[논문리뷰] RogSplat: Robust Gaussian Splatting via Generative Priors
ICCV 2025. [Paper]
Hanyang Kong, Xingyi Yang, Xinchao Wang
National University of Singapore
Introduction
3DGS는 입력 이미지들이 기하학적으로 일관성이 있다는 엄격한 가정 하에 작동한다. 즉, 이미지들은 통제된 조건에서 촬영되어야 하며, 가려짐, 움직이는 물체, 카메라 블러, 조명 변화가 없어야 한다. 이러한 제약 조건은 실제 환경에서의 적용 가능성을 크게 제한한다.
현재 SOTA 방법들은 이러한 불일치를 처리하는 데 어려움을 겪고 있다. 대부분의 접근 방식은 불일치를 제거하는 데 의존한다. 일시적으로 나타나는 물체를 필터링하거나, 재구성을 가이드하기 위해 불확실성을 계산하거나, 장면의 불변 요소와 가변 요소를 분리하는 방식이다. 그러나 예측할 수 없는 변화가 발생하는 실제 시나리오에서는 이러한 효과를 식별하고 배제하는 것이 어렵다. 결과적으로 이러한 방법들은 아티팩트를 해결하지 못한다.
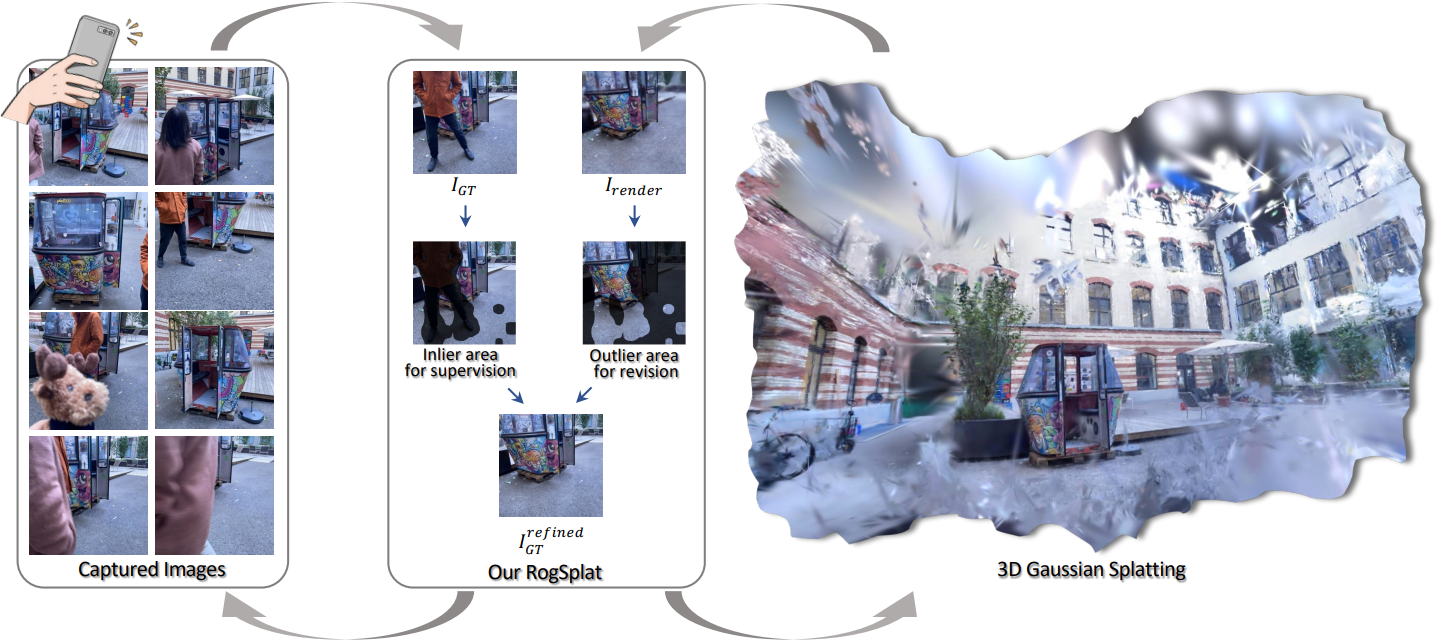
이러한 격차를 해소하기 위해, 본 논문에서는 불일치를 단순히 무시하는 대신 생성 모델을 통해 적극적으로 수정하는 새로운 프레임워크인 RogSplat을 소개한다. 제거 기반 방식과 달리, RogSplat은 이미지 컬렉션에서 불일치 영역을 반복적으로 식별하고 재생성함으로써 3DGS의 robustness를 향상시킨다. 3D 장면 최적화 과정에서 outlier를 적응적으로 식별하고 가려진 영역을 수정함으로써, 3D 재구성의 정확도와 robustness를 향상시켰다.
특히, text-to-image diffusion model과 DINO v2의 feature를 융합하여 두 feature 유형의 상호 보완적인 강점을 결합하였다. 학습 이미지와 렌더링된 이미지의 융합된 feature 간의 코사인 similarity map을 계산하여 가려진 영역을 식별한다. similarity 점수는 보이는 영역에서는 높게 나타나고, 가려진 영역에서는 낮게 나타난다.
저자들은 보이는 내용을 보존하면서 가려진 영역을 복원하기 위해, similarity 기반 denoising 스케줄에 따라 작동하는 rectified flow 기반 방법인 RF-Refiner를 도입하였다. 구체적으로, RF-Refiner는 cosine similarity map을 기반으로 생성 편집 강도를 조절한다. similarity가 높은 영역은 변경되지 않고, similarity가 낮은 영역은 더 강하게 정제를 받는다. RF-Refiner와 융합된 cosine similarity map은 동시에 협력하여 3DGS 모델의 파라미터를 최적화한다.
Method
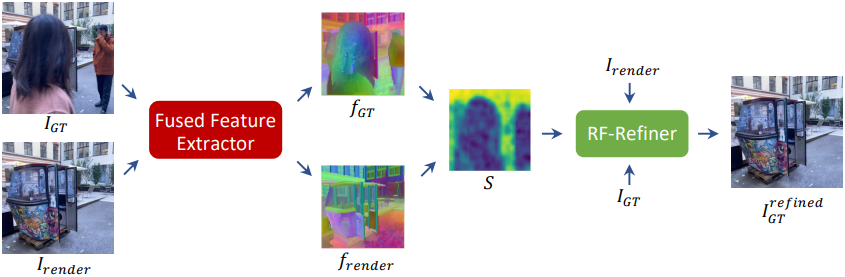
RogSplat은 아티팩트를 반복적으로 감지하고 수정하여 3DGS를 개선한다. 원본 이미지로 구축된 coarse한 3DGS 모델에서 시작하여, diffusion feature를 사용하여 렌더링된 뷰와 실제 이미지를 비교하고 distractor 영역을 식별한다. 이러한 영역은 similarity map으로 표현되며, FLUX 모델은 이 map을 사용하여 실제 이미지와 렌더링된 뷰의 정보를 통합하여 해당 영역을 inpainting한다. 이 반복적인 과정은 수렴될 때까지 계속된다.
1. Distractor Detection with Semantic Similarity
제약 없는 이미지 캡처는 3D 재구성 품질을 저하시키는 distractor (ex. occlusion, 움직이는 물체, 카메라 블러, 조명 변화)를 유발한다. 원본 이미지를 사용한 직접 재구성은 멀티뷰 correspondence의 불일치로 인해 아티팩트를 생성한다. 본 논문의 목표는 후속 개선을 위해 distractor 영역을 식별하는 것이다.
Similarity는 distractor 선택에 도움이 된다.
본 논문의 직관은 간단하다. Distractor는 멀티뷰 일관성을 저해하여 흐릿한 재구성 결과를 초래한다. 따라서 렌더링된 이미지 \(I_\textrm{render}\)와 실제 이미지 \(I_\textrm{GT}\) 간의 유사성이 낮은 영역에는 distractor가 포함되어 있을 가능성이 높다.
이를 위해 DINOv2 feature와 DIFT feature를 결합한 feature에 대해 similarity를 계산한다. 이는 두 feature가 서로 다른 특성을 가지고 있기 때문이다.

위 그림에서는 DINOv2 feature와 DIFT feature를 사용하여 렌더링된 이미지와 실제 이미지 간의 cosine similarity map을 보여준다. DINOv2 feature는 유사한 내용을 가진 영역에 더 민감하게 반응하지만, 유사하지 않은 영역에는 민감하지 않다. DIFT feature는 distractor에 robust하며, 흐릿한 영역은 outlier로 간주된다.
Feature Similarity
먼저, 학습 이미지 \(I_\textrm{GT}\)와 동일한 카메라 시점에서의 렌더링 이미지 \(I_\textrm{render}\)에 대해 각각 DINOv2와 DIFT로 픽셀 정렬된 feature map을 추출한다.
\[\begin{aligned} f_\textrm{render}^\textrm{dino} = \phi_\textrm{dino} (I_\textrm{render}), \quad f_\textrm{render}^\textrm{dift} = \phi_\textrm{dift} (I_\textrm{render}) \\ f_\textrm{GT}^\textrm{dino} = \phi_\textrm{dino} (I_\textrm{GT}), \quad f_\textrm{GT}^\textrm{dift} = \phi_\textrm{dift} (I_\textrm{GT}) \end{aligned}\]그런 다음, 두 feature를 각각 독립적으로 정규화하여 scale과 분포를 일치시킨 후, 두 feature를 concat하여 distractor를 감지하기 위한 최종 feature를 생성한다. 학습 및 렌더링 이미지에 대한 최종 feature는 다음과 같다.
\[\begin{equation} f_\textrm{render} = \frac{f_\textrm{render}^\textrm{dino}}{\| f_\textrm{render}^\textrm{dino} \|_2^2} \oplus \frac{f_\textrm{render}^\textrm{dift}}{\| f_\textrm{render}^\textrm{dift} \|_2^2}, \quad f_\textrm{GT} = \frac{f_\textrm{GT}^\textrm{dino}}{\| f_\textrm{GT}^\textrm{dino} \|_2^2} \oplus \frac{f_\textrm{GT}^\textrm{dift}}{\| f_\textrm{GT}^\textrm{dift} \|_2^2} \end{equation}\]그런 다음 렌더링된 feature와 GT feature 간의 pixel-wise cosine similarity map $S$를 다음과 같이 계산한다.
\[\begin{equation} S = \frac{f_\textrm{render} \cdot f_\textrm{GT}}{\| f_\textrm{render} \|_2^2 \cdot \| f_\textrm{GT} \|_2^2} \end{equation}\]이 프레임워크는 distractor가 semantic 일관성(DINOv2)과 geometry 일관성(DIFT)을 모두 위반할 때만 flag를 지정하여 모션 블러나 텍스처가 없는 표면과 같은 모호한 영역으로 인한 false positive를 줄인다.
2. Rectified Flow Model for Artifacts Refinement
기존의 robust한 3D 재구성 방법들은 주로 학습 이미지에서 distractor를 제거하는 데 초점을 맞추고 있다. 이러한 접근 방식은 단순한 경우에는 효과적이지만, distractor가 많은 경우에는 입력 이미지의 상당 부분을 제거함으로써 supervision이 불완전해지고 재구성 품질이 저하되어 한계를 드러낸다. 본 논문에서는 generative prior를 활용하여 distractor에 그럴듯한 콘텐츠를 생성하는 새로운 접근 방식을 제시하였다. 이를 통해 완전한 supervision을 유지하고 더욱 robust한 3D 최적화를 가능하게 한다.
직접적인 inpainting 방식은 한계가 있다.
가려진 영역에 단순히 inpainting 모델을 적용하는 것만으로는 robust한 3D 재구성을 수행하기에 불충분하다. 저자들은 렌더링된 이미지에서 가려진 영역을 마스킹하고 그럴듯한 콘텐츠를 생성하는 Stable Diffusion (SD) inpainting 모델을 사용하여 실험했다.

그러나 위 그림에서 볼 수 있듯이, SDXL-Inpainting은 비현실적인 아티팩트와 신뢰할 수 없는 콘텐츠를 생성하여 3D 최적화 품질을 저하시키는 불일치를 초래힌다.
결정적으로, 가려진 영역을 직접 복원하면 해당 영역의 내용이 변경되어 기본 장면과의 일관성이 깨진다. 결과적으로, 복원된 이미지를 사용하여 3DGS를 최적화하면 불일치가 발생하여 재구성 품질이 저하된다.
Similarity-Guided Rectified Flow Refinement
저자들은 distractor를 효과적으로 정제하기 위해 similarity 기반 RF 정제 프레임워크를 제안하였다. 핵심 아이디어는 이전에 계산된 similarity map $S$를 기반으로 생성 편집 강도를 조절하는 것이다. Similarity가 높은 영역은 변경되지 않고, similarity가 낮은 영역은 더 강력한 정제를 거친다. 이는 영역 적응형 denoising을 갖춘 SDEdit를 FLUX 모델에 적용함으로써 달성되며, 일관성을 유지하면서 가려진 영역을 선택적으로 강화한다.
구체적으로, timestep $t_i$에서 원본 이미지의 latent $z_0$에 noise를 추가하는 것으로 시작한다.
\[\begin{equation} z_{t_i} = (1 - t_i) z_0 + t_i z_1, \quad z_1 \sim \mathcal{N}(0,I) \end{equation}\]균일한 noise를 적용하는 대신, similarity map $S$에 기반하여 denoising 강도를 적응적으로 조절한다. 이를 통해 similarity가 낮은 영역에서는 더욱 정밀한 denoising을 수행하면서 similarity가 높은 영역은 보존할 수 있다. 이를 위해 similarity map을 전처리하여 영역별 denoising 강도를 계산한다.
\[\begin{equation} S_\textrm{RF} = \textrm{clamp} (1 - S, s_\textrm{min}, s_\textrm{max}) \end{equation}\](\(s_\textrm{min}\)과 \(s_\textrm{max}\)는 hyperparameter)
Denoising process에서 FLUX의 원래 timestep 스케줄 \(\textbf{t} = \{t_i\}\)에서 부분집합 \(\textbf{t}^\prime = \{t_i \in \textbf{t} \vert 0 \le t_i \le s_\textrm{max}\}\)를 추출한다. 전처리된 similarity 값을 특정 timestep에 매핑한다.
\[\begin{equation} t_i = s_\textrm{min} + (s_\textrm{max} - s_\textrm{min}) \cdot \frac{S_\textrm{RF}}{\max (S_\textrm{RF})} \end{equation}\]이 매핑을 통해 similarity가 낮은 영역에는 더 큰 timestep 값이 할당되어 필요한 부분에서 더 강력한 denoising이 가능해진다.
Regional Adaptive Denoising
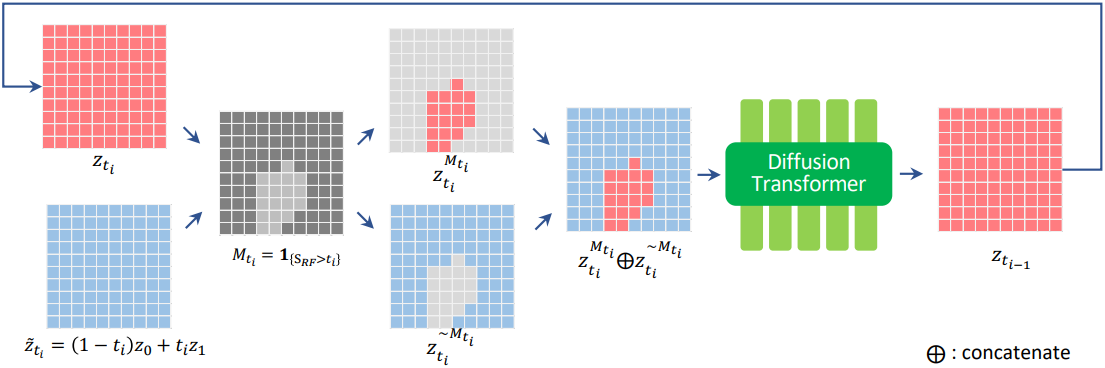
FLUX 모델은 \(t_i = s_\textrm{max}\)에서 시작하여 latent \(z_{t_i}\)를 반복적으로 denoising하여 $t_i = 0$까지 낮춘다. 이 과정에서 noise level이 다른 영역들을 동시에 처리하여 적응형 개선을 가능하게 한다.
FLUX 모델은 각 iteration에서 전체 latent space의 입력을 받지만, 현재 timestep $t_i$에 해당하는 영역만 선택적으로 업데이트한다. Noise level이 낮은 영역(더 작은 timestep)은 해당 timestep에 도달할 때까지 변경되지 않는다. 이를 통해 similarity가 낮아 더 강한 정제가 필요한 영역은 더 많은 업데이트를 거치고, similarity가 높은 영역은 원래 구조를 유지하면서 약간만 조정된다.
3. Optimization

전체적인 최적화 과정은 Algorithm 1에 소개되어 있다. 먼저 현재 3DGS 모델로 이미지를 렌더링한다. 그런 다음, 렌더링된 이미지와 GT 이미지 모두에서 DINOv2 feature와 DIFT feature를 추출한다. Cosine similarity map을 계산하여 가려진 영역을 식별하고, RF-Refiner를 사용하여 해당 영역을 개선한다. 개선된 이미지는 3DGS 파라미터 업데이트를 위한 supervision으로 사용된다. 최적화 loss function은 기존 3DGS와 동일하다.
Experiments
- 데이터셋: NeRF On-the-go, RobustNeRF
1. Comparison
다음은 장면 재구성 결과를 비교한 것이다.



2. Ablation Studies
다음은 ablation study 결과이다.

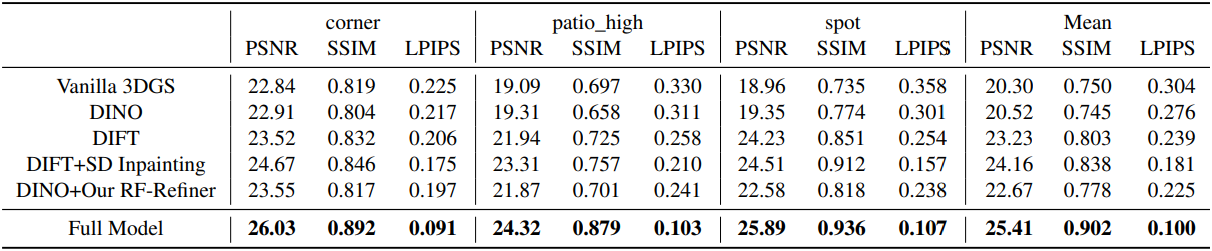
다음은 RF-Refiner 모듈에 대한 ablation 결과이다.
