[논문리뷰] Expressive Text-to-Image Generation with Rich Text
ICCV 2023. [Paper] [Page] [Github] [Demo]
Songwei Ge, Taesung Park, Jun-Yan Zhu, Jia-Bin Huang
University of Maryland, College Park | Adobe Research | Carnegie Mellon University
13 Apr 2023

Introduction
대규모 text-to-image 생성 모델의 개발로 인해 이미지 생성이 전례 없는 시대로 발전했다. 이러한 대규모 모델의 뛰어난 유연성은 시각적 신호와 텍스트 입력을 통해 사용자에게 강력한 생성 제어 기능을 제공한다. 기존 연구들에서는 사전 학습된 언어 모델로 인코딩된 일반 텍스트를 사용하여 생성을 가이드한다. 그러나 일상생활에서 블로그 작성이나 에세이 편집 등 텍스트 기반 작업을 할 때 일반 텍스트만 사용하는 경우는 거의 없다. 대신, 텍스트 작성 및 편집을 위한 다양한 서식 옵션을 제공하는 서식 있는 텍스트 편집기(rich text editor)가 더 널리 사용된다. 본 논문에서는 서식 있는 텍스트 편집기에서 text-to-image 합성으로 접근 가능하고 정확한 텍스트 제어를 도입하려고 하였다.
서식 있는 텍스트 편집기는 텍스트와 별도로 조건부 정보를 통합하기 위한 고유한 솔루션을 제공한다. 예를 들어 폰트 색상을 사용하면 임의의 색상을 나타낼 수 있다. 이와 대조적으로 일반 텍스트 인코더는 RGB 또는 Hex triplet을 이해하지 못하고 ‘올리브’나 ‘주황색’과 같은 많은 색상 이름이 모호한 의미를 갖기 때문에 일반 텍스트로 정확한 색상을 설명하는 것이 더 어렵다. 이 폰트 색상 정보를 사용하여 생성된 개체의 색상을 정의할 수 있다. 예를 들어, 특정 노란색을 선택하여 정확한 색상의 대리석 조각상 생성을 지시할 수 있다.
정확한 색상 정보를 제공하는 것 외에도 다양한 폰트 형식을 사용하면 단어 수준 정보를 간단하게 늘릴 수 있다. 예를 들어, 토큰의 영향력을 재가중하는 것은 폰트 크기를 사용하여 구현할 수 있는데, 이는 기존의 시각적 또는 텍스트 인터페이스로는 달성하기 어려운 작업이다. 이외에도 폰트 스타일이 개별 텍스트 요소의 스타일을 구별하는 방식과 유사하게 이를 사용하여 특정 지역의 예술적 스타일을 캡처할 수 있다. 또한 각주를 사용하여 선택한 단어에 대한 보충 설명을 제공하여 복잡한 장면을 만드는 과정을 단순화할 수 있다.
하지만 서식 있는 텍스트를 어떻게 사용할 수 있을까? 간단한 구현은 자세한 속성이 포함된 서식 있는 텍스트 프롬프트를 긴 일반 텍스트로 변환하고 이를 기존 방법에 직접 제공하는 것이다. 안타깝게도 이러한 방법은 뚜렷한 시각적 특성을 가진 여러 개체가 포함된 긴 텍스트 프롬프트에 해당하는 이미지를 합성하는 데 어려움을 겪으며, 종종 스타일과 색상을 혼합하여 전체 이미지에 균일한 스타일을 적용한다. 게다가 프롬프트가 길면 텍스트 인코더가 정확한 정보를 해석하는 데 추가적인 어려움이 발생하여 복잡한 디테일을 생성하는 것이 더욱 까다로워진다.
이러한 문제를 해결하기 위해 본 논문은 서식 있는 텍스트 프롬프트를 다음과 같은 두 가지 구성 요소로 분해하였다.
- 짧은 일반 텍스트 프롬프트 (서식 없음)
- 텍스트 속성을 포함하는 여러 영역별 프롬프트
먼저, 각 단어를 특정 영역과 연결하는 짧은 일반 텍스트 프롬프트와 함께 일반 denoising process를 사용하여 self-attention map과 cross-attention map을 얻는다. 둘째, 서식 있는 텍스트 프롬프트에서 파생된 속성을 사용하여 각 영역에 대한 프롬프트를 생성한다. 예를 들어, “font style: Ukiyo-e” 속성이 있는 “mountain”이라는 단어에 해당하는 지역에 대한 프롬프트로 “mountain in the style of Ukiyo-e”을 사용한다. 프롬프트로 변환할 수 없는 RGB 폰트 색상의 경우 대상 색상과 일치하도록 영역 기반 guidance를 사용하여 영역을 반복적으로 업데이트한다. 각 지역마다 별도의 denoising process를 적용하고 예측된 noise를 융합하여 최종 업데이트를 얻는다. 이 과정에서 형식이 없는 토큰과 관련된 영역은 일반 텍스트 결과와 동일하게 보인다. 또한 색상만 변경되는 경우 등 개체의 전체 모양은 변경되지 않은 상태로 유지되어야 한다. 이를 위해 저자들은 영역 기반 주입 방법을 사용할 것을 제안하였다.
Rich Text to Image Generation

서식 있는 텍스트 편집기는 디지털 장치에서 텍스트를 편집하기 위한 기본 인터페이스인 경우가 많다. 그럼에도 불구하고 text-to-image 생성에는 일반 텍스트만 사용되었다. 서식 있는 텍스트 편집기에서 서식 옵션을 사용하기 위해 먼저 rich-text-to-image 생성이라는 문제 설정을 도입한다. 그런 다음 이 task에 대한 접근 방식을 논의한다.
1. Problem Setting
위 그림에 표시된 것처럼 서식 있는 텍스트 편집기는 폰트 스타일, 폰트 크기, 색상 등과 같은 다양한 서식 옵션을 지원한다. 이러한 텍스트 속성을 추가 정보로 활용하여 text-to-image 생성 제어를 강화한다. 서식 있는 텍스트 프롬프트를 JSON으로 해석한다. 여기서 각 텍스트 요소는 토큰 $e_i$의 span (ex. ‘church’)와 span을 설명하는 속성 $a_i$ (ex. ‘color:#FF9900’)로 구성된다. 일부 토큰 $e_U$에는 속성이 없을 수도 있다. 이러한 주석이 달린 프롬프트를 사용하여 저자들은 다음과 같은 네 가지 응용을 탐색하였다.
- 폰트 스타일을 사용한 로컬 스타일 제어
- 폰트 색상을 사용한 정확한 색상 제어
- 각주를 사용한 자세한 영역 설명
- 폰트 크기를 사용한 명시적인 토큰 재가중화
폰트 스타일은 토큰의 span $e_i$의 합성에 특정 예술적 스타일(ex. $a_i^s$ = ‘Ukiyo-e’)을 적용하는 데 사용된다. 예를 들어 Ukiyo-e 그림 스타일을 바다의 파도에 적용하고 반 고흐의 스타일을 하늘에 적용하여 영역별로 예술적 스타일을 적용할 수 있다. 다양한 예술적 스타일을 갖춘 학습 이미지가 제한되어 있기 때문에 이 task는 기존 text-to-image 모델에 대한 고유한 과제를 제시한다. 결과적으로 기존 모델은 뚜렷한 로컬 스타일보다는 전체 이미지에 걸쳐 균일한 혼합 스타일을 생성하는 경향이 있다.
폰트 색상은 수정된 텍스트 span의 특정 색상을 나타낸다. “a red toy”라는 프롬프트가 주어지면 기존의 text-to-image 모델은 연한 빨간색, 진홍색, 적갈색과 같은 다양한 빨간색으로 장난감을 생성한다. 색상 속성 $a_i^c$는 RGB 색상 공간에서 정확한 색상을 지정하는 방법을 제공한다. 예를 들어, 빨간색 벽돌색 장난감을 생성하려면 폰트 색상을 “a toy“로 변경할 수 있다. 여기서 “toy”라는 단어는 속성 $a_i^c = [178, 34, 34]$와 연결된다. 그러나 사전 학습된 텍스트 인코더는 RGB 값을 해석할 수 없으며 라임, 오렌지와 같이 모호한 색상 이름을 이해하는 데 어려움을 겪는다.
각주는 긴 문장으로 가독성을 방해하지 않으면서 타겟 span에 대한 보충 설명을 제공한다. 복잡한 장면에 대한 자세한 설명을 작성하는 것은 지루한 작업이며 필연적으로 긴 프롬프트가 생성된다. 또한 기존 text-to-image 모델은 여러 개체가 있을 때 특히 긴 프롬프트의 경우 일부 개체를 무시하는 경향이 있다. 또한 프롬프트 길이가 텍스트 인코더의 최대 길이를 초과하면 초과 토큰이 삭제된다 (ex. CLIP 모델의 경우 77개 토큰). 각주 문자열 $a_i^f$를 사용하여 이러한 문제를 완화하는 것을 목표로 한다.
폰트 크기는 개체의 중요성, 수량, 크기를 나타내는 데 사용될 수 있다. 각 토큰의 가중치를 표시하기 위해 스칼라 $a_i^w$를 사용한다.
2. Method
서식 있는 텍스트 주석을 활용하기 위해 본 논문의 방법은 두 단계로 구성된다.
- 개별 토큰 span의 공간 레이아웃을 계산한다.
- 새로운 영역 기반 diffusion을 사용하여 각 영역의 속성을 글로벌하게 일관된 이미지로 렌더링한다.
Step 1. Token maps for spatial layout
몇몇 연구들에서는 diffusion UNet의 self-attention 및 cross-attention 레이어에 있는 attention map이 해당 생성의 공간 레이아웃을 특징짓는다는 사실을 발견했다. 따라서 먼저 일반 텍스트를 diffusion model의 입력으로 사용하고 다양한 head, 레이어, timestep에 걸쳐 $32 \times 32 \times 32 \times 32$ 크기의 self-attention map을 수집한다. 추출된 모든 맵에서 평균을 구하고 결과를 $1024 \times 1024$로 재구성한다. 맵의 $i$번째 행과 $j$번째 열의 값은 픽셀 $i$가 픽셀 $j$에 attend할 확률을 나타낸다. 대칭 행렬로 변환하기 위해 전치 행렬과 평균을 계산한다. 이는 spectral clustering을 수행하고 $K \times 32 \times 32$ 크기의 바이너리 segmentation map $\hat{M}$을 얻기 위한 유사도 맵으로 사용된다. 여기서 $K$는 세그먼트 수이다.
각 세그먼트를 텍스트 span과 연결하기 위해 각 토큰 $w_j$에 대한 cross-attention map도 추출한다.
\[\begin{equation} m_j = \frac{\exp (s_j)}{\sum_k \exp (s_k)} \end{equation}\]여기서 $s_j$는 attention score이다. 먼저 각 cross-attention map $m_j$를 $\hat{M}$과 동일한 해상도인 $32 \times 32$로 보간한다. Self-attention map의 처리 단계와 유사하게 head, 레이어, timestep에 걸쳐 평균을 계산하여 평균 맵 \(\hat{m}_j\)를 얻는다. Localizing Object-level Shape Variations with Text-to-Image Diffusion Models 논문을 따라 각 세그먼트를 텍스처 span $e_i$와 연관시킨다.
\[\begin{equation} \mathbb{M}_{e_i} = \{ \hat{M_k} \vert \bigg\vert \hat{M_k} \cdot \frac{\hat{m}_j - \min (\hat{m}_j)}{\max (\hat{m}_j) - \min (\hat{m}_j)} \bigg\vert > \epsilon, \; \forall j \textrm{ s.t. } w_j \in e_i \} \end{equation}\]여기서 $\epsilon$은 레이블링 임계값을 제어하는 hyperparameter이다. 즉, 이 span에 있는 토큰의 정규화된 attention score가 $\epsilon$보다 높으면 세그먼트 \(\hat{M_k}\)가 span $e_i$에 할당된다. 어떠한 span에도 할당되지 않은 세그먼트를 토큰 $e_U$와 연결한다. 마지막으로 아래와 같이 토큰 맵을 얻는다.
\[\begin{equation} M_{e_i} = \frac{\sum_{\hat{M_j} \in \mathbb{M}_{e_i}} \hat{M_j}}{\sum_i \sum_{\hat{M_j} \in \mathbb{M}_{e_i}} \hat{M_j}} \end{equation}\]Step 2. Region-based denoising and guidance
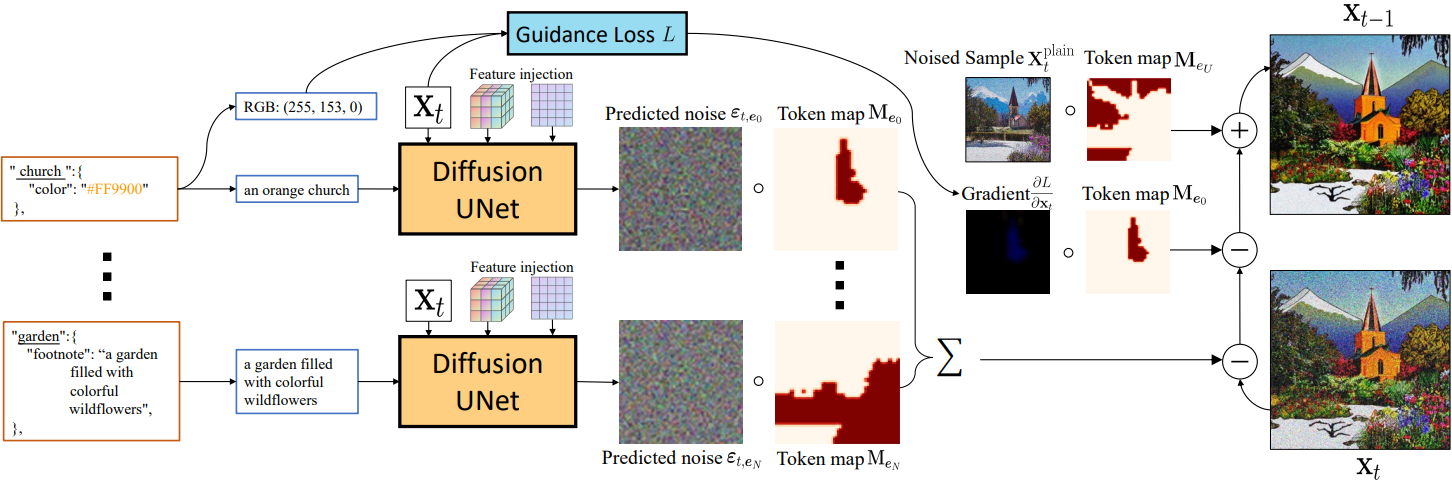
텍스트 속성과 토큰 맵이 주어지면 전체 이미지 합성을 여러 영역 기반 denoising 및 guidance 프로세스로 나누어 diffusion model의 앙상블과 유사하게 각 속성을 통합한다. 보다 구체적으로, span $e_i$, 토큰 맵 \(M_{e_i}\)에 의해 정의된 영역과 속성 $a_i$가 주어지면 timestep $t$에서 noisy한 생성 $x_t$에 대해 예측된 noise $\epsilon_t$는 다음과 같다.
여기서 $D$는 사전 학습된 diffusion model이고 $f(e_i, a_i)$는 다음 프로세스를 사용하여 텍스트 span $e_i$와 속성 $a_i$에서 파생된 일반 텍스트 표현이다.
- 처음에는 $f(e_i, a_i) = e_i$로 설정한다.
- 각주 $a_i^f$를 사용할 수 있는 경우 $f(e_i, a_i) = a_i^f$로 설정한다.
- 스타일 $a_i^s$가 존재하는 경우 추가된다. $f(e_i, a_i)$ = $f(e_i, a_i)$ + ‘in the style of’ + $a_i^s$
- 미리 정의된 집합 $\mathcal{C}$에서 폰트 색상에 가장 가까운 색상 이름(문자열) \(\hat{a}_i^c\)이 앞에 붙는다. \(f(e_i, a_i) = \hat{a}_i^c + f(e_i, a_i)\)
형식화되지 않은 토큰 $e_U$의 경우 1단계의 일반 텍스트 프롬프트 $f(e_i, a_i)$를 사용한다. 이는 특히 영역 경계 주변에서 일관된 이미지를 생성하는 데 도움이 된다.
Guidance
기본적으로 프롬프트 $f(e_i, a_i)$와 더 잘 일치하도록 각 영역에 대해 classifier-free guidance를 사용한다. 또한 폰트 색상이 지정된 경우 RGB 값 정보를 추가로 활용하기 위해 다음과 같은 이미지 예측에 기울기 guidance를 적용한다.
\[\begin{equation} \hat{x}_0 = \frac{x_t - \sqrt{1 - \bar{\alpha}_t} \epsilon_t}{\sqrt{\vphantom{1} \bar{\alpha}_t}} \end{equation}\]여기서 $x_t$는 timestep $t$에서의 noisy한 이미지이고, \(\bar{\alpha}_t\)는 noise scheduling 전략에 의해 정의된 계수이다. 여기서는 토큰 맵 \(M_{e_i}\)에 의해 가중치가 부여된 $\hat{x}$의 평균 색상과 RGB triplet $a_i^c$ 사이의 MSE loss $\mathcal{L}$을 다음과 같이 계산한다.
\[\begin{equation} \frac{d \mathcal{L}}{d x_t} = \frac{d \| \sum_p (M_{e_i} \cdot \hat{x}_0) / \sum_p M_{e_i} - a_i^c \|_2^2}{\sqrt{\vphantom{1} \bar{\alpha}_t} d \hat{x}_0} \end{equation}\]여기서 합계는 모든 픽셀 $p$에 대한 것이다. 그런 다음, 다음 방정식으로 $x_t$를 업데이트한다.
\[\begin{equation} x_t \leftarrow x_t - \lambda \cdot M_{e_i} \cdot \frac{d \mathcal{L}}{d x_t} \end{equation}\]여기서 $\lambda$는 guidance 강도를 제어하는 hyperparameter이다. $\lambda = 1$을 사용한다.
Token reweighting with font size
마지막으로 폰트 크기 $a_j^w$에 따라 토큰 $w_j$의 영향을 다시 평가하기 위해 cross-attention map $m_j$를 수정한다. 그러나 $\sum_j a_j^w m_j \ne 1$인 Prompt-to-Prompt에서와 같이 직접 곱셈을 적용하는 대신 $m_j$의 확률 속성을 유지하는 것이 중요하다. 따라서 저자들은 다음과 같은 재가중 방법을 제안하였다.
\[\begin{equation} \hat{m}_j = \frac{a_j^w \exp (s_j)}{\sum_k a_k^w \exp (s_k)} \end{equation}\]재가중화된 attention map을 사용하여 토큰 맵을 계산하고 noise를 예측할 수 있다.
Preserve the fidelity against plain-text generation
영역 기반 방법은 자연스럽게 레이아웃을 유지하지만 서식 있는 텍스트 속성이 지정되지 않거나 색상만 지정되면 개체의 디테일과 모양이 유지된다는 보장이 없다. 이를 위해 Plug-and-Play를 따라 \(t > T_\textrm{pnp}\)일 때 일반 텍스트 생성 프로세스에서 추출된 self-attention map과 residual feature를 주입하여 구조 충실도를 향상시킨다. 또한, 형식화되지 않은 토큰 $e_U$와 연관된 영역의 경우 더 강력한 콘텐츠 보존이 필요하다. 따라서 특정 \(t = T_\textrm{blend}\)에서 일반 텍스트를 기반으로 noisy한 샘플 \(x_t^\textrm{plain}\)을 해당 영역에 혼합한다.
\[\begin{equation} x_t \leftarrow M_{e_U} \cdot x_t^\textrm{plain} + (1 - M_{e_U}) \cdot x_t \end{equation}\]Experiments
- 구현 디테일
- Stable Diffusion V1-5을 사용
- 고해상도 레이어의 레이어는 잡음이 많으므로 첫 번째 인코더 블록과 마지막 디코더 블록을 제외한 모든 블록의 cross-attention 레이어를 사용하여 토큰 맵을 생성
- $T > 750$인 초기 denoising step에서 맵을 제거
- $K = 15$, $\epsilon = 0.3$, \(T_\textrm{pnp} = 0.3\), \(T_\textrm{blend} = 0.3\)
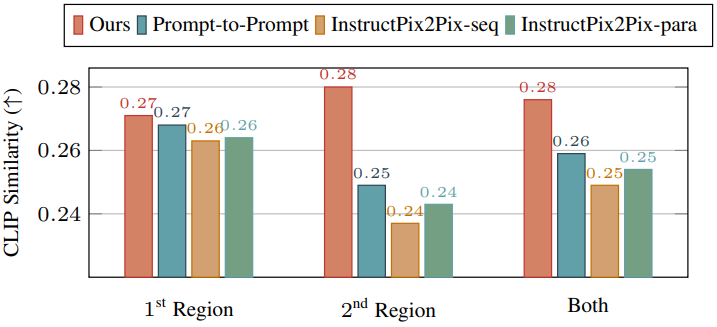
1. Quantitative Comparison
다음은 각 스타일화된 영역과 영역 프롬프트 사이의 CLIP 유사도를 비교한 그래프이다. (높을수록 좋음)
다음은 대상 색상과의 거리를 비교한 그래프이다. (낮을수록 좋음)

2. Visual Comparison
Precise color generation
다음은 정교한 색상 생성에 대한 결과를 비교한 것이다.

Local style generation
다음은 스타일 제어에 대한 결과를 비교한 것이다.

Complex scene generation
다음은 디테일한 설명을 기반으로 한 생성을 비교한 것이다.

Token importance control
다음은 토큰 재가중에 대한 결과를 비교한 것이다.

Interactive editing
다음은 InstructPix2Pix에 대한 인터랙티브한 강점과 편집 능력을 보여주는 샘플 워크플로우다.

3. Ablation Study
다음은 토큰 맵에 대한 ablation 결과이다.
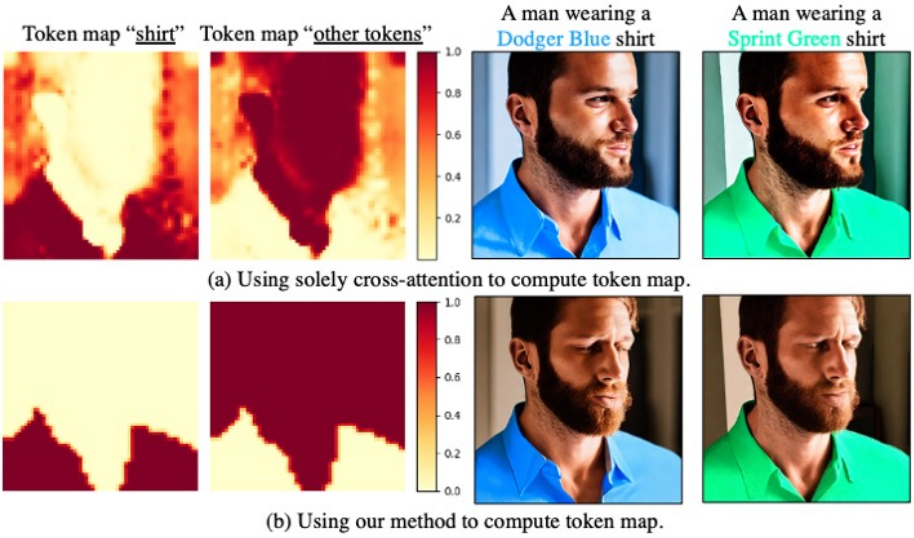
다음은 주입 방법에 대한 ablation 결과이다.

Limitations
- 여러 diffusion process와 2단계 방법을 사용하기 때문에 원래 프로세스보다 몇 배 더 느릴 수 있다.
- 토큰 맵을 생성하는 방법은 임계값 파라미터에 의존한다.