[논문리뷰] Representation Entanglement for Generation: Training Diffusion Transformers Is Much Easier Than You Think
NeurIPS 2025 (Oral). [Paper] [Github]
Ge Wu, Shen Zhang, Ruijing Shi, Shanghua Gao, Zhenyuan Chen, Lei Wang, Zhaowei Chen, Hongcheng Gao, Yao Tang, Jian Yang, Ming-Ming Cheng, Xiang Li
Shenzhen Futian | Nankai University | JIIOV Technology | Harvard University | University of Chinese Academy of Sciences
2 Jul 2025

Introduction
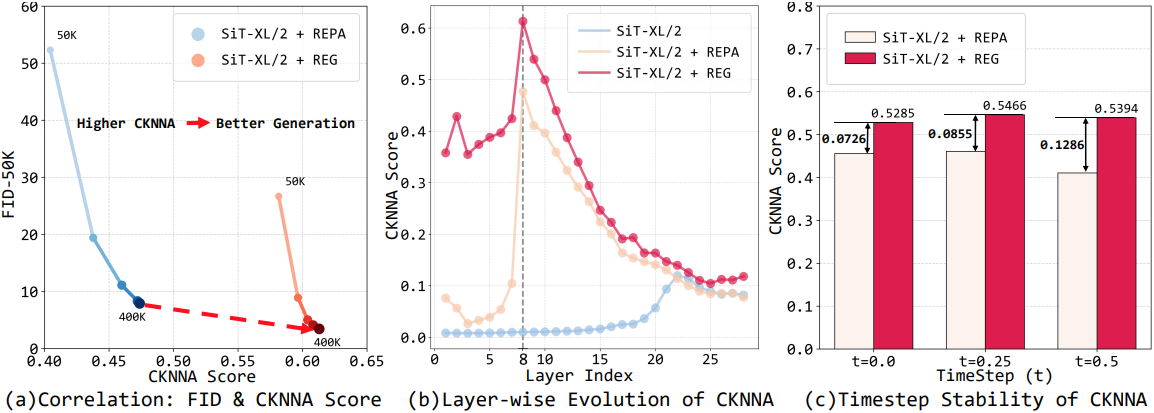
최근 논문들은 향상된 생성 모델이 더욱 판별력 있는 표현을 획득할 수 있음을 보여주며, 이를 통해 생성 모델이 유능한 표현 학습 모델로서의 역할을 수행할 수 있음을 시사하였다. 그러나 CKNNA metric으로 정량화했을 때, 이러한 feature들은 사전 학습된 비전 모델의 feature들에 비해 여전히 성능이 떨어진다. 이러한 성능 격차는 사전 학습된 비전 인코더 feature를 활용하여 생성 모델 학습 수렴 속도를 높이는 접근 방식에 대한 필요성을 제기했다.
REPA는 diffusion model과 foundation model 간의 feature 공간 정렬을 사용하며, REPA-E는 end-to-end VAE 튜닝을 가능하게 함으로써 이러한 정렬을 확장하고, 향상된 정렬이 생성 정확도를 직접적으로 향상시킨다는 것을 보여주었다. 그러나 전체 denoising 과정에서 적용되지 않는 REPA의 외부 정렬은 판별적 정보의 잠재력을 충분히 활용하지 못한다. 본 논문에서는 이러한 구조가 판별적 semantic 학습 및 전반적인 생성 능력의 발전을 저 해할 가능성이 있다고 생각하였다.
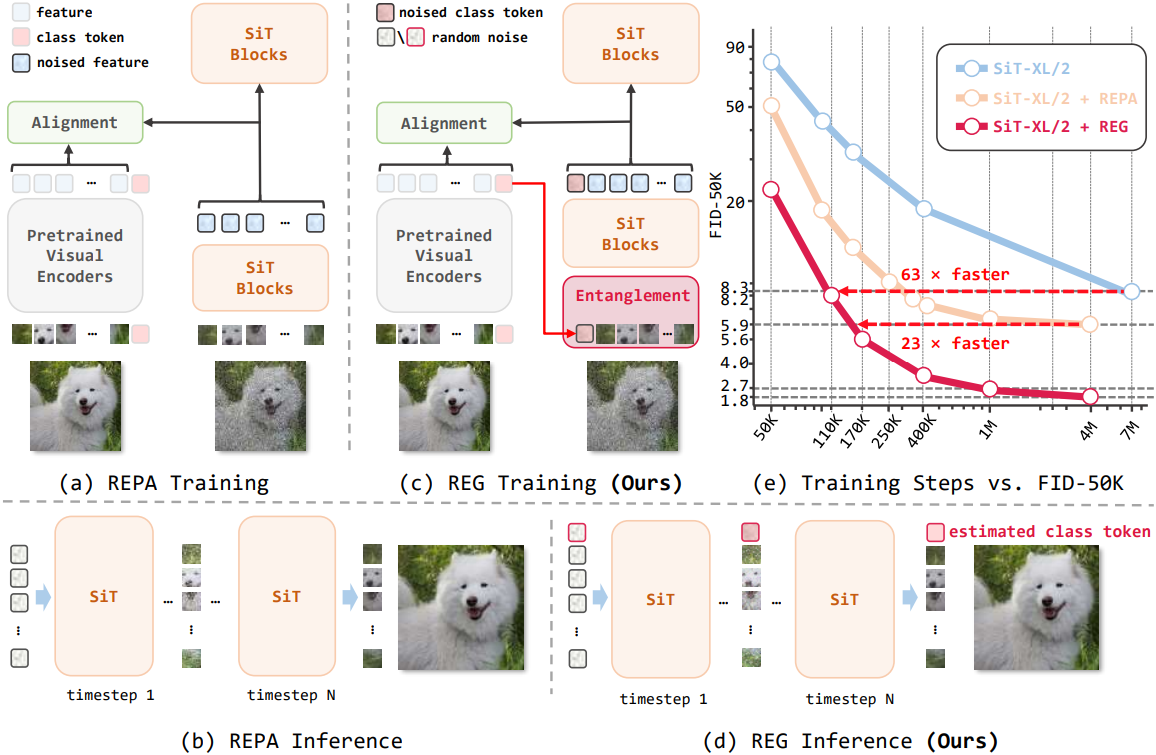
이러한 한계를 해결하기 위해, 본 논문에서는 판별적 정보를 생성 과정에 명시적으로 통합함으로써 판별적 정보의 잠재력을 극대화하는 효율적인 프레임워크인 Representation Entanglement for Generation (REG)을 제안하였다. REG는 사전 학습된 foundation model의 저수준 이미지 latent와 고수준 클래스 토큰을 concat하고 noise를 주입하여 학습 과정에서 이들을 얽히게 한다. Inference 과정은 랜덤 noise로부터 이미지 latent와 그에 해당하는 글로벌 semantic 정보를 동시에 재구성하며, 획득된 semantic 지식은 이미지 생성 과정을 적극적으로 가이드하고 향상시킨다.
REG는 단 하나의 토큰만 추가함으로써 최소한의 계산 비용으로 생성 품질, 학습 수렴 속도, semantic 학습을 크게 향상시킨다. 256$\times$256 해상도의 클래스 조건부 ImageNet 벤치마크에서, SiT-XL/2 + REG는 SiT-XL/2와 SiT-XL/2 + REPA에 비해 각각 63배, 23배 빠른 학습 수렴 속도를 달성했다. 특히, 40만 iteration의 학습을 거친 SiT-XL/2 + REPA는 400만 iteration의 학습을 거친 SiT-XL/2 + REPA의 성능을 능가했다.
Method
REG training process
깨끗한 입력 이미지 \(\textbf{x}_\ast\)가 주어졌을 때, VAE 인코더를 통해 이미지 latent \(\textbf{z}_\ast \in \mathbb{R}^{D_z \times C_z \times C_z}\)를 얻고, DINOv2와 같은 foundation model에서 이미지 feature \(\textbf{f}_\ast \in \mathbb{R}^{N \times D_{vf}}\)를 얻는다.
REPA에서는 inference 과정에서 생성을 가이드하는 판별적 표현을 자율적으로 생성하는 능력이 부족하여 판별적 정보의 활용도가 떨어질 수 있다. 본 논문에서는 판별적인 guidance를 제공하기 위해 foundation model에서 생성된 클래스 토큰 \(\textbf{cls}_\ast \in \mathbb{R}^{1 \times D_\textrm{vf}}\)를 이미지 latent와 얽히게 하였다.
구체적으로, 클래스 토큰과 이미지 latent 모두에 noise를 주입한다. 두 개의 Gaussian noise 샘플 \(\epsilon_z \in \mathbb{R}^{D_z \times C_z \times C_z}\)와 \(\epsilon_\textrm{cls} \in \mathbb{R}^{1 \times D_\textrm{vf}}\)가 주어졌을 때, 시간 $t \in [0, 1]$에서 다음과 같은 interpolation 연산을 수행한다.
\[\begin{aligned} \textbf{z}_t &= \alpha_t \textbf{z}_\ast + \sigma_t \epsilon_z \\ \textbf{cls}_t &= \alpha_t \textbf{cls}_\ast + \sigma_t \epsilon_\textrm{cls} \end{aligned}\]이는 forward process에서 중간 상태 \(\textbf{z}_t\)와 \(\textbf{cls}_t\)를 정의한다. 그런 다음 \(\textbf{z}_t\)를 \(\textbf{z}_t^\prime \in \mathbb{R}^{N \times D_z^\prime}\)로 patchify한다. 클래스 토큰 \(\textbf{cls}_t\)는 linear layer를 통해 동일한 임베딩 공간으로 projection되어 \(\textbf{cls}_t^\prime \in \mathbb{R}^{1 \times D_z^\prime}\)를 얻는다. 마지막으로, 이들을 concat하여 \(\textbf{h}_t = [\textbf{cls}_t^\prime, \textbf{z}_t^\prime] \in \mathbb{R}^{(N+1) \times D_z^\prime}\)를 생성하며, 이는 후속 SiT block의 입력으로 사용된다.
저자들은 특정 transformer layer $n$에서 정렬을 수행하여 REPA와의 일관성을 유지하였다 (SiT-B/2 + REG의 경우 $n=4$, 다른 모든 경우 $n=8$). 구체적으로, \(\textbf{h}_t^{[n]}\)를 MLP로 projection시켜 \(h_\phi (\textbf{h}_t^{[n]}) \in \mathbb{R}^{(N+1) \times D_\textrm{vf}}\)로 만든 다음, \(\textbf{y}_\ast = [\textbf{cls}_\ast, \textbf{f}_\ast]\) 정렬한다. 정렬 loss는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{REPA}(\theta, \phi) = - \mathbb{E}_{\textbf{x}_t, \epsilon, t} \left[ \frac{1}{N} \sum_{n=1}^N \textrm{sim} (\textbf{y}_\ast, h_\phi (\textbf{h}_t^{[n]})) \right] \end{equation}\]정렬 외에도, 학습 loss에는 noise가 포함된 이미지 latent \(\textbf{z}_t\)와 클래스 토큰 \(\textbf{cls}_t\) 모두에 대한 속도 예측이 포함된다. 예측 loss는 다음과 같다.
\[\begin{equation} \mathcal{L}_\textrm{pred} = \mathbb{E}_{\textbf{x}_\ast, \epsilon, t} \left[ \| \textbf{v} (\textbf{z}_t, t) - \dot{\alpha}_t \textbf{z}_\ast - \dot{\sigma}_t \epsilon_z \|^2 + \beta \| \textbf{v} (\textbf{cls}_t, t) - \dot{\alpha}_t \textbf{cls}_\ast - \dot{\sigma}_t \epsilon_\textrm{cls} \|^2 \right] \end{equation}\](\(\textbf{v}(\cdot, t)\)는 속도 예측 함수)
최종 학습 loss는 두 loss를 모두 통합한다.
\[\begin{equation} \mathcal{L}_\textrm{total} = \mathcal{L}_\textrm{pred} + \lambda \mathcal{L}_\textrm{REPA} \end{equation}\]REG inference process
이 프레임워크는 클래스 토큰 생성에 보조 네트워크를 필요로 하지 않는다. REG는 랜덤 noise 초기화를 통해 이미지 latent와 글로벌 semantic 정보를 동시에 재구성한다. 또한, 습득한 semantic 지식을 적극적으로 활용하여 생성 품질을 향상시킨다.
일반적으로 REG는 기존 접근 방식에 비해 세 가지 주요 이점을 보여준다.
- 판별적 정보 활용 향상
- 최소한의 계산 오버헤드
- 다양한 metric에서 향상된 성능
Experiments
1. Model performance
다음은 모델의 성능을 비교한 결과이다.
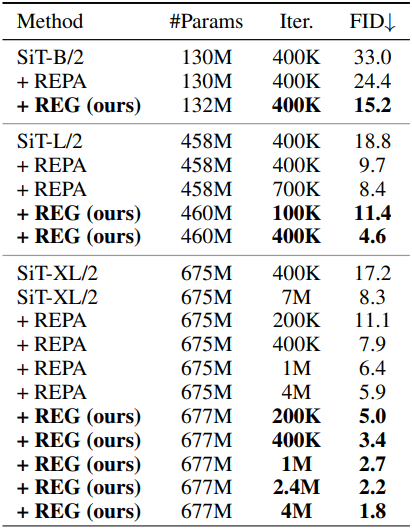
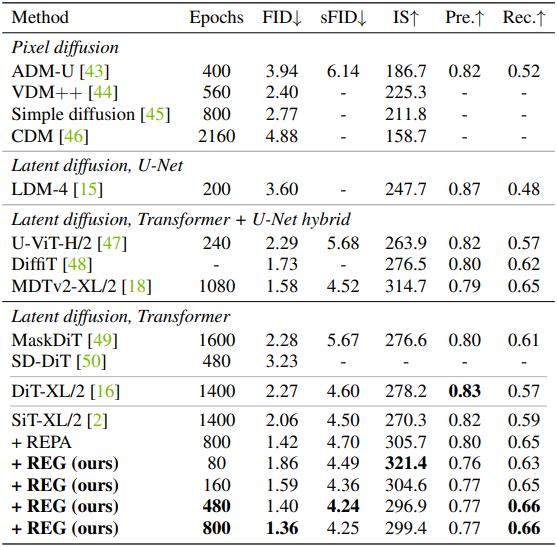
다음은 계산 비용을 비교한 결과이다. (ImageNet 256$\times$256)

2. Ablation analysis
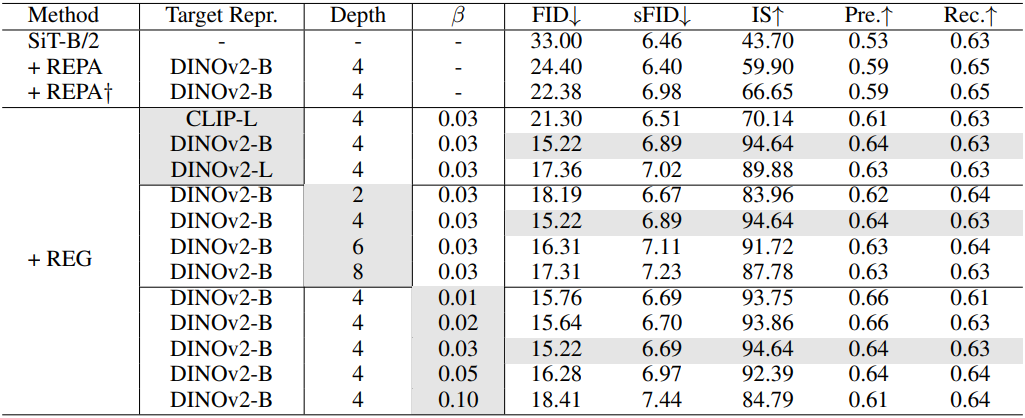
다음은 타겟 표현, layer 깊이, $\beta$에 대한 ablation study 결과이다. (ImageNet 256$\times$256)
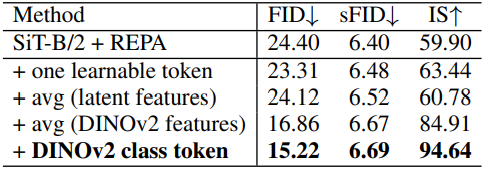
다음은 (왼쪽) 얽히게 할 신호와 (오른쪽) 클래스 토큰에 대한 ablation study 결과이다. (ImageNet 256$\times$256)
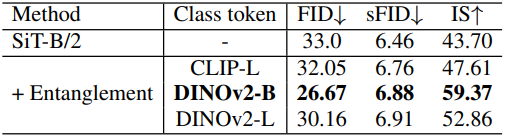
3. Discriminative semantics
다음은 학습된 표현에 대한 분석 결과이다.