[논문리뷰] Robust One-Shot Singing Voice Conversion (ROSVC)
arXiv 2022. [Paper] [Page]
Naoya Takahashi, Mayank Kumar Singh, Yuki Mitsufuji
Sony Group Corporation
20 Oct 2022
Introduction
Singing Voice Conversion(SVC)의 목적은 주어진 소스의 멜로디와 가사 내용을 유지하면서 소스 음성을 다른 가수의 음성으로 변환하는 것이다. Speech Voice Conversion에 비해 SVC는 음정 범위와 표현이 더 다양하고 음정 오류가 있는 경우 음정을 벗어난 것으로 인식되어 원래 멜로디를 유지하지 못하기 때문에 음정 오류에 더 민감하다. 이 문제를 해결하기 위해 많은 SVC 접근법이 제안되었으며 유망한 결과를 보여주었다. 그러나 대부분의 기존 SVC 시스템은 노래하는 목소리를 many-to-many 케이스 (또는 소스 음성이 보지 못한 가수의 음성일 수 있는 경우 any-to-many)로 알려진 학습 중에 본 음성으로 변환하는 데 중점을 둔다.
하지만 실제 응용에서 일부 깨끗한 음성은 제한된 가수로부터 수집될 수 있지만, 대상 가수로부터 깨끗한 가창 음성을 수집하는 것은 종종 어렵거나 심지어 불가능하다. 또한, 노래하는 목소리는 리버브와 반주 음악으로 녹음되는 경우가 많다. 입력에 이러한 왜곡이 있는 경우 SVC의 품질이 심각하게 저하된다. 이 문제를 완화하는 한 가지 방법은 음악 소스 분리 및 잔향 제거 알고리즘을 사용하여 녹음에서 음악과 잔향을 제거하는 것이지만, 종종 무시할 수 없는 아티팩트를 생성하며 SVC 시스템에 대한 입력에 대해 이러한 처리된 샘플을 사용하면 여전히 SVC 품질이 상당히 저하된다.
본 논문에서는 왜곡된 음성에도 강건하게 any-to-any SVC를 수행하는 robust one-shot singing voice conversion (ROSVC)를 제안한다. 제안하는 모델은 10초 미만의 가창 음성을 기준으로 삼고 inference 시간 동안 one-shot 방식으로 음원 가수의 음성을 변환한다. 이를 위해 StarGANv2을 적용한다.
StarGANv2는 domain-specific style encoder와 discriminator를 도입하여 이미지 변환 task에서 높은 샘플 품질과 다양성을 제공한다. StarGANv2는 Speech Voic Conversion (StarGANv2-VC)에 적용되었지만 다음과 같은 몇 가지 제한 사항이 있다.
- many(any)-to-many 경우로 제한되며 학습 중에 보지 못한 음성으로 변환할 수 없다.
- 노래하는 목소리에 적용하면 변환된 목소리가 음정이 맞지 않는 경우가 많다.
- 변환된 노래 음성이 종종 반주와 함께 연주되기 때문에 SVC에 중요한 피치 제어 기능이 없다.
- 노래하는 음성에 리버브와 반주 음악이 포함된 경우 변환 품질이 크게 저하된다.
이러한 문제를 해결하기 위해 one-shot SVC를 가능하게 하는 도메인에 독립적인 style encoder, 정확한 피치 제어를 가능하게 하는 AdaIN-skip 피치 컨디셔닝, 왜곡에 대한 견고성을 향상시키는 Robustify라는 2단계 학습을 도입한다.
Proposed Method
1. One-shot SVC framework
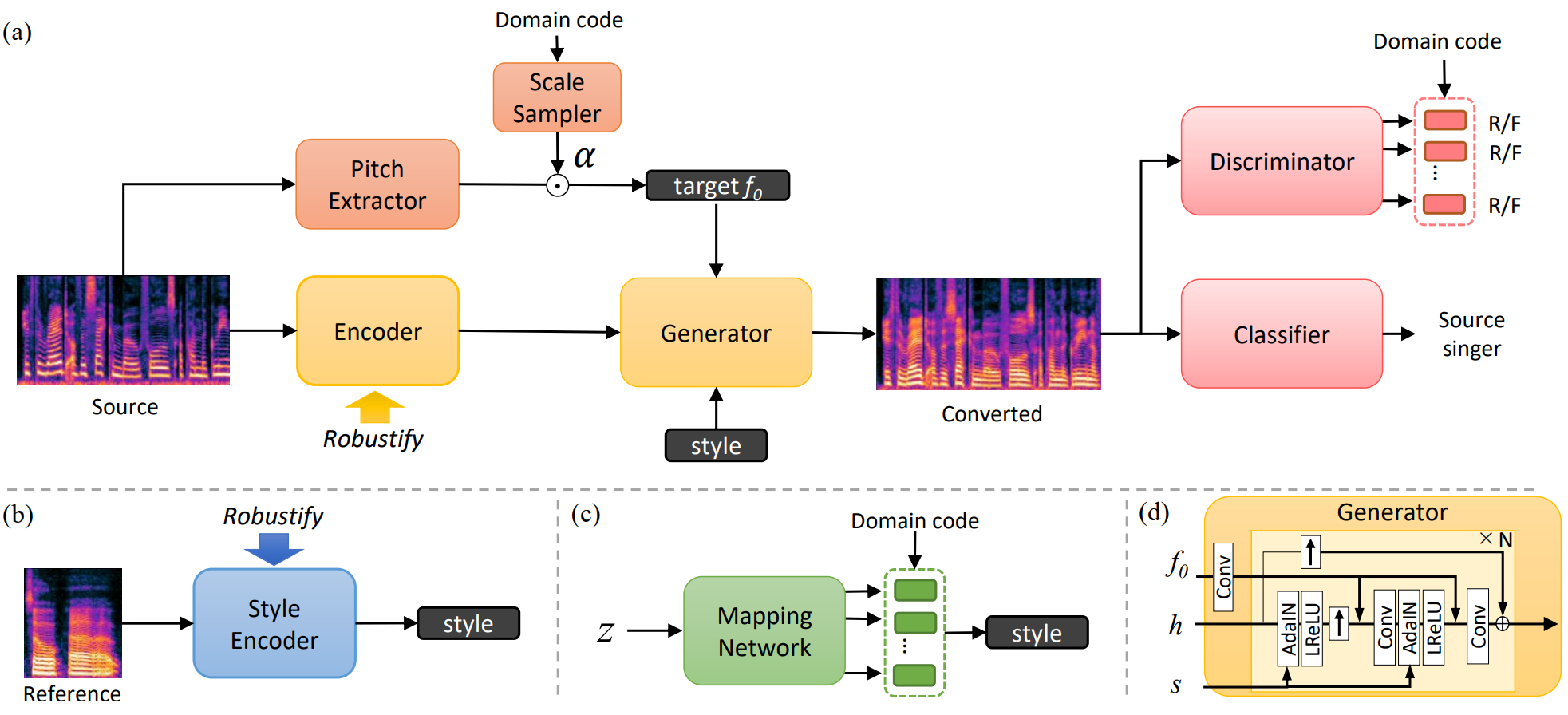
위 그림과 같이 StarGANv2를 one-shot SVC에 적용한다. Generator $G(h, f_0^{trg}, s)$는 인코더 출력 $h = E(X_{src})$, 타겟 기본 주파수(F0) $f_0^{trg}$, 스타일 임베딩 $s$를 기반으로 소스 mel-spectrogram $X_{src}$를 타겟 도메인 $X_{trg}$의 샘플로 변환한다. 여기서 도메인은 가수 ID이다. Discriminator $D$는 각 타겟 도메인에서 입력이 진짜인지 가짜인지를 분류하기 위해 domain-specific head가 뒤따르는 공유 layer로 구성되며, 다음과 같은 adversarial loss를 통해 학습된다.
Domain-specific discriminator는 generator의 출력을 현실적이고 타겟 도메인과 유사하게 만들지만 변환을 더욱 촉진하기 위해 추가 classifier $C$가 도입된다. Classifier는 소스 도메인 $y_{src}$를 식별하도록 학습되고 generator는 다음과 같은 classification loss를 통해 classifier를 속이도록 학습된다.
\[\begin{equation} L_{cl} = \mathbb{E}_{X, f_0^{trg}, s} [\textrm{CE} (C (G (h, f_0^{trg}, s), y))] \end{equation}\]여기서 $\textrm{CE}$는 cross-entropy loss이다.
스타일 임베딩은 style encoder나 mapping network에서 가져온다. 타겟 도메인 $y_{trg}$가 주어지면 mapping network $M$은 랜덤 latent coder $z \sim \mathcal{N} (0, 1)$을 $s = M(z, y_{trg})$와 같은 스타일 임베딩으로 변환한다. 원래 StarGANv2에서 mapping network, style encoder, discriminator는 domain-specific projection head를 가지고 있어 모델이 도메인별 정보를 쉽게 처리하고 도메인 내 다양성에 집중할 수 있다. 그러나 이 아키텍처는 미리 정의된 도메인 내에서 변환을 제한하며, 본 논문의 경우 many-to-many SVC이다.
본 논문은 any-to-any one-shot SVC를 활성화하기 위해 mapping network와 discriminator에 대한 domain-specific head를 유지하면서 도메인에 독립적인 style encoder $S(X)$를 사용한다. 그렇게 함으로써 style encoder는 도메인 코드를 필요로 하지 않으며 inference 시간 동안 가수의 음성을 변환할 수 있으며, domain-specific mapping network와 discriminator는 도메인별 정보를 처리하도록 모델을 계속 guide한다. 저자들은 경험적으로 이 디자인이 원래 many-to-many model에 비해 변환 품질을 저하시키지 않는다는 것을 발견했다. 본 논문의 목표는 one-shot SVC이므로 mapping network는 inference에 사용되지 않는다.
2. Pitch conditioning
Speech voice conversion과 달리 정확한 피치 재구성은 SVC가 멜로디 콘텐츠를 유지하는 데 필수적이다. StarGANv2 모델은 F0 추정 네트워크에 의해 소스에서 추출된 $f_0$ feature를 사용하여 생성을 guide하지만 출력은 소스와 유사한 정규화된 F0 궤적을 갖도록 약하게 제한된다. 따라서 변환된 샘플의 절대적인 피치는 제어할 수 없으며 종종 음정을 벗어난 음성을 생성하는 것을 발견했다. 이 문제를 해결하기 위해 목표 피치에서 generator를 컨디셔닝하고 정확한 컨디셔닝된 피치를 재구성하도록 변환된 샘플을 적용한다.
\[\begin{equation} L_{f_0} = \mathbb{E}_{X, f_0^{trg} \sim \mathcal{F}^y, s} [\| f_0^{trg} - F (G (h, f_0^{trg}, s)) \|_1] \end{equation}\]여기서 $F(X)$는 입력 X에 대하여 F0 값을 추정하는 F0 network이다. 이상적으로, 타겟 F0는 타겟 도메인의 F0 분포 $f_0^{trg} \sim \mathcal{F}^y$에서 샘플링되어야 멜로디 컨텐츠를 유지하면서 domain-specific discriminator와 classifier를 속일 수 있다. 이를 위해 소스 F0를
\[\begin{equation} \alpha = \mathcal{P} (y_{src}, y_{trg}) \end{equation}\]로 확률적으로 스케일링한다. 여기서 $\mathcal{P}$는 스케일링된 소스 F0의 F0 분포를 타겟 도메인의 F0 분포와 일치시키기 위한 scale sampler이다. 학습 셋의 가수에 대한 F0 히스토그램을 미리 계산하고 스케일링된 피치의 평균 $\textrm{mean} (\alpha f_0^{src})$이 학습하는 동안 타겟 가수의 F0 분포와 일치하도록 scale 값을 샘플링한다. Inference 시에는 단순히 평균 F0 값의 비율로 스케일 값을 계산한다.
\[\begin{equation} \alpha = \frac{\textrm{mean}(f_0^{trg})}{\textrm{mean}(f_0^{src})} \end{equation}\]컨디셔닝을 위해 AdaIN layer를 사용하는 스타일 임베딩과 달리 convolution layer에 의해 $f_0$에서 얻은 F0 feature는 AdaIN과 non-linearity 이후 입력에 concat된다. 저자들은 AdaIN 연산에서 instance normalization으로 인해 타겟 피치의 절대값이 손실되는 경향이 있기 때문에 타겟 피치를 재구성하기 위해 AdaIN layer를 skip하는 것이 필수적임을 발견했다. 처음에 F0 feature를 연결하면 모델이 절대적인 타겟 피치를 복구하는 데 어려움을 겪는다.
3. Robustify: Two-stage training for improving robustness
다음으로, 저자들은 노래하는 목소리에서 자주 발생하는 왜곡, 즉 리버브 효과와 반주 음악의 간섭에 대한 견고성을 개선하려고 시도하였다. 일부 가수로부터 깨끗한 노래 목소리를 수집하는 것이 상당히 가능하기 때문에 첫 번째 단계에서 깨끗한 데이터셋에서 one-shot SVC model을 학습시킨다. 첫 번째 단계의 loss function은 다음과 같다.
\[\begin{aligned} L_{E, G, S, M} = & \; L_{adv} + \lambda_{cl} L_{cl} + \lambda_{f_0} L_{f_0} + \lambda_{sty} L_{sty} \\ &- \lambda_{ds} L_{ds} + \lambda_{asr} L_{asr} + \lambda_{cyc} L_{cyc} \\ L_{D, C} = & - L_{adv} + \lambda_{cl} L_{cl} (y_{src}) \end{aligned}\]StarGANv2-VC와 동일하게 보조 loss들은 다음과 같다.
\[\begin{aligned} L_{sty} &= \mathbb{E} [\| s - S (G (h, f_0, s)) \|_1] \\ L_{ds} &= \mathbb{E}_{s_1, s_2} [\| G (h, f_0, s1) - G (h, f_0, s_2) \|_1] \\ L_{asr} &= \mathbb{E} [\| A(x) - A (G (h(x), f_0, s)) \|_1 ] \\ L_{sty} &= \mathbb{E} [\| s - S (G (h, f_0, s)) \|_1 ] \end{aligned}\]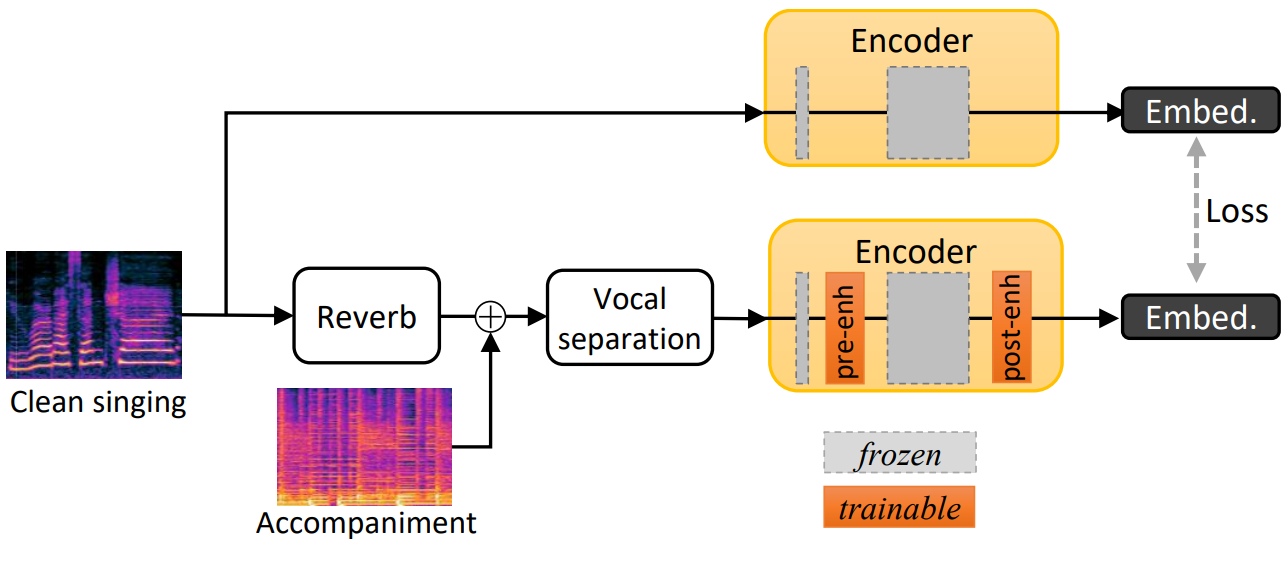
모델이 학습되면 위 그림과 같이 합성 왜곡된 데이터를 사용하여 feature 도메인에서 노래하는 음성을 향상시키기 위해 모델 파라미터를 고정하고 인코더와 style encoder에 두 개의 enhancement block을 추가한다. 원래 고정된 인코더에 의해 깨끗한 샘플에서 추출된 임베딩을 타겟으로 사용하고 타겟과 왜곡된 샘플의 enhancement block으로 인코더에서 얻은 출력 사이의 L1 거리를 최소화하여 새로 추가된 enhancement block을 학습시킨다.
여기서 $E^{enh}$와 $S^{enh}$는 enhancement block이 추가된 인코더와 style encoder이며, $X^{dist}$는 왜곡된 샘플의 mel-spectrogram, $\lambda$는 가중치이다.
Pre-enhancement block은 초기 convolution layer 뒤에 배치되고 post-enhancement block은 인코더 끝에 도입된다. 저자들은 이 아키텍처가 각 enhancement block만을 사용할 때보다 낮은 $L_{ro}$ loss를 제공한다는 것을 발견했다. 각 enhancement block은 인코더와 동일한 아키텍처를 갖는 두 개의 residual block으로 구성된다. 왜곡은 room impulse response (RIR)을 노래하는 목소리에 convolution하고 보컬이 없는 곡을 더하여 시뮬레이션된다. 노래를 추가하면 입력의 특성이 크게 바뀌기 때문에 음악이 혼합된 샘플을 직접 사용하는 것은 매우 어렵다. 따라서 D3Net이라는 사전 학습된 보컬 분리 네트워크를 활용하여 노래에서 보컬을 추출한다. 분리 네트워크의 출력은 완벽하지 않으며 여전히 분리 네트워크에서 도입된 리버브, 간섭, 아티팩트를 포함하므로 분리된 보컬을 직접 사용하면 여전히 SVC 품질이 상당히 저하된다.
제안된 2단계 교육에는 몇 가지 장점이 있다. 첫째, 깨끗한 데이터에 대해 학습된 인코더와 generator를 동결하므로 두 번째 단계에서 왜곡된 데이터에 대한 학습이 enhancement block을 skip하여 깨끗한 데이터에 대한 SVC의 품질을 저하시키지 않을 것임을 보장할 수 있다. 따라서 모델은 테스트 샘플도 깨끗한 것으로 알려진 경우 깨끗한 데이터를 활용할 수 있다. 또한 Robustify 방식은 왜곡된 샘플을 처음부터 처리하도록 전체 모델을 학습시킬 때와 비교했을 때 학습에 필요한 최대 계산 및 메모리 비용을 크게 줄인다. 왜곡된 샘플 합성에 필요한 모듈 (즉, 리버브 및 보컬 분리 모듈)을 첫 번째 단계에서 생략하고 generator, discriminator, classifier, mapping network를 두 번째 단계에서 생략할 수 있기 때문이다. 이를 통해 단일 GPU에서 강력한 모델을 학습시키고 즉시 data augmentation을 적용할 수 있다.
4. Hierarchical PriorGrad vocoder
StarGANv2-VC에서는 Parallel WaveGAN (PWG) vocoder를 mel-spectrogram에서 파형을 복구하는 데 사용된다. 그러나 저자들은 노래하는 음성 데이터에 대해 PWG를 학습시킨 후에도 원본 노래 음성에 비브라토가 포함되어 있을 때 PWG가 피치에서 부자연스러운 흔들림을 생성하는 경향이 있음을 발견했다. 저자들은 여러 vocoder를 탐색한 후 Hierarchical PriorGrad (HPG)라는 diffusion 기반 model이 더 적은 아티팩트를 생성한다는 사실을 발견하여 이를 사용했다.
Experiments
- 데이터셋: NUS48E, NHSS, MUSDB18
- 리버브 효과를 시뮬레이션하기 위해 리버브 플러그인을 사용하여 20개의 RIR를 생성
- 모든 데이터는 24kHz로 resampling됨
- 학습
- StarGANv2-VC를 기반으로 하고 style encoder의 domain-dependent head를 단일 head로 교체하고 피치 컨디셔닝과 enhancement block을 추가
- 150 epochs, batch size 16, learning rate 0.0001, AdamW optimizer
- $\lambda_{cl} = 0.1$, $\lambda_{f_0} = \lambda_{cyc} = 5$, $\lambda_{sty} = \lambda_{ds} = 1$, $\lambda_{asr} = 10$
- Metric
- phonetic feature distance (PFD): 언어적 내용 보존 정도를 평가
- identity: speaker verification model에서 추출한 d-vector의 cosine similarity
- pitch mean absolute error (PMAE): 타겟 F0와 변환된 샘플의 F0 사이의 MAE. 타겟 피치 컨디셔닝이 없는 경우 소스 F0를 스케일링하여 mPMAE로 사용
- mean opinion score (MOS): 34명의 오디오 엔지니어가 오디오 샘플의 자연스러움과 레퍼런스 음성과의 유사성을 1에서 5로 평가
Objective evaluation
다음은 깨끗한 데이터셋에서 one-shot SVC 방법들을 객관적으로 평가한 표이다. ($\ast$는 mPMAE 사용)
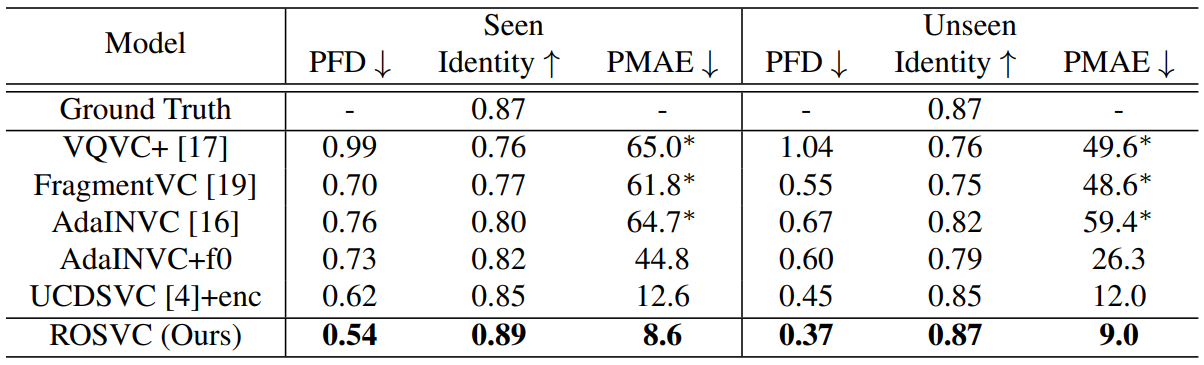
ROSVC는 모든 metric에서 모든 baseline보다 우수한 성능을 보여 변환된 샘플이 음성 및 멜로디 내용을 잘 유지하고 가수의 ID가 타겟 가수에 더 가깝다는 것을 나타낸다.
Ablation Study
다음은 학습 중에 본 가수에 대한 ablation study 결과이다.
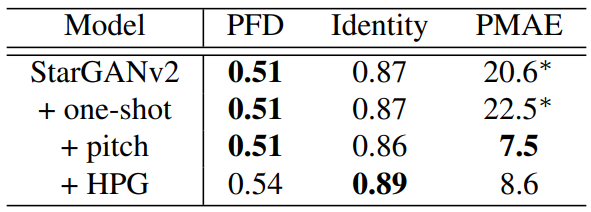
Domain-specific style encoder를 domain-independent style encoder로 교체해도 많은 성능 저하가 관찰되지 않는다. 이는 추가 비용 없이 one-shot 능력이 실현 가능함을 시사한다.
그러나 높은 mPMAE 값에서 알 수 있듯이 그 결과는 피치가 맞지 않는 소리를 낸다. 제안된 피치 컨디셔닝은 피치 재구성 정확도를 크게 향상시킨다. PWG 보코더를 HPG로 교체하면 가수 ID의 유사성이 개선되고 PFD와 PMAE 점수가 약간 저하되는 것을 관찰할 수 있다. 이 저하가 무시할 만하지만 가수 ID에 대한 개선이 중요하므로 저자들은 나머지 실험에는 HPG를 사용하였다.
Subjective test (clean)
다음은 one-shot SVC 방법들을 주관적으로 평가한 표이다.

ROSVC가 baseline을 상당한 차이로 앞서는 것을 볼 수 있다.
Robustness against distortions
다음은 (학습 중에 보지 못한) 왜곡된 데이터셋에 대한 주관적 평가 결과이다.
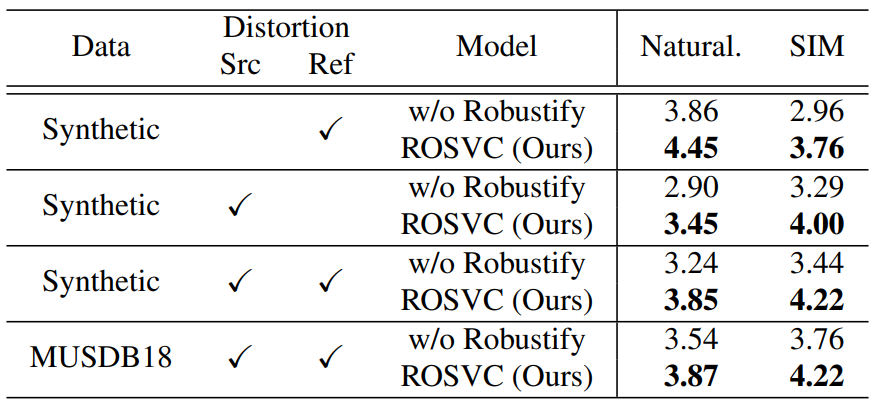
모든 케이스에서 Robustify가 주관적 점수를 상당히 개선하는 것을 볼 수 있다.