[논문리뷰] ReStyle: A Residual-Based StyleGAN Encoder via Iterative Refinement
ICCV 2021. [Paper] [Project] [Github]
Yuval Alaluf, Or Patashnik, Daniel Cohen-Or
Blavatnik School of Computer Science, Tel Aviv University
6 Apr 2021
Introduction
StyleGAN은 효과적으로 semantic 정보를 latent space에 인코딩한다. Latent space $\mathcal{W}$는 disentangle하기 때문에 잘 학습된 StyleGAN generator로 광범위한 이미지 조작이 가능하다. 이미지 조작을 위해서는 일반적으로 실제 이미지를 latent space로 invert하여 latent code $w$를 얻고 $w$를 pre-trained StyleGAN을 통과시켜 이미지를 얻는다. 이를 위해 실제 이미지를 $\mathcal{W}$가 확장된 $\mathcal{W}+$로 invert시키는 것이 일반적인 관행이 되었다.
이전 연구에서는 latent code 매핑을 위해 인코더를 학습하였다. 이러한 방법은 개별 이미지에 대한 latent code를 최적화하여 찾는 것보다 빠르고 이미지 편집에 더 적합한 latent space로 수렴한다. 그러나 reconstruction 정확도 측면에서는 학습 기반의 inversion이 최적화 기반의 방법보다 낮은 성능을 보여준다. 따라서 학습 기반의 inversion에서도 개별 이미지 최적화에 의존하는 과제가 남아 있다.
저자들은 single shot에서 정확한 inversion을 얻는 것이 어렵기 때문에 실제 이미지를 $\mathcal{W}+$ StyleGAN latent space로 인코딩하는 새로운 인코더를 도입하였다. 또한, 일반적인 인코더 기반 방법들이 single forward pass를 사용하는 것과 달리 iterative feedback mechanism을 사용한다. 즉, 원본 입력 이미지와 함께 이전의 출력 이미지를 인코더에 입력으로 주어 inversion이 수행된다. 이를 통해 인코더는 이전 iteration에서 학습한 지식을 사용하여 입력 이미지를 정확히 reconstruct하는 데 필요한 영역에 집중할 수 있다. Latent space 측면에서 보면 이러한 residual encoder는 각 단계에서 현재 latent code와 새로운 latent code 사이의 잔차를 예측하도록 학습되며, 이를 통해 인코더가 inversion을 점진적으로 수렴할 수 있다. 또한 inversion은 최적화 과정 없이 인코더만을 사용한다.
저자들은 이 inversion 방법을 ReStyle이라 이름 붙였다. ReStyle은 pre-trained generator의 latent space 내에서 잔차 기반 형식으로 적은 수의 step(ex. 10)을 수행하는 방법을 학습하는 것으로 볼 수 있다. 또한 Restyle은 StyleGAN inversion을 위한 다양한 인코더 구조와 손실 함수에 적용할 수 있다.
저자들은 광범위한 실험을 진행하여 ReStyle이 기존의 feed-forward 인코더에 비해 reconstruction 품질이 크게 개선되었음을 보였다. 이는 infernce time의 큰 증가 없이 가능하며 시간이 오래 걸리는 최적화 기반 inversion보다 훨씬 빠르다. 또한 각 iterative 피드백 단계에서 어떤 이미지 영역이 수정되는 지 확인하였으며, coarse한 영역이 먼저 수정되고 fine한 영역이 나중에 수정되는 것을 확인하였다.
Method
$E$를 인코더, $G$를 StyleGAN generator라고 하면 주어진 이미지 $x$와 생성된 이미지 $\hat{Y} = G(E(x))$가 거의 같도록 학습하는 것이 기존의 인코더 기반 inversion 방법이다. 이 때 $\hat{y}$는 single forward pass로 $E$와 $G$를 통과한다. $E$를 학습할 때는 pixel-wise L2 loss와 feature를 추출하여 비교하는 perceptual loss를 사용하며 $G$는 고정된다.
ReStyle의 경우, inversion $w = E(x)$를 $N>1$ step에 걸쳐 예측한다. 여기서 하나의 step는 하나의 single forward pass로 정의된다. 즉, $N=1$이면 기존의 inverrsion 방법과 동일하다. 인코더 $E$를 학습하기 위해서 하나의 이미지 배치에 대한 $N$ step을 하나의 학습 interation으로 정의한다. 기존의 인코딩 방법과 동일한 loss가 학습에 사용되며 pre-trained generator $G$는 고정된다. Loss는 각 step마다 계산되며 매번 역전파를 수행한다. 즉, 각 배치다마 $N$번의 역전파가 수행된다.
Inference를 할 때는 loss 계산만 하지 않고 동일한 multi-step 과정이 수행된다. 각 배치에 대해서 작은 수($N<10$)의 step이 수렴에 필요하다고 한다.
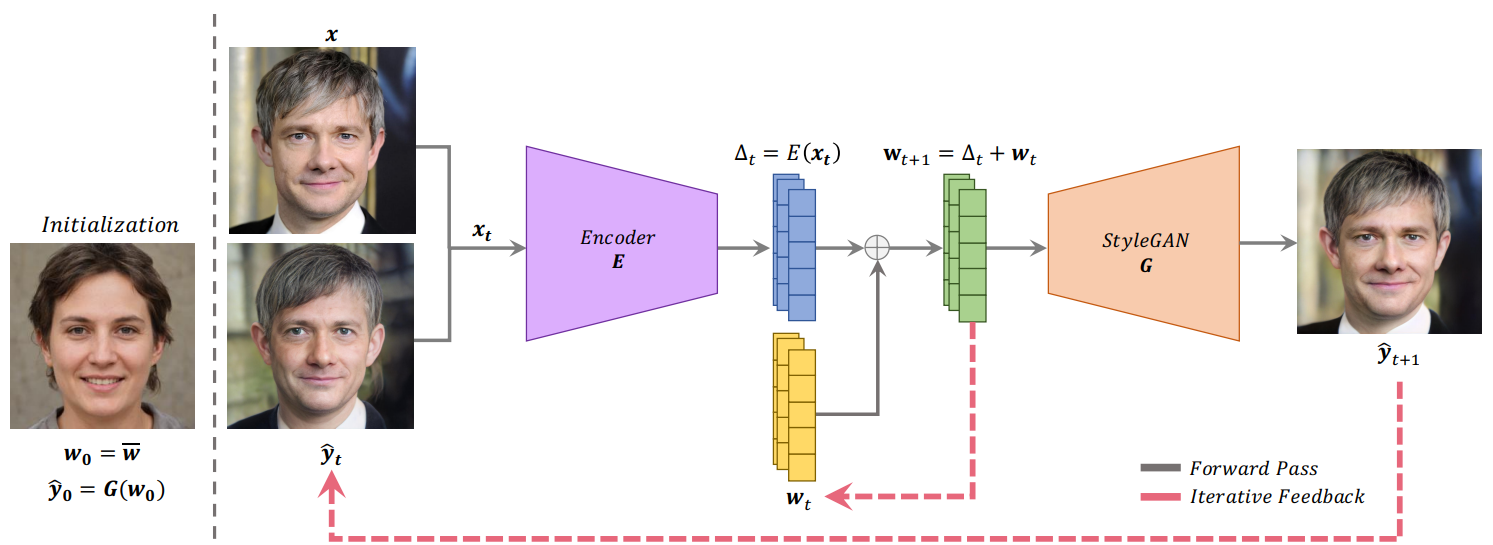
ReStyle의 inversion 과정은 위 그림과 같다. 각 step $t$에서 ReStyle은 입력 이미지 $x$와 현재 reconstruction의 예측값인 $\hat{y}_t$를 concat하여 입력으로 받는다.
$x_t$는 채널이 6개이며 인코더 $E$는 $x_t$를 입력받아 residual code $\Delta_t$를 계산한다. latent code에 대한 새로운 code를 기존의 code에 residual code를 더하여 계산한다.
\[\begin{equation} \Delta_t := E(x_t) \\ w_{t+1} \leftarrow \Delta_t + w_t \end{equation}\]새로운 latent code $w_{t+1}$는 generator $G$를 통과하여 새로운 reconstruction의 예측값을 만든다.
\[\begin{equation} \hat{y}_{t+1} := G(w_{t+1}) \end{equation}\]업데이트된 예측값 $\hat{y}_{t+1}$은 다시 입력 이미지 $x$와 concat되며 이 과정이 반복된다. 이 과정은 generator의 평균 style vector $w_0$와 generator로 합성한 대응되는 이미지 $\hat{y}_0$로 시작한다.
단일 step으로 주어진 이미지를 invert하도록 인코더를 제한하면 학습에 엄격한 제약이 부과된다. 반면, ReStyle은 어떤 의미에서 이 제약을 완화하는 것으로 볼 수 있다. 위 식에서 인코더는 $w_0$를 이전 step의 output으로 guide하여 latent space에서 여러 step을 가장 잘 수행하는 방법을 학습한다. 이런 완화된 제약 조건에 의해 인코더는 자체 수정 방식으로 원하는 latent code로의 inversion의 범위를 좁힐 수 있다. 이는 최적화 방식과 비슷한 데, 최적화 방식과의 큰 차이점은 inversion을 효율적으로 수행하기 위해 인코더에서 step을 학습한다는 것이다.
Encoder Architecture
저자들은 ReStyle의 방식이 기존의 다양한 인코더 구조에 적용할 수 있다는 것을 보여주기 위해 state-of-the-art 인코더인 pSp와 e4e를 사용하였다. 이 두 인코더는 ResNet backbone에 Feature Pyramid Network를 사용하고 있으며 style feature를 세 개의 중간 레벨에서 추출한다. 이러한 계층적 인코더는 style input을 세 가지 레벨로 나눌 수 있는 얼굴 domain과 같은 잘 구조화된 domain에 적합하다. 이를 통해 이러한 디자인이 덜 구조화된 multimodal domain에 미치는 영향이 무시할 수 있지만 overhead가 증가한다는 것을 발견했다. 또한, ReStyle이 복잡한 인코더 구조의 필요성을 완화한다는 사실을 발견했다.
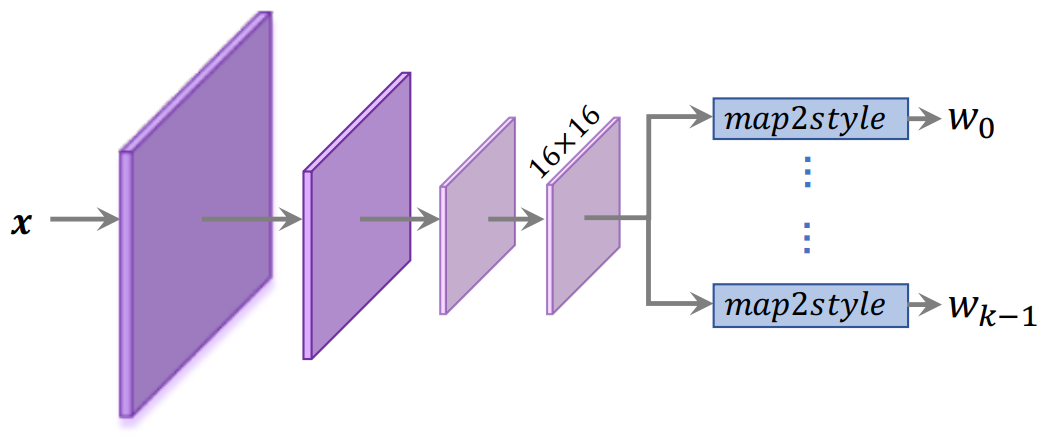
따라서 저자들은 pSp와 e4e의 더 단순한 변형 버전을 설계하였다. 인코더를 따라 세 개의 중간 레벨에서 style을 추출하는 대신 마지막 16x16 feature map에서만 style vector를 추출된다. $k$개의 style input이 있는 StyleGAN generator가 주어진다면, pSp에 사용된 map2style 블록을 $k$개 사용하여 feature map을 down-sampling하여 대응하는 512차원 style input을 얻었다.
Experiment
- Dataset: FFHQ (train) + CelebA-HQ (eval), Standford Cars, LSUN Horse & Church, AFHQ Wild
- Baseline: (인코더 기반) IDInvert encdoer, pSp, e4e / (최적화 기반) Karras / (Hybrid) 인코더 + 최적화
- Loss와 training detail은 pSp와 e4e의 기존 연구와 동일하게 사용
- $N=5$로 설정

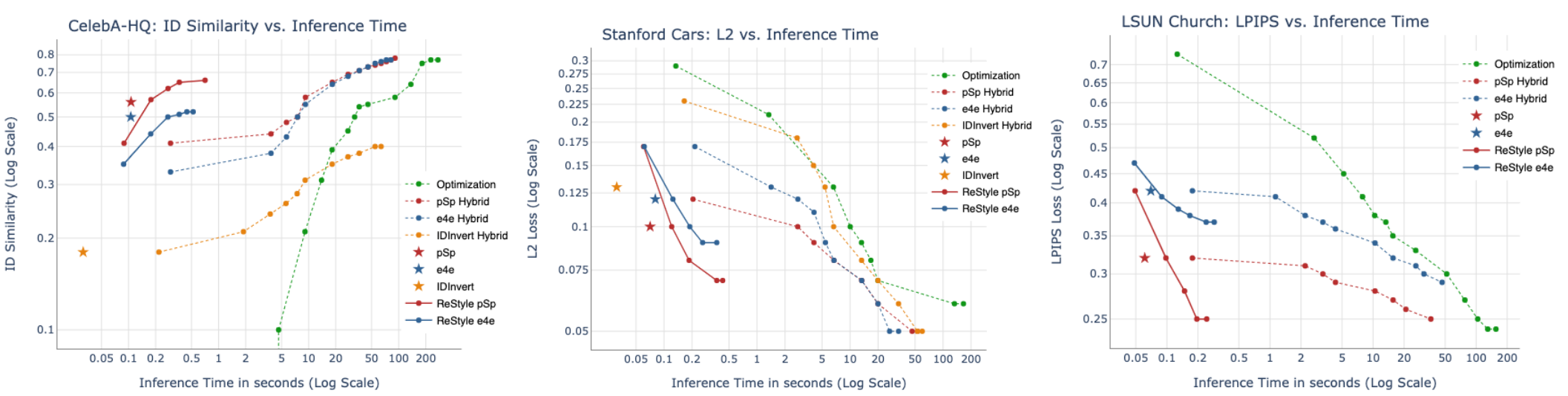
각 데이터 셋에 대한 정량적 평가는 아래와 같다.
다음은 각 step에서의 이미지 변화를 나타낸 그림이다.
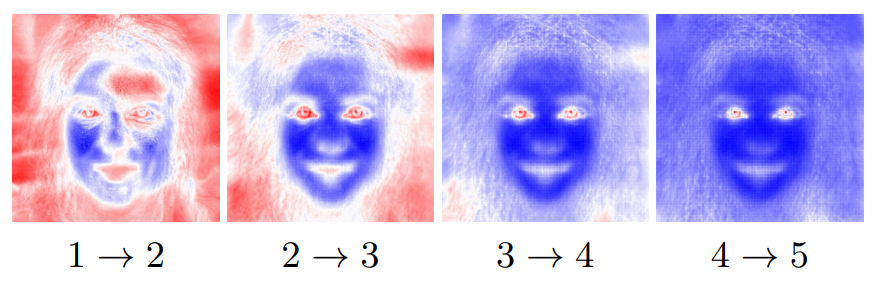

위는 각 step에서 상대적으로 많이 변한 부분을 빨간색으로, 덜 변한 부분을 파란색으로 나타낸 것이다. 아래는 step 간의 상대적인 변화량을 나타낸 것이다.
Editability 비교는 다음과 같다.

다음은 입력 이미지에 대한 각 step의 output이다.

Encoder Bootstapping
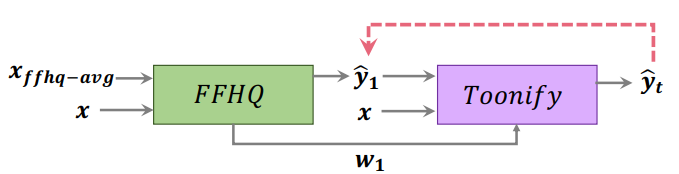
논문에서는 Encoder bootstrapping이라는 새로운 개념을 제시되었다. 먼저 FFHQ로 학습한 인코더로 step을 한 번 수행하여 latent code $w_1$과 대응되는 이미지 $\hat{y}_1$을 계산한다. 그런 다음 나머지 step은 Toonify 인코더로 latent code와 이미지를 계산하여 최종적으로 입력 이미지와 비슷한 Toonify 이미지를 만들어낸다.

