[논문리뷰] Rig3R: Rig-Aware Conditioning for Learned 3D Reconstruction
arXiv 2025. [Paper] [Page]
Samuel Li, Pujith Kachana, Prajwal Chidananda, Saurabh Nair, Yasutaka Furukawa, Matthew Brown
Wayve Technologies | Carnegie Mellon University
2 Jun 2025
Introduction
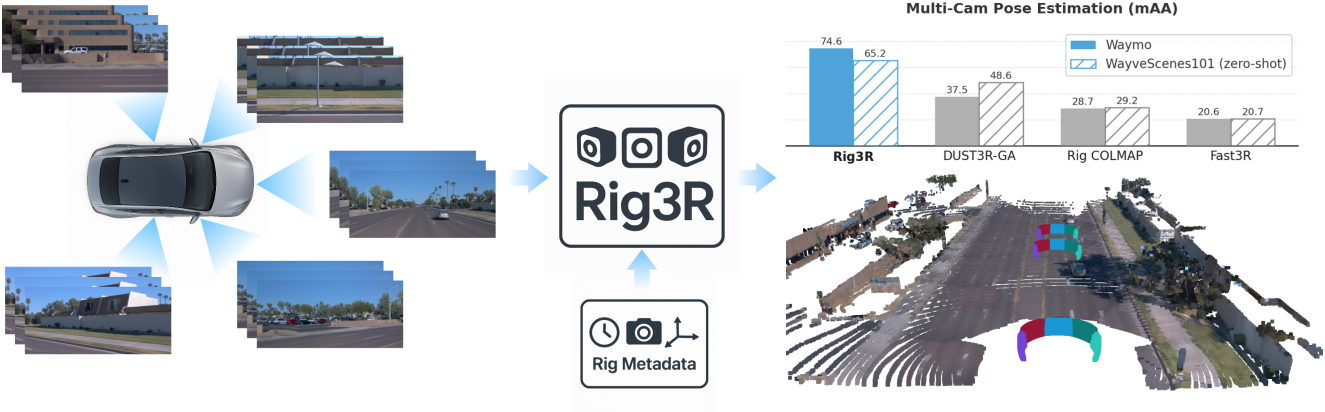
DUSt3R와 같은 최근 방법들은 멀티뷰 3D 재구성에서 인상적인 성능을 보여주었으며, 많은 후속 방법들이 이를 single-pass inference로 확장했다. 그러나 이러한 방법들은 이미지를 비정형화된 집합으로 취급한다는 한계가 있다. 이는 실제 응용 분야에서 흔히 나타나는 중요한 구조적 prior, 즉 이미지는 고정된 상대적 구성을 가진 동기화된 멀티 카메라 리그를 사용하여 촬영되는 경우가 많다는 점을 간과한다. 카메라 ID, 타임스탬프, 상대적 포즈와 같은 리그 메타데이터는 특히 시야 중첩이 제한될 때 귀중한 단서를 제공할 수 있다. 기존 파이프라인은 이러한 구조를 활용할 수 있지만, feedforward 모델은 현재 이 구조를 활용하지 않고 있다.
본 논문은 멀티뷰 3D 재구성 및 포즈 추정을 위한 transformer 기반 모델인 Rig3R을 소개한다. Rig3R은 리그 메타데이터가 있는 경우 이를 활용하고, 없는 경우 리그 구조를 추론하도록 학습되었다. Rig3R은 한 번의 forward pass에서 각 이미지에 대한 dense pointmap과 raymap을 예측한다. Raymap은 카메라의 intrinsic 및 extrinsic 정보를 공간적으로 인코딩하며, 하늘이나 동적 픽셀과 같이 모호한 영역에서도 closed form으로 복원할 수 있다. 이러한 유연성을 지원하기 위해 Rig3R은 메타데이터 임베딩과 dropout 학습을 결합하고, 메타데이터를 사용할 수 없는 경우 이미지 콘텐츠에서 리그 구조를 직접 추론하는 전용 리그 예측 head를 포함한다.
Method
본 논문은 $N$개의 RGB 이미지 세트 \(\{I_i\}_{i=1}^N\)에서 3D 구조와 카메라 포즈를 예측하는 것을 목표로 한다. 입력은 순서가 지정되지 않은 이미지 컬렉션부터 멀티 카메라 리그에서 촬영한 시간적으로 분포된 뷰까지 다양하다. 각 이미지에는 선택적으로 메타데이터 \(M_i = \{c_i, t_i, r_i\}\)가 포함될 수 있으며, 여기서 $c_i$는 카메라 ID, $t_i$는 타임스탬프, $r_i$는 카메라 포즈를 인코딩하는 리그 기준 raymap이다. 각 메타데이터 필드는 선택 사항이며 학습 및 inference 과정에서 독립적으로 생략될 수 있다.
입력 \(\{I_i, M_i\}_{i=1}^N\)이 주어지면, 모델은 각 이미지에 대해 다음을 예측한다.
- Pointmap $P_i \in \mathbb{R}^{3 \times H \times W}$: 첫 번째 이미지 프레임에 대한 픽셀별 3D 좌표
- Confidence map $C_i \in \mathbb{R}^{H \times W}$: Pointmap loss에 가중치를 부여
- Pose raymap \(R_i^\textrm{pose} \in \mathbb{R}^{6 \times H \times W}\): 첫 번째 이미지 프레임을 기준으로 카메라 파라미터를 인코딩
- Rig raymap \(R_i^\textrm{rig} \in \mathbb{R}^{6 \times H \times W}\): 자체 모션과 분리된 리그 중심 프레임을 기준으로 카메라 파라미터를 인코딩
1. Raymap Representation
Rig3R은 pose head와 rig head 모두에서 dense한 raymap을 출력한다. Raymap은 각 픽셀에 단위 광선 방향을 할당하는 방향 필드이며, 모든 광선은 공유 카메라 중심에서 시작된다. 이 표현은 카메라 intrinsic과 포즈를 모두 통일되고 기하학적으로 일관된 형식으로 인코딩한다.
각 픽셀 $(u, v)$에 대해, 광선 \(\hat{\textbf{r}}_{uv} \in \mathbb{S}^2\)는 \(\hat{\textbf{r}}_{uv} = \textbf{R} \cdot \textbf{K}^{-1} [u,v,1]^\top\)으로 계산된다. 모든 광선은 공통된 카메라 중심 $\textbf{c} \in \mathbb{R}^3$을 공유한다.
Raymap은 다른 표현 방식에 비해 주요 장점을 제공한다. 공간적으로 정렬된 픽셀별 supervision을 제공하고, 하늘이나 동적 물체와 같이 모호한 영역에서도 안정적인 신호 역할을 한다. 3D 예측을 통해 간접적으로 포즈를 추론하고 이러한 영역에서 종종 실패하는 pointmap과 달리, raymap은 포즈 추정에 있어 더욱 직접적이고 일관된 표현을 제공한다. 또한 해석 가능한 geometry를 인코딩하여 광선 방향과 픽셀 거리에서 카메라의 intrinsic 및 extrinsic을 closed-form으로 복원할 수 있다.
저자들은 픽셀-광선 대응 관계에서 도출된 각도 제약 조건을 사용하여 초점 거리를 복원하고, 정렬된 광선들에 SVD를 사용하여 closed form으로 rotation을 추정하였다.
2. Rig-Aware Metadata
각 이미지는 선택적으로 메타데이터 튜플 \(M_i = \{c_i, t_i, r_i\}\)와 연결될 수 있다. 여기서 $c_i$는 동일한 카메라의 모든 이미지에서 공유되는 개별 카메라 식별자이고, $t_i \in \mathbb{R}$은 초 단위로 정규화된 continuous한 타임스탬프이며, $r_i \in \mathbb{R}^{H \times W \times 6}$은 리그 내 카메라의 포즈를 인코딩하는 리그 기준 raymap이다. 이 메타데이터는 멀티뷰 추론을 위한 기하학적 및 시간적 컨텍스트를 제공한다. 카메라 ID와 타임스탬프의 조합은 프레임 ID의 구조적 분해를 형성하여 시공간적 정렬에 대한 강력한 단서를 제공한다. 모든 메타데이터 필드는 선택 사항이며 학습 중에 독립적으로 제거하여 누락된 정보에 대한 robustness를 높일 수 있다.
3. Model Architecture
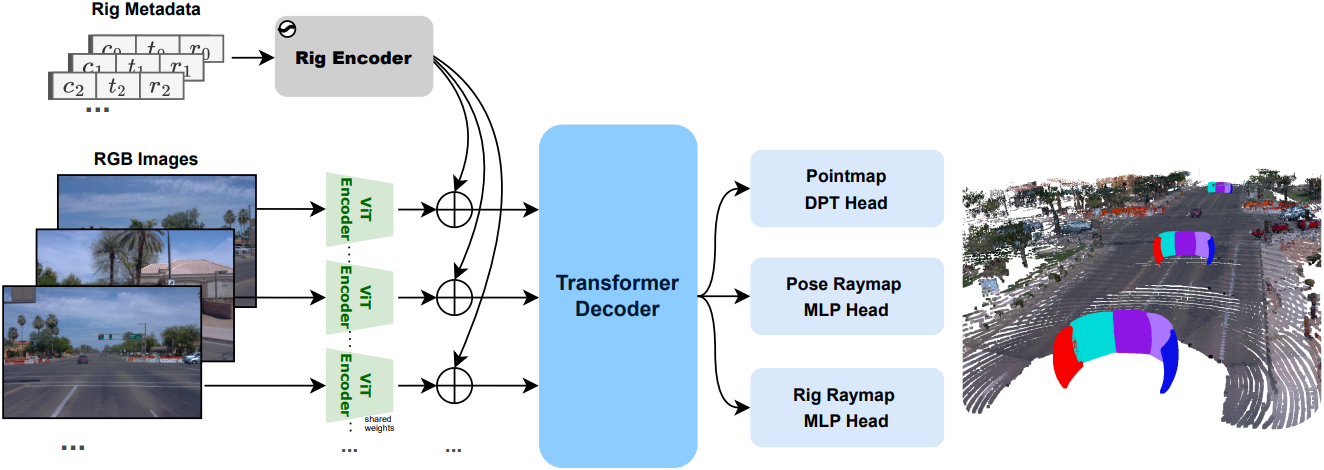
이미지 인코더
Rig3R은 공유 ViT-Large 인코더를 사용하여 2D 사인-코사인 위치 인코딩을 통해 각 입력 이미지를 독립적으로 patchify하고 인코딩한다. 본 논문에서는 DUSt3R를 기반으로 이미지 인코더를 초기화하였다.
메타데이터 임베딩
각 패치는 선택적으로 메타데이터, 즉 프레임 인덱스 $N$, 카메라 ID $c_i$, 타임스탬프 $t_i$, rig raymap 패치 $r_i$로 augmentation된다. Discrete한 $N$과 $c_i$는 더 큰 인덱스 범위에서 무작위로 샘플링되고 1D 사인-코사인 임베딩을 사용하여 인코딩되어 다양한 수의 프레임과 카메라로 일반화할 수 있다. $t_i$는 초 단위로 정규화되고 유사하게 인코딩된다. $r_i$는 모델 차원으로 선형적으로 projection된다.
모든 성분은 concat되어 패치 토큰에 더해진다. 학습 중에 robustness를 높이기 위해 $c_i$, $t_i$, $r_i$는 랜덤하게 제거되고 프레임 인덱스 $N$은 항상 포함되어 transformer 내의 각 이미지를 고유하게 식별한다.
Transformer 디코더
모든 이미지의 패치 토큰은 처음부터 학습된 두 번째 ViT-Large transformer로 전달되며, 이 transformer는 전체 이미지 집합에 대해 joint self-attention을 수행한다. 이를 통해 Rig3R은 메타데이터가 있는 경우 메타데이터를 기반으로 시점과 시간에 걸쳐 정보를 집계할 수 있다. 공유 이미지 인코더와 달리, 디코더는 공유된 latent space에서 멀티뷰 feature를 융합한다.
예측 Head
Rig3R은 세 개의 head를 사용한다. 하나는 pointmap 예측용이고, 두 개는 raymap 예측용이며 (포즈 기준, 리그 기준), 프레임 간에 가중치가 공유된다. Pointmap head는 3D pointmap $P_i$와 신뢰도 맵 $C_i$를 예측하는 DPT 모듈이다. 각 raymap head는 두 개의 MLP로 구성된다. 하나는 픽셀당 광선 방향을 예측하고, 다른 하나는 패치 토큰에 대한 average pooling을 통해 글로벌한 카메라 중심을 예측한다. 이러한 설계는 전용 쿼리 토큰을 피하고 모든 gradient가 패치 토큰을 통해 흐르도록 하여 일관성을 향상시킨다.
이 세 가지 출력은 밀접하게 결합되어 있다. Pointmap은 pose raymap에 의해 정의된 광선을 따라 배치되며, rig raymap과 pose raymap은 자체 모션을 통해 연관된다. 이러한 멀티태스크 공식은 구조적 prior 역할을 하여 다양한 멀티뷰 설정에서 일관성과 일반화를 향상시킨다.
4. Training
학습 Loss
Rig3R은 pointmap, pose raymap, rig raymap에 대한 multitask loss를 사용하여 학습된다.
\[\begin{equation} \mathcal{L}_\textrm{total} = \mathcal{L}_\textrm{pmap} + \lambda_\textrm{p} \mathcal{L}_\textrm{p_rmap} + \lambda_\textrm{r} \mathcal{L}_\textrm{r_rmap} \end{equation}\]Pointmap loss \(\mathcal{L}_\textrm{pmap}\)는 DUSt3R를 따른다. 프레임 $v$에 대해 pointmap loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{pmap} = \sum_{i \in \mathcal{D}^v} C_i^v \| X_i^v - \frac{1}{\bar{z}} \bar{X}_i^v \| - \alpha \log C_i^v \end{equation}\]($X_i^v$는 예측된 3D 포인트, \(\bar{X}_i^v\)는 GT, $C_i^v$는 예측된 신뢰도, $\bar{z}$는 정규화에 사용된 평균 깊이, $\alpha$는 정규화 항 가중치)
Raymap loss \(\mathcal{L}_\textrm{rmap}\)에는 광선 방향과 카메라 중심에 대한 항이 모두 포함된다.
\[\begin{equation} \mathcal{L}_\textrm{rmap} = \sum_{h, w} \| \textbf{r}_{v,h,w} - \bar{\textbf{r}}_{v,h,w} \| + \beta \| \textbf{c}_v - \frac{1}{\bar{z}} \bar{\textbf{c}}_v \| \end{equation}\]저자들은 모델이 scale과 방향 norm을 직접 학습할 때, 특히 원점 근처에 있는 카메라 중심의 경우 학습이 더 안정적임을 확인했다.
Experiments
- 데이터셋: CO3D-v2, BlendedMVS, Mapfree, ScanNet++ v2, MVImgNet, PointOdyssey, Virtual KITTI2, TartanAir V2, PandaSet, KITTI, Argoverse2, nuScenes, Waymo, 사내 데이터셋
- 구현 디테일
- 학습 중에 각 메타데이터 필드는 50% 확률로 제거됨
- 이미지 크기: 512$\times$512
- batch size: 128 (각 샘플은 24 프레임)
- optimizer: AdamW
- learning rate: 0.0001 (cosine annealing)
- data augmentation: color jitter, Gaussian blur, centered aspect-ratio crop
- GPU: H100 128개
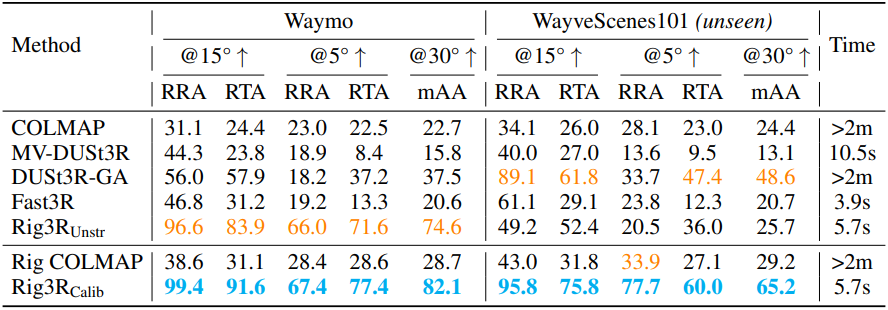
1. Camera Pose Estimation
다음은 멀티뷰 카메라 포즈 추정에 대한 성능 비교 결과이다.
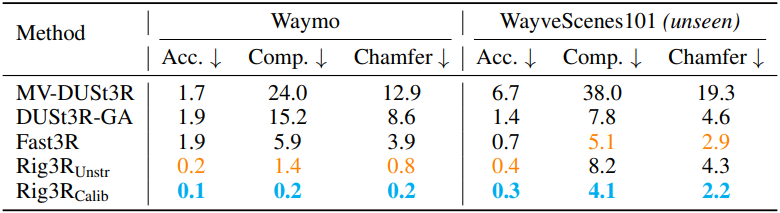
2. Pointmap Estimation
다음은 멀티뷰 pointmap 추정에 대한 성능 비교 결과이다.
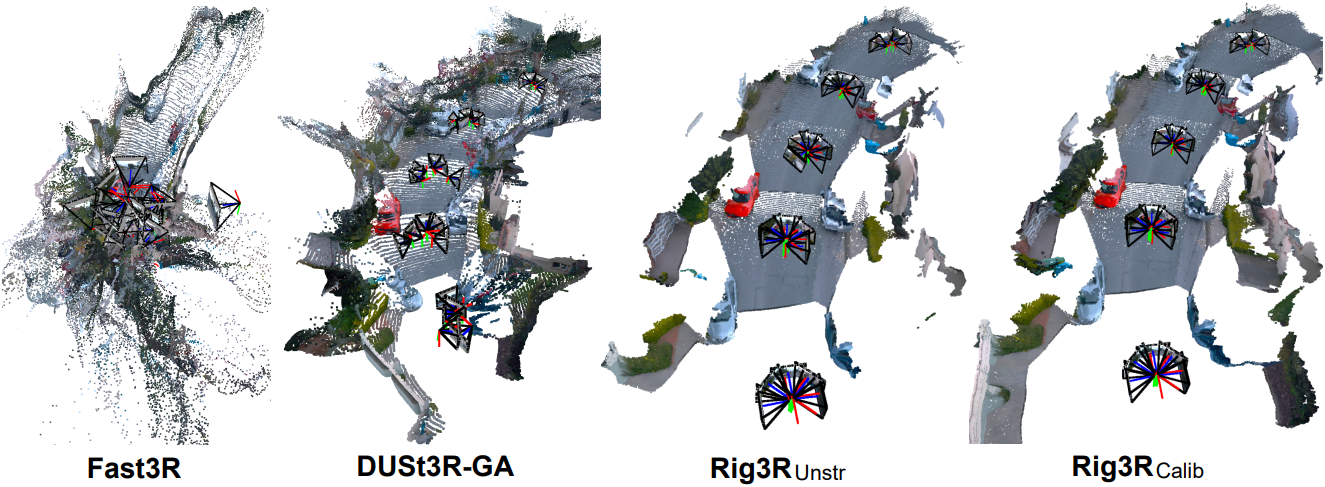
다음은 카메라 포즈와 pointmap에 대한 정성적 비교 결과이다.
3. Generalization Across Rig Configurations
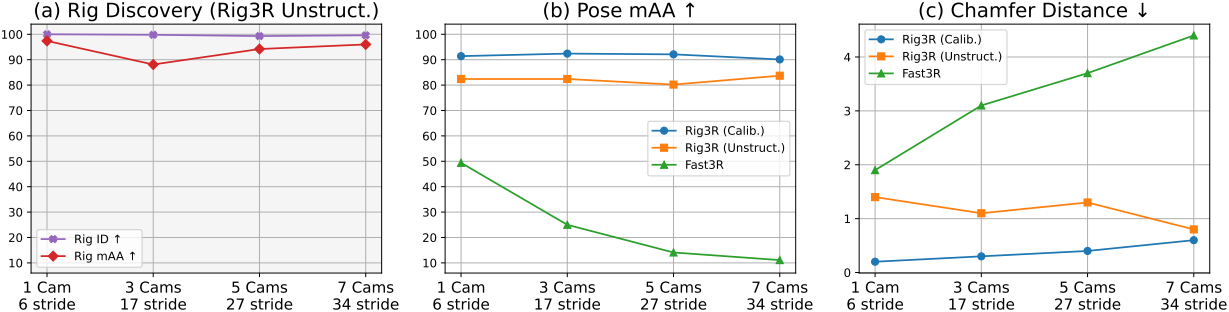
다음은 다양한 리그 설정에 대한 성능 비교 결과이다.
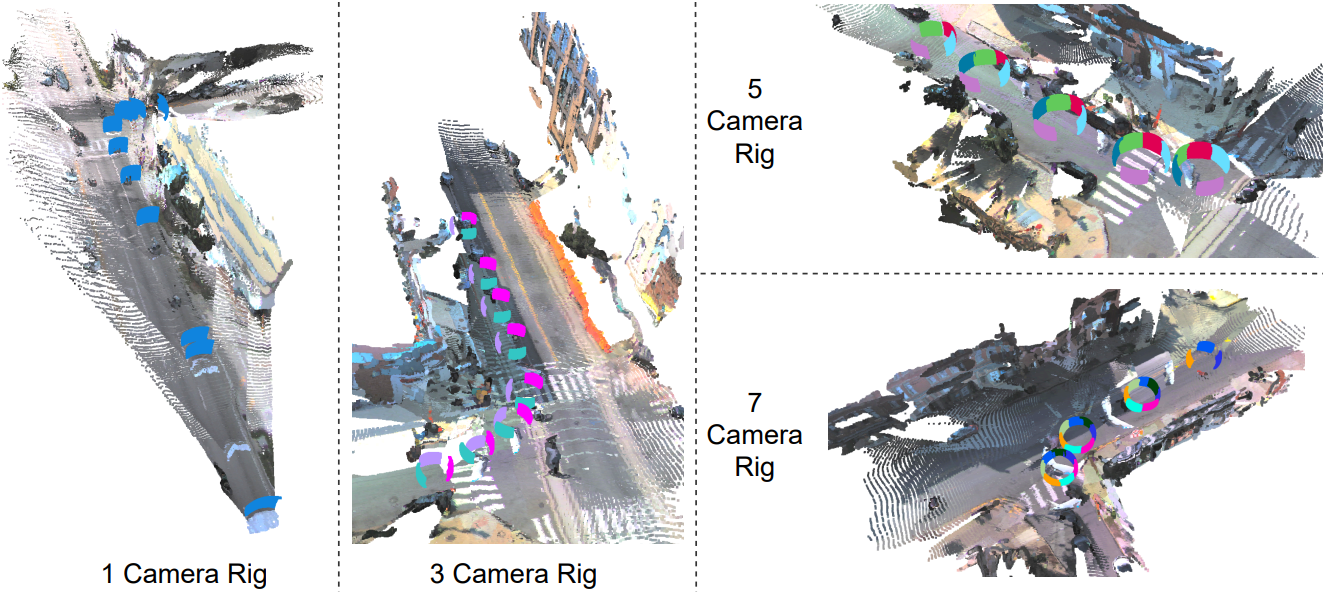
다음은 다양한 리그 설정에 대한 카메라 포즈와 pointmap 추정 예시들이다.
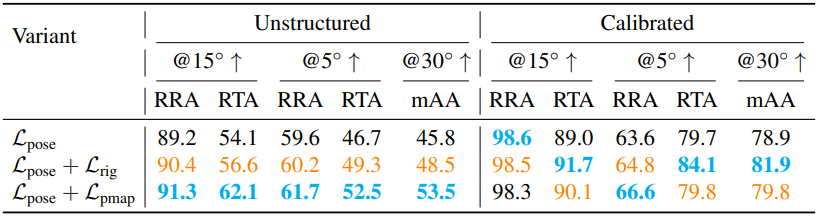
4. Ablation Studies
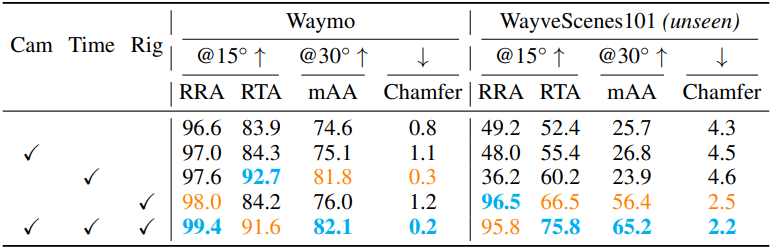
다음은 입력 메타데이터에 대한 ablation 결과이다.
다음은 head 조합에 대한 ablation 결과이다.