[논문리뷰] RGB↔X: Image Decomposition and Synthesis Using Material- and Lighting-aware Diffusion Models
SIGGRAPH 2024. [Paper] [Page] [Github]
Zheng Zeng, Valentin Deschaintre, Iliyan Georgiev, Yannick Hold-Geoffroy, Yiwei Hu, Fujun Luan, Ling-Qi Yan, Milos Hasan
Adobe Research | University of California
1 May 2024
Introduction
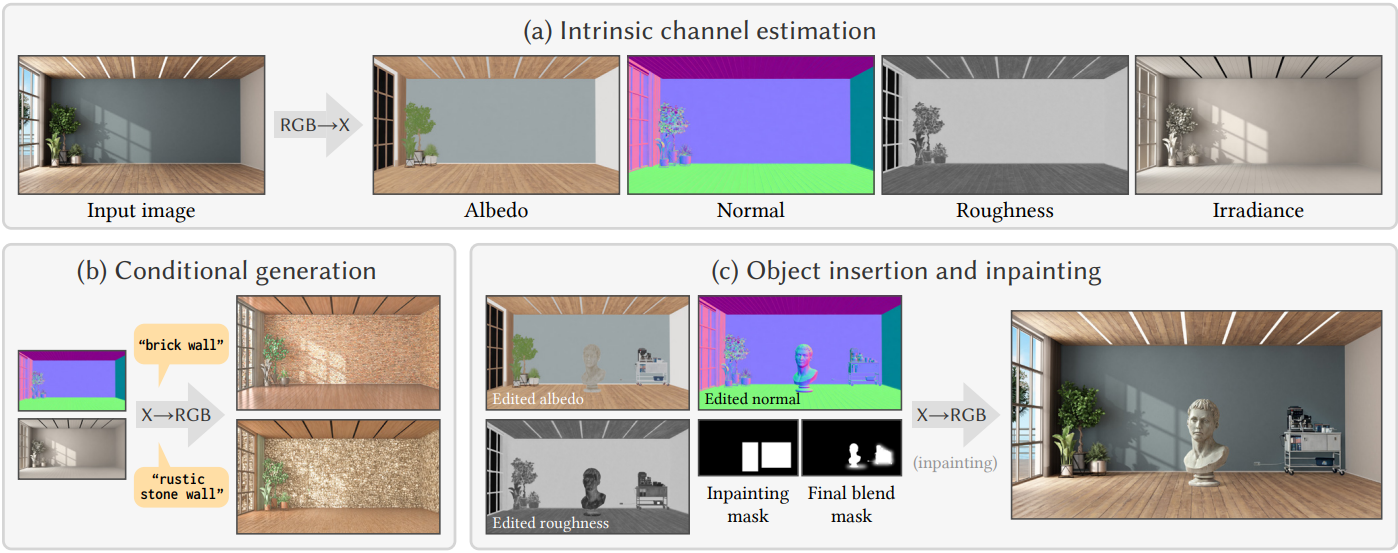
이미지에서 기하학적 정보, 명암 정보, 조명 정보를 추정하는 것은 오랫동안 연구되어 왔으며, 조명(illumination)과 재질(material) 간의 모호성을 포함하여 제약 조건이 부족하여 본질적으로 어렵다. 최근 연구들은 per-pixel inverse rendering 문제에 집중했다. 이를 통해 물리적 재질 및 조명 추정, 특히 diffuse albedo, specular roughness, metallicity, 그리고 공간적으로 다양한 조명 표현이 가능해졌다. 이러한 모든 정보 버퍼를 intrinsic channel이라고 하며, 기호 $\textrm{X}$를 사용하여 나타내고, 이를 추정하는 문제는 RGB→X로 나타낸다.
반면, 물리 기반 렌더링 분야는 오랫동안 geometry, 조명, 재질로 구성된 세부적인 장면 묘사를 사실적인 이미지로 변환하는 역방향 task에 집중해 왔다. 본 논문에서는 이 문제를 X→RGB라고 부른다.
기존 렌더링과는 매우 다른, 매우 사실적인 이미지를 생성하는 최근의 접근법은 이미지 합성을 위한 생성 모델, 특히 대규모 diffusion model에 기반을 두고 있다. Diffusion model은 순수한 noise에서 이미지의 noise를 반복적으로 제거하는 방식으로 작동한다.
이 세 영역은 서로 관련성이 없어 보일 수 있지만, 통합된 방식으로 연구되어야 한다. 본 논문은 diffusion model, 렌더링, intrinsic channel 추정 간의 연관성을 탐구하며, 동일한 diffusion 프레임워크 내에서 재료/조명 추정과 재료/조명에 따른 이미지 합성에 중점을 두었다.
최근 연구에서는 diffusion 아키텍처를 기반으로 intrinsic channel 추정의 개선을 입증했다. Intrinsic channel 추정 문제의 제약 조건이 부족하고 모호한 특성으로 인해 생성 모델링을 사용하는 것이 유망하며, 본 논문에서는 이러한 방향을 더욱 발전시켰다. 본 논문은 개선된 RGB→X에 대한 새로운 모델 외에도, 전체 또는 일부 intrinsic channel에서 사실적인 이미지를 합성하는 최초의 X→RGB diffusion model을 소개하였다. RGB→X와 마찬가지로, X→RGB 문제는 불완전하거나 지나치게 단순한 intrinsic channel 정보 $\textrm{X}$를 사용하더라도 그럴듯한 이미지를 얻기 위한 강력한 prior를 요구한다.
일반적인 생성 모델은 사용하기는 간단하지만 정밀하게 제어하기 어렵다. 반면, 전통적인 렌더링 방법은 정밀하지만 전체 장면에 대한 정보가 필요하여 제약이 있다. 본 논문의 X→RGB 모델은 특정 외형 속성만 지정하고 나머지 속성의 그럴듯한 버전을 모델이 자유롭게 상상할 수 있도록 하는 절충안을 모색하였다.
Intrinsic channel X는 픽셀별 albedo, normal 벡터, roughness, 픽셀별 irradiance로 표현되는 조명 정보를 포함한다. 또한, X→RGB 모델은 채널 dropout 방식을 사용하여 학습되며, 이를 통해 임의의 intrinsic channel 집합을 입력으로 사용하여 이미지를 합성할 수 있다. 이를 통해 사용 가능한 intrinsic channel이 서로 다른 다양한 학습 데이터셋을 혼합하여 사용할 수 있으며, 기존 모델보다 학습 데이터를 확장할 수 있는 주요 장점이다.
Intrinsic Channels and Datasets
1. Intrinsic channels
RGB→X 모델과 X→RGB 모델에서는 다음과 같은 intrinsic channel을 사용한다.
- Normal $\textbf{n} \in \mathbb{R}^{H \times W \times 3}$: 카메라 공간에서 기하학적 정보를 지정.
- Albedo $\textbf{a} \in \mathbb{R}^{H \times W \times 3}$: 이는 불투명한 비금속 표면의 diffuse albedo와 금속 표면의 specular albedo를 지정.
- Roughness $\textbf{r} \in \mathbb{R}^{H \times W}$: 일반적으로 GGX 또는 Beckmann microfacet 분포에서 파라미터 $\alpha$의 제곱근. Roughness가 높으면 무광택 소재가 많고, roughness가 낮으면 광택이 더 남.
- Metallicity $\textbf{m} \in \mathbb{R}^{H \times W}$: 일반적으로 표면을 비금속과 금속으로 처리하는 것 사이를 interpolation하는 선형 혼합 가중치.
- Diffuse irradiance $\textbf{E} \in \mathbb{R}^{H \times W \times 3}$: 조명 표현으로 사용. 표면 지점에 도달하는 빛의 양을 코사인 가중치를 적용한 반구에 걸친 적분으로 계산.
픽셀별 깊이는 normal로부터 추정할 수 있고, normal은 일반적으로 고주파 로컬 변화에 대한 더 많은 정보를 포함하고 있기 때문에 깊이 채널은 불필요하다.
전통적인 렌더링 프레임워크와는 달리, 위의 속성들은 상당히 부정확하다. 예를 들어, 유리를 표현할 수 없다. 대신, 유리는 roughness와 metallicity가 0인 것으로 처리한다. 이는 일반적으로 문제가 되지 않는다. 모델은 컨텍스트를 통해 물체가 창문이나 유리 캐비닛이라고 추론하고, 유리 뒤의 물체나 조명을 그럴듯하게 칠한다.
데이터셋의 모든 intrinsic channel은 해당 RGB 이미지와 동일한 해상도를 가지며, RGB→X로 전체 해상도를 추정한다. 그러나 다운샘플링된 채널에 X→RGB를 적용하는 것이 유용한 경우도 있다.
2. Datasets

모델을 학습시키기 위해서는 이상적으로 필요한 모든 채널에 대한 쌍 정보를 포함하는 대용량 고품질 이미지 데이터셋이 필요하다. 이 데이터셋에는 normal $\textbf{n}$, albedo $\textbf{a}$, roughness $\textbf{r}$, metallicity $\textbf{m}$, diffuse irradiance $\textbf{E}$, RGB 이미지 $\textbf{I}$, 그리고 이미지를 설명하는 텍스트 캡션이 포함된다. 그러나 기존 데이터셋은 이러한 요건을 충족하지 못하기 때문에, 저자들은 부분적인 정보만 있는 데이터셋을 조합하고 새로운 데이터셋을 구축하여 부족한 부분을 메웠다. 위 표는 본 논문에서 사용한 데이터셋의 크기와 채널 가용성을 요약한 것이다.
InteriorVerse는 렌더링된 이미지 $\textbf{I}$ 외에도 $\textbf{n}$, $\textbf{a}$, $\textbf{r}$, $\textbf{m}$ 채널이 있는 5만 개 이상의 렌더링된 이미지를 포함하는 합성 실내 장면 데이터셋이다. 이 데이터셋에는 몇 가지 문제가 있다.
- 렌더링된 이미지에 노이즈가 포함되어 있다. 이는 RGB→X 추정에는 문제가 되지 않지만 X→RGB 모델은 이 노이즈를 재현하는 방법을 학습한다. 저자들은 NVIDIA OptiX denoiser를 적용하여 이 문제를 해결하였다.
- Roughness와 metallicity 값이 종종 모호하기 때문에 모델 학습에 사용하지 않는다.
- 데이터셋에 합성 스타일도 있는데, X→RGB 모델은 이에 대해서만 학습하면 이를 모방하는 방법을 학습한다. 다양한 물체와 재료가 적어 약간의 편향이 발생한다.
Hypersim은 7만 개 이상의 렌더링된 이미지로 구성된 또 다른 합성 데이터셋으로, $\textbf{n}$, $\textbf{a}$, $\textbf{E}$ 데이터를 제공한다. 이 데이터셋은 roughness나 metallicity와 같은 다른 정보는 포함하지 않으며, 때때로 albedo에 specular shading을 적용하기도 한다. 다행히 이러한 방식은 흔하지 않아 albedo 데이터를 사용하지 못할 정도는 아니다. Hypersim은 InteriorVerse보다 장면 표현의 다양성을 넓혔지만, 매우 사실적인 합성을 위해서는 여전히 충분하지 않다.
저자들은 자체 데이터셋 두 개를 사용하였다. 첫 번째는 Evermotion으로, InteriorVerse와 유사하게 합성 장면을 렌더링하고, 미리 녹화된 카메라 경로를 따라 카메라를 무작위로 배치하고, 85개의 실내 장면에 대한 17,000장의 이미지를 렌더링하여 생성된 합성 데이터셋이다. Evermotion의 주요 장점은 roughness와 metallicity를 제공한다는 점이며, 유일하게 roughness와 metallicity를 신뢰할 수 있는 데이터셋이다.
저자들은 학습 데이터를 더욱 강화하고 X→RGB 모델이 사실적인 이미지를 합성할 수 있도록, 5만 장의 고품질 상업용 실내 장면 이미지를 사용하였다. 이 이미지들은 사진이나 고품질 렌더링 이미지이며, 추가 채널은 사용할 수 없다. 따라서 RGB→X 모델을 사용하여 각 intrinsic channel을 추정한다. 이미지와 추정된 intrinsic channel의 조합으로 ImageDecomp 데이터셋을 구성하였다.
X→RGB fine-tuning 과정에서 기본 Stable Diffusion 모델의 기존 텍스트 이해 능력을 더욱 잘 유지하기 위해, 저자들은 BLIP-2 모델을 사용하여 위 모든 데이터셋의 모든 이미지에 대한 이미지 캡션을 미리 계산하였다.
The RGB→X Model
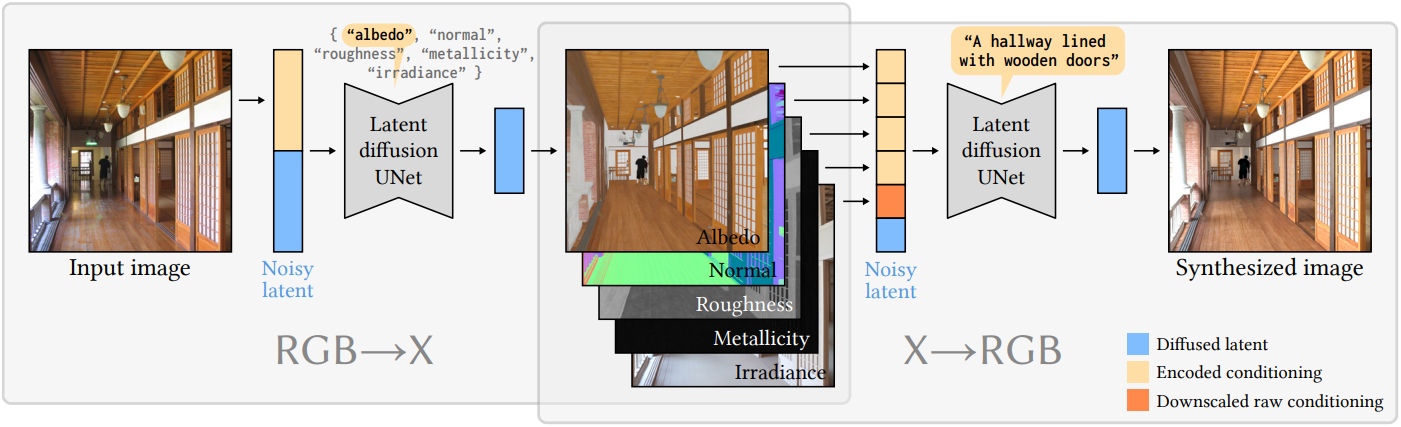
RGB→X 모델을 얻기 위해 Stable Diffusion 2.1을 fine-tuing한다. RGB→X 모델은 사전 학습된 인코더 $\mathcal{E}$와 디코더 $\mathcal{D}$를 갖는 latent space에서 동작한다. Inference 과정에서는 $\mathcal{E}(\textbf{I})$를 입력 조건으로 사용하여 Gaussian noise \(\textbf{z}_T^\textrm{X}\)의 noise를 반복적으로 제거하여 intrinsic channel $\textrm{X}$를 인코딩하는 \(\textbf{z}_0^\textrm{X}\)를 생성한다. 학습 과정에서는 $\epsilon$-예측보다 더 나은 결과를 제공하는 $v$-예측을 사용하여 다음과 같은 loss function \(L_\theta\)를 최적화한다.
($t$는 noise 양 (timestep), $\epsilon \sim \mathcal{N}(0,1)$, \(\hat{\textbf{v}}_\theta^\textrm{RGB→X}\)는 RGB→X diffusion model, \(\textbf{z}_0^\textrm{X}\)는 타겟 latent, \(\textbf{z}_t^\textrm{X}\)는 timestep $t$의 noise $epsilon$을 \(\textbf{z}_0^\textrm{X}\)에 추가한 latent, \(\textbf{p}^\textrm{X}\)는 $\textbf{I}$에 대해 계산된 텍스트 프롬프트, $\tau$는 프롬프트를 텍스트 임베딩 벡터로 인코딩하는 CLIP 텍스트 인코더)
\(\textbf{z}_t^\textrm{X}\)와 \(\mathcal{E}(\textbf{I})\)는 concat되어 RGB→X 모델에 입력된다. CLIP 임베딩은 cross-attention layer를 위한 특수 컨텍스트로 사용된다.
이미지 및 intrinsic 채널 인코딩
본 모델은 latent space에서 동작하므로, 입력 이미지를 $\mathcal{E}(\textbf{I})$로 인코딩하고 이를 noise가 더해진 latent 이미지 \(\textbf{z}_t^\textrm{X}\)에 concat하여 \(\hat{\textbf{v}}_\theta^\textrm{RGB→X}\) 모델의 입력으로 사용한다. 본 논문에서는 Stable Diffusion 모델의 인코더 $\mathcal{E}$를 고정하여 사용하는데, 이 인코더는 모든 intrinsic 이미지 인코딩에 잘 작동한다.
다양한 출력 채널 처리
원래 Stable Diffusion 모델의 출력은 하나의 RGB 이미지로 디코딩할 수 있는 4채널 latent 이미지이다. 추가 출력 채널을 생성하려고 하므로 더 큰 latent 벡터가 정보를 더 잘 인코딩하는 데 도움이 될 것으로 예상할 수 있다. 그러나 원래 모델의 latent 채널 수를 늘리면 결과 품질이 낮아진다. 실제로 diffusion model의 latent space에 더 많은 latent 채널을 추가하면 입력 및 출력 convolutional layer를 모두 처음부터 다시 학습해야 한다. 어떤 면에서는 모델이 갑자기 새로운 도메인으로 충격을 받아 학습이 더 어려워진다.
다양성을 높이기 위해 다양한 데이터셋으로 모델을 학습시켰지만, 이 과정에서 다양한 intrinsic channel이라는 추가적인 문제가 발생하는데, 이는 모든 intrinsic channel을 더 큰 latent 채널로 쌓는 본 논문의 방식에는 어려운 문제이다. 간단한 방법은 각 학습 iteration에서 사용 가능한 맵에 대한 loss만 포함하는 것이지만, 이 방법은 성능이 좋지 않았다.
본 논문의 해결책은 한 번에 하나의 intrinsic channel을 생성하고 입력 텍스트 프롬프트를 diffusion model 출력을 제어하는 ”스위치”로 재활용하는 것이다. 구체적으로, 스위치 역할을 하는 5개의 고정 프롬프트를 사용한다. 한 단위의 데이터는 \(\{\textbf{g}, \textbf{p}^\textrm{X}, \textbf{I}\}\)로 정리된다.
\[\begin{equation} \textbf{g} \in \{\textbf{n}, \textbf{a}, \textbf{r}, \textbf{m}, \textbf{E}\} \\ \textbf{p}^\textrm{X} \in \{\textrm{"normal"}, \textrm{"albedo"}, \textrm{"roughness"}, \textrm{"metallicity"}, \textrm{"irradiance"}\} \end{equation}\]$\textbf{p}^\textrm{X}$는 $\textbf{g}$에 따라 설정된다. 이 접근 방식은 \(\{\textbf{n}, \textbf{a}, \textbf{r}, \textbf{m}, \textbf{E}\}\)에서 각 출력 모달리티에 대해 별도의 모델을 fine-tuning하는 것과 유사하게 수행되는 반면 하나의 네트워크의 가중치만 fine-tuning하고 저장한다.
The X→RGB Model
RGB→X와 마찬가지로, Stable Diffusion 2.1을 fine-tuning하여 X→RGB 모델을 얻는다. 이미지 $\textbf{I}$를 인코딩하여 타겟 latent 변수 \(\textbf{z}_0^\textrm{RGB} = \mathcal{E}(\textbf{I})\)를 얻는다. 인코딩된 입력 intrinsic channel들을 concat하여 입력 조건 $\textrm{X}$를 구성하며, 모든 intrinsic 이미지를 사용할 때 입력 latent 벡터는 다음과 같이 정의된다.
\[\begin{equation} \textbf{z}_t^\textrm{X} = (\mathcal{E}(\textbf{n}), \mathcal{E}(\textbf{a}), \mathcal{E}(\textbf{r}), \mathcal{E}(\textbf{m}), \mathcal{E}(\textbf{E})) \end{equation}\]Loss function \(L_\theta^\prime\)을 최소화하여 X→RGB 모델을 학습시킨다.
\[\begin{equation} \textbf{v}_t^\textrm{X→RGB} = \sqrt{\vphantom{1} \bar{\alpha}_t} \epsilon - \sqrt{1 - \bar{\alpha}_t} \textbf{z}_0^\textrm{RGB} \\ L_\theta = \left\| \textbf{v}_t^\textrm{X→RGB} - \hat{\textbf{v}}_\theta^\textrm{X→RGB} \left( t, \textbf{z}_t^\textrm{RGB}, \textbf{z}_t^\textrm{X}, \tau (\textbf{p}) \right) \right\|_2^2 \end{equation}\]\(\textbf{z}_t^\textrm{RGB}\)와 \(\textbf{z}_t^\textrm{X}\)는 concat되어 X→RGB 모델에 입력된다. CLIP 임베딩은 cross-attention layer를 위한 특수 컨텍스트로 사용된다. 텍스트 임베딩은 diffusion model에서 일반적으로 사용되는 추가 제어로 사용된다.
RGB→X 모델은 여러 모달리티를 출력하기 위한 솔루션이 필요했지만, X→RGB 모델은 추가적인 조건부 latent 채널을 처리하기 위해 입력 레이어만 변경하면 된다. 따라서, Stable Diffusion 모델과 마찬가지로 출력은 하나의 RGB 이미지로 유지된다. 학습 과정에서는 입력 convolutional layer에 새로 추가된 가중치만 추가 조건을 처리하기 위해 처음부터 학습하면 되므로, \(\textbf{z}_t^\textrm{RGB}\)에 대한 모델의 정상적인 noise 제거 능력에 충격을 주지 않는다.
다양한 데이터 처리
그럼에도 불구하고, 서로 다른 데이터셋에서 서로 다른 intrinsic 데이터 채널이 누락되는 문제는 여전히 남아 있다. 이 문제를 해결하기 위해, classifier-free guidance (CFG)를 따라 조건 채널 dropout을 통해 conditional diffusion model과 unconditional diffusion model을 공동으로 학습하여 샘플 품질을 개선하고 모든 조건의 부분집합에 대한 이미지 생성을 가능하게 한다.
따라서 조건부 latent \(\textbf{z}_t^\textrm{X}\)는 다음과 같이 다시 쓸 수 있다.
\[\begin{equation} \mathcal{P}(x) \in \{ \mathcal{E}(x), 0 \} \\ \textbf{z}_t^\textrm{X} = (\mathcal{P}(\textbf{n}), \mathcal{P}(\textbf{a}), \mathcal{P}(\textbf{r}), \mathcal{P}(\textbf{m}), \mathcal{P}(\textbf{E})) \end{equation}\]이러한 접근 방식을 사용하면 학습 중에 다양한 종류의 데이터셋을 처리하고 inference 시 제공할 입력을 선택할 수 있다.
저해상도 조명
RGB→X 모델은 고해상도 geometry와 normal을 면밀히 따르는 diffusion irradiance 이미지 $\textbf{E}$의 형태로 매우 세부적인 조명을 추정하는 데 성공했다. 이는 일부 응용 분야에서는 유용할 수 있지만, X→RGB에 이러한 세부적인 조명 버퍼를 사용하는 것은 세부적인 normal을 실제로 편집하고 $\textbf{E}$의 더 coarse한 해석을 사용하여 조명을 제어하려는 경우 문제가 될 수 있다.
다시 말해, 저자들은 조명을 픽셀 단위의 정확한 제어가 아닌 X→RGB 모델에 대한 힌트로 제공하고자 하였다. 다른 조건처럼 전체 해상도 조명 $\textbf{E}$를 latent space에 인코딩하는 대신, latent space와 동일한 해상도로 간단히 다운샘플링한다. 이를 통해 X→RGB 모델에 픽셀 디테일 없이 더 coarse한 조명 힌트를 제공하면서도 전체 조명 조건을 유지할 수 있다.
인페인팅을 위한 fine-tuning
로컬 편집 애플리케이션을 활성화하기 위해, 마스킹된 이미지와 마스크 채널을 모델 입력에 추가하는 것만으로 X→RGB 모델을 fine-tuning하여 인페인팅을 지원한다. 마스크를 latent space 해상도로 다운샘플링하고 이를 컨디셔닝 latent \(\textbf{z}_t^\textrm{X}\)에 concat한다.
Experiments
1. RGB→X on synthetic and real inputs
다음은 합성 데이터에 대한 RGB→X 결과를 기존 방법과 비교한 예시들이다.

다음은 현실 데이터에 대한 RGB→X 결과를 기존 방법과 비교한 예시들이다.

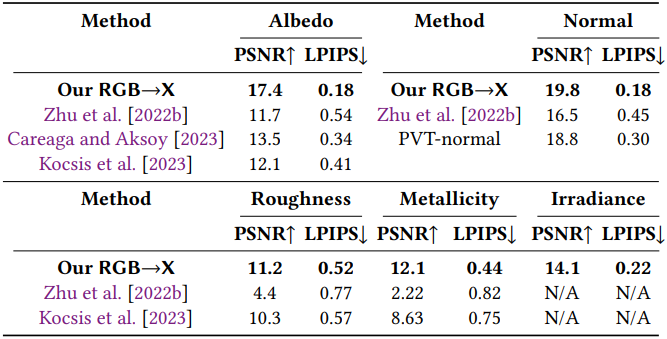
다음은 RGB→X 모델에 대한 기존 방법과의 정량적 평가 결과이다.
2. X→RGB model results
다음은 학습 데이터에 없는 합성 장면에 대한 X→RGB 결과이다.

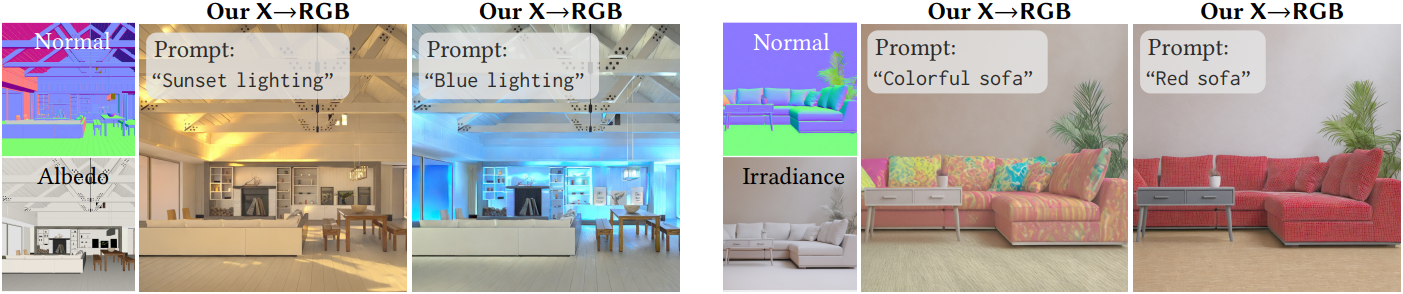
다음은 normal과 albedo만 주어진 X→RGB 합성을 통해 텍스트 프롬프트의 조명 및 색상 제어를 적용한 예시들이다.
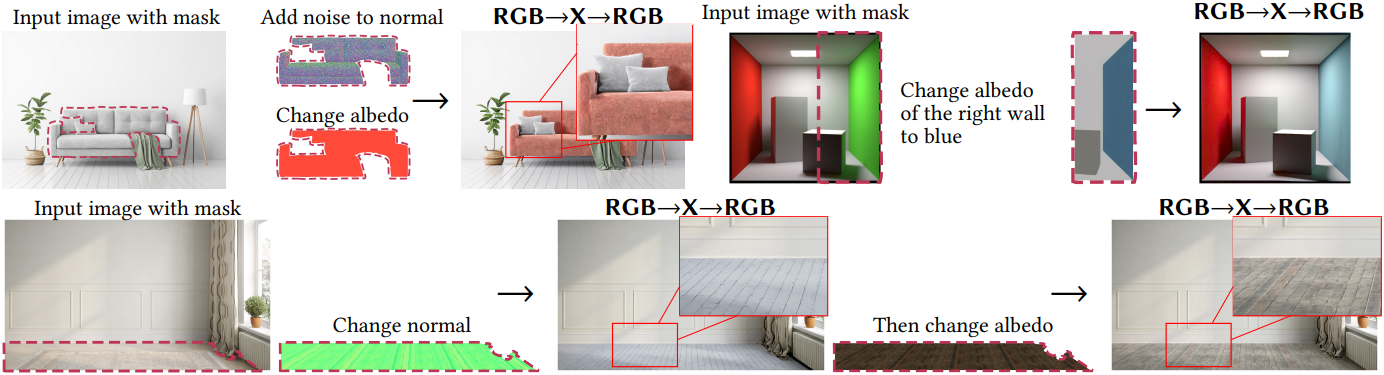
3. Applications
다음은 RGB→X 모델과 X→RGB 모델을 함께 사용하여 재료를 변경하는 예시들이다.