[논문리뷰] Reloc3r: Large-Scale Training of Relative Camera Pose Regression for Generalizable, Fast, and Accurate Visual Localization
CVPR 2025. [Paper] [Github]
Siyan Dong, Shuzhe Wang, Shaohui Liu, Lulu Cai, Qingnan Fan, Juho Kannala, Yanchao Yang
The University of Hong Kong | Aalto University | ETH Zurich | VIVO 5University of Oulu
11 Dec 2024
Introduction
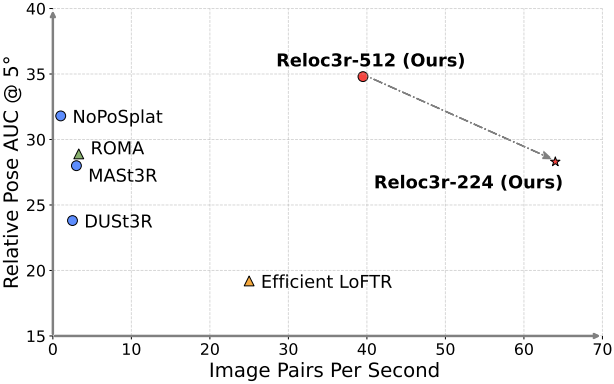
기존의 relative pose regression (RPR) 방법들은 새로운 장면으로의 일반화, test-time 효율성, 카메라 포즈 정확성 중 하나에서 어려움을 겪는다. 본 논문은 이러한 한계를 해결하기 위해, 간단하면서도 효과적인 visual localization 프레임워크인 Reloc3r을 제시하였다.
저자들은 DUSt3R의 아키텍처를 backbone으로 채택하고, 간결한 수정을 통해 RPR 네트워크를 구축하였다. 네트워크는 완전히 대칭적으로 설계되었으며 학습 중 relative pose의 metric scale을 무시한다. 그런 다음 이를 motion averaging 모듈과 통합하여 absolute pose를 추정한다. 저자들은 대규모 학습의 힘을 최대한 활용하기 위해 다양한 소스에서 약 800만 개의 이미지 쌍을 처리했다.
Method
- 목표: 카메라 포즈를 알고 있는 $n$개의 이미지 \(\textbf{D} = \{I_{d_n} \in \mathbb{R}^{H \times W \times 3} \vert n = 1, \ldots, N\}\)이 주어졌을 때, 쿼리 이미지 $I_q$의 카메라 포즈 $P = [R \vert t] \in \mathbb{R}^{3 \times 4}$를 $\textbf{D}$의 좌표계에서 추정
- 방법 개요
- top-K 이미지를 선택해 이미지 쌍의 집합 \(\textbf{Q} = \{(I_{d_k}, I_q) \vert k = 1, \ldots, K\}\)를 구성
- 각 이미지 쌍에 대한 relative pose $P_{d,q}$와 $P_{q,d}$를 추정
- 알고 있는 포즈 \(\{\hat{P}_{d_1}, \ldots, \hat{P}_{d_K}\}\)로부터 $I_q$의 absolute pose를 계산
1. Relative Camera Pose Regression
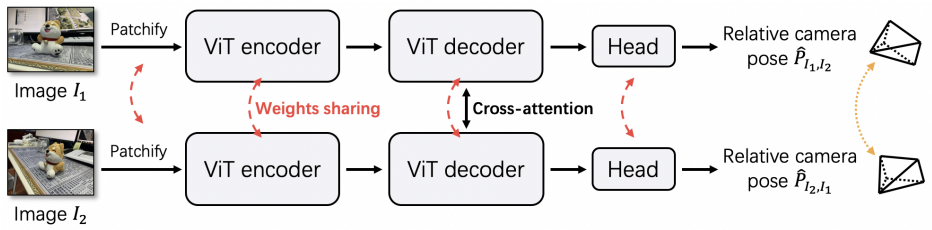
네트워크는 이미지 쌍 $I_1$, $I_2$를 입력으로 받는다. 두 이미지의 해상도는 동일하다고 가정하지만, 실제로는 해상도가 다를 수 있다. 네트워크는 이미지를 패치로 나누고 ViT 인코더를 통해 토큰으로 처리한다. 그런 다음 ViT 디코더는 cross-attention을 사용하여 두 branch의 토큰 간에 정보를 교환한다. 그 후 relative pose \(\hat{P}_{I_1, I_2}\)와 \(\hat{P}_{I_2, I_1}\)을 예측하는 regression head가 이어진다. 두 branch는 완전히 대칭적이며 가중치를 공유한다.
ViT 인코더-디코더 아키텍처
두 모듈은 DUSt3R의 모듈과 유사하며 사전 학습을 통해 상당한 이점을 얻는다. 먼저, 각 입력 이미지 $I_1$, $I_2$를 각각 차원 $d$를 가진 $T$개의 토큰 시퀀스로 나눈다. 다음으로, 각 토큰에 대한 RoPE 위치 임베딩을 계산하여 이미지 내 상대적인 공간적 위치를 인코딩한다. 그런 다음, 각 토큰이 self-attention layer와 feed-forward layer로 구성된 $m$개의 ViT 인코더 블록을 통해 토큰을 처리하여 인코딩된 feature 토큰 $F_1$과 $F_2$를 생성한다.
\[\begin{aligned} F_1^{(T \times d)} &= \textrm{Encoder} (\textrm{Patchify} (I_1^{(H \times W \times 3)})) \\ F_2^{(T \times d)} &= \textrm{Encoder} (\textrm{Patchify} (I_2^{(H \times W \times 3)})) \end{aligned}\]디코더는 $n$개의 ViT 디코더 블록으로 구성되며, 각 블록은 RoPE 위치 임베딩을 사용한다. 인코더 블록과 달리, 각 디코더 블록은 self-attention layer와 feed-forward layer 사이에 추가적인 cross-attention layer을 포함한다. 이러한 구조를 통해 모델은 두 개의 feature 토큰 집합 간의 공간적 관계를 추론할 수 있다.
\[\begin{aligned} G_1^{(T \times d)} &= \textrm{Decoder} (F_1^{(T \times d)}, F_2^{(T \times d)}) \\ G_2^{(T \times d)} &= \textrm{Decoder} (F_2^{(T \times d)}, F_1^{(T \times d)}) \end{aligned}\]Pose regression head
최근 연구에 따라, pose regression head는 $h$개의 feed-forward layer와 average pooling으로 구성되며, relative rotation 및 relative translation 예측을 위한 추가 레이어가 있다. Rotation은 처음에 9차원 표현을 사용하여 표현된다. 그런 다음 SVD 직교화를 사용하여 3$\times$3 rotation 행렬로 변환된다. 이 행렬은 3차원 translation 벡터와 concat되어 최종 변환 행렬이 형성된다.
\[\begin{equation} \hat{P}_{I_1, I_2}^{(3 \times 4)} = \textrm{Head} (G_1^{(T \times d)}), \quad \hat{P}_{I_2, I_1}^{(3 \times 4)} = \textrm{Head} (G_2^{(T \times d)}) \end{equation}\]Supervision signal
네트워크가 예측한 포즈는 두 가지 정보, rotation과 translation을 전달한다. 네트워크는 다음과 같은 loss로 학습된다.
\[\begin{equation} \mathcal{L} = \textrm{arccos} (\frac{\textrm{tr} (\hat{R}^{-1} R) - 1}{2}) + \textrm{arccos} (\frac{\hat{t} \cdot t}{\| \hat{t} \| \| t \|}) \end{equation}\]($\textrm{tr}(\cdot)$은 대각합, $\hat{R}$과 $\hat{t}$는 예측된 rotation과 translation, $R$과 $t$는 GT rotation과 translation)
2. Motion Averaging
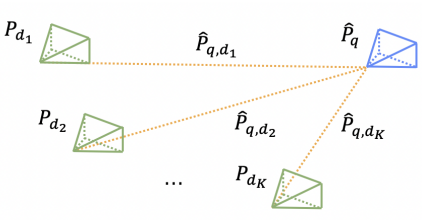
효율성과 단순성을 유지하기 위해, regression 네트워크를 작은 motion averaging 모듈과 통합한다. 기본적으로, 쿼리 $q$를 데이터베이스 $\textbf{D}$에 매핑하는 변환을 motion averaging의 입력으로 사용한다. 모듈은 rotation과 translation을 개별적으로 처리한다.
Rotation avgeraging
데이터베이스-쿼리 쌍에서 relative rotation 추정값 \(\hat{R}_{q, d_i}\)이 주어지면, absolute rotation은
\[\begin{equation} \hat{R}_q = R_{d_i} \hat{R}_{q, d_i} \end{equation}\]로 계산된다. Motion averaging 모듈은 사용 가능한 모든 쌍에서 absolute rotation 추정값을 집계하여 예측 정확도를 높인다. 이 집계는 quaternion 표현을 사용하여 중간 rotation을 계산하며, 평균 rotation을 계산하는 것보다 노이즈에 대한 robustness를 더욱 향상시킬 수 있다.
Camera center triangulation
절대적인 카메라 중심은 두 데이터베이스-쿼리 쌍으로부터 triangulation될 수 있다. Rotation averaging과 유사하게, 모든 유효한 쌍을 사용하여 평균 교점을 계산한다. 교점의 기하 중앙값은 일반적으로 반복 최적화가 필요하지만, 본 논문에서는 relative pose 추정치로부터 도출된 카메라 중심에서 각 translation 방향까지의 거리 제곱의 합을 최소화하는 간단한 최소제곱법을 사용한다. 이 해는 SVD를 통해 구한다.
Experiments
- 구현 디테일
- 인코더 블록 $m = 24$개, 디코더 블록: $n = 12$개
- regression head: convolutional layer $h = 2$개
- memory-efficient attention 사용 (속도 14% 상승, GPU 메모리 25% 절약)
- 사전 학습된 DUSt3R 가중치로 초기화
- batch size: 8
- learning rate: $10^{-5} \rightarrow 10^{-7}$
- GPU: AMD MI250x-40G 8개
1. Relative Camera Pose Estimation
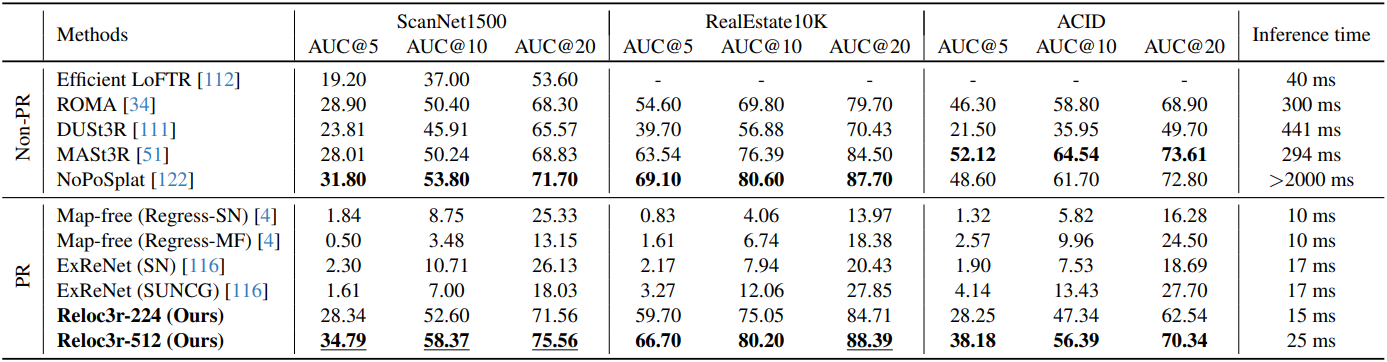
다음은 pair-wise relative pose에 대한 비교 결과이다.
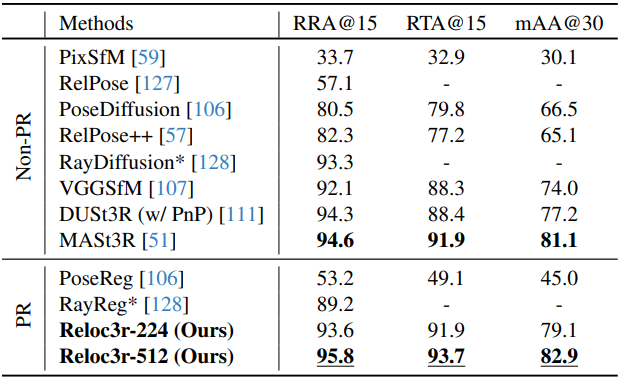
다음은 multi-view relative pose에 대한 비교 결과이다. (CO3Dv2)
2. Visual Localization
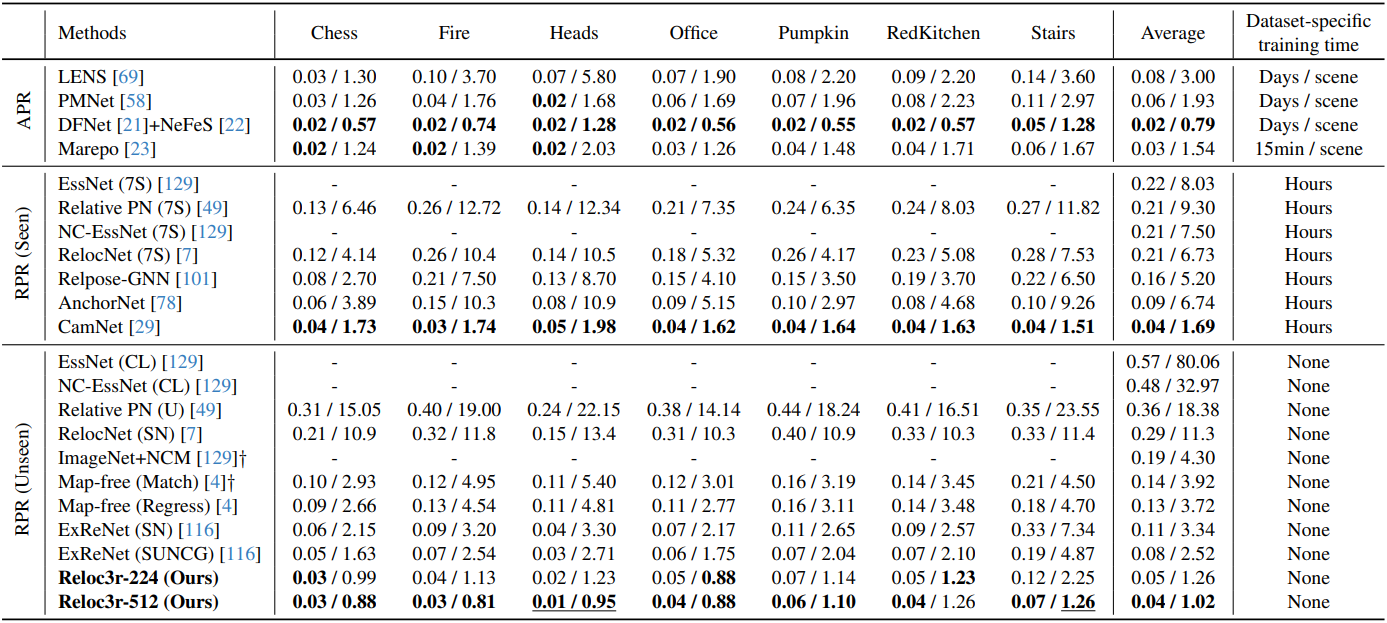
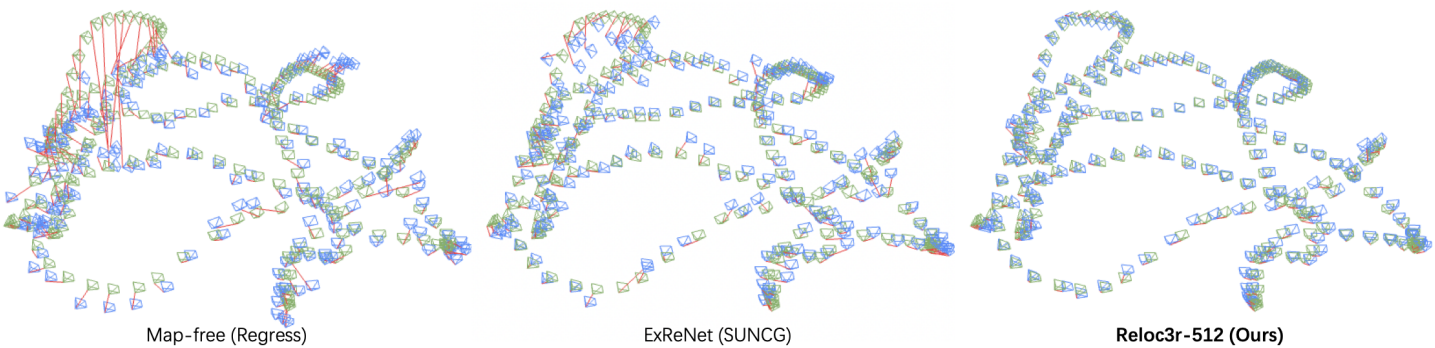
다음은 7 Scenes 데이터셋에 대한 visual localization 결과이다.
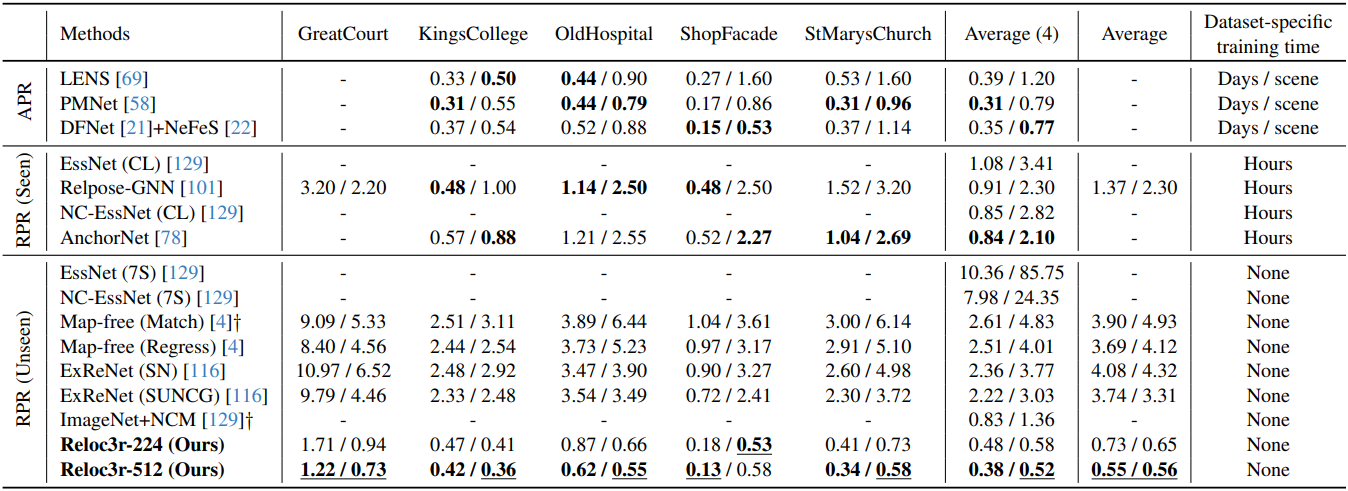
다음은 Cambridge Landmarks 데이터셋에 대한 visual localization 결과이다.
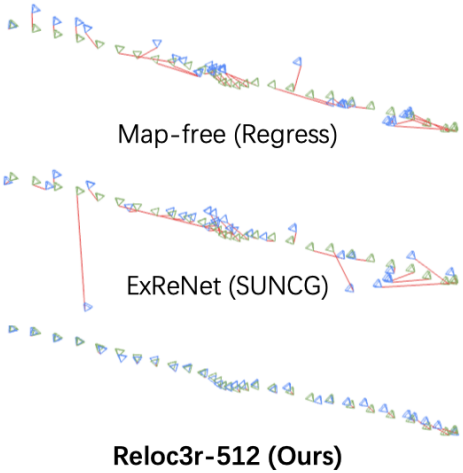
3. Analyses
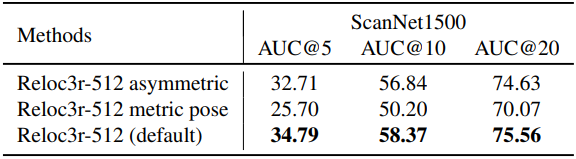
다음은 아키텍처에 대한 ablation 결과이다.
Limitations
쿼리 이미지와 검색된 모든 데이터베이스 이미지가 동일 선상에 있으면, motion averaging 방법으로 metric scale을 해결할 수 없다.