[논문리뷰] Video Depth without Video Models
CVPR 2025. [Paper] [Page] [Github]
Bingxin Ke, Dominik Narnhofer, Shengyu Huang, Lei Ke, Torben Peters, Katerina Fragkiadaki, Anton Obukhov, Konrad Schindler
ETH Zurich | Carnegie Mellon University
28 Nov 2024

Introduction
일반적으로 단일 이미지 depth estimator를 동영상에 프레임 단위로 적용하면 만족스러운 결과를 얻기 어렵고, 깜빡임과 드리프트 같은 아티팩트가 발생한다. 이러한 문제는 여러 요인에 의해 발생한다.
가장 분명한 이유는 모델 학습이나 inference 과정에서 인접한 프레임 간의 시간적 일관성에 대한 개념이 전혀 반영되지 않기 때문이다. 또한, 단일 이미지 depth estimator는 장면을 이해하는 능력에 의존하는데, 이는 시간적 컨텍스트의 부족으로 인해 영향을 받을 수 있다. (ex. 부분적으로만 보이는 물체가 줌아웃 후에야 제대로 인식될 수 있는 경우)
게다가 동영상에서는 가까운 장면과 먼 장면 부분 간의 깊이 범위가 갑작스럽게 변할 수 있다. 예를 들어, 전경의 물체가 시야에 들어오거나 시야에 창문이 들어오는 경우 이러한 변화가 발생할 수 있다. 이러한 상황은 일관된 깊이 추정을 더욱 어렵게 만든다.
일부 방법들은 깊이 예측을 위해 Stable Video Diffusion과 같은 생성 모델을 재활용하는 아이디어를 탐구했다. 이러한 방법은 시간 축을 따라 정보 교환을 가능하게 하고 학습 중에 강력한 flow 및 모션 prior를 획득하므로 시간에 따라 우수한 로컬 일관성을 달성한다.
단점은 video LDM이 계산적으로 까다로우며, 고정된 짧은 시퀀스 길이에 대해 학습되며 다양한 길이의 동영상에 직접 적용할 수 없다는 것이다. 실질적으로 유용하게 사용하려면 입력 동영상을 분할하여 처리하고 깊이 추정치를 이어 붙여야 하며, 종종 깜빡임과 드리프트가 발생한다. 또한 현재 LDM 기반 동영상 깊이 모델은 먼 장면 부분에서 정확도가 떨어지는 경향이 있다.
본 논문은 더 정교한 video LDM을 설계하는 대신, 증강된 단일 이미지 LDM을 사용하여 동영상 깊이 추정을 얼마나 잘 수행할 수 있을지 다시 살펴보았다. 저자들은 Marigold와 같은 단일 이미지 깊이 추정 프레임워크를 확장할 수 있는 일련의 방법들을 설계했으며, 이를 통해 동영상 입력을 처리할 수 있도록 했다. 중요한 점은, 이러한 방법들이 시간에 따른 로컬 및 글로벌 일관성을 크게 향상시키면서도, 일관된 메모리 크기를 유지하여 긴 시퀀스를 처리할 수 있게 한다는 것이다.
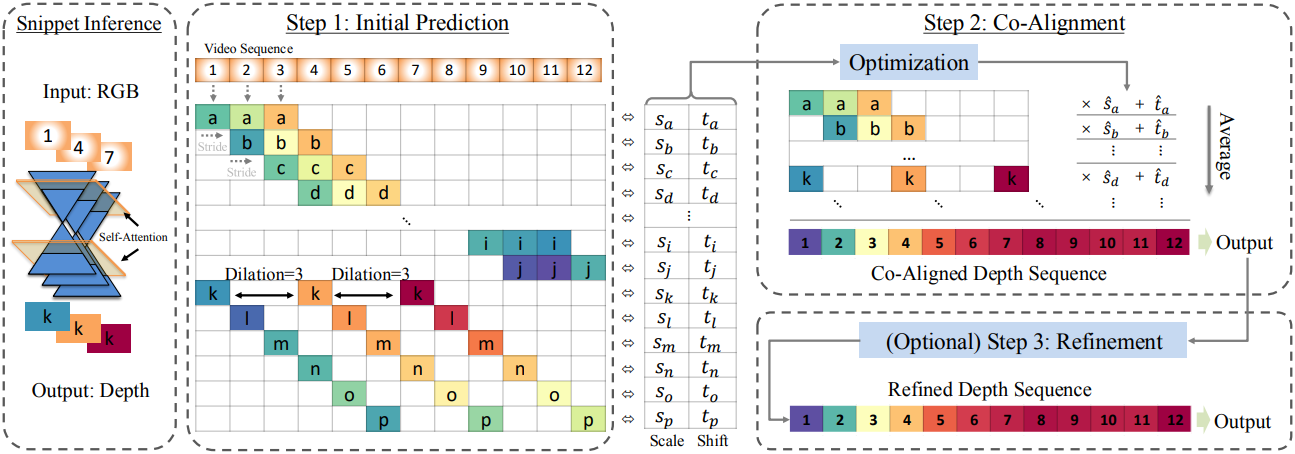
구체적으로, 세 프레임의 sliding window를 이용한 “rolling” inference를 적용한다. 이 snippet은 입력 동영상에서 간격을 두고 샘플링된다. 즉, snippet들이 인접할 수도 있고, 시간 축을 따라 늘려서 긴 범위의 컨텍스트를 다룰 수 있도록 할 수 있다. 그런 다음, 이러한 snippet들은 단일 프레임 모델에서 fine-tuning된 multi-frame LDM에 입력된다. 여기에는 정보를 교환할 수 있도록 수정된 cross-frame self-attention 메커니즘이 사용된다.
Snippet을 다시 조합하는 방법으로는 강력한 최적화 기반의 global co-alignment를 사용하며, 그 후 정렬된 프레임들을 평균화하여 최종 결과를 생성한다. 선택적으로, 결과 동영상은 적당한 임의의 noise로 손상시킨 후, 같은 per-snippet LDM을 사용하여 다시 denoise하여 공간적 디테일을 더욱 세밀하게 다듬을 수 있다.
Method
길이가 $N_F$인 RGB 동영상 $\textbf{x} \in \mathbb{R}^{N_F \times 3 \times H \times W}$가 주어지면, 동영상 깊이 추정기의 목표는 깊이 동영상 $\textbf{d} \in \mathbb{R}^{N_F \times H \times W}$를 예측하는 것이다. 깊이 동영상의 모든 프레임은 공통된 깊이 scale과 shift를 공유해야 한다. 즉, 연관된 픽셀이 카메라에 대해 이동하지 않는 한 깊이 값이 일정해야 한다.
1. Marigold Monocular Depth Recap
기본 모델인 Marigold를 포함한 최근의 여러 방법은 monodepth estimation을 조건부 이미지 생성 문제로 간주하였다. 이러한 방법들은 사전 학습된 LDM을 재활용하여 입력 이미지가 주어졌을 때 depth map을 생성하도록 조정하였다. 이를 위해, 모델은 점진적으로 깊이 샘플 $\textbf{d}^i$에 noise를 추가하고, 그 손상을 되돌리는 과정을 학습하여 조건부 분포 $p(\textbf{d}^i \vert \textbf{x}^i)$를 근사화하는 방법을 학습한다.
모델은 다음과 같은 목적 함수를 최소화함으로써 각 step에서 추가된 noise $\epsilon$을 예측하도록 학습된다.
\[\begin{equation} \mathcal{L} (\theta) = \mathbb{E}_{(\textbf{d}_0^i, \textbf{x}^i) \sim \textrm{P}_{\textbf{d}^i, \textbf{x}^i}, t \sim \mathcal{U}, \epsilon \sim \mathcal{N}} [\| \epsilon - \epsilon_\theta (\textbf{d}_t^i, \textbf{x}^i, t) \|^2] \end{equation}\]Inference 시에 모델은 입력 $\textbf{x}^i$와 Gaussian noise \(\textbf{d}_T^i \sim \mathcal{N}(0,I)\)에서 시작하여 학습된 denoising step을 반복적으로 적용하여 \(\textbf{d}_T^i\)를 depth map \(\textbf{d}_0^i\)에 점진적으로 매핑한다. 계산 효율성을 위해 denoising process는 저차원 latent space $\mathcal{Z}$에서 작동하고 오토인코더를 사용하여 이미지를 latent 임베딩에 매핑하고 depth map을 이미지 공간으로 다시 매핑한다.
2. Extension to Snippets
멀티뷰 diffusion model에서 영감을 얻어, Marigold를 확장하여 self-attention layer를 수정하여 여러 프레임을 처리한다. 각 self-attention block에서 snippet의 모든 프레임에서 토큰을 단일 시퀀스로 flatten하여 attention 메커니즘이 프레임 전체에서 작동하고 공간적 및 시간적 상호 작용을 포착한다. Spatial-temporal attention이 분리된 video diffusion model과 달리, 이 접근 방식은 시간 간격이 다양한 프레임을 처리할 수 있으므로 더 낮은 프레임 속도로 snippet을 샘플링하고 장거리 의존성을 포착할 수 있으며, 긴 동영상을 처리할 때 이점이 된다.
원래 Marigold 모델은 이미지별 근거리와 원거리 평면 사이의 affine-invariant depth를 예측한다. 그러나 동영상에서 시간에 따라 깊이 범위가 변할 수 있기 때문에 동영상 깊이 추정에서 문제를 일으킬 수 있다. 따라서 저자들은 Marigold를 다시 학습시켜 inverse depth를 예측하도록 했다. 이는 다른 monodepth estimator들과 유사한 방식으로, 깊이 범위의 변화, 특히 원거리에서 발생하는 변화에 덜 민감하다.
3. From Snippets to Video
Multi-frame depth estimator는 $n$ 프레임의 짧은 snippet에서 작동하며, 여기서 $n \ll N_F$이다. Snippet은 독립적으로 처리되므로 각각 고유한 scale과 shift가 있다. 이는 Marigold를 포함한 affine-invariant 방법의 경우 임의적이지만 실제로는 metric depth estimator를 사용하더라도 완벽하게 정렬되지 않는다. 이러한 모호성을 해결하기 위해 서로 다른 dilation rate를 가진 겹치는 snippet들을 구성한다. 서로 다른 snippet 간에 공유되는 프레임은 이후 모든 깊이 예측을 공통된 shift와 scale에 맞추는 데 사용된다.
Dilated Rolling Kernel
Dilated rolling kernel을 사용하여 multi-scale snippet들을 구성한다. 예를 들어, dilation rate (프레임 간격) $g$와 stride $h$를 갖는 3프레임 snippet의 경우, kernel은 입력 동영상에서 프레임 \((\textbf{x}^{i−g}, \textbf{x}^i, \textbf{x}^{i+g})\)를 선택한다. Dilation rate를 변경하여 다른 프레임 레이트로 snippet을 샘플링하여 다른 시간 스케일에서 시간적 의존성을 포착한다. 그런 다음 $n$개 프레임의 각 snippet에 대해 multi-frame LDM을 사용하여 깊이를 예측하여 $n$ 프레임의 깊이 snippet을 얻는다.
Depth Co-alignment
이 단계에서 $N_T$개의 depth snippet들을 생성한다. 각각은 고유한 scale 및 shift 파라미터 \(\{(s_k, t_k), k \in 1 \ldots T\}\)를 가지고 있으며, 이는 snippet을 구성하는 프레임 사이에서 공유된다.
여기서 목표는 $N_T$개의 scale 및 shift 값을 공동으로 계산하여 모든 snippet을 일관된 동영상으로 최적으로 정렬하는 것이다. 주어진 프레임 $\textbf{x}^i$에서 $N^i$개의 서로 다른 개별 depth map \(\{\textbf{d}_j^i, j = 1 \ldots N^i\}\)가 있으며, 이는 서로 다른 snippet에서 비롯된다. $N^i$는 프레임마다 다를 수 있다. $k(i, j)$를 프레임 $i$에서 $j$번째 depth map에 대한 snippet 인덱스 $k$를 검색하는 인덱싱 함수라고 하자. 최상의 정렬을 추정하기 위해 모든 개별 깊이 예측에 대한 L1 loss를 최소화한다.
\[\begin{equation} \min_{s_k > 0, t_k} \bigg( \sum_{i=1}^{N_F} \sum_{j=1}^{N^i} \vert s_{k(i,j)} \textbf{d}_j^i + t_{k(i,j)} - \bar{\textbf{d}}^i \vert \bigg) \\ \textrm{where} \; \bar{\textbf{d}}^i = \frac{1}{N^i} \sum_{j=1}^{N^i} (s_{k(i,j)} \textbf{d}_j^i + t_{k(i,j)}) \end{equation}\]이 방정식의 해는 gradient descent로 구할 수 있으며, 높은 dilation rate의 snippet에 더 많은 강조점을 두고 추가 정규화하여 안정화된다. Snippet들의 깊이가 추정된 scale 및 shift 값과 함께 공통 프레임에 정렬되면 모든 프레임 $\textbf{x}^i$의 depth map은 픽셀별 평균 \(\bar{\textbf{d}}^i\)를 취하여 얻어지며, 프레임별로 하나의 depth map이 있는 일관된 깊이 동영상이 생성된다.
Depth Refinement
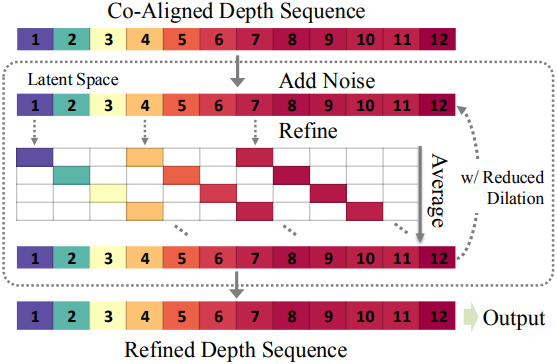
시각적 품질을 향상시키고 더 미세한 디테일을 포착하기 위해, 병합된 깊이 동영상 $\textbf{d}$에 diffusion 기반의 정제 단계를 선택적으로 적용한다.
동영상은 다시 프레임별로 latent space에 인코딩되고, diffusion step $T/2$에 해당하는 적당한 양의 noise로 손상된다. 저하된 동영상은 다시 dilation rolling kernel을 사용하여 snippet으로 분할되고, 각 snippet은 위와 동일한 LDM으로 개별적으로 noise가 제거된다. 겹치는 snippet에 걸쳐 정보를 통합하기 위해 모든 프레임의 latent 임베딩은 모든 denoising step 후에 평균을 취한다.
이 부분적 diffusion은 큰 dilation rate에서 시작하여 denoising process를 따라 점진적으로 감소시키는 방식으로 coarse-to-fine 방식으로 적용할 때 가장 잘 작동한다. 정제 프로세스는 inference 시간이 늘어나는 대가로 글로벌한 장면 깊이 레이아웃을 변경하지 않고 고주파 디테일을 향상시킨다.
4. Multi-Frame Training
Multi-frame self-attention 메커니즘의 유연한 설계를 활용하여 다양한 snippet 길이로 모델을 fine-tuning한다. 학습 snippet은 무작위로 선택되어 1 ~ 3개의 프레임을 가진다.
Inverse depth 값은 robustness를 위해 2번째 및 98번째 백분위수를 사용하여 snippet로 정규화된다. 각 프레임을 개별적으로 정규화하는 대신 각 snippet 내의 값을 공동으로 정규화하는 것이 중요하다. 이런 방식으로 동일한 프레임은 나타나는 컨텍스트에 따라 다르게 정규화되고, 정규화된 깊이는 snippet 내에서 비슷한 상태를 유지하여 모델이 긴 동영상 시퀀스에서 나타나는 깊이 범위의 빠른 변화를 이해하고 올바르게 처리할 수 있게 한다.
Experiments
- 데이터셋: TartanAir, Hypersim
- 학습 디테일
- optimizer: AdamW
- learning rate: $3 \times 10^{-5}$
- batch size: 32
- iteration: 1.8만
- GPU: NVIDIA A100 4개로 2일 소요
- Inference
- dilation rate: \(g \in \{1, 10, 25\}\)
- $s_k = 1$, $t_k = 0$으로 초기화 후 2,000 step 최적화
- optimizer: Adam
- 선택적 정제 단계
- timestep $T/2$에서 시작하여 10 denoising step
- dilation rate은 6에서 1로 점진적으로 감소
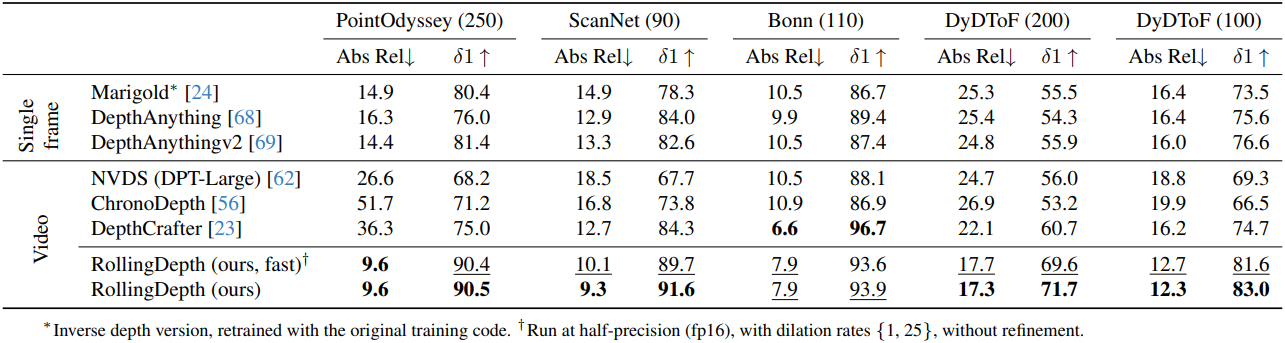
1. Comparison with Other Methods
다음은 다른 방법들과 비교한 결과이다.
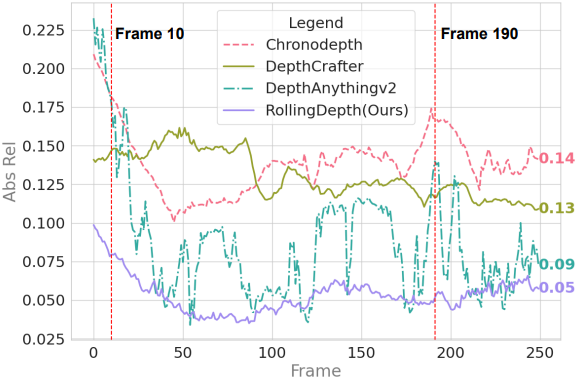
다음은 (위) 시간에 따른 AbsRel과 (아래) 두 프레임에서의 error map을 비교한 것이다.

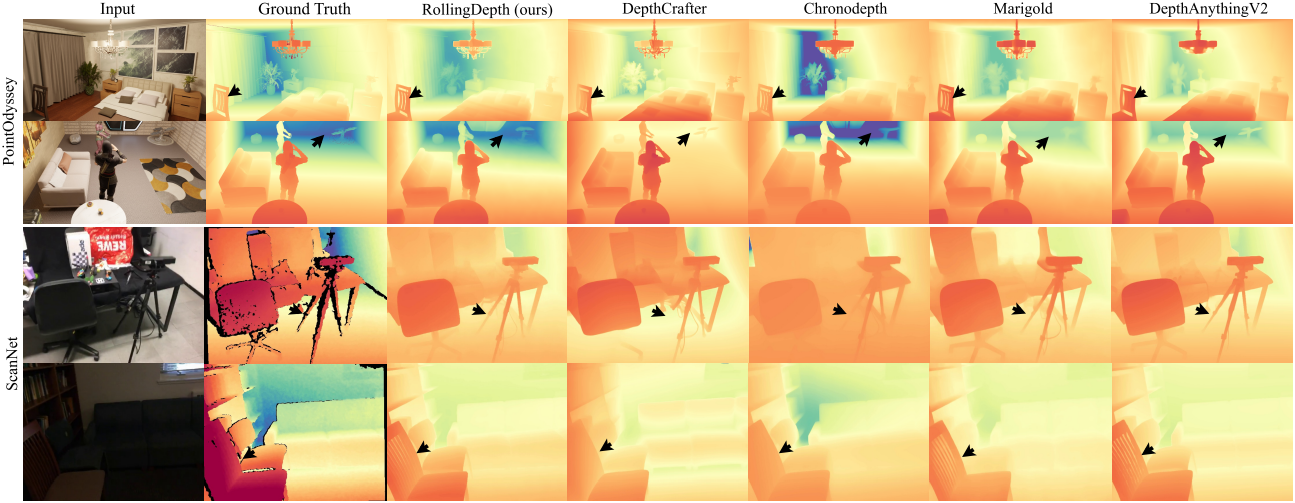
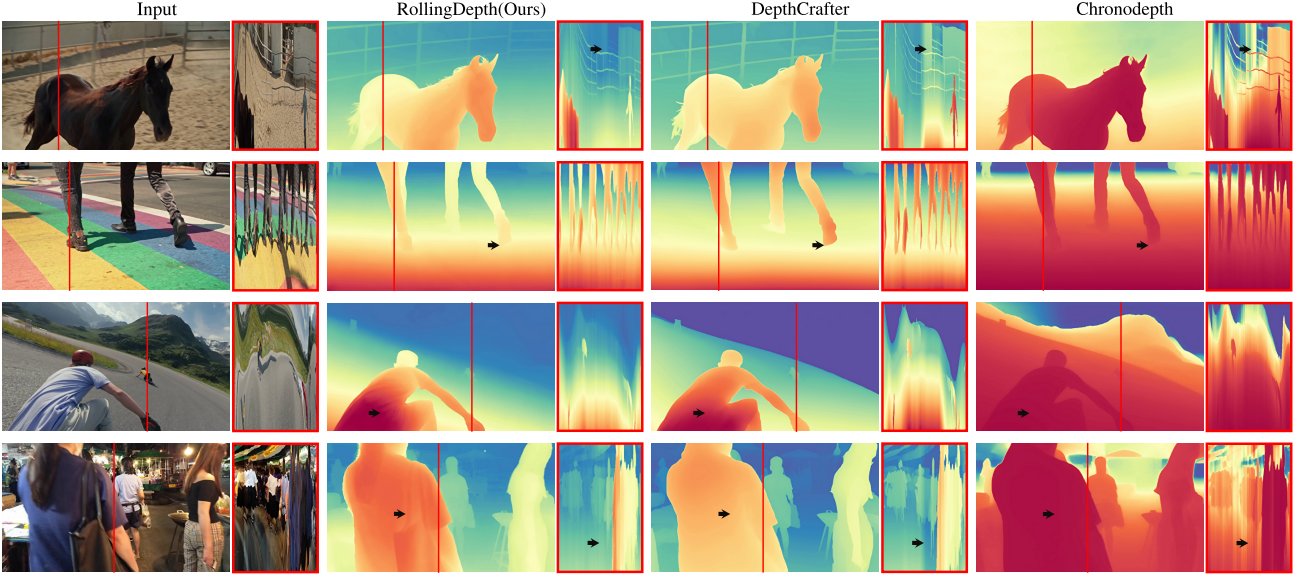
다음은 in-the-wild 동영상에 대한 깊이 예측 결과를 비교한 것이다.
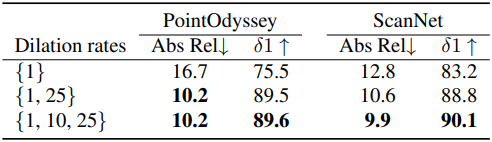
2. Ablation Studies
다음은 dilation rate에 대한 ablation 결과이다.
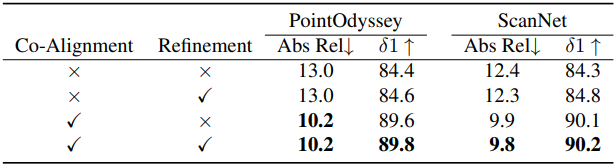
다음은 구성 요소에 대한 ablation 결과이다.