[논문리뷰] RobustSAM: Segment Anything Robustly on Degraded Images
CVPR 2024 (Highlight). [Paper] [Page] [Github]
Wei-Ting Chen, Yu-Jiet Vong, Sy-Yen Kuo, Sizhuo Ma, Jian Wang
National Taiwan University | Snap Inc.
13 Jun 2024
Introduction
Segment Anything Model (SAM)은 인상적인 zero-shot segmentation 능력을 보여주었지만, 복잡하고 어려운 시나리오에서, 특히 화질이 저하된 이미지에 대한 robustness는 여전히 해결해야 할 문제이다. 저조도, 노이즈, 블러, 약천후, 압축 손실 등, 여러 degradation에 SAM이 생성하는 segmentation mask의 품질이 크게 영향을 받는다.
이러한 문제를 해결하기 위해 직관적인 접근 방식 중 하나는 기존 image restoration 기술을 활용하여 이미지를 SAM에 공급하기 전에 전처리하는 것이다. 이러한 방법은 이미지 품질을 어느 정도 개선할 수 있지만 image restoration 기술이 image segmentation을 개선할 수 있다는 보장은 없다. 이는 대부분의 image restoration 알고리즘이 SAM과 같은 segmentation 모델의 특정 요구 사항이 아닌 인간의 시각적 인식에 최적화되어 있기 때문이다.
다른 전략은 저하된 이미지에서 SAM을 직접 fine-tuning하는 것이다. 그러나 SAM 디코더를 직접 fine-tuning하거나 새로운 디코더 모듈을 통합하면 zero-shot task에서 모델의 일반화 능력이 크게 손상될 수 있다. 또한, 저하된 이미지로 SAM을 맹목적으로 fine-tuning하면 네트워크가 원래의 깨끗한 이미지에서 학습한 지식을 잃어버리는 catastrophic forgetting으로 이어질 수 있다.
본 논문은 zero-shot 능력을 유지하면서 저하된 이미지를 처리하는 데 있어 robust한 RobustSAM을 소개한다. RobustSAM은 두 가지 새로운 모듈, Anti-Degradation Token Generation 모듈과 Anti-Degradation Mask Feature Generation 모듈을 사용한다. 두 모듈들은 저하된 이미지에서 추출한 feature와 깨끗한 이미지애서 추출한 feature에 대한 consistency loss들로 학습되며, degradation 무관한 segmentation feature들을 추출하도록 설계되었다. 또한 SAM의 원래 출력 토큰을 fine-tuning하여 robust한 segmentation에 맞게 조정한다. 학습 중에 SAM의 원래 모듈을 고정함으로써 zero-shot segmentation에 대한 효과를 유지하면서 저하된 이미지를 처리하는 능력을 향상시켰다.
또한 추가 모듈들은 효율적으로 학습할 수 있다. 수백 개의 GPU에서 학습해야 하는 원래 SAM과 달리 RobustSAM은 8개의 A100에서 30시간 이내에 학습할 수 있다. RobustSAM은 깨끗한 이미지와 저하된 이미지 모두에서 우수한 성능을 발휘한다. 나아가 RobustSAM은 SAM 기반 다운스트림 task에 더 강력한 prior를 제공하여 효율성을 향상시킨다.
저자들은 RobustSAM의 능력과 robustness를 강화하기 위해 Robust-Seg 데이터셋을 도입하였다. Robust-Seg는 기존 데이터셋 7개에서 세심하게 주석이 달린 43,000개의 이미지를 결합하였다. 각 이미지는 15가지 유형의 신중하게 모델링된 합성 degradation과 결합하여 종합적으로 688,000개의 이미지가 수집되었다. 이 광범위한 데이터셋은 이미지 segmentation의 경계를 넓히는 것을 목표로 한다.
Method
1. Model Overview
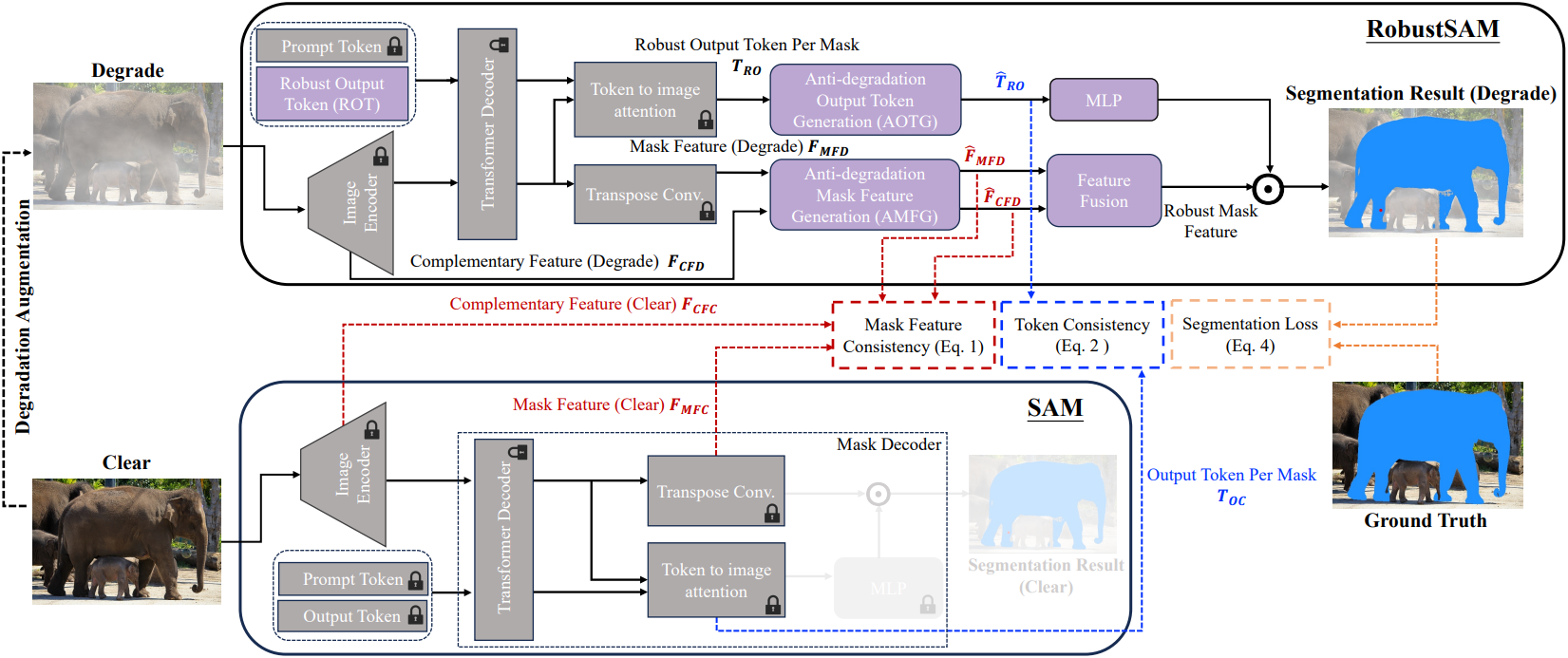
RobustSAM의 주요 기여는 Anti-Degradation Output Token Generation (AOTG) 모듈과 Anti-Degradation Mask Feature Generation (AMFG) 모듈이다. 두 모듈은 원래 SAM에서 깨끗한 이미지로부터 추출한 정보와 정렬된 degradation과 무관한 정보를 추출한다. 이는 15가지 유형의 합성 degradation augmentation을 통해 깨끗한 이미지와 저하된 이미지의 쌍을 생성하여 달성된다. 그런 다음 깨끗한 feature와 저하된 feature 사이의 일관성 loss와 예측된 segmentation과 GT 사이의 일관성 loss를 적용한다.
학습
먼저 깨끗한 입력 이미지에 degradation augmentation을 적용한 다음 저하된 결과 이미지를 RobustSAM에 공급한다. 처음에 모델은 이미지 인코더를 활용하여 이 저하된 이미지에서 feature를 추출한다. 원래 SAM 프레임워크와 달리 출력 토큰을 fine-tuning했으며, 이 토큰을 Robust Output Token (ROT)이라고 한다. ROT는 프롬프트 토큰과 이미지 인코더에서 추출한 feature와 함께 원래 SAM 레이어를 통해 처리되어 mask feature \(F_\textrm{MFD}\)와 마스크별 ROT \(T_\textrm{RO}\)를 생성한다. 또한, 이미지 인코더의 초기 및 최종 레이어 complementary feature \(F_\textrm{CFD}\)를 추출한다.
AOTG 블록은 \(T_\textrm{RO}\)를 처리하여 degradation에 강한 정보를 추출하고 \(\hat{T}_\textrm{RO}\)로 변환한다. 동시에 AMFG 블록은 \(F_\textrm{MFD}\)와 \(F_\textrm{CFD}\)를 정제하여 degradation 관련 정보를 제거하여 정제된 feature \(\hat{F}_\textrm{MFD}\)와 \(\hat{F}_\textrm{CFD}\)을 생성한다. HQ-SAM에서 제안된 아키텍처에 따라 Feature Fusion block은 정제된 feature들을 robust mask feature로 결합한다.
동시에, 원래의 깨끗한 이미지는 표준 SAM에 의해 처리되어 complementary feature \(F_\textrm{CFC}\), mask feature \(F_\textrm{MFC}\), 출력 토큰을 추출한다. 이러한 깨끗한 feature와 RobustSAM의 정제된 feature 간의 일관성 loss들은 저하되지 않은 이미지 출력과의 정렬을 보장한다. Segmentation 결과는 segmentation loss function을 사용하여 GT와 비교된다.
Degradation augmentation은 15가지 유형의 degradation과 identity 매핑을 포함한다. 이를 통해 깨끗한 이미지가 품질을 유지하여 저하되지 않은 시나리오에서 성능 저하를 방지한다.
Inference
Inference 시에는 RobustSAM만 segmentation mask를 생성하는 데 사용된다.
2. Anti-Degradation Mask Feature Generation
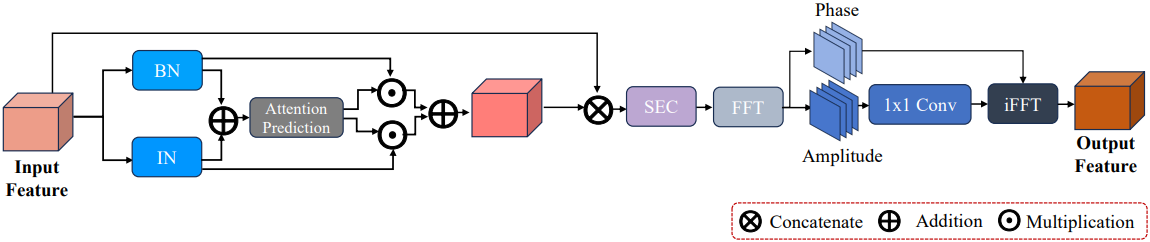
입력 feature는 먼저 Instance Normalization (IN)에 의해 처리된다. IN의 목적은 이미지 degradation과 관련된 정보를 표준화하는 것이며, 핵심 콘텐츠를 보존하면서 스타일 속성을 제거한다. 이 단계는 개별 이미지 왜곡의 영향을 완화하고 다양한 degradation 조건에서 콘텐츠의 안정성을 보장하는 데 필수적이다. 이와 병행하여 URIE에서 영감을 받아 Batch Normalization (BN)을 적용하는 또 다른 branch를 포함한다. BN은 IN 프로세스로 인해 발생하는 잠재적인 디테일 손실을 해결하기 때문에 중요하다.
그런 다음 BN과 IN에서 개별적으로 생성된 feature를 병합한다. Attention 메커니즘은 병합된 feature를 면밀히 조사하여 attention map을 생성하고, 이는 각 feature 유형의 중요성에 동적으로 가중치를 주어 IN과 BN의 장점을 모두 포함하는 feature 세트를 합성한다. 손실되었을 수 있는 semantic 정보를 보상하기 위해 이 향상된 feature 세트는 채널 차원을 따라 원래 입력 feature와 concat된다. 또한, squeeze-and-excitation와 비슷한 channel attention (SEC)을 통합하여 feature 통합을 적응적으로 개선한다.
저자들은 통합된 feature를 향상시키기 위해 푸리에 변환을 사용하여 공간 도메인에서 주파수 도메인으로 변환하는 Fourier Degradation Suppression 모듈을 도입했다. 이 기술은 진폭 성분을 활용하여 degradation에 대한 스타일 정보를 캡처한다. 1$\times$1 convolution을 적용하여 degradation 성분을 분리하고 제거하는 데 중점을 둔다. 한편, 위상 성분은 구조적 무결성을 유지하기 위해 보존된다. 이후 역 푸리에 변환은 정제된 feature를 공간 도메인으로 다시 가져온다. 이 프로세스는 degradation을 이미지 스타일로 처리하고 degradation에 무관한 feature를 생성한다.
이 모듈은 \(F_\textrm{CFD}\)와 \(F_\textrm{MFD}\)에 적용된다. 이러한 정제된 feature가 \(F_\textrm{CFC}\), \(F_\textrm{MFC}\)와 일관성을 유지하도록 하기 위해 Mask Feature Consistency Loss \(\mathcal{L}_\textrm{MFC}\)를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{MFC} = \| \hat{F}_\textrm{CFD} - F_\textrm{CFC} \|_2 + \| \hat{F}_\textrm{MFD} - F_\textrm{MFC} \|_2 \end{equation}\]\(\mathcal{L}_\textrm{MFC}\)의 각 부분을 최소화함으로써 정제된 feature가 깨끗한 이미지에서 추출된 feature와 일관성을 유지하도록 보장하고, 이를 통해 다양한 degradation에서도 feature의 robustness와 일관성을 보장한다.
3. Anti-Degradation Output Token Generation

AOTG 모듈은 마스크별 ROT \(T_\textrm{RO}\)을 정제하여 degradation 관련 정보를 제거하는 데 전념한다. 기존 mask feature와 달리 \(T_\textrm{RO}\)는 주로 분류 경계의 명확성을 보장하는 기능을 하므로 텍스처 정보가 덜 포함된다. 따라서 degradation에 민감한 정보를 필터링하는 데 가벼운 모듈을 사용하면 충분하며, IN과 MLP를 사용한다. 이 전략은 모델이 degradation의 영향을 받는 입력에서 robust한 마스크 정보를 복구할 수 있도록 하는 동시에 계산 효율성을 유지하는 것을 목표로 한다. 정제된 토큰 \(\hat{T}_\textrm{RO}\)는 원래 SAM이 깨끗한 이미지에서 추출한 출력 토큰 \(T_\textrm{OC}\)와 비교하여 Token Consistency Loss \(\mathcal{L}_\textrm{TC}\)를 계산한다.
이 loss는 정제된 토큰이 깨끗한 이미지에서 추출된 토큰과 일관성을 유지하도록 보장한다. \(\hat{T}_\textrm{RO}\)는 MLP를 통해 처리된 후, robust mask feature와 결합되어 최종 마스크를 생성한다.
4. Overall Loss
전체 loss function은 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{MFC} + \lambda_1 \mathcal{L}_\textrm{TC} + \lambda_2 \mathcal{L}_\textrm{Seg} \\ \end{equation}\]\(\mathcal{L}_\textrm{Seg}\)는 dice loss와 focal loss로 구성된다.
\[\begin{equation} \mathcal{L}_\textrm{Seg} = \mathcal{L}_\textrm{Dice} (P, G) + \lambda_3 \mathcal{L}_\textrm{Focal} (P, G) \end{equation}\]($P$는 예측된 마스크, $G$는 GT 마스크)
5. Robust-Seg
저자들은 RobustSAM을 학습시키고 평가하기 위해 688,000개의 이미지-마스크 쌍으로 구성된 Robust-Seg 데이터셋을 구성했다. 이 데이터셋은 여러 기존 데이터셋, 즉 LVIS, ThinObject5k, MSRA10K, NDD20, STREETS, FSS-1000, COCO의 이미지로 구성된다. 이 데이터셋에는 원래의 깨끗한 이미지와 블러, 노이즈, 저조도, 악천후 등 15가지 유형의 합성 degradation이 적용된 저하된 이미지가 통합되어 있다. 이를 통해 모델이 광범위하게 학습되고 다양한 이미지 품질에 robust하도록 보장한다.
- train: MSRA10K, ThinObject-5k, LVIS의 train set
- validation: MSRA10k와 LVIS의 test set
- test: NDD20, STREETS, FSS-1000, COCO의 전체 이미지
추가로, 다양한 실제 degradation을 포함하는 BDD-100k와 LIS 데이터셋을 사용하여 광범위한 테스트를 수행한다.
Experiments
- 학습 디테일
- 사전 학습된 원래 SAM의 파라미터는 고정하고 제안된 모듈들만 최적화
- 포인트 기반 프롬프트로 학습
- learning rate: 0.0005
- epoch: 40
- Nvidia A100 8개에서 30시간 소요
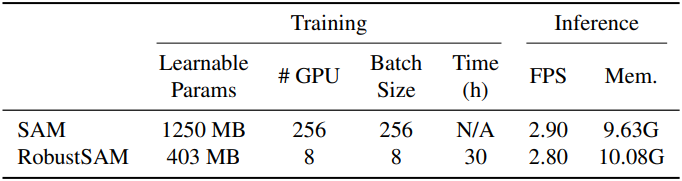
1. Performance Evaluation
다음은 (왼쪽) MSRA10k와 (오른쪽) LVIS의 test set에 대한 segmentation 성능을 비교한 표이다.
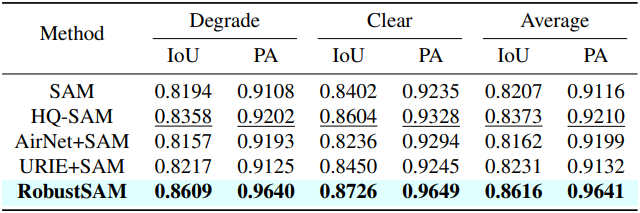
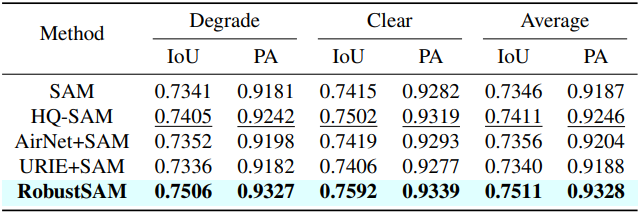
다음은 NDD20, STREETS, FSS-1000에 대한 zero-shot segmentation 성능을 비교한 표이다. (포인트 프롬프트)
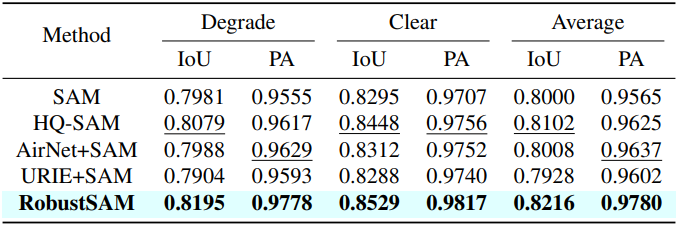
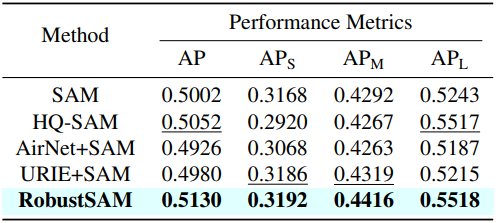
다음은 COCO에 대한 zero-shot segmentation 성능을 비교한 표이다. (Bounding box 프롬프트)
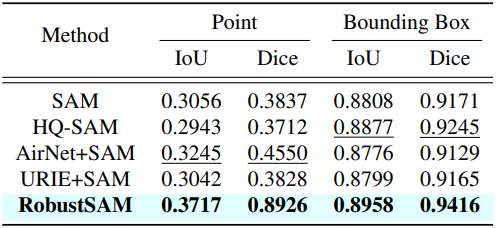
다음은 BDD-100k와 LIS에 대한 zero-shot segmentation 성능을 비교한 표이다. (포인트 프롬프트)
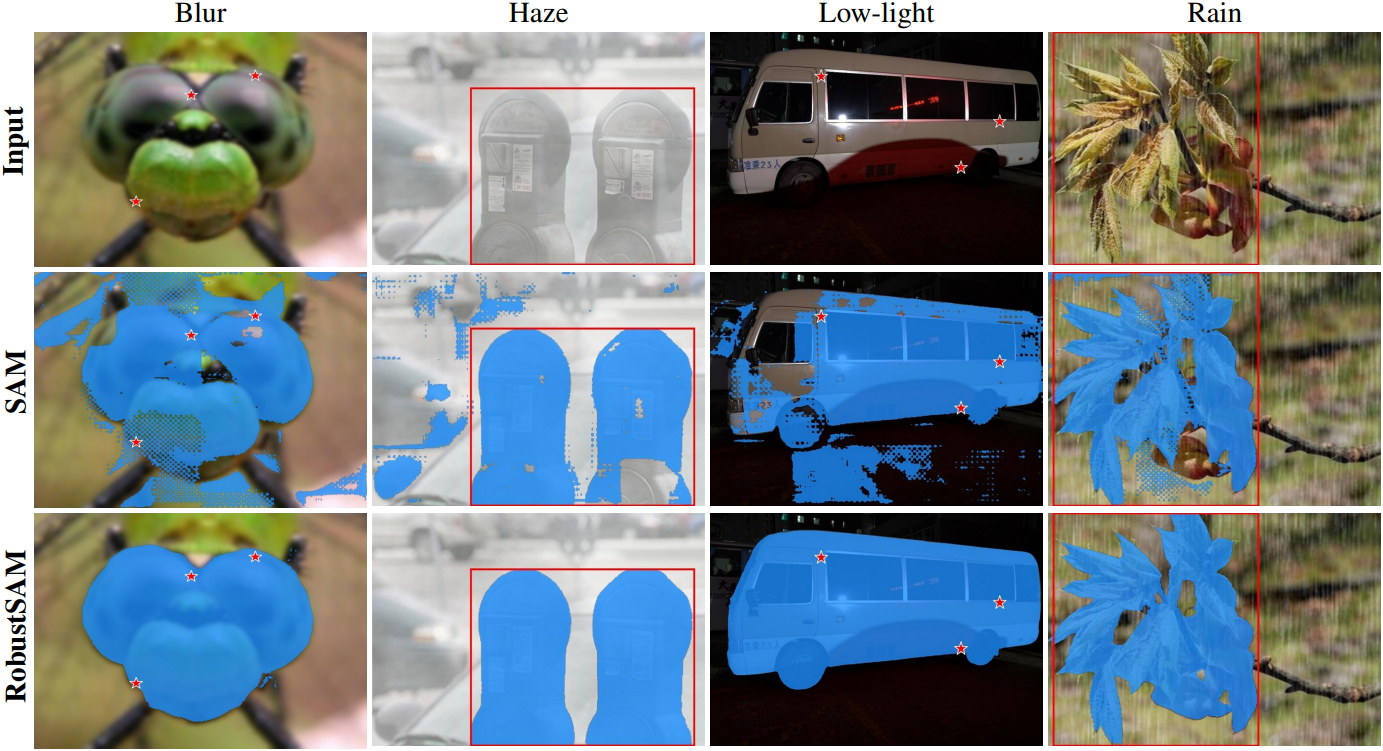
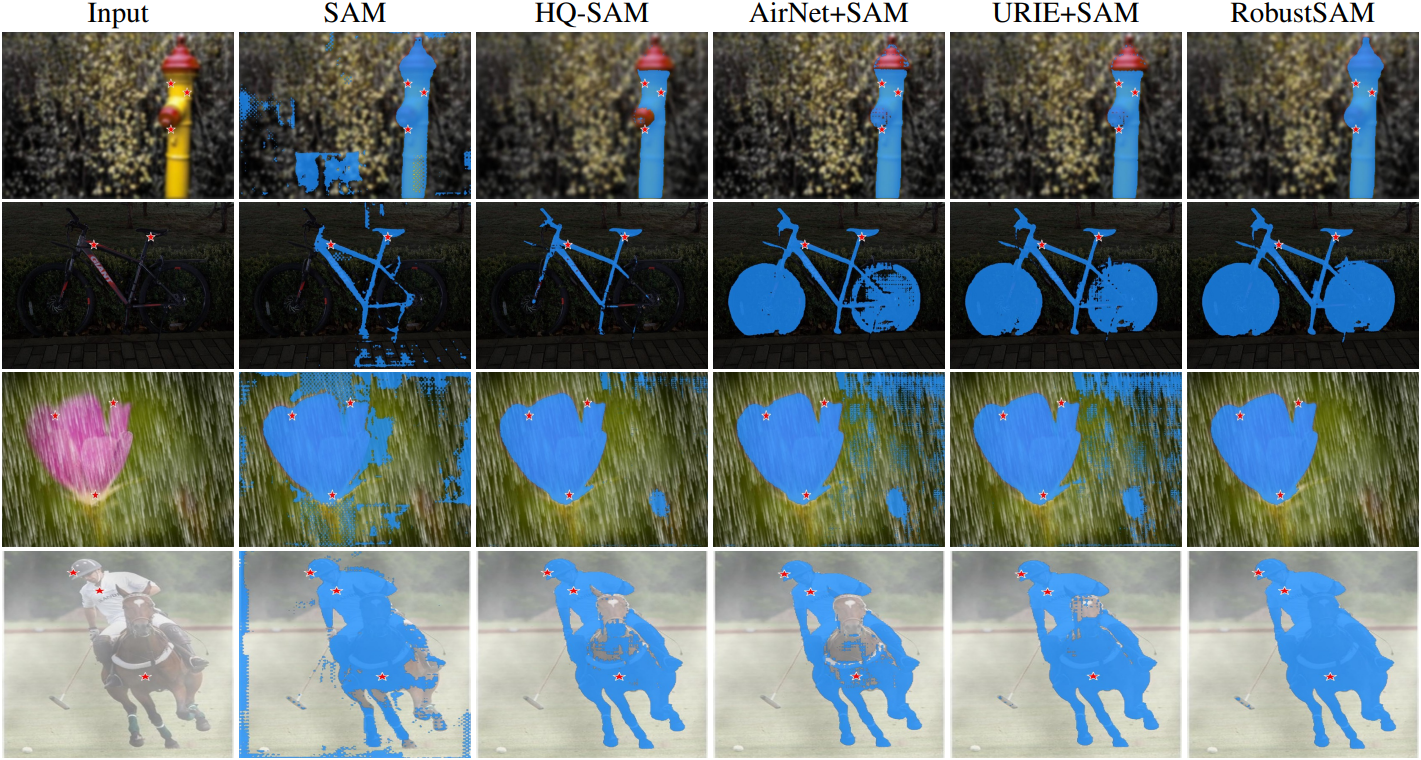
다음은 zero-shot segmentation 예시이다.
2. Ablation Study
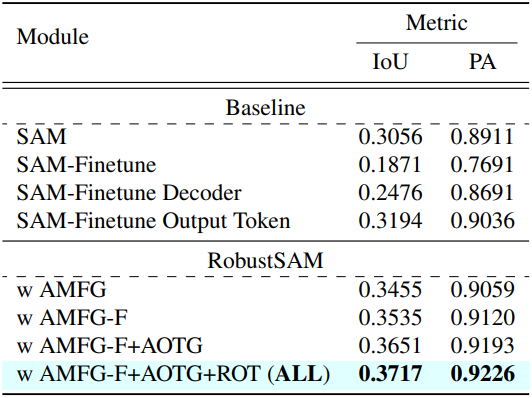
다음은 제안된 모듈들에 대한 ablation 결과이다.
3. Improving SAM-prior Tasks
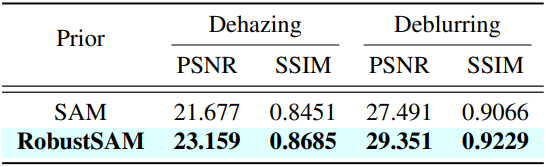
다음은 SAM과 RobustSAM을 prior로 사용하여 dehazing 및 deblurring task에 적용한 결과를 비교한 것이다.