[논문리뷰] Refusion: Enabling Large-Size Realistic Image Restoration with Latent-Space Diffusion Models
CVPRW 2023. [Paper] [Github]
Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sjölund, Thomas B. Schön
Uppsala University
17 Apr 2023

Introduction
이미지 복원은 다양한 degradation(저하) 요인 (ex. noise, 다운샘플링, hazing)에 따라 저품질(LQ) 이미지에서 고품질(HQ) 이미지를 복원하는 문제이다. 지난 10년 동안 딥 러닝에 기반한 방법은 이미지 복원에서 인상적인 성능을 달성했다. 그러나 이러한 방법의 대부분은 픽셀 기반 reconstruction loss function, 즉 $L_1$/$L_2$로 인해 지나치게 매끄러운 이미지를 생성하는 경향이 있다.
최근 diffusion model은 순수한 noise로 구성된 이미지를 샘플링한 다음 Langevin 역학 또는 reverse-time SDE로 반복적으로 noise를 제거하여 고품질 결과를 생성하는 강력한 능력을 보여주었다. 그러나 많은 일반적인 이미지 복원 작업은 복잡한 성능 저하와 실제 데이터셋의 크고 임의적인 이미지 크기로 인해 diffusion model에서 여전히 어려운 task이다. 사전 학습된 diffusion model의 사용과 관련하여 흥미로운 발전이 있었다. 기존 접근 방식의 두 가지 단점은 다음과 같다.
- 데이터셋(ex. ImageNet, FFHQ)을 신중하게 큐레이팅하는 데 의존
- Degradation 파라미터를 알아야 한다.
이러한 단점은 현실에서의 적용 가능성을 제한한다.
복잡한 실제 왜곡을 처리하기 위해 최근 연구들에서는 순수한 noise 이미지와 저품질 이미지의 조합을 noise 네트워크의 중간 입력으로 활용했다. 이 접근 방식은 degradation 파라미터의 필요성을 피하고 noise를 원하는 고품질 이미지로 변환하기 위해 reverse process를 시행한다. 그러나 이러한 접근 방식은 다소 휴리스틱하며 일반적인 task에 적용하기 어렵다. 보다 일반적인 이미지 복원 방법은 IR-SDE로, degradation을 모델링하는 mean-reverting SDE를 기반으로 HQ 이미지를 복구할 것을 제안하며 데이터셋만 변경하여 다양한 task에 적용할 수 있다. IR-SDE의 단점은 최종 출력을 복원하기 위해 전체 이미지에서 여러 단계의 noise 제거가 필요하기 때문에 테스트 시에 계산적으로 요구된다는 것이다. 이는 실제 애플리케이션, 특히 고해상도 이미지의 경우 문제가 될 수 있다.
본 논문의 목적은 diffusion model을 개선하여 다양한 실제 이미지 복원 작업을 처리하는 데 효율성을 높이는 것이다. 그 결과는 Refusion (image Restoration with diffusion models)이다. 다양한 문제를 수용하는 단순성과 유연성으로 인해 IR-SDE는 Refusion의 기반 역할을 한다. 다양한 noise 네트워크 아키텍처를 탐색하여 NAFNet (Nonlinear-activation-free network)을 사용하면 noise와 score 예측에서 우수한 성능을 달성하는 동시에 계산 효율이 높아질 수 있다. 또한 다양한 noise 레벨, denoising step, 학습 이미지 크기, 최적화/스케줄러 선택의 영향도 설명하였다. 더 큰 이미지를 다루기 위해 U-Net 기반 latent diffusion 전략을 제안한다. 이를 통해 압축된 저해상도 latent space에서 이미지 복원을 수행할 수 있으므로 학습 및 inference 속도가 모두 빨라진다.
Preliminaries: Mean-Reverting SDE
본 논문의 방법은 사실적인 이미지 복원을 위해 diffusion model을 활용한다. 특히 IR-SDE를 기본 diffusion 프레임워크로 사용하여 degradation이 얼마나 복잡한지에 관계없이 고품질 이미지를 degrade된 저품질 이미지로 자연스럽게 변환할 수 있다. IR-SDE의 forward process는 다음과 같이 정의된다.
\[\begin{equation} dx = \theta_t (\mu - x) dt + \sigma_t dw \end{equation}\]여기서 $\theta_t$와 $\sigma_t$는 각각 mean-reversion 속도와 확률적 변동성을 특징짓는 양의 파라미터이다. SDE 계수가 모든 $t$에 대하여 $\frac{\sigma_t^2}{\theta_t} = 2 \lambda^2$을 만족하도록 설정하면 주변 분포 $p_t (x)$는 다음과 같이 계산할 수 있다.
\[\begin{aligned} p_t (x) &= \mathcal{N}(x(t) \vert m_t, v_t) \\ m_t &:= \mu + (x(0) - \mu) \exp(- \bar{\theta}_t) \\ v_t &:= \lambda^2 (1 - \exp(-2 \bar{\theta}_t)) \\ \bar{\theta}_t &:= \int_0^t \theta_z dz \end{aligned}\]$t$가 증가함에 따라 평균값 $m_t$와 분산 $v_t$는 각각 $\mu$와 $\lambda^2$으로 수렴한다. 따라서 초기 상태 $x(0)$는 추가 noise를 사용하여 반복적으로 $\mu$로 변환되며 noise 레벨은 $\lambda$로 고정된다.
IR-SDE forward process는 forward Ito SDE이며 reverse-time 표현은 다음과 같다.
\[\begin{equation} dx = [\theta_t (\mu - x) - \sigma_t^2 \nabla_x \log p_t (x)] dt + \sigma_t d \hat{w} \end{equation}\]학습하는 동안 HQ 이미지에 접근할 수 있다. 즉, $p_t (x)$를 사용하여 ground-truth score function을 계산할 수 있다.
\[\begin{equation} \nabla_x \log p_t (x) = - \frac{x(t) - m_t}{v_t} \end{equation}\]Reparameterization trick은
\[\begin{equation} x(t) = m_t(x) + \sqrt{v_t} \epsilon_t, \quad \epsilon_t \sim \mathcal{N} (0, I) \end{equation}\]에 따라 $x(t)$를 샘플링할 수 있게 해준다. 그러면
\[\begin{equation} \nabla_x \log p_t(x) = − \frac{\epsilon_t}{v_t} \end{equation}\]로 다시 쓸 수 있다. CNN 네트워크는 일반적으로 noise를 추정하도록 학습되며 테스트 시에 reverse SDE를 시뮬레이션하여 다른 diffusion 기반 모델과 유사하게 저품질 이미지를 고품질 이미지로 변환한다.
Improving the Diffusion Model
1. Latent Diffusion under U-Net
고해상도 이미지가 포함된 task에서 diffusion model을 반복적으로 실행하는 것은 시간이 많이 걸리는 것으로 악명이 높다. 특히 모든 이미지가 6000$\times$4000$\times$3 픽셀로 캡처되는 HR dehazing의 경우 기존 diffusion model의 입력 크기를 훨씬 뛰어넘는다. 큰 입력 크기를 처리하기 위해 사전 학습된 U-Net 네트워크를 통합하여 저해상도 latent space에서 복원을 수행한다. 제안된 U-Net 기반 latent diffusion model의 전체 구조는 아래 그림에 나와 있다.
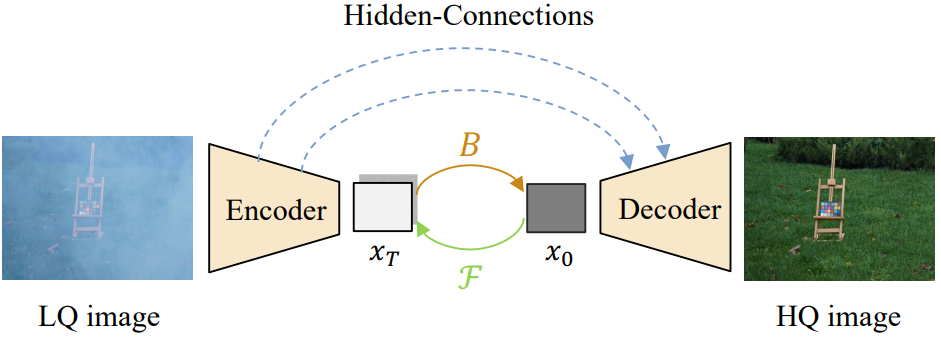
인코더는 LQ 이미지를 latent 표현으로 압축하고 IR-SDE reverse process를 통해 HQ latent 표현으로 변환한다. 이로부터 디코더는 HQ 이미지를 재구성한다. VAE-GAN을 압축 모델로 사용하는 latent diffusion과 비교할 때 중요한 차이점은 제안된 U-Net이 skip connection을 통해 인코더에서 디코더로 흐르는 멀티스케일 디테일을 유지한다는 것이다. 이렇게 하면 입력 이미지의 정보를 더 잘 캡처하고 더 정확한 HQ 이미지를 재구성하기 위해 디코더에 추가 디테일을 제공한다.
U-Net 모델을 학습할 때 압축된 latent 표현이 판별적이고 주요 degradation 정보를 포함하는지 확인해야 한다. 또한 U-Net 디코더는 변환된 LQ latent 표현에서 HQ 이미지를 재구성할 수 있어야 한다. 따라서 아래 그림과 같이 latent 교체 학습 전략을 채택한다.
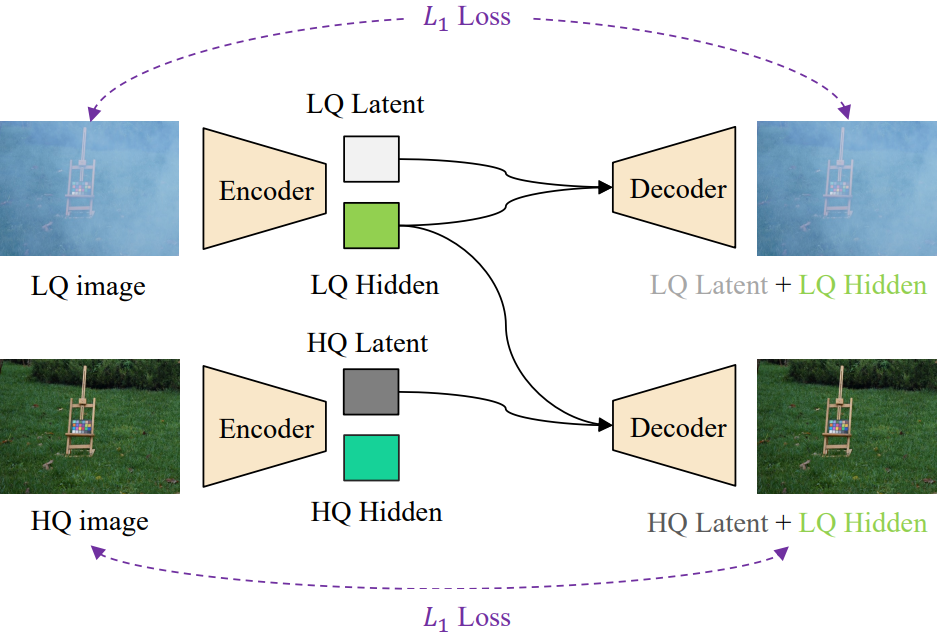
각 LQ 이미지는 먼저 U-Net에 의해 인코딩 및 디코딩되며 reconstruction $L_1$ loss가 적용된다. 그런 다음 U-Net은 LQ 잠재 표현을 HQ 이미지의 표현으로 대체하고 디코더를 다시 실행하여 해당 HQ 이미지를 재구성하도록 학습된다. 중요한 것은 이 학습 전략에는 적대적 최적화가 포함되지 않는다는 것이다. 따라서 모델 학습은 latent diffusion보다 더 안정적이다.
2. Modified NAFBlocks for Noise Prediction
Noise/score 예측에 일반적으로 사용되는 아키텍처는 residual block과 channel-attention, self-attention과 같은 attention 메커니즘이 있는 U-Net이다. 최근에 제안된 DiT는 Transformer 기반 구조를 사용하고 저해상도 latent space에서 diffusion을 시뮬레이션하여 FID 측면에서 클래스 조건부 ImageNet 512$\times$512 생성에 새로운 SOTA가 되었다. 그러나 latent diffusion 프레임워크 하에서도 순수한 Transformer 아키텍처는 여전히 기존 이미지 복원 애플리케이션에서 사용할 수 있는 것보다 더 큰 계산 비용을 발생시킨다.
본 논문은 앞서 언급한 모델 효율성 문제를 해결하기 위해 noise 예측을 위한 새로운 아키텍처를 탐색하였다. 특히 noise 네트워크는 약간 수정된 nonlinear activation free block (NAFBlock)을 기반으로 한다. 비선형 activation이 필요 없다는 것은 모든 비선형 activation function을 “SimpleGate”로 대체한다는 의미이다. 이는 feature 채널을 두 부분으로 분할한 다음 함께 곱하여 출력을 생성하는 element-wise 연산이다.
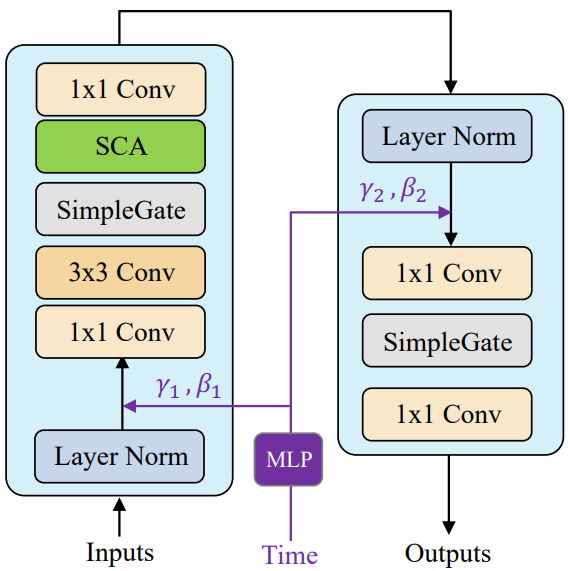
위 그림에서 볼 수 있듯이 attention layer와 feed-forward layer 모두에 대해 채널 방향의 scale 파라미터 $\gamma$와 shift 파라미터 $\beta$에 대한 시간 임베딩을 처리하기 위해 MLP를 추가한다. 다양한 task에 적응하기 위해 Bokeh Effect Transform의 렌즈 정보와 Stereo Image Super-Resolution의 이중 입력과 같은 task별 아키텍처로 네트워크를 약간 수정한다. U-Net 및 NAFNet 기반 diffusion의 학습 곡선은 아래 그림에 설명되어 있다.
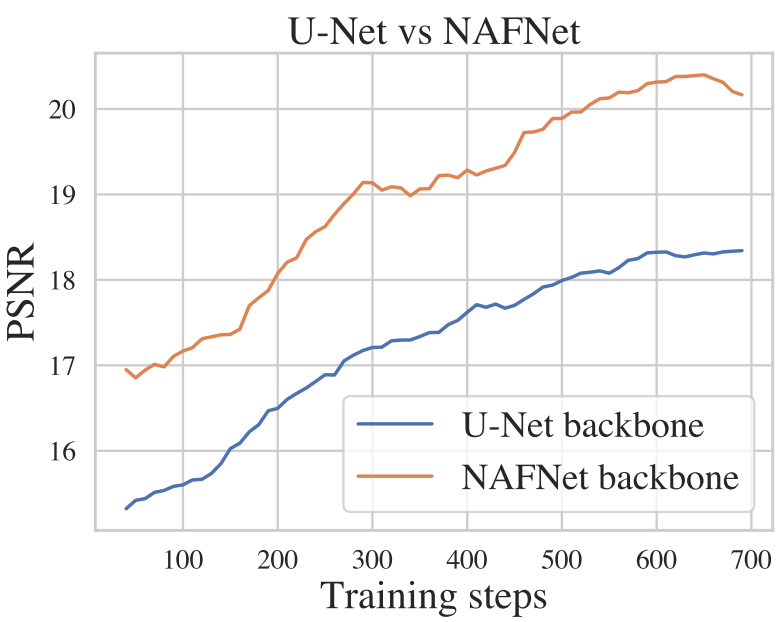
3. Improved Training Strategies
Noise levels
Noise 레벨은 확산 모델의 성능과 관련하여 중요한 역할을 할 수 있다. 이미지 복원에서 순수한 noise가 아닌 LQ 이미지에서 직접 HQ 이미지를 복구하는 경우가 많기 때문에 종단 상태에 대한 표준 가우시안이 필요하지 않다.
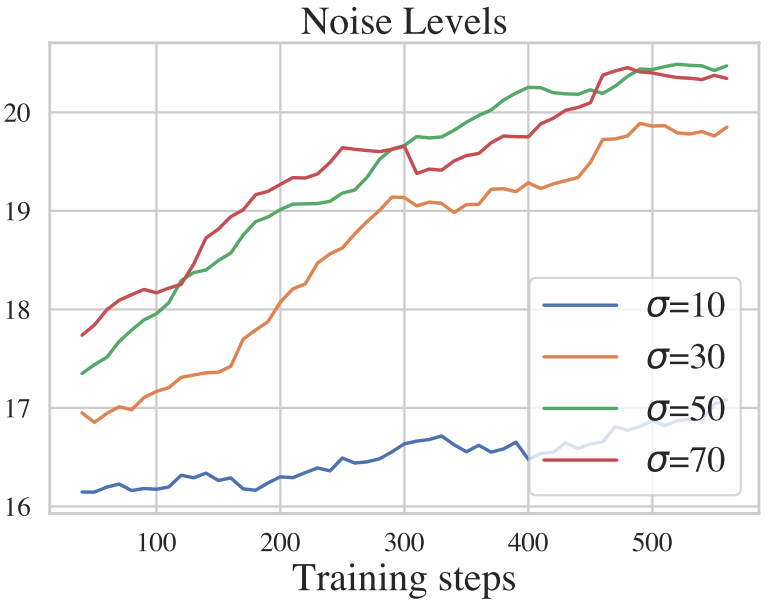
저자들은 그림자 제거 task에서 4개의 noise 레벨 \(\sigma = \{10, 30, 50, 70\}\)을 비교하였다. 위 그래프에서 볼 수 있듯이 작은 noise 레벨보다 큰 noise 레벨에서 더 높은 PSNR을 달성하였다.
Denoising steps
몇몇 연구들은 긴 step의 사전 학습된 가중치를 사용하지만 더 적은 step을 사용하여 이미지를 생성하도록 제안하였다. 이는 실제로 샘플 효율성을 개선하지만 이미지 품질을 저하시킨다. 이미지 복원에서는 모든 task에 대해 diffusion model을 처음부터 다시 학습해야 한다. IR-SDE는 안정적이고 강력한 학습 프로세스를 가지고 있기 때문에 저자들은 성능을 유지하면서 학습에서 denoising step을 직접 조정하였다.
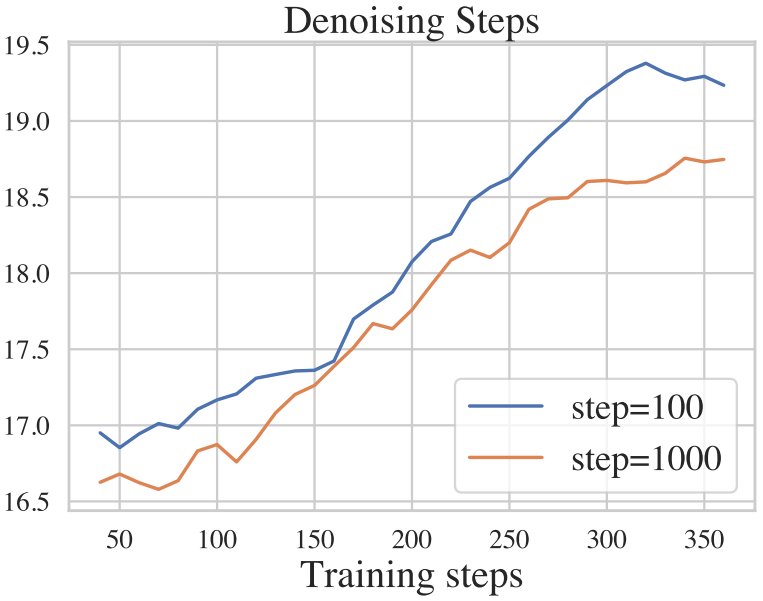
더 적은 수의 denoising step을 사용하면 복원 성능이 비슷하고 때로는 훨씬 더 우수할 수 있다.
Training patch sizes
일반적으로 큰 패치로 학습하면 이미지 복원 성능이 향상될 수 있다. 그러나 기존 연구들 중 어느 것도 diffusion model 학습에서 패치 크기의 영향에 대해 논의하지 않았다.
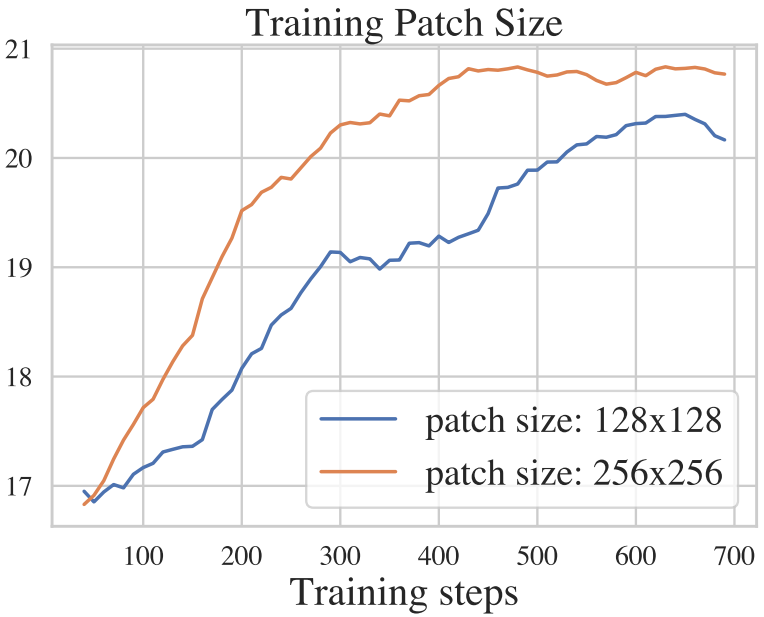
위 그래프에서 볼 수 있듯이 큰 패치를 사용한 학습이 훨씬 더 잘 수행되며 이는 다른 CNN/Transformer 기반 이미지 복원 접근 방식과 일치한다.
Optimizer/scheduler
적절한 learning rate scheduler가 있는 좋은 optimizer도 성능에 중요하다. 어떤 optimizer가 diffusion model과 더 잘 일치하는지 알아보기 위해 저자들은
- Adam + multi-step decay
- AdamW + cosine decay
- Lion + cosine decay
를 비교하였다.
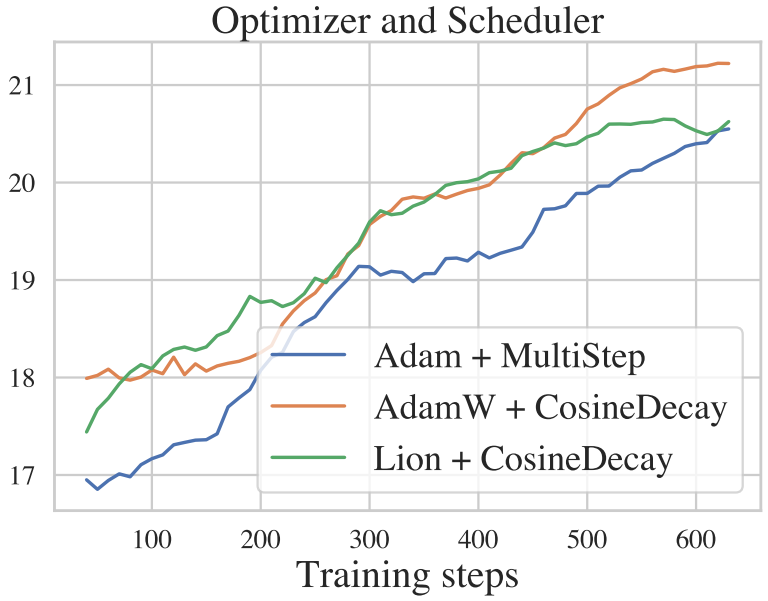
AdamW와 Lion 모두 multi-step learning rate decay를 통해 Adam 보다 약간 더 나은 성능을 보인다는 것을 보여준다.
Experiments
- Task / 데이터셋
- 이미지 그림자 제거 / NTIRE 2023 Shadow Removal Challenge
- Bokeh Effect Transformation / NTIRE 2023 Bokeh Effect Transformation challenge
- HR Non-Homogeneous Dehazing / NTIRE 2023 HR NonHomogeneous Dehazing competition
- 구현 세부 사항
- NAFNet과 동일한 세팅
- Batch size: 8
- 학습 패치 크기: 256$\times$256
- Optimizer: Lion ($\beta_1 = 0.9$, $\beta_2 = 0.99$)
- Learning rate: $3 \times 10^{-5}$ / cosine scheduler $10^{-7}$
- Noise 레벨: $\sigma = 50$
- Diffusion step: 100
- Augmentation: 랜덤 horizontal flip, 90도 회전
1. Experimental Results
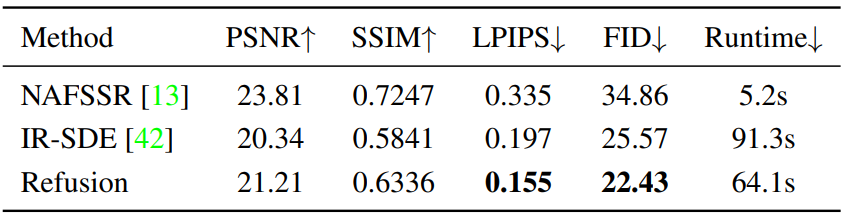
Stereo Image Super-Resolution
다음은 stereo super-resolution validation dataset에서 정량적으로 비교한 표이다.
다음은 stereo super-resolution의 시각적 결과이다.

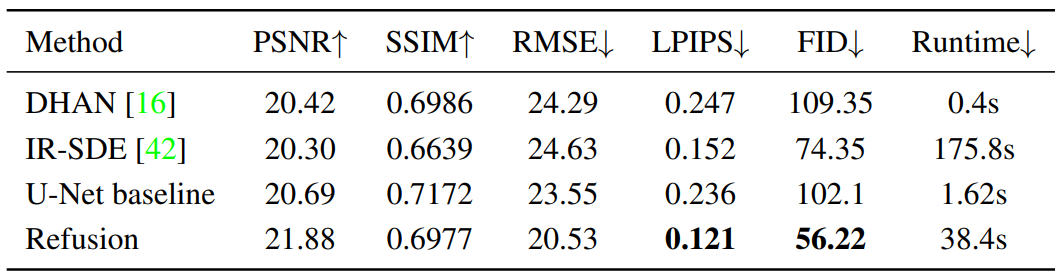
Image Shadow Removal
다음은 그림자 제거 데이터셋에서 정량적으로 비교한 표이다.
다음은 그림자 제거 task에 대한 시각적 결과이다. 위에서부터 순서대로 입력 이미지, U-Net baseline의 출력, Refusion의 출력이다.

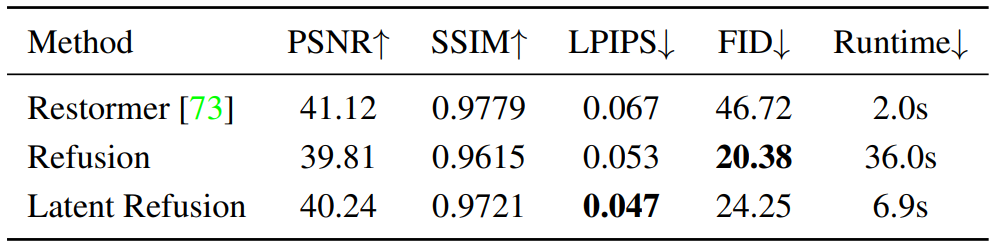
Bokeh Effect Transformation
다음은 Bokeh effect transformation 데이터셋에서 Restormer와 정량적으로 비교한 표이다.
다음은 Bokeh effect transformation task에 대한 시각적 결과이다. 위에서부터 순서대로 입력 이미지, Restormer의 출력, Refusion의 출력이다.

다음은 파라미터 수와 flops를 비교한 표이다.

HR Non-Homogeneous Dehazing
다음은 dehazing의 시각적 결과이다. 위가 입력 이미지, 아래가 Refusion의 출력이다.

2. NTIRE 2023 Challenge Results
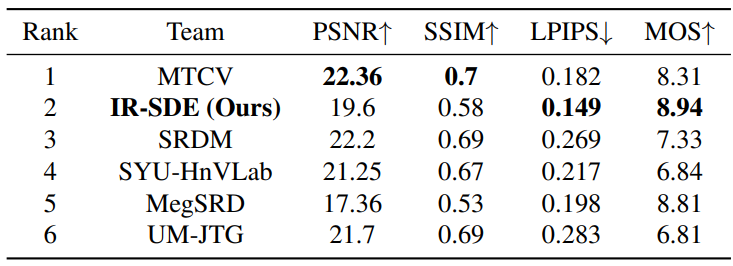
다음은 Shadow Removal Challenge의 최종 랭킹이다.