[논문리뷰] Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers (RO-ViT)
CVPR 2023. [Paper] [Github]
Dahun Kim, Anelia Angelova, Weicheng Kuo
Google Research, Brain Team
11 May 2023
Introduction
객체를 탐지하는 능력은 컴퓨터 비전과 기계 지능의 특징이다. 그러나 최신 물체 감지기는 일반적으로 영역 및 클래스 레이블의 수동 주석에 의존하므로 vocabulary 크기가 $10^3$ 단위로 제한되며 추가로 확장하는 데 엄청난 비용이 든다. 이는 우리가 실제 접하는 물체보다 훨씬 작은 크기이다.
최근에는 테스트 시에 사용자가 제공한 텍스트 쿼리를 학습하고 수집하기 위해 풍부한 이미지-텍스트 쌍을 활용하여 이러한 한계를 극복하기 위해 open-vocabulary detection task (OVD)가 제안되었다. 카테고리를 이산 ID가 아닌 텍스트 임베딩으로 취급함으로써 open-vocabulary detector는 학습하는 동안 보지 못한 다양한 객체를 유연하게 예측할 수 있다. 대부분의 기존 연구들은 open-vocabulary 개념에 대한 풍부한 semantic 지식을 포함하는 이미지-텍스트 사전 학습을 활용한다. Knowledge distillation, weak supervision, self-training, frozen model이 제안되었으며 CNN backbone이 가장 일반적으로 사용된다. 이미지 이해, 멀티모달, self-supervised task에서 ViT의 인기가 높아짐에 따라 ViT를 사용하여 유능한 open-vocabulary detector를 구축하는 방법을 이해하는 것이 중요하다.
기존의 모든 연구들은 사전 학습된 Vision-Language Model (VLM)이 제공되고 적응 또는 fine-tuning 방법을 개발하여 이미지 레벨 사전 학습과 객체 레벨 fine-tuning 사이의 격차를 해소한다고 가정한다. VLM은 이미지 레벨 task용으로 설계되었기 때문에 사전 학습 프로세스에서 적절하게 활용되지 않는다. 저자들은 이미지-텍스트 사전 학습에서 로컬 정보를 사용한다면 open-vocabulary detection에 도움이 될 것이라고 생각하였다.
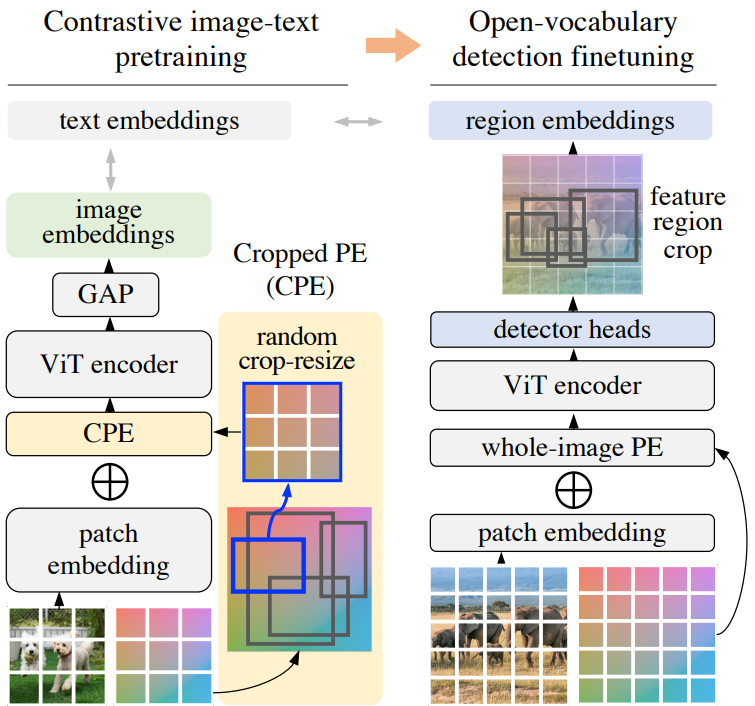
본 논문은 open-vocabulary object detection을 위해 region-aware 방식으로 ViT를 사전 학습하는 RO-ViT를 제시한다. 표준 사전 학습은 일반적으로 전체 이미지 위치 임베딩을 사용하며 이는 detection task로 잘 일반화되지 않는다. 따라서 본 논문은 detection fine-tuning에서 영역 자르기의 사용과 더 잘 일치하는 Cropped Positional Embedding (CPE)이라는 새로운 위치 임베딩 체계를 제안한다 (위 그림 참조). 또한 contrastive learning의 softmax cross entropy loss를 focal loss로 대체하는 것이 유익하다는 것을 발견했다. 이는 더 어렵고 더 유익한 예제에서 학습할 수 있는 더 많은 제어를 제공한다. 마지막으로 새로운 object proposal의 최근 발전을 활용하여 open-vocabulary detection fine-tuning을 개선한다. 그 동기는 proposal이 전경 카테고리에 overfitting되는 경향이 있기 때문에 기존 접근 방식이 object proposal 단계에서 새로운 객체를 놓치는 경우가 많다는 것이다.
Method
본 논문에서는 open-vocabulary detection의 문제를 다룬다. 학습 시에 모델은 기본 카테고리 $C_B$의 detection label에 액세스할 수 있지만 테스트 시에는 새로운 카테고리 $C_N$의 집합에서 객체를 탐지해야 한다. 사전 학습된 Vision-Language Model (VLM)을 활용하기 위해 기존 연구들을 따른다. 본 논문은 기존 연구들과 달리 open-vocabulary detection을 위한 ViT를 사용하여 자체 VLM을 가장 잘 사전 학습하는 방법을 탐색하였다.
1. Preliminaries
Contrastive image-text pretraining
Contrastive image-text learning에는 이미지 인코더와 텍스트 인코더가 포함된다. 텍스트 인코더는 일반적으로 transformer 인코더인 반면 이미지 인코더는 CNN 기반 또는 ViT일 수 있다. 이미지-텍스트 집합이 주어지면 모델은 각 이미지와 해당 텍스트를 함께 가져오고 일치하지 않는 다른 텍스트를 임베딩 space에서 밀어내는 방법을 학습한다. 가장 일반적인 목적 함수는 softmax cross-entropy loss이다. 이미지/텍스트 임베딩은 일반적으로 클래스 토큰 임베딩, self-attention pooling 또는 average pooling을 사용하여 얻는다. 이미지 임베딩과 텍스트 임베딩 모두에 대해 global average pooling과 L2 정규화를 사용한다.
Open-vocabulary object detector
Open-vocabulary object detector는 기본 카테고리 $C_B$의 레이블로 학습되지만 테스트 시에 기본 카테고리와 새로운 카테고리 $C_N$의 합집합 $C_B \cup C_N$을 탐지해야 한다. 대부분의 object detector는 학습과 테스트의 카테고리 수가 동일하기 때문에 K-way classifier를 사용한다. 테스트 시 추가 카테고리를 처리하기 위한 일반적인 관행은 기존의 고정 크기 classifier fully-connected layer를 기본 카테고리의 텍스트 임베딩으로 대체하는 것이다. 사전 학습 중에 이미지 인코더의 일치하는 텍스트 인코더에서 텍스트 임베딩을 가져오는 것이 중요하므로 open-vocabulary 지식이 보존된다. “배경” 문구로 배경 카테고리를 나타내며 $C_B$의 주석과 일치하지 않는 proposal은 배경으로 표시된다.
학습하는 동안 RoI-Align feature (즉, 영역 임베딩)과 $C_B$의 텍스트 임베딩 사이의 코사인 유사도로 각 영역 $i$에 대한 탐지 점수 $p_i$를 계산한 다음 softmax를 계산한다. 테스트 시 $C_B$에서 $C_B \cup C_N$으로 텍스트 임베딩을 확장하고 open-vocabulary detection을 위한 “배경” 카테고리를 추가한다. ViT backbone의 출력 feature map에서 RoI-Align에 의해 영역 $i$의 VLM 임베딩을 추출하고 $C_B \cup C_N$ 텍스트 임베딩과의 코사인 유사도로 VLM 영역 점수 $z_i$를 계산한다. 마찬가지로 탐지 점수 $p_i$는 이제 $C_B \cup C_N$ 텍스트 임베딩으로 계산된다. 결합된 open-vocabulary 탐지 점수 $s_i^\textrm{OVD}$는 다음과 같이 얻어진다.
\[\begin{equation} s_i^\textrm{OVD} = \begin{cases} z_i^{(1 - \alpha)} \cdot p_i^\alpha & \quad \textrm{if} \; i \in C_B \\ z_i^{(1 - \beta)} \cdot p_i^\beta & \quad \textrm{if} \; i \in C_N \end{cases} \end{equation}\]여기서 $\alpha, \beta \in [0, 1]$는 기본 카테고리와 새로운 카테고리에 대한 가중치를 제어한다. “배경” 문구가 있는 VLM 점수는 신뢰할 수 없는 경향이 있기 때문에 배경 점수는 탐지 점수 $p_i$에서 직접 가져온다.
Detector에 Mask R-CNN head를 채택하고 기존 연구들을 따라 클래스에 구애받지 않는 box regression과 마스크 예측 head를 사용한다. 대조적으로 사전 학습된 ViT를 사용하여 detector backbone를 초기화하고 간단한 feature pyramid와 windowed attention을 채택하여 고해상도 이미지 입력을 처리한다.
2. Region-Aware Image-Text Pretraining
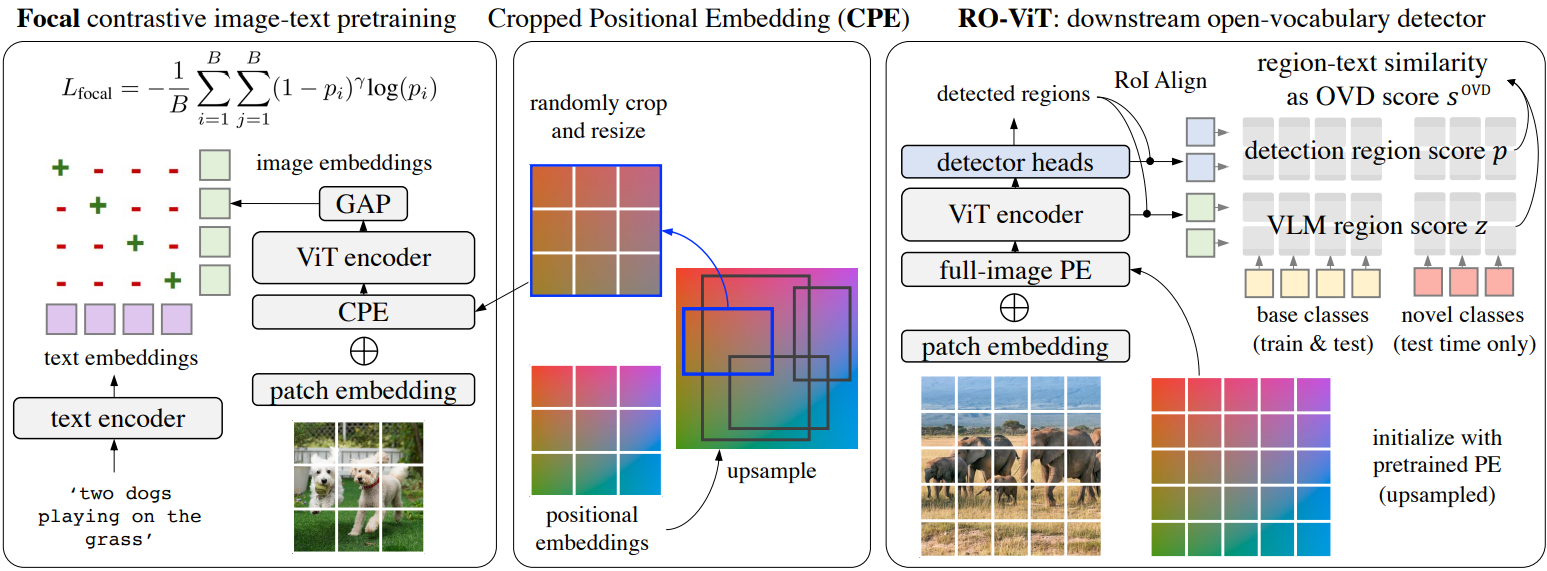
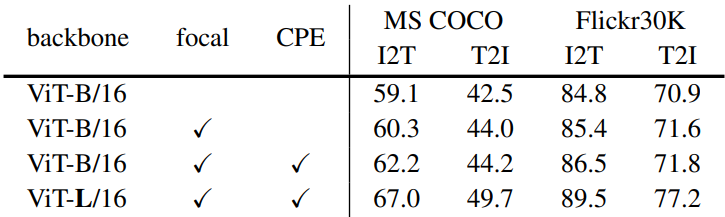
기존 VLM은 이미지를 전체적으로 텍스트 설명과 일치시키도록 학습된다. 그러나 사전 학습은 영역 레벨 표현과 다운스트림 open-vocabulary detection에 필수적인 텍스트 토큰 간의 정렬을 인식하지 못한다. 본 논문은 이 격차를 해소하기 위해 새로운 Cropped Positional Embedding (CPE)을 제안하고 focal loss가 있는 어려운 예제에서 배우는 것이 유익하다는 것을 발견했다. 이 개선 사항은 추가 파라미터가 없고 계산 비용이 최소화된다.
Cropped Positional Embedding (CPE)
위치 임베딩은 집합의 각 요소가 어디에서 왔는지에 대한 정보를 제공하므로 transformer에 중요하다. 이 정보는 종종 다운스트림 recognition task와 localization task에 유용하다.
위치 임베딩이 기존의 contrastive 사전 학습 접근 방식과 open-vocabulary detection fine-tuning에 사용되는 방식 간에 불일치가 있다. 사전 학습 접근 방식은 일반적으로 학습 중에 전체 이미지 위치 임베딩을 적용하고 다운스트림 task에 대해 동일한 위치 임베딩을 사용한다. 그러나 인식은 영역 레벨에서 발생하며, 사전 학습 중에 절대 볼 수 없는 영역으로 일반화하려면 전체 이미지 위치 임베딩이 필요하다.
이 격차를 해소하기 위해 Cropped Positional Embedding (CPE)를 제안한다. 먼저 위치 임베딩을 사전 학습에 일반적인 이미지 크기 (ex. 224)에서 detection task의 일반적인 이미지 크기 (ex. 1024)로 업샘플링한다. 그런 다음 업샘플링된 위치 임베딩에서 영역을 무작위로 자르고 rescale하고 이를 사전 학습 중 이미지 레벨 위치 임베딩으로 사용한다. Crop scale이 $[0.1, 1.0]$ 안에 있도록 유지하면서 $x_1 \sim \textrm{Uniform} (0, 1)$, $y_1 \sim \textrm{Uniform} (0, 1)$, $x_2 \sim \textrm{Uniform} (x_1, 1)$, $y_2 \sim \textrm{Uniform} (y_1, 1)$로 정규화된 좌표에서 영역을 균일하게 샘플링한다.
직관적으로 이것은 모델이 이미지를 그 자체로 전체 이미지가 아니라 더 큰 알려지지 않은 이미지에서 잘라낸 영역으로 보도록 한다. 이는 이미지 레벨이 아닌 영역에서 인식이 발생하는 detection의 다운스트림 사용 사례와 더 잘 일치한다.
Focal Loss
저자들은 softmax cross entropy loss가 제공할 수 있는 것보다 어려운 예제에 가중치를 부여하는 방법을 더 세밀하게 제어하고자 하였다. Focal loss는 어려운 예제의 가중치를 조정하는 자연스러운 옵션을 제공한다. $v_i$와 $l_i$를 정규화된 이미지와 텍스트 임베딩이라고 하고 image-to-text (I2T) contrastive loss를 softmax (baseline) $L_\textrm{softmax}$ 또는 focal loss (RO-ViT) $L_\textrm{focal}$이라고 하자.
\[\begin{equation} L_\textrm{softmax} = - \frac{1}{B} \sum_{i=1}^B \log (\frac{\exp (v_i l_i / \tau)}{\sum_{j=1}^B \exp (v_i l_j / \tau)}) \\ L_\textrm{focal} = - \frac{1}{B} \sum_{i=1}^B \sum_{j=1}^B (1 - p_i)^\gamma \log (p_i) \end{equation}\]여기서 $p_i$는 아래와 같이 실제 클래스 확률을 나타낸다.
\[\begin{equation} p_i = \begin{cases} \sigma (v_i l_j / \tau) & \quad \textrm{if} \; i = j \\ 1 - \sigma (v_i l_j / \tau) & \quad \textrm{if} \; i \ne j \end{cases} \end{equation}\]여기서 $\sigma$는 시그모이드 함수이다. Text-to-image (T2I) contrastive loss는 단순히 합 순서를 바꾸어 I2T loss와 대칭이다. 총 loss는 I2T loss와 T2I loss의 합계이다.
3. Open-vocabulary Detector Finetuning
저자들은 다운스트림 open-vocabulary detector를 개선하기 위한 두 가지 간단한 기술을 제시하였다. 방대한 open-vocabulary 데이터에서 사전 학습된 backbone feature에도 불구하고 추가된 detector layer는 다운스트림 detection 데이터셋 (ex. LVIS 기본 카테고리)로 새로 학습된다. 기존 접근 방식은 object proposal 단계에서 새롭거나 레이블이 지정되지 않은 객체를 누락하는 경우가 많다. 이는 proposal이 객체를 배경으로 분류하는 경향이 있기 때문이다. 이를 해결하기 위해 새로운 object proposal 방법의 최근 발전을 활용하고 객체 여부 이진 분류 점수 대신 localization 품질 기반 객체성 점수를 채택한다. 위치당 단일 앵커를 사용하고 앙상블 탐지 점수 $s_i^\textrm{OVD}$와 예측된 객체성 점수 $o_i$를 결합하여 다음과 같이 최종 OVD 점수를 얻는다.
\[\begin{equation} S_i^\textrm{OVD} = o_i^\delta s_i^\textrm{OVD} \end{equation}\]추가로, 표준 classifier와 마스크 출력 레이어를 정규화된 레이어로 교체한다. 이 L2-norm은 가중치 $w$와 feature $x$를 다음과 같이 정규화한다.
\[\begin{equation} f(x; w, b, \tau) = \frac{\tau}{\| w \|_2 \| x \|_2} w^\top x + b \end{equation}\]여기서 $\tau = 20$이다. 학습에 드문 카테고리가 없지만 경험적으로 유익한 것으로 나타났다.
Experimental Results
- 사전 학습 디테일
- 데이터셋: ALIGN
- 이미지 인코더: ViT-B/16, ViT-L/16
- 입력 이미지 크기: 224$\times$224
- 패치 크기: 16$\times$16
- 위치 임베딩 크기: 14$\times$14
- Cropped Positional Embedding (CPE)
- 먼저 위치 임베딩을 64$\times$64 크기로 통합
- scale ratio는 [0.1, 1.0], 종횡비는 [0.5, 2.0] 안에서 영역을 랜덤하게 자름
- 자른 영역은 14$\times$14으로 크기 조정 후 패치 임베딩에 더해짐
- 마지막 ViT 레이어에 global average pooling을 적용하여 이미지 임베딩 추출
- 텍스트 인코더: 12-layer Transformer
- 최대 텍스트 길이: 64
- batch size: 16384
- optimizer: AdamW
- learning rate: $5 \times 10^{-4}$ (linear warmup 1만 step)
- iteration 수: 500
- 다운스트림 detection 디테일
- 데이터셋: LVIS / COCO (1024$\times$1024)
- batch size: 256 / 128
- iteration 수: 4.61만 / 1.13만
- optimizer: SGD
- 초기 learning rate: 0.36 / 0.02
- momentum: 0.9
- weight decay: $10^{-4}$ / $10^{-2}$
- 사전 학습된 위치 임베딩은 더 높은 해상도의 패치 임베딩 크기에 맞게 조정하기 위해 쌍선형으로 보간됨
- 사전 학습 지식을 유지하기 위해 모델의 나머지 부분보다 backbone의 learning rate를 낮게 설정
- $\alpha$ = 0.65, $\beta$ = 0.3, $\delta$ = 3
- RPN 단계에서 OLN-RPN를 사용 (NMS threshold는 학습 시 0.7, 테스트 시 1.0)
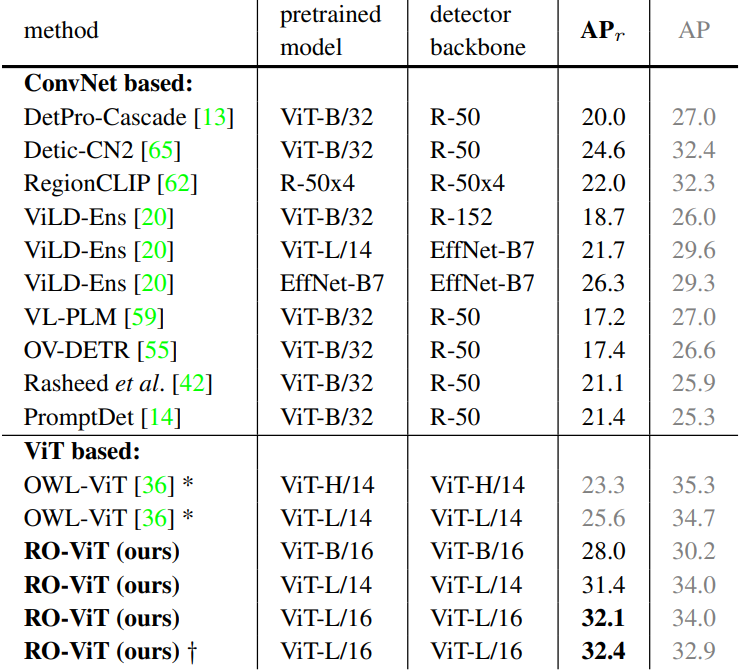
1. Open-vocabulary Object Detection
다음은 LVIS에서의 open-vocabulary object detection 결과이다. (mask AP)
다음은 COCO에서의 open-vocabulary object detection 결과이다. (box AP50)

2. Image-Text Retrieval
다음은 COCO와 Flickr30K에서의 zero-shot 이미지-텍스트 검색 결과이다.
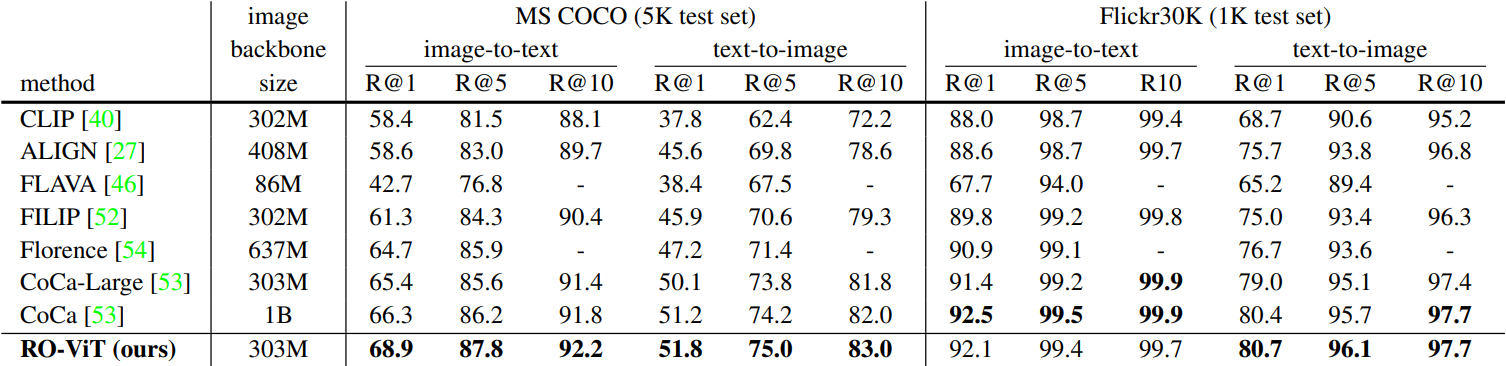
3. Transfer Object Detection
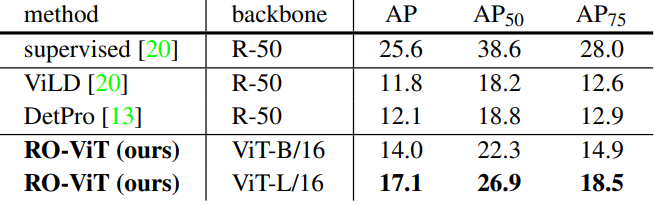
다음은 Objects365에서의 transfer detection 결과이다.
4. Ablation Study
다음은 사전 학습 전략에 대한 ablation 결과이다.

다음은 zero-shot 이미지-텍스트 검색에 대한 사전 학습 평가 결과이다 .
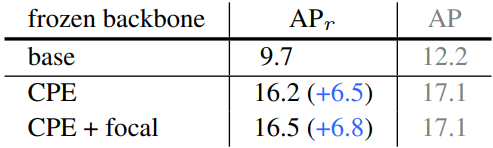
다음은 고정된 backbone에 대한 ablation 결과이다.
다음은 backbone fine-tuning의 learning rate에 대한 ablation 결과이다.
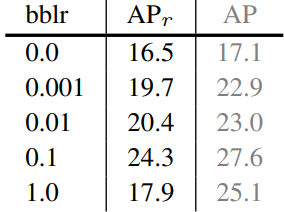
다음은 detector 개선에 대한 ablation 결과이다. loc.obj는 localization 품질 기반 객체성 점수를 의미하고 norm.lyr는 정규화된 classifier와 마스크 출력 레이어를 의미한다.

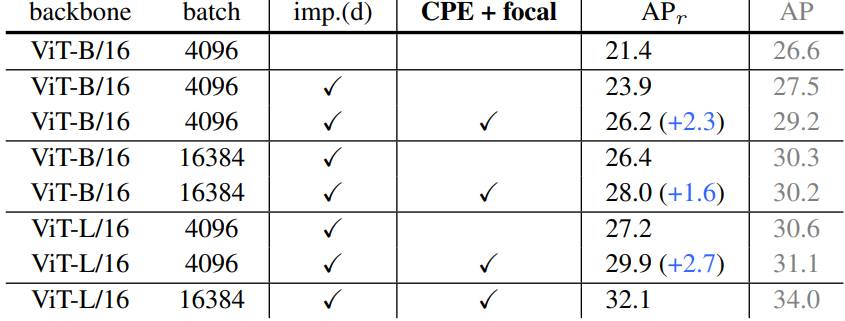
다음은 모델 크기와 batch size에 대한 ablation 결과이다. imp.(d)는 위 표의 detector 개선을 의미한다.
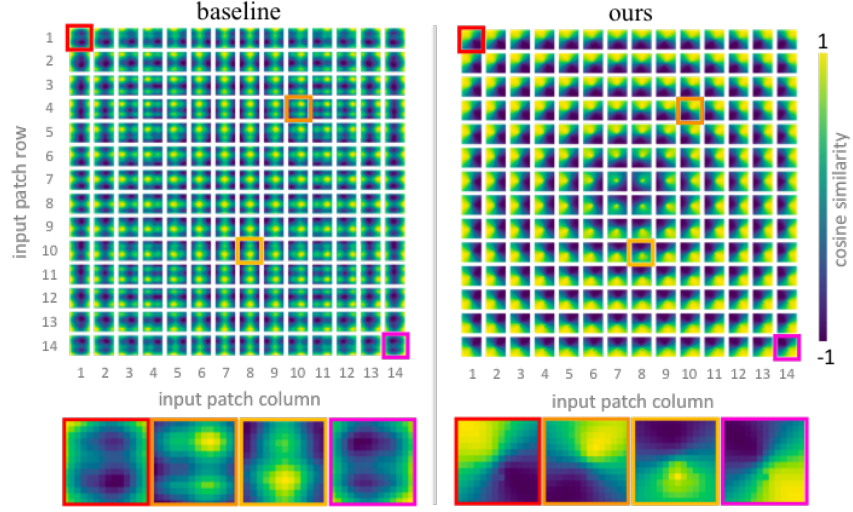
5. Visualization of Positional Embeddings
다음은 학습된 위치 임베딩을 시각화한 것이다.