[논문리뷰] Segment Anything in 3D with Radiance Fields
NeurIPS 2023. [Paper] [Page] [Github]
Jiazhong Cen, Jiemin Fang, Zanwei Zhou, Chen Yang, Lingxi Xie, Xiaopeng Zhang, Wei Shen, Qi Tian
SJTU | Huawei Inc. | HUST
24 Apr 2023

Introduction
Segment Anything Model (SAM)은 2D 이미지에서 무엇이든 분할할 수 있는 능력을 가진 vision foundation model이다. 그러나 SAM의 능력을 3D 장면으로 확장하는 방법은 대부분 밝혀지지 않았다. SAM의 파이프라인을 복제하여 대규모 3D 장면 세트에서 반자동으로 주석을 달 수 있다. 그러나 3D 데이터를 고밀도로 얻고 주석을 달는 것은 2D 모델보다 훨씬 복잡하기 때문에 이 데이터 기반 접근 방식은 비실용적이다.
처음부터 3D foundation model을 구축할 필요 없이 3D 표현 모델을 통해 2D foundation model (즉, SAM)에 3D 지각을 제공하면 된다. Radiance field는 미분 가능한 렌더링 기술을 사용하여 2D 멀티뷰 이미지를 3D에 연결하는 다리 역할을 한다. 본 논문은 3D segmentation을 용이하게 하기 위해 SAM을 radiance field와 통합하는 Segment Anything in 3D (SA3D)를 제안하였다.
2D 이미지 세트에서 학습된 radiance field가 주어지면 SA3D는 단일 뷰에서 프롬프트 (ex. 클릭 포인트)를 입력으로 사용하여 이 뷰에서 SAM으로 2D 마스크를 생성한다. 그런 다음 다양한 뷰에서 두 단계를 번갈아가며 수행하여 객체의 3D 마스크를 반복적으로 정제한다.
- Mask inverse rendering: SAM에서 얻은 2D segmentation mask가 density-guided inverse rendering을 통해 3D 공간에 projection된다.
- Cross-view self-prompting: radiance field를 사용하여 다른 뷰의 3D 마스크를 기반으로 2D segmentation mask를 렌더링한다 (부정확할 수 있음). 그런 다음 렌더링된 마스크에서 자동으로 생성된 몇 개의 포인트 프롬프트를 SAM에 입력하여 보다 완전하고 정확한 2D 마스크를 생성한다.
위의 절차는 모든 뷰가 샘플링될 때까지 반복적으로 실행된다. 이 간소화된 파이프라인을 통해 SA3D는 몇 분 안에 3D segmentation을 달성할 수 있다. SAM이 feature 추출 단계에서 시간 소모가 크기 때문에 모든 뷰에 대한 feature를 SAM 인코더로 미리 캐싱하고 마스크 디코딩 단계만을 수행한다. 이를 통해 SA3D의 inference 속도를 가속화할 수 있다. 결과적으로 3D-GS와 같은 효율적인 표현과 통합할 때 SA3D는 가장 빠른 속도로 2초 이내에 장면에서 3D 물체를 고품질로 분할할 수 있다. 이 가속화는 SA3D의 광범위한 적용에 도움이 된다.
SA3D는 SAM이나 radiance field를 재학습/재설계하지 않고도 다양한 시나리오에 쉽고 효율적으로 적응한다. SA3D는 radiance field에서 3D segmentation을 위한 효율적인 도구를 제공하고 2D segmentation model을 3D 공간으로 끌어올리는 일반적인 방법론을 보여주었다.
Method
1. Overall Pipeline
이미 멀티뷰 이미지 세트 $\mathcal{I}$에서 학습된 radiance field가 있다고 가정한다. Segmentation 프로세스가 시작되기 전에 먼저 SAM 인코더 $S_e$로 $\mathcal{I}$의 모든 이미지의 feature를 추출하며, 이는 feature 캐시 \(\mathcal{F} = \{\mathbf{f}_\mathbf{I} \vert \mathbf{I} \in \mathcal{I}\}\)를 구성하는 데 사용된다.
전체 프로세스는 다음과 같다.
- 이미지 \(\mathbf{I}^{(1)}\)가 사전 학습된 radiance field로 렌더링된다.
- 프롬프트 집합 \(\mathcal{P}^{(1)}\)와 렌더링된 이미지가 함께 SAM에 입력되어 해당 뷰의 2D segmentation mask \(\mathbf{M}_\textrm{SAM}^{(1)}\)이 얻어진다.
- \(\mathbf{M}_\textrm{SAM}^{(1)}\)을 3D 공간으로 projection한 뒤 mask inverse rendering을 사용하여 coarse한 3D 마스크를 형성한다.
- 3D 마스크에서 이미지 \(\mathbf{I}^{(n)}\)에 대한 2D segmentation mask \(\mathbf{I}^{(n)}\)이 렌더링된다. 렌더링된 마스크는 부정확할 수 있다.
- 렌더링된 마스크에서 포인트 프롬프트 \(\mathcal{P}^{(n)}\)을 추출하기 위해 cross-view self-prompting을 사용한다.
- 추출된 프롬프트는 이미지 \(\mathbf{I}^{(n)}\)의 캐싱된 feature \(\mathbf{f}_{\mathbf{I}^{(n)}}\)과 함께 SAM 디코더에 공급되어 정제된 2D segmentation mask \(\mathbf{M}_\textrm{SAM}^{(n)}\)이 생성된다.
- \(\mathbf{M}_\textrm{SAM}^{(n)}\)도 정제를 위해 3D 공간에 projection된다.
위의 절차는 더 많은 뷰를 탐색하면서 반복적으로 실행되며, 3D 마스크는 점점 더 정확해진다. 전체 프로세스는 2D segmentation 결과와 3D 결과를 효율적으로 연결한다. 3D 마스크 외에는 다른 파라미터는 최적화할 필요가 없다.
2. 3D Mask Representation
저자들은 더 나은 효율성과 효과성을 위해 NeRF와 3D-GS라는 두 가지 유형의 radiance field에 맞는 두 가지 3D 마스크 표현을 설계했다.
NeRF의 경우, 단순히 3D 마스크를 표현하기 위해 3D voxel grid $\mathbf{V} \in \mathbb{R}^{L \times W \times H}$를 채택한다. 각 grid vertex는 0으로 초기화된 마스크 신뢰도 점수를 저장한다. 이러한 voxel grid를 기반으로 한 뷰의 2D 마스크의 각 픽셀은 다음과 같이 렌더링된다.
\[\begin{equation} \mathbf{M} (\mathbf{r}) = \int_{t_n}^{t_f} \omega (\mathbf{r} (t)) \mathbf{V} (\mathbf{r} (t)) dt \end{equation}\]3D-GS의 경우 약간 다른 디자인을 채택하는데, 0으로 초기화된 마스크 신뢰도 점수 \(m_{\mathbf{g}_i}\)가 각 3D Gaussian \(\mathbf{g}_i\)에 대한 새로운 속성으로 통합된다. 이를 위해서는 Gaussian이 분할 대상이나 배경에 완전히 할당되어야 한다. 따라서 마스크 표현을 위해 추가 마스크 그리드를 사용할 이점이 없다. 이 디자인에서 마스크 렌더링 프로세스는 미분 가능한 rasterization 알고리즘을 원활하게 사용할 수 있다.
\[\begin{equation} \mathbf{M} (\mathbf{r}) = \sum_{i=1}^{\vert \mathcal{G}_r \vert} \omega_{\mathbf{g}_i} m_{\mathbf{g}_i} \end{equation}\]또한 이 수정은 두 가지 이점을 제공한다.
- GPU 메모리 사용량 감소: 장면에서 3D Gaussian의 수는 1,000만 개를 넘지 않는데, $320^3$ 해상도 마스크 그리드에는 약 3,300만 개의 값이 필요하다. 따라서 각 Gaussian에 속성을 첨부하면 메모리 효율성이 훨씬 높아진다.
- 계산 소모량 감소: 그리드에 마스크 신뢰도를 저장하려면 렌더링 단계에서 각 Gaussian의 신뢰도 점수에 액세스하기 위해 추가 쿼리가 필요하므로 계산 오버헤드가 증가한다.
3. Mask Inverse Rendering
렌더링된 이미지 $\mathbf{I}$의 각 픽셀 색상은 해당 광선을 따라 가중치가 적용된 색상의 합으로 결정된다. NeRF에서 가중치 \(\omega (\mathbf{r} (t))\), 3D-GS에서 \(\{\omega_{\mathbf{g}_i} \vert \mathbf{g}_i \in \mathcal{G}_r\}\)는 3D 공간 내의 물체 구조를 나타내며, 여기서 높은 가중치는 물체 표면에 가까운 포인트를 나타낸다. Mask inverse rendering은 이러한 가중치를 기반으로 3D 마스크를 형성하기 위해 2D 마스크를 3D 공간으로 projection하는 것을 목표로 한다.
SAM에서 생성된 마스크를 \(\mathbf{M}_\textrm{SAM} (\mathbf{r})\)라 하자. \(\mathbf{M}_\textrm{SAM} (\mathbf{r}) = 1\)일 때 mask inverse rendering의 목표는 $\omega$에 대해 NeRF는 \(\mathbf{V} (\mathbf{r}(t))\), 3D-GS는 \(\{m_{\mathbf{g}_i} \vert \mathbf{g}_i \in \mathcal{G}_r\}\)을 증가시키는 것이다. 이는 gradient descent로 최적화할 수 있다. 이를 위해 mask projection loss를 \(\mathbf{M}_\textrm{SAM} (\mathbf{r})\)과 \(\mathbf{M} (\mathbf{r})\)의 음의 곱으로 정의한다.
\[\begin{equation} \mathcal{L}_\textrm{proj} = - \sum_{\mathbf{r} \in \mathcal{R} (\mathbf{I})} \mathbf{M}_\textrm{SAM} (\mathbf{r}) \cdot \mathbf{M} (\mathbf{r}) \end{equation}\]($\mathcal{R}(I)$는 이미지 $I$의 광선 집합)
Mask projection loss는 radiance field의 형상과 SAM의 segmentation 결과가 모두 정확하다는 가정에 따라 구성된다. 그러나 실제로는 항상 그런 것은 아니기 때문에 멀티뷰 마스크 일관성에 따라 3D 마스크 그리드를 최적화하기 위해 loss에 음의 정제 항을 추가한다.
\[\begin{aligned} \mathcal{L}_\textrm{proj} = \; & - \sum_{\mathbf{r} \in \mathcal{R} (\mathbf{I})} \mathbf{M}_\textrm{SAM} (\mathbf{r}) \cdot \mathbf{M} (\mathbf{r}) \\ & + \lambda \sum_{\mathbf{r} \in \mathcal{R} (\mathbf{I})} (1 - \mathbf{M}_\textrm{SAM} (\mathbf{r})) \cdot \mathbf{M} (\mathbf{r}) \end{aligned}\]이 항을 사용하면 SAM이 다른 뷰에서 영역을 일관되게 전경으로 예측하는 경우에만 SA3D가 해당 3D 영역을 전경으로 표시한다.
4. Cross-view Self-prompting
Mask inverse rendering은 2D 마스크를 3D 공간에 projection하여 대상 물체의 3D 마스크를 형성할 수 있도록 한다. 정확한 3D 마스크를 구성하려면 다양한 뷰에서 많은 2D 마스크를 projection해야 한다. SAM은 적절한 프롬프트가 주어지면 고품질 segmentation 결과를 제공할 수 있다. 그러나 모든 뷰에서 프롬프트를 수동으로 선택하는 것은 시간이 많이 걸리고 실용적이지 못하다. 저자들은 다양한 뷰에 대한 프롬프트를 자동으로 생성하는 cross-view self-prompting 메커니즘을 제안하였다. 구체적으로, 먼저 3D 마스크에서 새로운 뷰에 대한 2D segmentation mask $\mathbf{M}^{(n)}$을 렌더링한다. 그런 다음 렌더링된 마스크에서 포인트 프롬프트를 얻는다.
Self-prompting Strategy
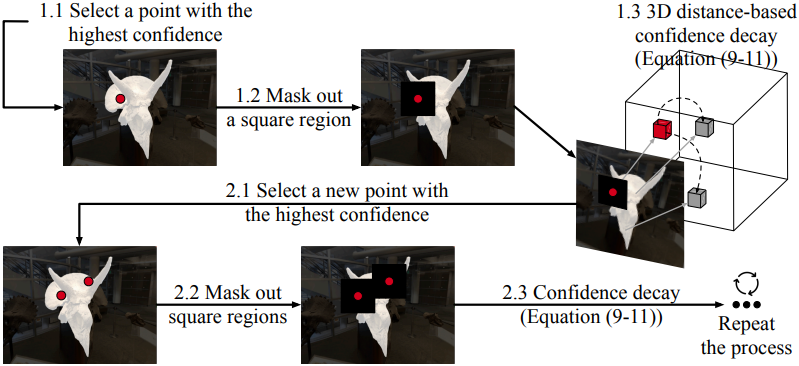
부정확한 2D 렌더링 마스크 \(\mathbf{M}^{(n)}\)이 주어졌을 때, self-prompting 전략은 이로부터 일련의 프롬프트 포인트 \(\mathcal{P}_s\)를 추출하는 것을 목표로 하며, 이는 SAM이 가능한 한 정확한 2D segmentation 결과를 생성하는 데 도움이 될 수 있다. \(\mathbf{M}^{(n)}\)은 일반적인 2D 비트맵이 아니라 신뢰도 점수 맵이다. 저자들은 이 신뢰도 점수와 radiance field에서 제공하는 3D prior를 사용하는 간단하면서도 효과적인 self-prompting 전략을 제안하였다.
\(\mathcal{P}_s\)가 공집합으로 초기화되므로 첫 번째 프롬프트 포인트 \(\mathbf{p}_0\)는 가장 마스크 신뢰도 점수가 높은 포인트로 선택된다.
\[\begin{equation} \mathbf{p}_0 = \underset{\mathbf{p}}{\arg \max} \{ \mathbf{M}^{(n)} (\mathbf{p}) \vert \mathbf{p} \in \mathcal{R} (\mathbf{I}^(n))\} \end{equation}\]새로운 프롬프트 포인트를 선택하기 위해 먼저 각 기존 포인트 프롬프트 \(\hat{p} \in \mathcal{P}_s\)를 중심으로 하는 \(\mathbf{M}^{(n)}\)의 정사각형 모양 영역을 마스크 아웃한다. 사전 학습된 radiance field에서 깊이 $z(\mathbf{p})$를 추정할 수 있기 때문에 2D 픽셀 $\mathbf{p}$를 3D 포인트 $\mathcal{G}(\mathbf{p})$로 변환한다.
\[\begin{equation} \mathcal{G} (\mathbf{p}) = \begin{bmatrix} x(\mathcal{G}(\mathbf{p})) \\ y(\mathcal{G}(\mathbf{p})) \\ z(\mathcal{G}(\mathbf{p})) \end{bmatrix} = z (\mathbf{p}) \mathbf{K}^{-1} \begin{bmatrix} x(\mathbf{p}) \\ y(\mathbf{p}) \\ 1 \end{bmatrix} \end{equation}\]($x(\mathbf{p})$, $y(\mathbf{p})$는 $\mathbf{p}$의 2D 좌표, $\mathbf{K}$는 카메라 intrinsics)
새로운 프롬프트 포인트는 기존 프롬프트 포인트와 가깝지만 높은 신뢰 점수를 가질 것으로 예상된다. 두 가지 요소를 고려하여 신뢰도 점수에 감쇠 항을 도입한다. \(\mathbf{M}^{(n)}\)의 나머지 포인트 $\mathbf{p}$에 대해 감쇠 항은 다음과 같다.
\[\begin{equation} \Delta \mathbf{M}^{(n)} (\mathbf{p}) = \min \{ \mathbf{M}^{(n)} (\hat{\mathbf{p}}) \cdot d (\mathcal{G} (\mathbf{p}), \mathcal{G} (\hat{\mathbf{p}})) \; \vert \; \hat{\mathbf{p}} \in \mathcal{P}_s \} \end{equation}\]($d(\cdot, \cdot)$는 최소-최대 정규화된 유클리드 거리)
그러면 감쇠된 마스크 신뢰도 점수 \(\tilde{\mathbf{M}}^{(n)} (\mathbf{p})\)는 다음과 같다.
\[\begin{equation} \tilde{\mathbf{M}}^{(n)} (\mathbf{p}) = \mathbf{M}^{(n)} (\hat{\mathbf{p}}) - \Delta \mathbf{M}^{(n) (\mathbf{p})} \end{equation}\]가장 높은 감쇠된 점수를 갖는 나머지 포인트가 프롬프트 세트에 추가된다.
\[\begin{equation} \mathbf{p}^\ast = \underset{\mathbf{p}}{\arg \max} \{ \tilde{\mathbf{M}}^{(n)} (\mathbf{p}) \vert \mathbf{p} \in \mathcal{R} (\mathbf{I}^{(n)}) \} \\ \mathcal{P}_s \leftarrow \mathcal{P}_s \cup \{ \mathbf{p}^\ast \} \end{equation}\]위의 선택 프로세스는 프롬프트 수가 threshold $n_p$에 도달하거나 \(\tilde{\mathbf{M}}^{(n)} (\mathbf{p})\)의 최대값이 0보다 작을 때까지 반복된다.
IoU-aware View Rejection
대상 물체가 심하게 가려진 뷰에서 렌더링되는 경우 SAM은 잘못된 분할 결과를 생성하고 3D 마스크의 품질을 저하시킬 수 있다. 이러한 상황을 피하기 위해 렌더링된 마스크 \(\mathbf{M}^{(n)}\)과 SAM 예측 \(\mathbf{M}_\textrm{SAM}^{(n)}\) 사이의 IoU를 기반으로 하는 view rejection 메커니즘을 도입한다. IoU가 threshold $\tau$ 아래로 떨어지면 SAM의 예측은 거부되고 이 iteration에서 mask inverse rendering 단계는 건너뛴다.
5. Eliminating Ambiguous Gaussians in 3D-GS

3D-GS에서 세분화 대상을 검색하는 직관적인 방법은 미리 정해진 threshold (default 0) 아래의 마스크 신뢰도 점수를 가진 3D Gaussian을 버리는 것이다. 그러나 3D Gaussian은 물체 개념을 고려하지 않고 멀티뷰 RGB 이미지에서 학습되었기 때문에 두 물체 사이에 여러 개의 모호한 Gaussian이 있다. 위 그림에서 볼 수 있듯이 배경을 제거한 후 이러한 Gaussian이 나타나 정확성을 손상시킨다. 이러한 모호한 Gaussian을 제거하기 위한 제거 전략을 도입한다.
Segmentation 과정에서 SAM에서 추출한 모든 2D 마스크와 IoU-aware view rejection 메커니즘에 사용된 IoU 점수를 유지한다. Segmentation을 완료한 후 배경으로 분류된 3D Gaussian을 제거하고 보존된 마스크를 다시 적용하여 mask inverse rendering을 다시 진행한다. Threshold $\tau$ 아래의 IoU 점수를 가진 뷰는 삭제된다. 이 단계에서 음의 정제 항이 모호한 Gaussian 대부분을 감지하여 제거할 수 있다.
Experiments
- 데이터셋: Neural Volumetric Object Selection (NVOS), SPIn-NeRF, Replica
- 구현 디테일
1. Quantitative Results
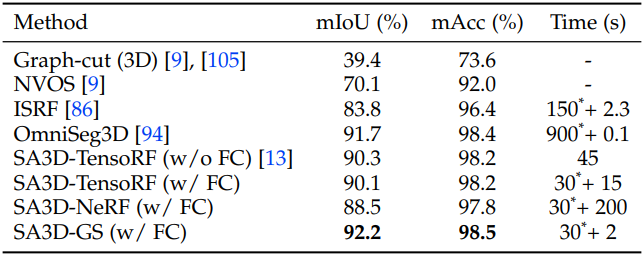
다음은 NVOS 데이터셋에서의 성능을 다른 방법들과 비교한 표이다. (FC: feature cache)
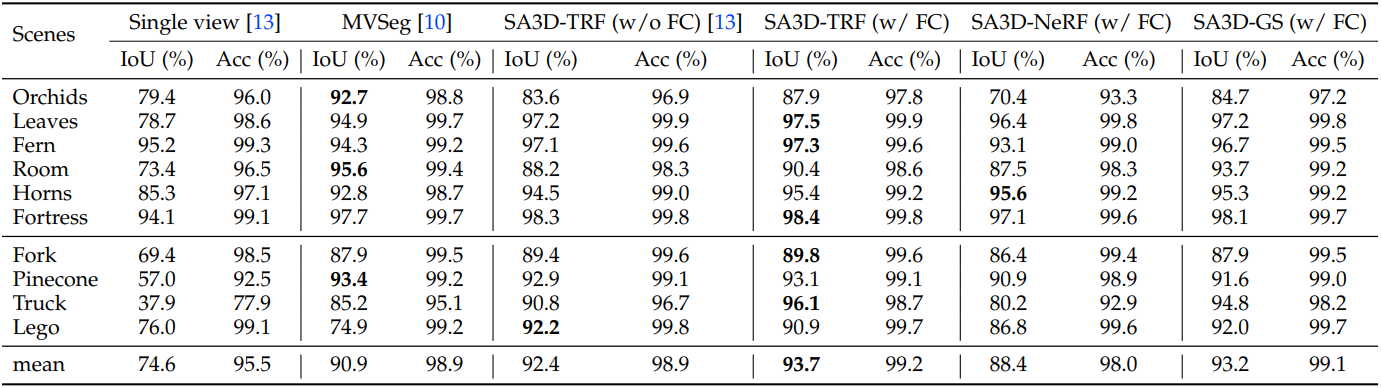
다음은 SPIn-NeRF 데이터셋에서의 성능을 다른 방법들과 비교한 표이다.
다음은 Replica 데이터셋에서의 mIoU를 다른 방법들과 비교한 표이다.

2. Qualitative Results
다음은 여러 장면에서의 결과를 시각화한 것이다.

다음은 텍스트 프롬프트를 사용한 3D segmentation 결과이다.

다음은 3D 마스크를 4D로 확장하여 여러 물체들을 동시에 분할한 결과이다.

다음은 OmniSeg3D와 비교한 결과이다.

3. Ablative Studies
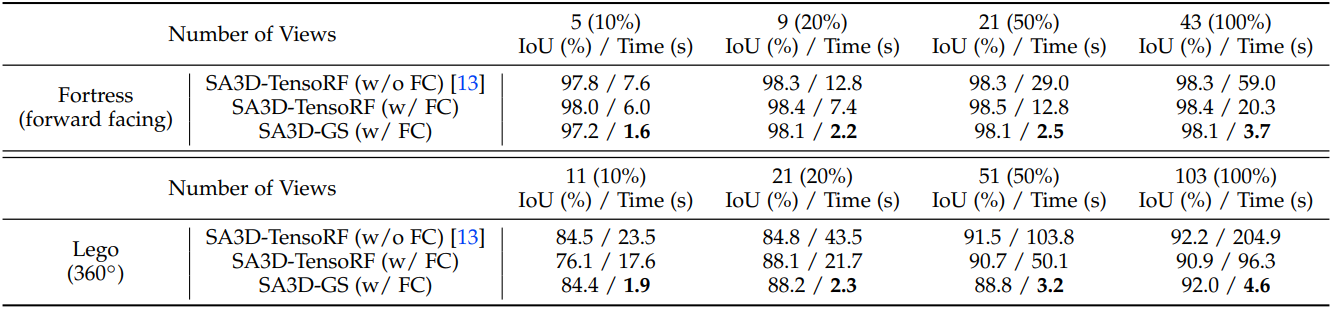
다음은 3D 마스크 생성을 위해 사용된 뷰 수에 대한 ablation 결과이다.
다음은 $\tau$와 $\lambda$에 대한 ablation 결과이다. (Replica office_0)


다음은 self-prompting 포인트 수 $n_p$에 대한 ablation 결과이다.

다음은 신뢰도 감쇠 항에 대한 ablation 결과이다.

다음은 2D segmentation model에 대한 ablation 결과이다.

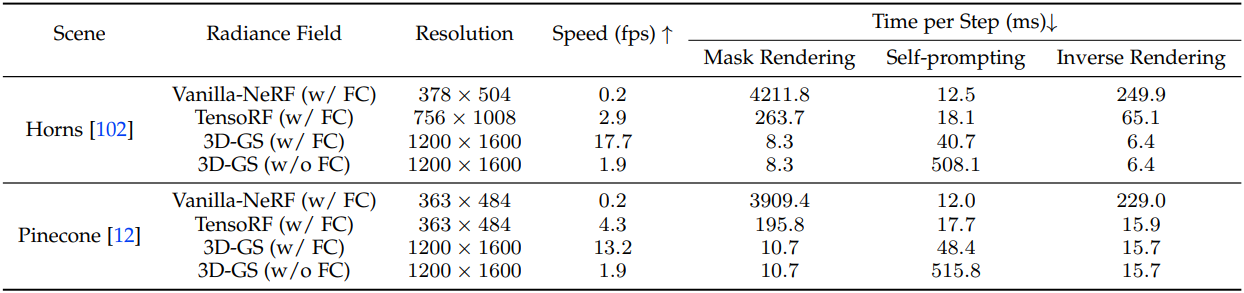
다음은 다양한 radiance field에 따른 시간 소모를 분석한 표이다.
다음은 3D 마스크 그리드의 해상도에 대한 ablation 결과이다.

다음은 모호한 Gaussian 제거 전략에 대한 ablation 결과이다.

Discussion
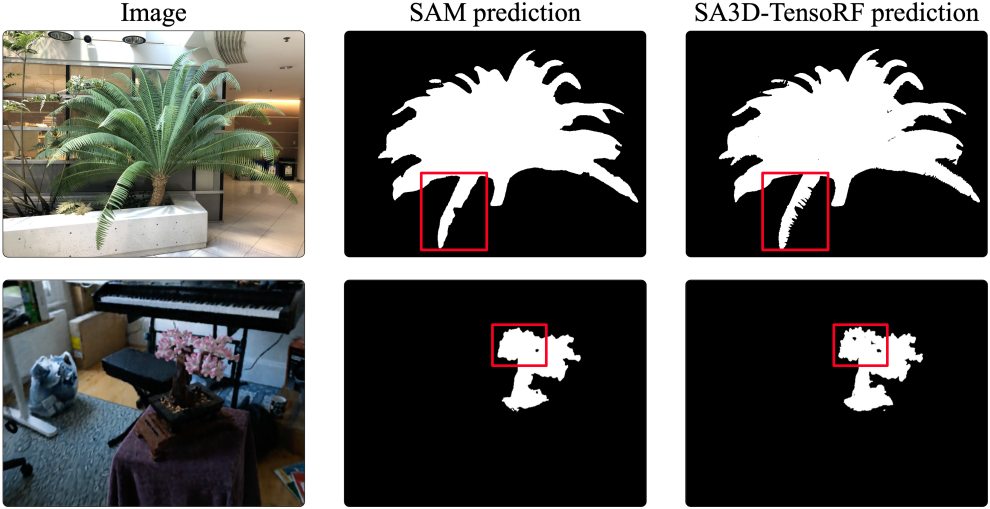
위에서 볼 수 있듯이 radiance field은 SAM의 segmentation 품질을 개선하는 데 도움이 될 수 있다.
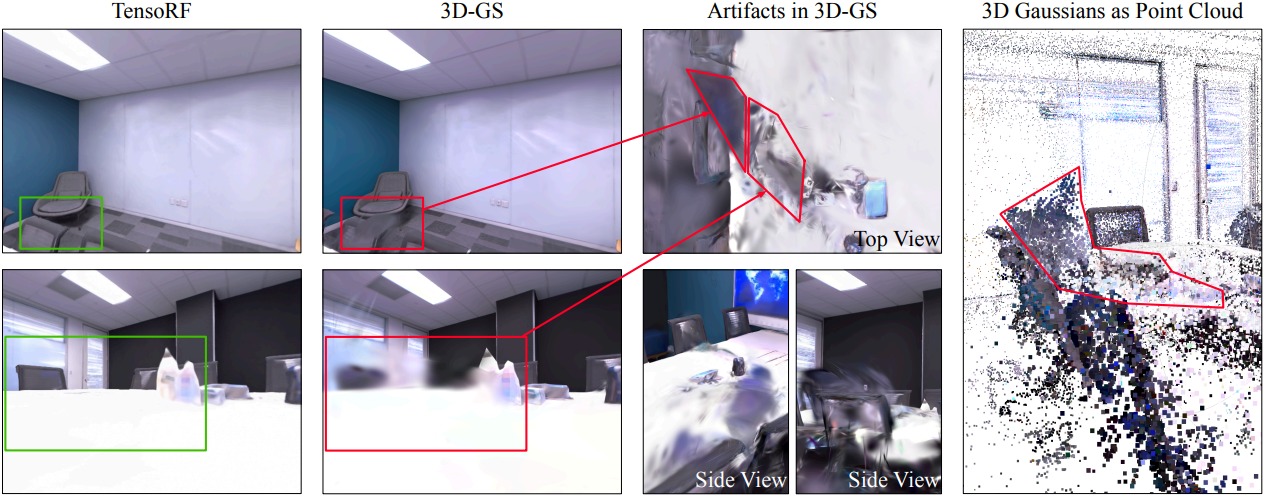
반면, 잘못 학습된 형상은 SA3D를 혼란스럽게 만들고 성능 저하로 이어진다.