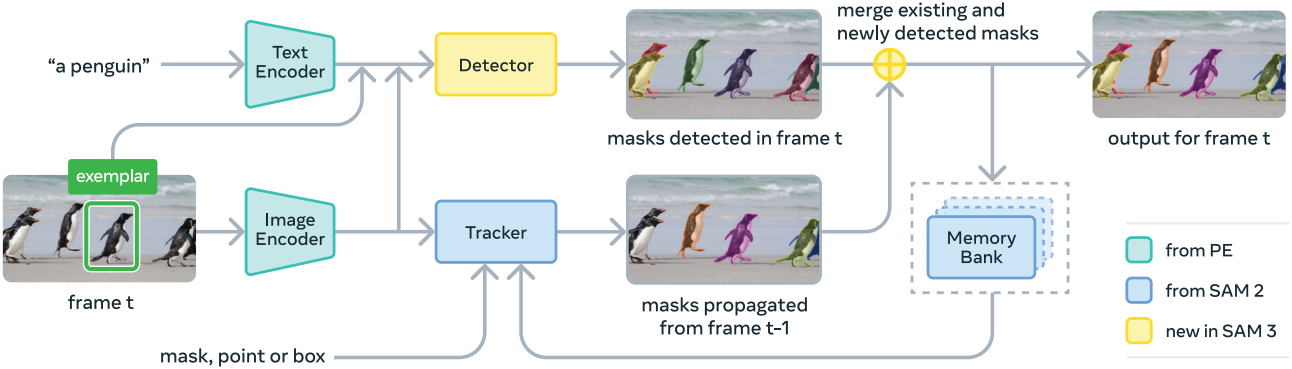
SAM 3은 SAM 2의 일반화로, 기존의 PVS task와 함께 새로운 PCS task를 지원한다. 개념 프롬프트 (단순 명사구, image exemplar) 또는 비주얼 프롬프트 (점, 상자, 마스크)를 사용하여 시공간적으로 분할할 object를 정의한다. image exemplar와 비주얼 프롬프트를 개별 프레임에 반복적으로 추가하여 대상 마스크를 개선할 수 있다. False positive 및 false negative object는 image exemplar를 사용하여 각각 제거하거나 추가할 수 있으며, 개별 masklet은 SAM 2 스타일의 PVS를 사용하여 개선할 수 있다.
아키텍처는 SAM과 DETR 시리즈를 기반으로 하며, detector, tracker, 동영상용 메모리로 구성된다. Detector와 tracker는 정렬된 Perception Encoder (PE) backbone에서 비전-언어 입력을 수집한다.
Detector Architecture
Detector의 아키텍처는 일반적인 DETR 패러다임을 따른다. 이미지와 텍스트 프롬프트는 먼저 PE로 인코딩되고, image exemplar가 있는 경우 exemplar encoder로 인코딩된다. image exemplar 토큰과 텍스트 토큰을 통칭하여 프롬프트 토큰이라고 한다. 퓨전 인코더는 이미지 인코더로부터 컨디셔닝되지 않은 임베딩을 받고, 프롬프트 토큰과 cross-attention하여 컨디셔닝된다. 퓨전 후 DETR-like decoder가 실행되며, 여기서 학습된 object query는 퓨전 인코더의 컨디셔닝된 이미지 임베딩에 cross-attention된다.
각 디코더 레이어는 각 object query에 대한 classification logit (object가 프롬프트에 해당하는지 여부를 나타내는 바이너리 레이블)과 이전 레벨에서 예측한 bounding box의 델타를 예측한다. 본 논문에서는 box-region-positional bias를 사용하여 각 object에 attention을 집중시키지만, 최근 DETR 모델과는 달리 기본 attention을 고수하였다. 학습 과정에서 DAC-DETR의 dual supervision과 Align-DETR의 Align loss를 채택하였다. Mask head는 MaskFormer에서 가져왔다. 또한, 이미지의 모든 픽셀에 대해 프롬프트에 해당하는지 여부를 나타내는 바이너리 레이블을 예측하는 semantic segmentation head도 있다.
Presence Token
각 proposal query가 이미지/프레임에서 object를 인식하고 그 위치를 동시에 파악하는 것(localization)은 어려울 수 있다. 인식 성분의 경우 전체 이미지의 맥락적 단서가 중요하다. 그러나 proposal query가 글로벌 컨텍스트를 이해하도록 강제하는 것은 localization loss의 본질적인 로컬한 특성과 충돌하기 때문에 역효과를 낼 수 있다.
저자들은 학습된 글로벌 presence token을 도입하여 인식 단계와 localization 단계를 분리하였다. 이 토큰은 명사구(NP) 형태의 대상 개념이 이미지/프레임에 존재하는지 여부를 예측하는 데 전적으로 책임이 있다. 각 proposal query $q_i$는 localization 문제만 해결하면 된다. 각 proposal query의 최종 점수는 자체 점수와 presence 점수의 곱이다.
\[\begin{equation} p(q_i \textrm{ is a match}) = \underbrace{p(\textrm{NP is present in input})}_{\textrm{recognition}} \; \underbrace{p(q_i \textrm{ is a match } \vert \textrm{ NP is present in input})}_{\textrm{localization}} \end{equation}\]Image Exemplars and Interactivity
SAM 3는 bounding box와 관련 바이너리 레이블(positive 또는 negative)의 쌍으로 제공되는 image exemplar를 지원하며, 이는 단독으로 사용하거나 텍스트 프롬프트를 보완하는 데 사용할 수 있다. 그런 다음 모델은 프롬프트와 일치하는 모든 인스턴스를 감지한다. 예를 들어, 개에 positive bounding box가 주어지면 모델은 이미지의 모든 개를 감지한다. 이는 비주얼 프롬프트가 하나의 인스턴스만 생성하는 SAM 1과 2의 PVS task와는 다르다.
각 image exemplar는 exemplar encoder에서 위치 임베딩, 레이블 임베딩, ROI-pooling된 visual feature를 사용하여 개별적으로 인코딩된 후, 작은 transformer를 통해 concat 및 처리된다. 결과 프롬프트는 텍스트 프롬프트에 concat되어 프롬프트 토큰을 구성한다. Image exemplar는 대화형으로 제공되어 출력을 개선할 수 있다.
Tracker and Video Architecture
동영상과 프롬프트 $P$가 주어지면, detector와 tracker를 사용하여 동영상 전체에서 프롬프트에 해당하는 object를 검출하고 추적한다. 각 프레임에서 detector는 새로운 object \(\mathcal{O}_t\)를 찾고, tracker는 이전 프레임 $t−1$의 masklet \(\mathcal{M}_{t-1}\)을 현재 프레임 $t$의 새로운 위치 \(\hat{\mathcal{M}}_t\)로 전파한다. 매칭 함수를 사용하여 전파된 masklet \(\hat{\mathcal{M}}_t\)를 현재 프레임에 나타나는 새로운 object mask \(\mathcal{O}_t\)와 연결한다.
\[\begin{aligned} \hat{\mathcal{M}}_t &= \textrm{propagate} (\mathcal{M}_{t-1}) \\ \mathcal{O}_t &= \textrm{detect} (I_t, P) \\ \mathcal{M}_t &= \textrm{match_and_update} (\mathcal{M}_t, \mathcal{O}_t) \\ \end{aligned}\]Tracking an Object with SAM 2 Style Propagation
첫 번째 프레임에서 감지된 모든 object에 대해 masklet이 초기화된다. 이후 각 프레임에서 tracker 모듈은 SAM 2의 video object segmentation (VOS) task와 유사한 단일 프레임 전파 단계를 통해 이전 위치 \(\mathcal{M}_{t-1}\)을 기반으로 이미 추적된 object의 새로운 masklet 위치 \(\hat{\mathcal{M}}_t\)를 예측한다. Tracker는 detector와 동일한 이미지/프레임 인코더(PE backbone)를 공유한다. 저자들은 detector를 학습시킨 후, PE를 고정시키고 SAM 2와 같이 tracker를 학습시켰다. 여기에는 프롬프트 인코더, 마스크 디코더, 메모리 인코더, 그리고 과거 프레임과 컨디셔닝 프레임의 feature를 사용하여 object의 모양을 인코딩하는 memory bank가 포함된다. 메모리 인코더는 현재 프레임의 visual feature에 대한 self-attention과 visual feature에서 memory bank의 메모리 feature으로의 cross-attention이 있는 transformer이다.
Inference 시에는 object가 memory bank에 확실하게 존재하는 프레임만 보존한다. 마스크 디코더는 인코더의 hidden state와 출력 토큰 간의 양방향 transformer이다. 모호성을 처리하기 위해 각 프레임에서 추적된 모든 object에 대해 3개의 출력 마스크와 그 신뢰도를 예측하고, 가장 신뢰도가 높은 출력을 현재 프레임의 예측 마스크로 선택한다.
Matching and Updating Based on Detections
추적된 마스크 \(\mathcal{M}_{t-1}\)를 얻은 후, 간단한 IoU 기반 매칭 함수를 통해 현재 프레임에서 detection된 마스크 \(\mathcal{O}_t\)와 매칭하고, 이를 현재 프레임의 \(\mathcal{M}_t\)에 추가한다. 매칭되지 않은 새로 detection된 모든 object에 대해 새로운 masklet을 생성한다. 특히 혼잡한 장면에서 병합 과정에서 모호성이 발생할 수 있다. 따라서 두 가지 시간적 모호성 해소 전략을 통해 이 문제를 해결한다.
- Masklet detection 점수 형태의 시간 정보를 사용하여 masklet이 temporal window 내에서 detection 결과와 얼마나 일관되게 매칭되는지 측정한다 (detection 결과와 매칭된 과거 프레임 수를 기준으로 함). Masklet의 detection 점수가 threshold 아래로 떨어지면 해당 masklet을 억제한다.
- Detector 출력을 사용하여 occlusion이나 distractor로 인한 tracker의 특정 실패 케이스를 해결한다. Tracker 자체의 예측 \(\hat{\mathcal{M}}_t\)를 대체하여 tracker에 고신뢰도 detection mask \(\mathcal{O}_t\)를 주기적으로 다시 표시한다. 이를 통해 memory bank에 tracker 자체 예측 이외의 최신의 신뢰할 수 있는 레퍼런스가 저장되도록 한다.
Instance Refinement with Visual Prompts
초기 마스크 또는 masklet 세트를 얻은 후, SAM 3는 positive click과 negative click을 사용하여 개별 마스크 또는 masklet를 개선한다. 구체적으로, 사용자 클릭이 주어졌을 때, 프롬프트 인코더를 적용하여 해당 클릭을 인코딩하고, 인코딩된 프롬프트를 마스크 디코더에 입력하여 조정된 마스크를 예측한다. 동영상에서는 마스크를 전체 동영상에 전파하여 개선된 masklet을 얻는다.
Training Stages
SAM 3는 데이터와 기능을 점진적으로 추가하는 4단계로 학습된다.
- Perception Encoder (PE) 사전 학습
- Detector 사전 학습
- Detector fine-tuning
- 고정된 backbone을 사용한 tracker 학습
Data Engine
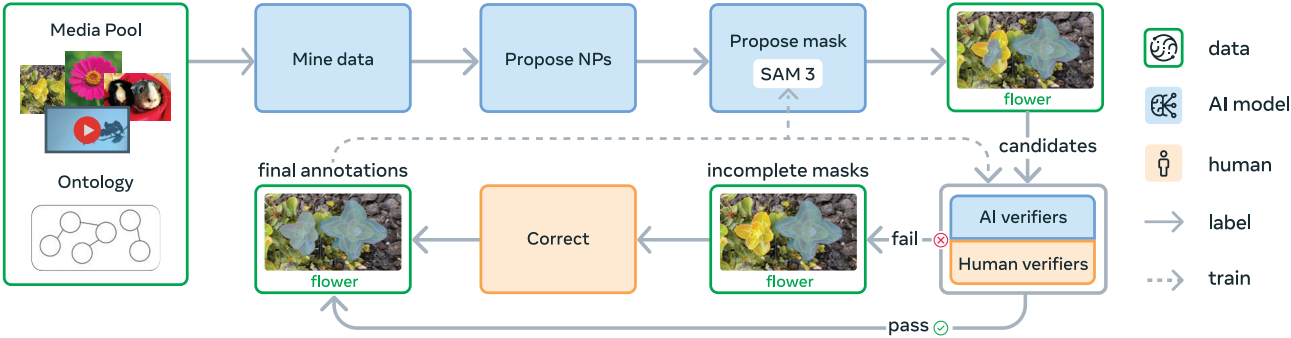
SAM 3를 활용한 PCS의 획기적인 변화를 달성하려면 기존 데이터셋을 넘어 광범위하고 다양한 개념과 도메인에 대한 학습이 필요하다. 저자들은 SAM 3, 인간, AI annotator 간의 피드백 루프를 통해 반복적으로 주석 데이터를 생성하는 효율적인 데이터 엔진을 구축하였다. 현재 버전의 SAM 3가 고품질 학습 데이터를 생성하지 못하는 미디어-구문 쌍을 적극적으로 마이닝하여 모델을 더욱 개선하였다. 특정 task를 인간의 정확도와 동일하거나 그 이상의 정확도를 가진 AI annotator에게 위임함으로써, 인간만 사용하는 파이프라인보다 처리량을 두 배 이상 향상시켰다. 데이터 엔진은 4단계로 개발되었으며, 각 단계에서는 AI 모델을 활용하여 인간의 노력을 가장 어려운 실패 사례로 유도하고 도메인 커버리지를 확장하였다. 1~3단계는 이미지에만 집중하고, 4단계에서는 동영상으로 확장하였다.
Data Engine Components
미디어 입력(이미지 또는 동영상)은 큐레이팅된 온톨로지의 도움을 받아 대규모 풀에서 마이닝된다. AI 모델은 시각적 개념을 설명하는 명사구(NP)를 제안하고, 이어서 제안된 각 NP에 대한 후보 인스턴스 마스크를 또 다른 모델(예: SAM 3)이 생성한다. 생성된 마스크는 두 단계 프로세스를 통해 검증된다.
- Mask Verification (MV): 마스크의 품질과 NP와의 관련성을 기준으로 마스크를 수락하거나 거부한다.
- Exhaustivity Verification (EV): 입력에서 모든 NP 인스턴스가 마스킹되었는지 확인한다. 완전성 검사를 통과하지 못한 모든 미디어-NP 쌍은 수동 수정 단계로 보내지며, 여기서 사람이 마스크를 추가, 제거, 편집하거나 작고 구분하기 어려운 object에 대해 “group” 마스크를 사용한다.
Phase 1: Human Verification
먼저 간단한 captioner와 parser를 사용하여 이미지-NP 쌍을 무작위로 샘플링한다. 초기 마스크 생성 모델은 SAM 2이며, 초기 검증자는 사람이다. 이 단계에서는 초기 SA-Co/HQ 데이터셋으로 430만 개의 이미지-NP 쌍을 수집했다. 이 데이터를 기반으로 SAM 3를 학습시키고 다음 단계의 마스크 생성 모델로 사용한다.
Human + AI Verification
2단계에서는 1단계에서 수집한 MV 및 EV에 대한 사람의 수락/거부 레이블을 사용하여 Llama 3.2를 fine-tuning하여 MV와 EV를 자동으로 수행하는 AI verifier를 개발하였다. 이 모델은 이미지-구문-마스크 triplet을 입력받아 마스크 품질 또는 완전성에 대한 객관식 평가를 출력한다. 이 새로운 자동 검증 프로세스를 통해 사람의 노력을 가장 까다로운 케이스에 집중할 수 있다.
저자들은 새로 수집된 데이터를 기반으로 SAM 3를 지속적으로 재학습시키고 6번 업데이트하였다. SAM 3와 AI verifier의 성능이 향상됨에 따라 레이블이 자동 생성되는 비율이 높아져 데이터 수집 속도가 더욱 빨라진다. MV와 EV에 AI verifier를 도입하면 데이터 엔진의 처리량이 사람 대비 약 두 배로 증가한다. 저자들은 NP 생성 단계를 SAM 3에 적대적인 hard negative NP를 생성하는 Llama 기반 파이프라인으로 더욱 업그레이드하였다. 2단계에서는 SA-Co/HQ에 1억 2,200만 개의 이미지-NP 쌍이 추가되었다.
Phase 3: Scaling and Domain Expansion
3단계에서는 AI 모델을 사용하여 점점 더 어려워지는 케이스들을 마이닝하고 SA-Co/HQ의 도메인 커버리지를 15개 데이터셋으로 확장하였다. 도메인은 텍스트와 비전 데이터의 고유한 분포이다. 새로운 도메인에서 MV AI verifier는 zero-shot에서 우수한 성능을 보이지만, EV AI verifier는 도메인별 적정 수준의 인간 supervision을 통해 개선이 필요하다. 또한, 이미지 alt-text에서 가능한 경우 NP를 추출하고, Wikidata 기반 2,240만 노드 SA-Co 온톨로지에서 개념을 마이닝하여 long-tail의 세밀한 개념으로 개념 커버리지를 확장하였다. 저자들은 SAM 3 학습을 7회 반복하고 AI verifier 학습을 3회 반복하였으며, 1,950만 개의 이미지-NP 쌍을 SA-Co/HQ에 추가하였다.
Phase 4: Video Annotation
4단계에서는 데이터 엔진을 동영상으로 확장한다. 저자들은 이미지에서 학습된 SAM 3를 사용하여 동영상 전용 과제를 포착하는 목표 품질의 주석을 수집하였다. 동영상 프레임들은 샘플링되어 3단계의 데이터 엔진으로 전송된다. Masklet은 SAM 3를 통해 생성되고, 중복 제거 및 불필요한 마스크 제거를 통해 후처리된다. 수집된 동영상 데이터 SA-Co/VIDEO는 5.25만 개의 동영상과 46.7만 개의 masklet으로 구성된다.
Experiments
- Metric: classification-gated F1 (cgF1 = pmF1 $\times$ IL_MCC)
- localization: positive micro F1 (pmF1)
- classification: image-level Matthews Correlation Coefficient (IL_MCC)
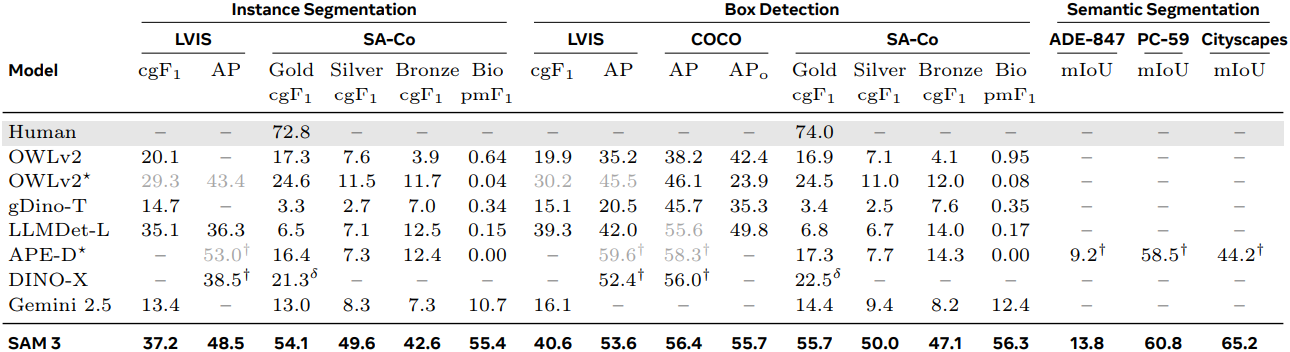
다음은 텍스트를 사용한 image concept segmentation 성능을 비교한 결과이다.
다음은 두 in-the-wild 데이터셋에 대한 zero-shot 및 10-shot transfer 성능을 비교한 결과이다.
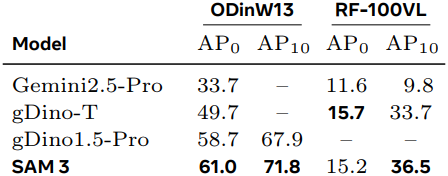
다음은 image exemplar 1개를 사용한 image concept segmentation 성능을 비교한 결과이다. (T는 텍스트, I는 이미지, AP+는 positive 예제만을 사용하였을 때의 성능)

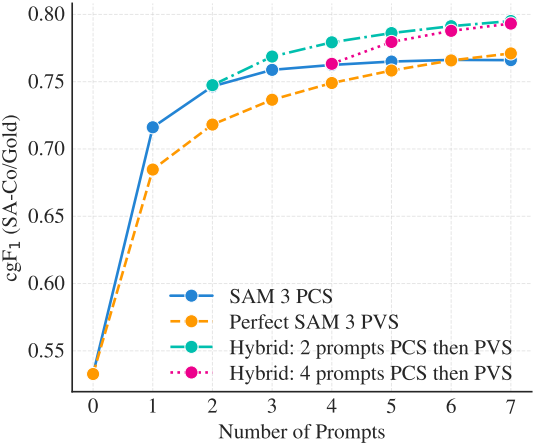
다음은 image exemplar 개수에 따른 성능을 비교한 그래프이다.
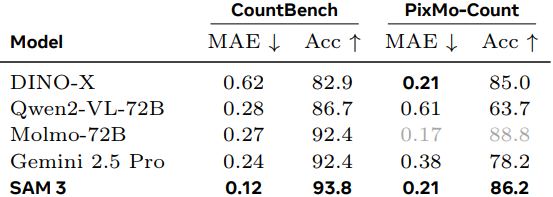
다음은 object counting 성능을 MLLM과 비교한 결과이다.
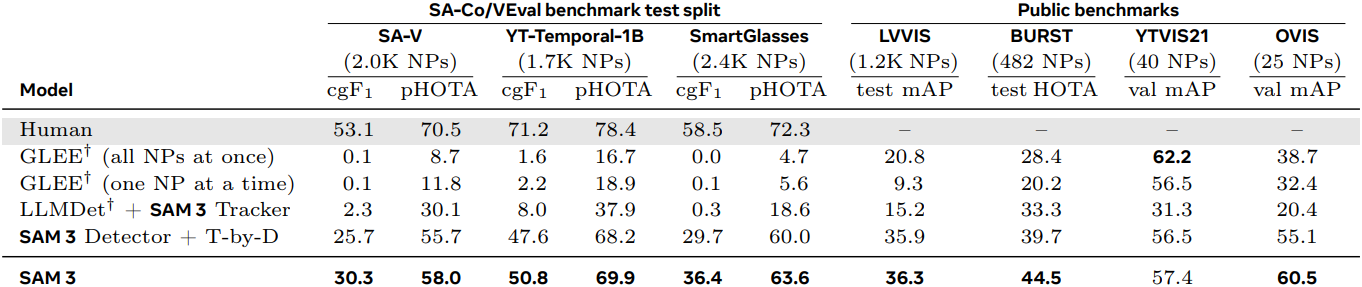
다음은 텍스트 프롬프트를 사용한 Video PCS 성능을 비교한 결과이다.
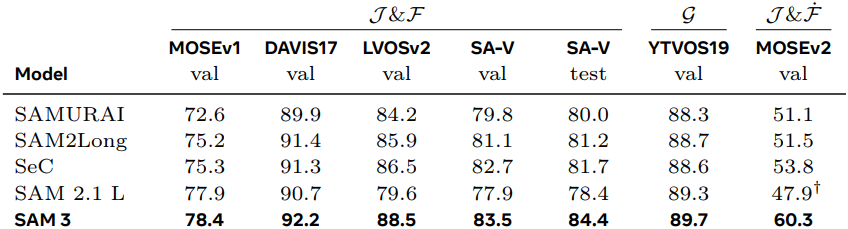
다음은 Video Object Segmentation (VOS) 성능을 비교한 결과이다.
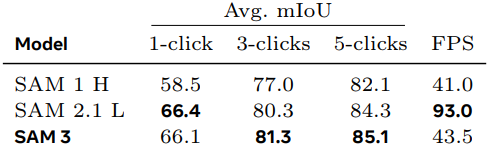
다음은 SA-37 벤치마크에서 interactive image segmentation 성능을 비교한 결과이다.
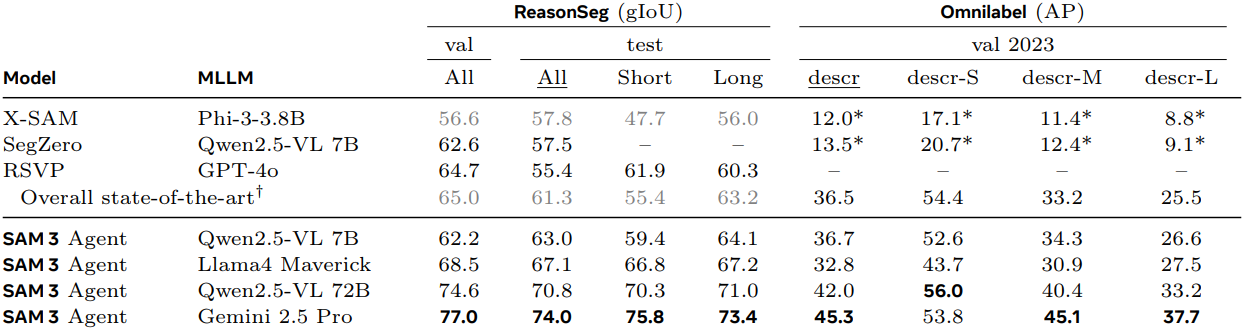
다음은 SAM 3를 MLLM과 함께 사용하였을 떄의 결과이다. MLLM은 SAM 3에 프롬프트로 넣어줄 NP query들을 제안하고 결과 마스크를 분석하며, 이 과정을 반복한다.
다음은 모델 및 데이터에 대한 ablation 결과이다.

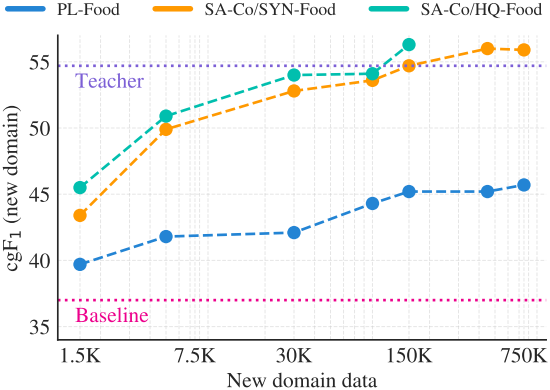
다음은 합성 데이터를 사용한 domain adaptation 성능을 비교한 결과이다.