[논문리뷰] Revelio: Interpreting and leveraging semantic information in diffusion models
ICCV 2025. [Paper] [Github]
Dahye Kim, Xavier Thomas, Deepti Ghadiyaram
Boston University | Runway
23 Nov 2024
Introduction
본 논문에서는 diffusion model의 풍부한 표현을 활용하는 데 그치지 않고, diffusion model의 내부 상태를 근본적으로 이해하고 해석하는 것을 목표로 하였다. 구체적으로 다음과 같은 질문들을 다룬다.
- Diffusion model의 다양한 layer와 timestep에서 어떤 시각적 정보가 포착되는가?
- 이러한 정보들은 서로, 그리고 학습된 전체 시각적 정보와 어떻게 상호 작용하고 보완되는가?
- 각 layer는 외부 컨디셔닝에 따라 다른 이점을 얻는가? 그 이유는 무엇인가?
- Transformer 기반 diffusion model과 비교하여 convolution 기반 모델에서 고유하게 포착되는 inductive bias는 무엇인가?
모델이 시각 정보를 어떻게 학습하는지 이해하면 몇 가지 주요 이점을 얻을 수 있다. 첫째, 현재의 생성 모델은 본질적으로 블랙박스이다. 즉, 프롬프트가 때때로 안전하지 않은 출력을 생성하는 이유나 동일한 프롬프트를 아주 조금만 수정해도 매우 다른 출력이 생성되는 이유는 명확하지 않다. 위의 근본적인 질문에 답하는 것은 블랙박스 생성 모델을 해석하는 데 중요한 단계가 될 것이다. 둘째, 다양한 layer, timestep, 모델 아키텍처에 걸쳐 표현된 semantic 정보의 세분성을 정제하면 semantic 및 스타일 제어를 제공하는 더욱 효율적인 알고리즘을 설계하는 데 도움이 될 수 있다.
Diffusion model을 통해 학습된 시각적 지식을 밝히기 위해, 저자들은 mechanistic interpretation 기법을 채택하고 단일 semantic 시각적 개념의 sparse한 사전을 학습시켰다. 구체적으로, 언어 모델 해석에 도움이 되는 것으로 입증된 k-sparse autoencoder (k-SAE)를 활용하여 해석 가능한 feature를 찾아내는 것을 목표로 하였다. 시각적 semantic 정보가 테스트 데이터셋의 표현 세분성, 다양한 diffusion layer, denoising timestep, 모델 아키텍처, 사전 학습 데이터에 따라 어떻게 다르게 패킹되는지 설명한다.
더 나아가, 저자들은 기존 diffusion model의 feature를 기반으로 매우 가벼운 classifier인 Diff-C를 학습시킴으로써 해석을 뒷받침하였다. Diff-C는 추가적인 loss function 사용, student 모델 학습, 또는 feature map 융합 기법의 필요성을 우회하여 상당한 연산 이점을 제공한다.
Method
본 논문의 목표는 블랙박스 diffusion model에 대한 이해를 해석하고 확장하는 것이다. 저자들은 두 가지 관점에서 이 문제를 다뤘다.
- 다양한 layer, timestep, 아키텍처에 걸쳐 해석 가능한 시각적 semantic feature를 복구하도록 k-sparse autoencoder를 학습시킨다.
- 동일한 diffusion feature에 대해 가벼운 classifier인 Diff-C를 학습시켜 각 해석 결과를 입증하였다.
1. Preliminaries on k-sparse autoencoders
본 논문의 목표는 시각적 정보가 diffusion model에 어떻게 캡슐화되는지에 대한 통찰력을 얻는 것이다. Diffusion model의 매우 높은 비선형성과 복잡한 아키텍처를 고려할 때, layer activation에서 직접 해석 가능한 구성 요소를 식별하는 것은 불가능하다. 본 논문에서는 서로 다른 diffusion layer, timestep, 아키텍처의 activation에 대해 k-sparse autoencoder (k-SAE)를 학습시켜 monosemantic feature를 분리하였다.
Sparse autoencoder (SAE)는 unsupervised learning 방식으로 컴팩트한 feature 표현을 학습하는 신경망이다. 인코더와 디코더를 포함하며, sparsity 페널티와 샘플 reconstruction loss를 사용하여 주어진 입력에 대해 소수의 뉴런만 최대로 activation되도록 학습된다. 그러나 SAE의 sparsity 페널티 항은 학습의 어려움을 야기한다. k-SAE는 SAE를 확장한 것으로, 학습 중 활성 뉴런의 수를 $k$개로 명시적으로 조절하여 학습의 어려움을 개선하도록 설계되었다. 특히, 각 학습 step에서 top-$k$ activation function을 사용하여 activation 값이 가장 큰 $k$개의 뉴런만 유지하고 나머지는 0으로 초기화한다.
$x$를 $d$차원 공간으로 pooling된 diffusion activation으로, \(W_\textrm{enc} \in \mathbb{R}^{n \times d}\)와 \(W_\textrm{dec} \in \mathbb{R}^{d \times n}\)을 각각 k-SAE의 인코더와 디코더의 가중치 행렬이라 하자. $n$은 $d$에 expansion factor를 곱한 값이다. 인코더에 입력하기 전에 입력 $x$에 더해지는 bias 항인 pre-encoder bias를 $b_\textrm{pre} \in \mathbb{R}^d$라 하고, 인코더의 bias 항을 \(b_\textrm{enc} \in \mathbb{R}^n\)이라 하자. $x$를 인코더에 통과시키면 다음과 같이 정의되는 $z$를 얻는다.
\[\begin{equation} z = \textrm{TopK} (W_\textrm{enc} (x - b_\textrm{pre}) + b_\textrm{enc}) \end{equation}\]여기서 TopK activation function은 상위 $k$개 뉴런의 activation 값만 유지하고 나머지는 0으로 설정한다. 그런 다음, 디코더는 다음과 같이 $z$를 재구성한다.
\[\begin{equation} \hat{x} = W_\textrm{dec} z + b_\textrm{pre} \end{equation}\]학습 loss는 재구성된 feature $\hat{x}$와 원래 feature $x$ 사이의 MSE이다.
\[\begin{equation} L_\textrm{mse} = \| x - \hat{x} \|_2^2 \end{equation}\]2. Diffusion Classifier (Diff-C)
저자들은 사전 학습된 diffusion model에 포함된 시각적 semantic 정보를 정량적으로 연구하기 위해, diffusion feature를 다운스트림 task에 적용하는 Diff-C라는 classifier를 설계하였다. Diff-C는 diffusion feature의 공간적 차원을 점진적으로 줄이는 일련의 convolution layer와 그 뒤에 pooling layer, 그리고 다운스트림 task에 따라 다른 fully-connected layer로 구성된다. Convolution 기반 U-Net과 diffusion 기반 DiT는 본질적으로 고유한 아키텍처를 가지고 있지만, 본 논문에서는 다양한 U-Net layer와 DiT block의 출력을 2D feature map으로 변환하고 Diff-C를 사용하여 처리하였다.
Experiments
- 기본 세팅: Stable Diffusion 1.5 + DDIM scheduler + 빈 프롬프트
- 구현 디테일
- k-SAE: $k = 32$, $d = 1280$
- Diff-C
- 4 convolution layer
- 최종 feature 차원: 1024
- optimizer: AdamW (learning rate = $10^{-4}$)
- epoch: 30
- 입력 이미지 해상도: 512$\times$512
- GPU: NVIDIA RTX A6000 1개
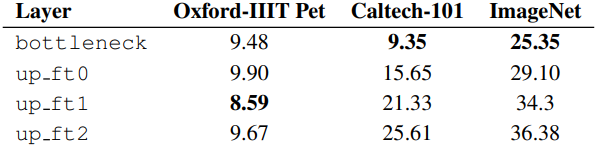
1. Information granularity across diffusion layers
저자들은 활성화된 뉴런의 순수한 정도를 측정하기 위해, 가장 activation 값이 큰 10개의 이미지에 대하여 클래스 레이블의 평균 표준편차 \(\sigma_\textrm{label}\)을 측정하였다.
다음은 layer에 따른 \(\sigma_\textrm{label}\)을 여러 데이터셋에 대하여 비교한 결과이다.
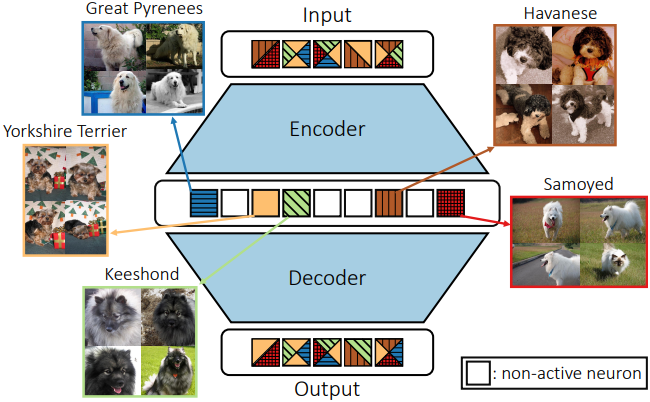
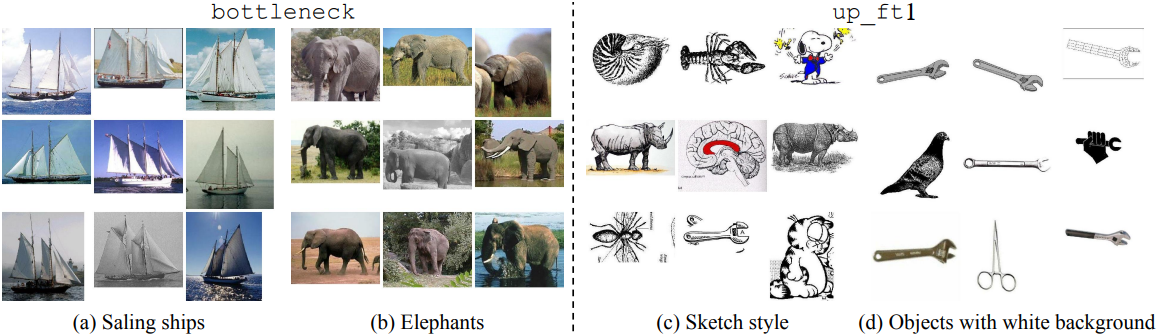
다음은 Oxford-IIIT Pet 데이터셋에 대하여 k-SAE를 시각화한 것이다. bottleneck은 배경에 대해 유사하게 배치된 매우 coarse한 물체 패턴을 분리한다. up_ft1의 경우, 명확한 클래스별 feature가 관찰되어 품종을 분리하는 데 도움이 된다. up_ft2는 잔디와 같은 더욱 포괄적인 텍스처 정보를 포착한다.

다음은 각 layer별로 activation 값이 큰 상위 10개에 이미지에 대한 GPT-4o의 예측 결과이다.

다음은 Caltech-101 데이터셋에 대하여 k-SAE를 시각화한 것이다. Oxford-IIIT Pet과는 다르게, bottleneck은 클래스 정보를 포착하고, up_ft1은 더 추상적인 정보를 포착한다.
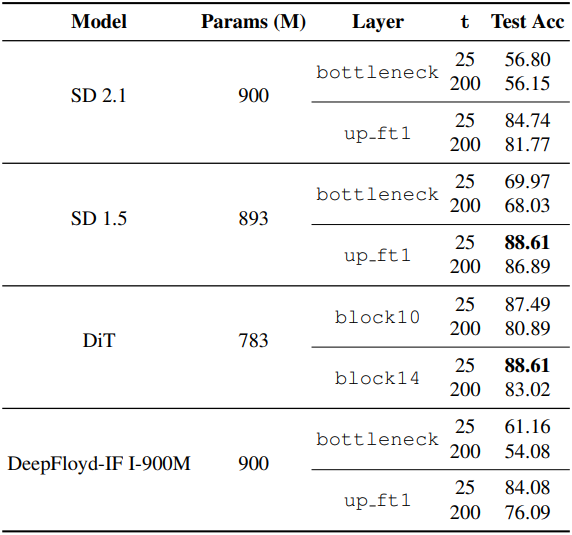
다음은 layer에 따른 Diff-C의 classification 정확도를 비교한 결과이다.
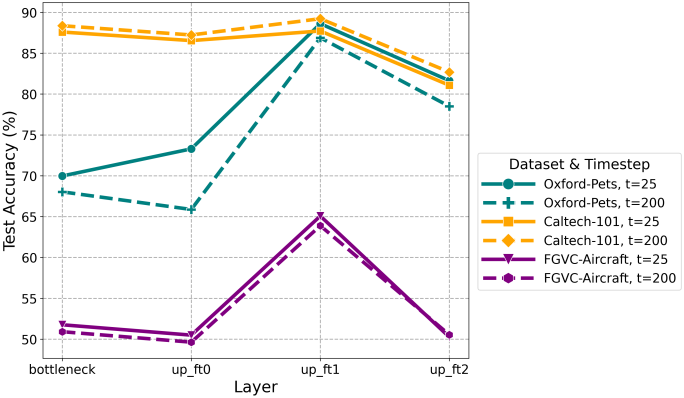
2. Information packed across diffusion timesteps
다음은 timestep에 따른 \(\sigma_\textrm{label}\)을 여러 데이터셋에 대하여 비교한 결과이다.
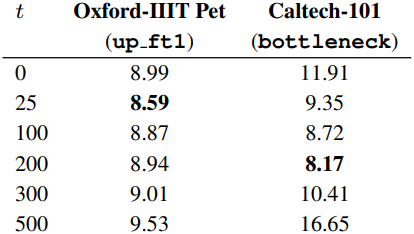
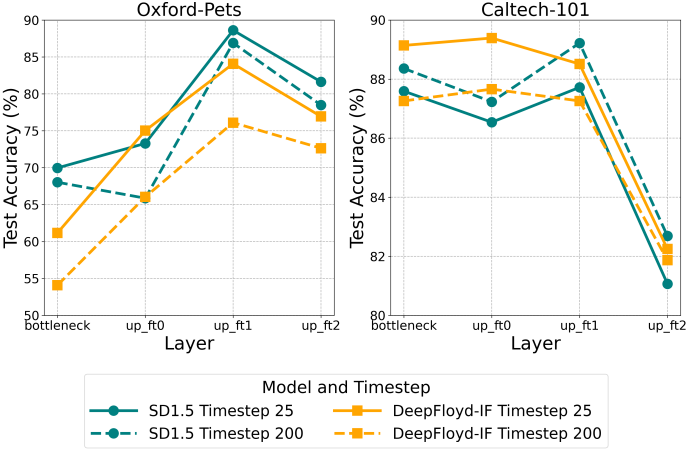
다음은 timestep에 따른 Diff-C의 classification 정확도를 비교한 결과이다 (layer는 up_ft1). Fine-grained 데이터셋인 Oxford-IIIT Pet, FGVC-Aircraft의 경우 초기 timestep의 정확도가 높았고, coarse-grained 데이터셋인 Caltech-101의 경우 중간 timestep의 정확도가 높았다.
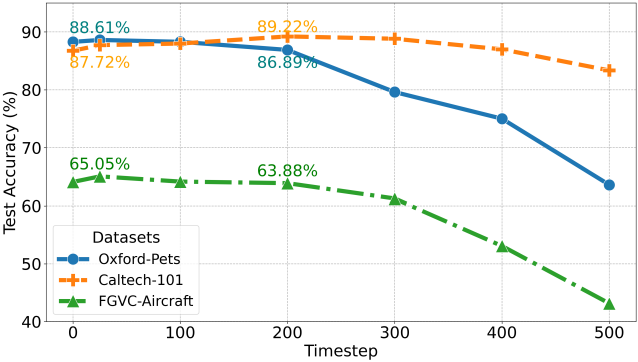
3. Effect of different models and architectures
다음은 Stable Diffusion 버전에 따른 \(\sigma_\textrm{label}\)을 Oxford-IIIT Pet에서 비교한 결과이다. SD 1.5의 feature가 SD 2.1보다 물체 중심의 정보를 더 잘 포착하는 것을 알 수 있다.
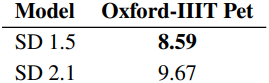
다음은 SD 2.1의 up_ft1에 대한 k-SAE 시각화 결과이다.

다음은 diffusion 아키텍처에 따른 Diff-C 정확도를 비교한 결과이다.
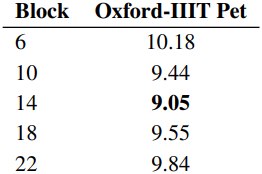
다음은 DiT block에 따른 \(\sigma_\textrm{label}\)을 Oxford-IIIT Pet에서 비교한 결과이다.
다음은 DiT block에 대한 k-SAE 시각화 결과이다. (Oxford-IIIT Pet)

다음은 SD 1.5와 DiT의 top-3 PCA component를 비교한 예시이다. SD 1.5의 feature는 다양한 세분성으로 공간적인 정보를 포착한다.

4. Performance on visual reasoning
다음은 멀티모달 추론 task에 대한 성능을 비교한 결과이다.

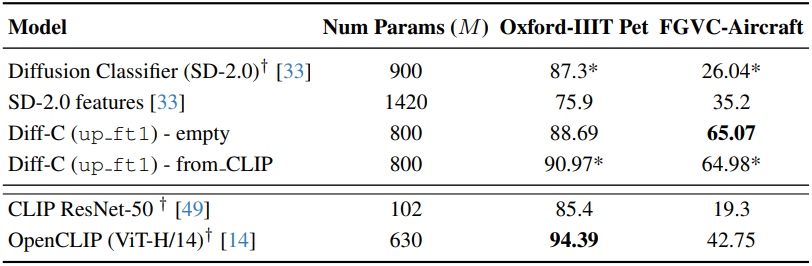
5. State-of-the-art performance
다음은 top-1 classification 정확도를 비교한 결과이다.