[논문리뷰] DETRs Beat YOLOs on Real-time Object Detection (RT-DETR)
CVPR 2024. [Paper] [Github]
Wenyu Lv, Yian Zhao, Shangliang Xu, Jinman Wei, Guanzhong Wang, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu
Baidu Inc.
17 Apr 2023
Introduction
Object detection은 이미지에서 물체를 식별하고 위치를 파악하는 기본적인 비전 task이다. 최신 object detector에는 CNN 기반과 Transformer 기반이라는 두 가지 아키텍처가 있다. 지난 몇 년 동안 CNN 기반 object detector에 대한 광범위한 연구가 있었다. 이러한 detector의 아키텍처는 초기 2단계에서 1단계로 진화했으며 anchor-based 및 anchor-free 두 가지 detection 패러다임이 등장했다. 이러한 연구들은 detection 속도와 정확성 모두에서 상당한 진전을 이루었다. Transformer 기반 object detector(DETR)는 Non-Maximum Suppression(NMS)과 같은 다양한 수작업 구성 요소를 제거하여 제안된 이후 학계에서 많은 관심을 받았다. 이 아키텍처는 object detection 파이프라인을 크게 단순화하고 end-to-end object detection을 실현하였다.
실시간 object detection은 중요한 연구 분야이며 물체 추적, 감시 카메라, 자율 주행 등과 같은 광범위한 응용 분야를 가지고 있다. 기존 실시간 detector는 일반적으로 detection 속도와 정확도 사이의 합리적인 trade-off를 달성하는 CNN 기반 아키텍처를 채택하였다. 그러나 이러한 실시간 detector에는 일반적으로 후처리를 위해 NMS가 필요하다. 이는 일반적으로 최적화가 어렵고 충분히 견고하지 않아 detector의 inference 속도가 지연된다. 최근 학습 수렴을 가속화하고 최적화 난이도를 낮추려는 연구자들의 노력으로 Transformer 기반 detector가 놀라운 성능을 달성했다. 그러나 DETR의 높은 계산 비용 문제는 효과적으로 해결되지 않았으며, 이로 인해 DETR의 실제 적용이 제한되고 결과적으로 DETR의 이점을 최대한 활용할 수 없게 되었다. 이는 object detection 파이프라인이 단순화되었음에도 불구하고 모델 자체의 높은 계산 비용으로 인해 실시간 object detection을 구현하기 어렵다는 것을 의미한다. 위의 질문들은 실시간 detector에서 NMS로 인한 지연을 방지하기 위해 end-to-end detector를 최대한 활용하여 DETR을 실시간 시나리오로 확장할 수 있는지 고려하도록 저자들에게 자연스럽게 영감을 주었다.
위의 목표를 달성하기 위해 저자들은 DETR을 다시 생각하고 핵심 구성 요소에 대한 상세한 분석과 실험을 수행하여 불필요한 계산 중복을 줄였다. 특히, 멀티스케일 feature를 도입하면 학습 수렴을 가속화하고 성능을 향상시키는 데 도움이 되지만 인코더로 공급되는 시퀀스 길이가 크게 늘어난다. 결과적으로 Transformer 인코더에서 높은 계산 비용이 발생한다. 따라서 저자들은 실시간 object detection을 달성하기 위해 원래 Transformer 인코더를 대체할 효율적인 하이브리드 인코더를 설계하였다. 멀티스케일 feature의 스케일 내 상호 작용과 스케일 간 융합을 분리함으로써 인코더는 다양한 스케일의 feature들을 효율적으로 처리할 수 있다. 또한 디코더의 object query 초기화 방식이 detection 성능에 중요하다. 성능을 더욱 향상시키기 위해 학습 중에 IoU 제약 조건을 제공하여 디코더에 더 높은 품질의 초기 object query를 제공하는 IoU-aware query selection을 제안하였다. 또한 제안된 detector는 재학습 없이 다양한 디코더 레이어를 사용하여 inference 속도의 유연한 조정을 지원한다. 이는 DETR 아키텍처의 디코더 설계의 이점을 누리고 실시간 detector의 실제 적용을 용이하게 한다.
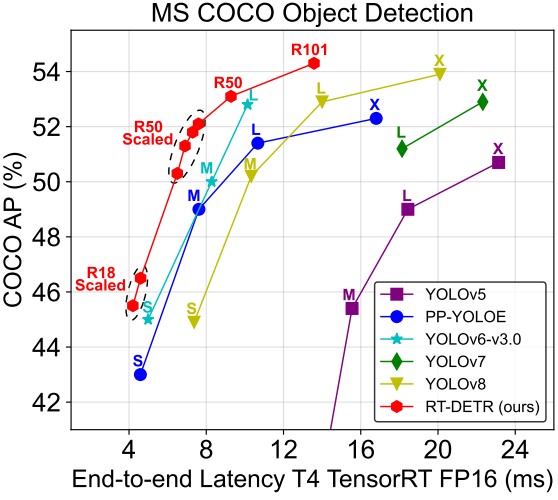
본 논문에서는 최초의 실시간 end-to-end object detector인 Real-Time DEtection TRansformer(RT-DETR)을 제안하였다. RT-DETR은 정확도와 속도 측면에서 SOTA 실시간 detector보다 성능이 뛰어날 뿐만 아니라 후처리가 필요하지 않으므로 detector의 inference 속도가 지연되지 않고 안정적으로 유지되어 end-to-end detection 파이프라인의 장점을 최대한 활용한다. RT-DETR-L은 COCO val2017에서 53.0% AP와 NVIDIA Tesla T4 GPU에서 114 FPS를 달성하였으며, RT-DETR-X는 54.8% AP와 74 FPS를 달성하여 두 가지 모두에서 동일한 스케일의 최신 YOLO detector보다 속도와 정확성이 뛰어나다. 따라서 RT-DETR은 실시간 object detection을 위한 새로운 SOTA가 되었다. 또한 제안된 RT-DETR-R50은 53.1% AP 및 108 FPS를 달성하였으며, 이는 DINO-Deformable-DETR-R50보다 정확도가 2.2% AP만큼 뛰어나고, FPS가 약 21배 더 뛰어나다 (108 FPS vs 5 FPS).
End-to-end Speed of Detectors
1. Analysis of NMS
NMS는 object detection에 널리 채택된 후처리 알고리즘으로, detector에서 출력된 중복되는 예측 상자를 제거하는 데 사용된다. NMS에는 score threshold와 IoU threshold라는 두 가지 hyperparameter가 필요하다. 특히, score threshold보다 낮은 점수를 갖는 예측 상자는 직접 필터링되며, 두 예측 상자의 IoU가 IoU threshold를 초과할 때마다 점수가 낮은 상자는 제거된다. 이 프로세스는 모든 카테고리의 모든 상자가 처리될 때까지 반복적으로 수행된다. 따라서 NMS의 실행 시간은 주로 입력 예측 상자의 수와 2개의 hyperparameter에 따라 달라진다.
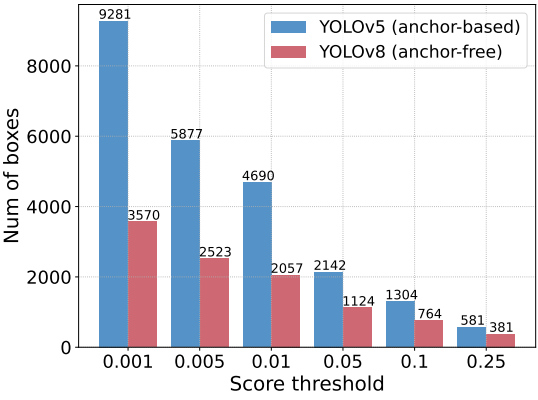
저자들은 이 의견을 확인하기 위해 YOLOv5(anchor-based)와 YOLOv8(anchor-free)을 실험에 활용하였다. 먼저 출력 상자가 동일한 입력 이미지를 사용하여 서로 다른 score threshold로 필터링된 후 남아 있는 예측 상자 수를 계산한다. 위 그래프는 0.001에서 0.25까지의 score threshold를 샘플링하여 두 detector의 남은 예측 상자를 계산하고 이를 히스토그램으로 그린 것이며, NMS가 hyperparameter에 취약하다는 것을 직관적으로 반영한다.
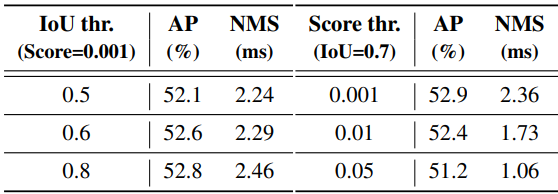
또한 저자들은 YOLOv8을 예로 들어 COCO val2017의 모델 정확도와 다양한 NMS hyperparameter 하에서 NMS 연산의 실행 시간을 평가하였다. 실험에서 채택한 NMS 후처리 연산은 EfficientNMSFilter, RadixSort, EfficientNMS 등을 포함한 여러 CUDA 커널을 포함하는 TensorRT efficientNMSPlugin을 참조하며 EfficientNMS 커널의 실행 시간만 보고하였다. T4 GPU에서 속도를 테스트했는데, 위 실험의 입력 이미지와 전처리가 동일하다. 저자들이 사용한 hyperparameter와 해당 결과는 위 표와 같다.
2. End-to-end Speed Benchmark
저자들은 다양한 실시간 detector의 end-to-end inference 속도를 공정하게 비교할 수 있도록 end-to-end 속도 테스트 벤치마크를 설정하였다. NMS의 실행 시간은 입력 이미지에 의해 영향을 받을 수 있다는 점을 고려하여 벤치마크 데이터셋을 선택하고 여러 이미지에 대한 평균 실행 시간을 계산해야 한다. 벤치마크는 COCO val2017을 기본 데이터셋으로 채택하고 후처리가 필요한 실시간 detector를 위해 TensorRT의 NMS 후처리 플러그인을 추가한다. 구체적으로, 벤치마크 데이터셋에서 가져온 해당 정확도의 hyperparameter에 따라 detector의 평균 inference 시간을 테스트하고 IO 및 메모리 복사 연산은 제외한다.
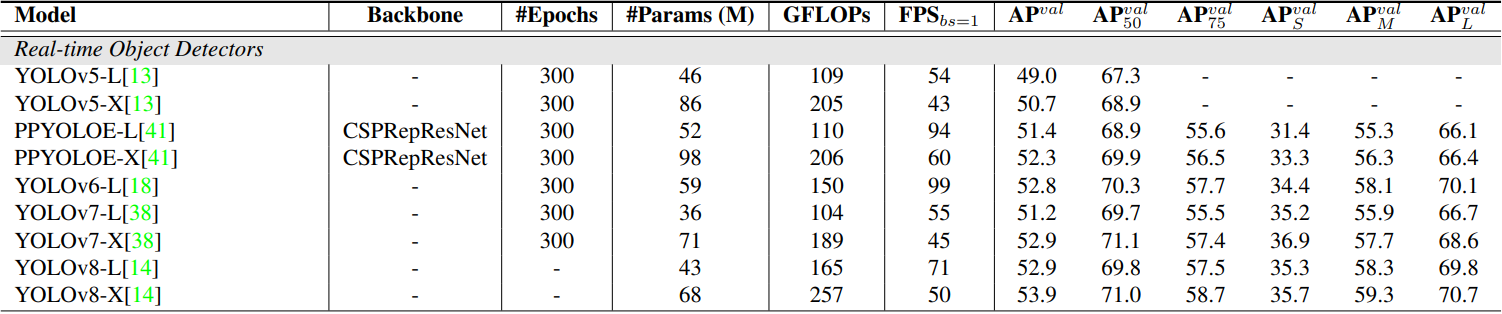
저자들은 이 벤치마크를 활용하여 anchor-based detector인 YOLOv5, YOLOv7과 anchor-free detector인 PP-YOLOE, YOLOv6, YOLOv8의 end-to-end 속도를 T4 GPU에서 테스트하였다. 테스트 결과는 위 표와 같다. 결과를 보면 NMS 후처리가 필요한 실시간 detector의 경우 anchor-free detector가 anchor-based detector보다 동일한 정확도로 성능이 뛰어나며, 이는 전자가 후자보다 후처리 시간이 훨씬 덜 걸리기 때문이다. 이 현상의 이유는 anchor-based detector가 anchor-free detector보다 더 많은 예측 상자를 생성하기 때문이다 (테스트된 detector에서는 3배 더 많음).
The Real-time DETR
1. Model Overview
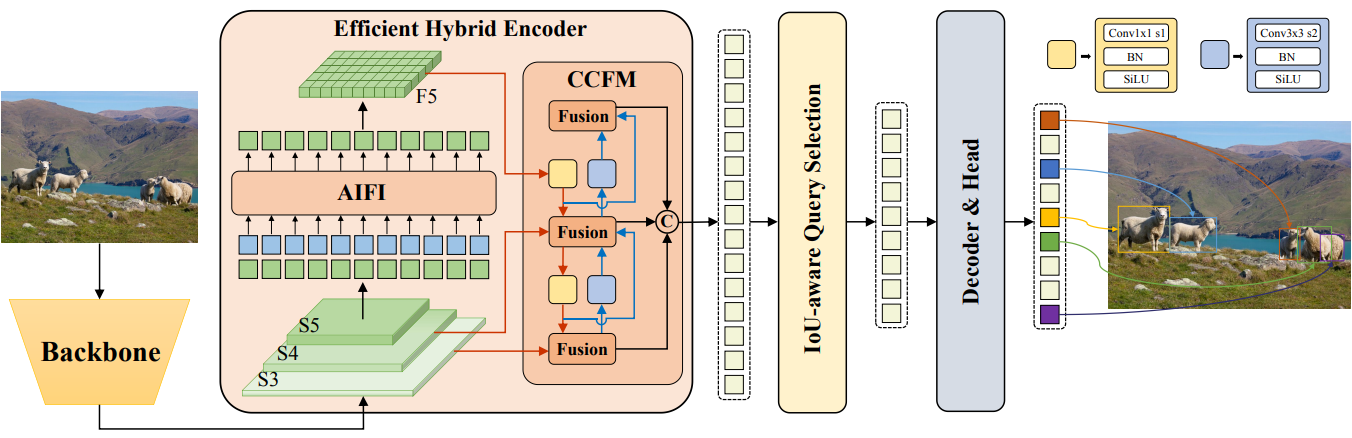
제안된 RT-DETR은 백본, 하이브리드 인코더, 보조 예측 헤드가 있는 Transformer 디코더로 구성된다. 모델 아키텍처의 개요는 위 그림에 설명되어 있다. 특히 백본의 마지막 세 단계의 출력 feature \(\{S_3, S_4, S_5\}\)를 인코더에 대한 입력으로 활용한다. 하이브리드 인코더는 스케일 내 상호 작용과 스케일 간 융합을 통해 멀티스케일 feature를 일련의 이미지 feature로 변환한다. 이어서, IoU-aware query selection은 디코더에 대한 초기 object query 역할을 하기 위해 인코더 출력 시퀀스에서 고정된 개수의 이미지 feature를 선택하는 데 사용된다. 마지막으로 보조 예측 헤드가 있는 디코더는 object query를 반복적으로 최적화하여 상자와 신뢰도 점수를 생성한다.
2. Efficient Hybrid Encoder
Computational bottleneck analysis
Deformable-DETR은 학습 수렴을 가속화하고 성능을 향상시키기 위해 멀티스케일 feature 도입을 제안하고 계산을 줄이기 위한 deformable attention 메커니즘을 제안하였다. 그러나 attention 메커니즘의 개선으로 계산 오버헤드가 줄어들었음에도 불구하고 입력 시퀀스의 길이가 급격히 증가하면 여전히 인코더가 계산 병목 현상을 일으키고 DETR의 실시간 구현을 방해한다. Deformable-DETR에서 인코더는 GFLOP의 49%를 차지하지만 AP의 11%만 기여한다. 이러한 장애물을 극복하기 위해 저자들은 멀티스케일 Transformer 인코더에 존재하는 계산 중복성을 분석하고 스케일 내 및 스케일 간 feature의 동시 상호 작용이 계산적으로 비효율적임을 증명하기 위해 여러 변형들을 설계하였다.
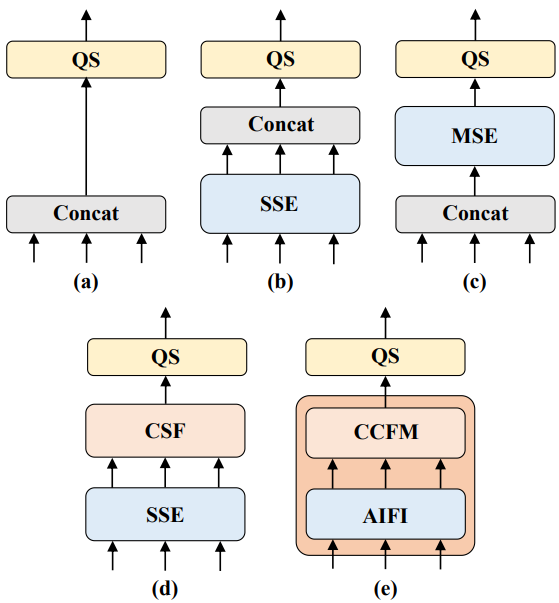
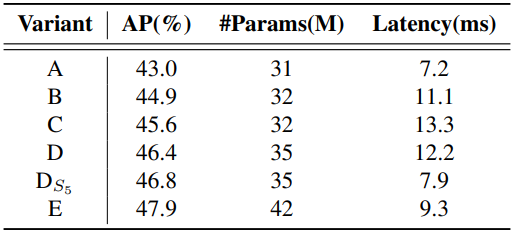
높은 수준의 feature는 이미지의 물체에 대한 풍부한 semantic 정보를 포함하는 낮은 수준의 feature에서 추출된다. 직관적으로 concatenate된 멀티스케일 feature에 대해 feature 상호 작용을 수행하는 것은 중복된다. 이 의견을 검증하기 위해 저자들은 위 그림과 같이 인코더 구조를 다시 생각하고 다양한 인코더를 사용하여 다양한 변형을 설계하였다. 변형들은 멀티스케일 feature 상호 작용을 스케일 내 상호작용과 스케일 간 융합으로 분리하여 계산 비용을 크게 줄이면서 모델 정확도를 점차적으로 향상시킨다. 먼저 DINO-R50의 멀티스케일 Transformer 인코더를 제거하여 baseline A로 사용한다. 다음으로 다양한 형태의 인코더를 삽입하여 A를 기반으로 한 일련의 변형을 생성한다.
- A → B: B는 Transformer 블록의 한 레이어를 사용하는 단일 스케일 Transformer 인코더를 삽입한다. 각 스케일의 feature는 스케일 내 feature 상호 작용을 위해 인코더를 공유한 다음 출력 멀티스케일 feature를 concatenate한다.
- B → C: C는 B를 기반으로 스케일 간 feature 융합을 도입하고 concatenate된 멀티스케일 feature를 인코더에 공급하여 feature 상호 작용을 수행한다.
- C → D: D는 멀티스케일 feature의 스케일 내 상호 작용과 스케일 간 융합을 분리한다. 먼저 단일 스케일 Transformer 인코더를 사용하여 스케일 내 상호 작용을 수행한 다음 PANet과 유사한 구조를 사용하여 스케일 간 융합을 수행한다.
- D → E: E는 저자들이 설계한 효율적인 하이브리드 인코더를 채택하였으며, D를 기반으로 멀티스케일 feature의 스케일 내 상호 작용과 스케일 간 융합을 더욱 최적화한다.
위 그림에서 QS는 query selection, SSE는 단일 스케일 인코더(single-scale encoder), MSE는 멀티스케일 인코더(multi-scale encoder), CSF는 스케일 간 융합(cross-scale fusion)이다.
Hybrid design
위의 분석을 바탕으로 저자들은 인코더의 구조를 다시 생각하고 새로운 효율적인 하이브리드 인코더를 제안하였다. 제안된 인코더는 Attention-based Intrascale Feature Interaction(AIFI) 모듈과 CNN 기반 Cross-scale Feature-fusion Module(CCFM)의 두 가지 모듈로 구성된다. AIFI는 $S_5$에서 스케일 내 상호 작용만 수행하는 D를 기반으로 계산 중복성을 더욱 줄인다. 더 풍부한 semantic 개념을 가진 상위 수준 feature에 self-attention 연산을 적용하면 이미지의 개념적 엔터티 간의 연결을 캡처할 수 있으며, 이를 통해 후속 모듈에서 이미지의 물체 감지 및 인식을 용이하게 할 수 있다.
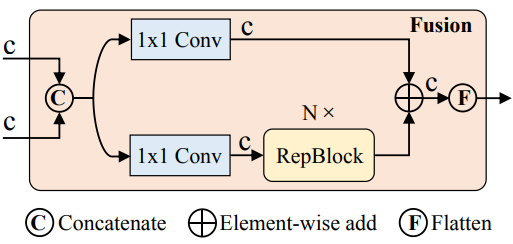
한편, 하위 수준 feature의 스케일 내 상호 작용은 semantic 개념이 부족하고 상위 수준 feature의 상호 작용과 중복 및 혼동의 위험이 있으므로 불필요하다. 저자들은 이 의견을 확인하기 위해 D의 $S_5$에서 스케일 내 상호 작용만 수행하였다. 실험 결과 D에 비해 지연 시간을 크게 줄이지만(35% 더 빠름) 정확도는 향상된다(0.4% AP 더 높음). 이 결론은 실시간 detector 설계에 매우 중요하다. CCFM도 D를 기반으로 최적화되어 convolution layer로 구성된 여러 fusion block을 융합 경로에 삽입한다. Fusion block의 역할은 인접한 feature를 새로운 feature로 융합하는 것이며 그 구조는 위 그림과 같다. Fusion block은 $N$개의 RepBlock을 포함하며 두 경로 출력은 element-wise add에 의해 융합된다. 이 프로세스를 다음과 같이 공식화할 수 있다.
여기서 $\textrm{Attn}$은 multi-head self-attention이고, $\textrm{Reshape}$은 feature의 모양을 $S_5$와 동일하게 복원하는 연산이다 ($\textrm{Flatten}$의 역연산).
3. IoU-aware Query Selection
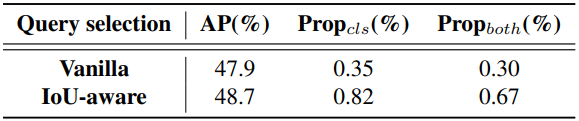
DETR의 object query는 디코더에 의해 최적화되고 예측 헤드에 의해 분류 점수 및 bounding box에 매핑되는 학습 가능한 임베딩의 집합이다. 그러나 이러한 object query는 명시적인 물리적 의미가 없기 때문에 해석하고 최적화하기가 어렵다. 이후 연구들에서는 object query의 초기화를 개선하고 이를 content query와 position query(anchor)로 확장하였다. 그 중 일부 연구들의 query 선택 방식은 분류 점수를 활용하여 인코더에서 상위 $K$개의 feature를 선택하여 object query(또는 position query만)를 초기화한다는 공통점이 있다. 그러나 분류 점수와 위치 신뢰도의 일관되지 않은 분포로 인해 일부 예측 상자는 분류 점수가 높지만 GT 상자에 가깝지 않아 분류 점수가 높고 IoU 점수가 낮은 상자가 선택되는 반면 분류 점수가 낮고 IoU 점수가 높은 상자가 제거된다. 이는 detector의 성능을 저하시킨다.
이 문제를 해결하기 위해 저자들은 학습 중에 IoU 점수가 높은 feature에 대해 높은 분류 점수를 생성하고 IoU 점수가 낮은 feature에 대해 낮은 분류 점수를 생성하도록 모델을 제한하여 IoU-aware query selection을 제안하였다. 따라서 분류 점수에 따라 모델이 선택한 상위 $K$개의 인코더 feature에 해당하는 예측 상자는 분류 점수와 IoU 점수가 모두 높다. Detector의 최적화 목적 함수를 다음과 같이 재구성한다.
\[\begin{aligned} \mathcal{L} (\hat{y}, y) &= \mathcal{L}_\textrm{box} (\hat{b}, b) + \mathcal{L}_\textrm{cls} (\hat{c}, \hat{b}, y, b) \\ &= \mathcal{L}_\textrm{box} (\hat{b}, b) + \mathcal{L}_\textrm{cls} (\hat{c}, c, \textrm{IoU}) \\ \end{aligned}\]여기서 \(\hat{y} = \{\hat{c}, \hat{b}\}\)와 \(y = \{c, b\}\)는 각각 예측과 GT를 나타내고, $c$와 $b$는 각각 카테고리와 bounding box를 나타낸다. IoU 점수를 classification branch의 목적 함수에 도입하여 positive 샘플의 분류 및 localization에 대한 일관성 제약을 도입한다.
4. Scaled RT-DETR
RT-DETR의 확장 가능한 버전을 제공하기 위해 ResNet 백본을 HGNetv2로 대체한다. 깊이 multiplier와 너비 multiplier를 사용하여 백본과 하이브리드 인코더를 함께 확장한다. 따라서 파라미터와 FPS의 수가 다른 두 가지 버전의 RT-DETR을 얻는다. 하이브리드 인코더의 경우 CCFM의 RepBlock 수와 인코더의 임베딩 크기를 각각 조정하여 깊이 multiplier와 너비 multiplier를 제어한다. 다양한 스케일의 RT-DETR은 균일한 디코더를 유지한다.
Experiments
- 데이터셋: MS-COCO
- 구현 디테일
- AIFI: Transformer layer 1개
- CCMF: base model은 RepBlock 3개
- IoU-aware query selection: 상위 300개의 인코더 feature를 선택
- 디코더의 학습 전략과 hyperparameter는 DINO를 따름
- optimizer: AdamW
- base learning rate: 0.0001
- weight decay: 0.0001
- global gradient clip norm: 0.1
- linear warmup steps: 2000
- exponential moving average (EMA) 사용 (decay: 0.9999)
- data augmentation: color distort, expand, crop, flip, resize
1. Comparison with SOTA
다음은 RT-DETR을 다른 실시간 및 end-to-end object detector와 성능을 비교한 표이다.

2. Ablation Study
다음은 Hybrid Encoder에 대한 ablation 결과이다.
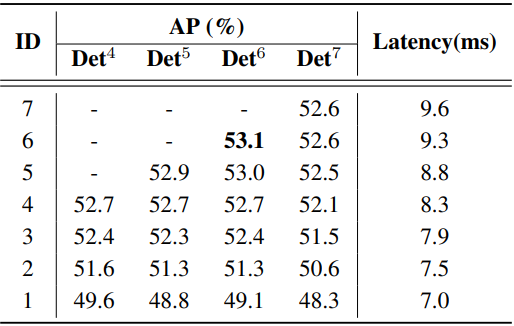
다음은 IoU-aware query selection에 대한 ablation 결과이다. Propcls와 Propboth는 각각 0.5보다 큰 분류 점수의 비율과 0.5보다 두 점수가 모두 큰 비율을 나타낸다.
다음은 디코더에 대한 ablation 결과이다.