[논문리뷰] Explore In-Context Segmentation via Latent Diffusion Models (Ref LDM-Seg)
arXiv 2024. [Paper] [Page]
Chaoyang Wang, Xiangtai Li, Henghui Ding, Lu Qi, Jiangning Zhang, Yunhai Tong, Chen Change Loy, Shuicheng Yan
Peking University | S-Lab | Skywork AI | The University of California | Zhejiang University
14 Mar 2024
Introduction
In-context learning은 비전 및 NLP를 위한 cross-task modeling에 대한 새로운 관점을 제공하였다. 이를 통해 모델은 프롬프트에 따라 학습하고 예측할 수 있다. GPT3는 in-context learning을 먼저 정의하였으며, 이는 컨텍스트로 제공된 일부 입력-출력 쌍을 조건으로 처음 보는 task를 추론하는 것으로 해석된다. 여러 연구들에서는 프롬프트가 비전 task의 입력-출력인 비전의 in-context learning도 탐구하였다.
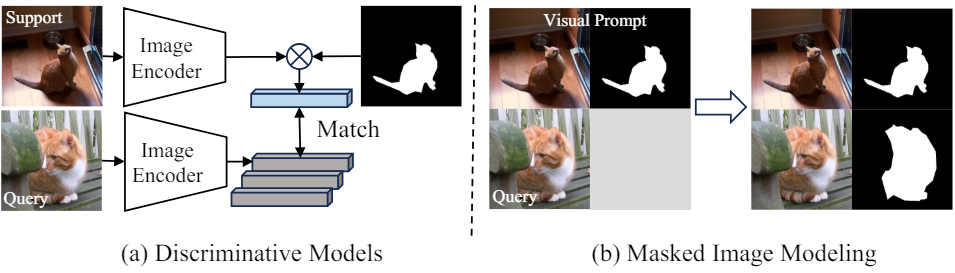
이는 segmentation 분야에서 few-shot segmentation(FSS)와 동일한 역할을 한다. 대부분의 접근 방식은 쿼리 이미지와 지원 이미지 (in-context learning을 위한 시각적 프롬프트) 간의 거리를 계산한다. FSS의 데이터 볼륨 및 카테고리에 대한 엄격한 제약을 극복하고 다양한 task에 걸쳐 일반화를 가능하게 하기 위해 최근 여러 연구들에서는 in-context segmentation으로 확장하고 마스크 일반화 task(b)로 공식화했다. 이는 마스크 디코딩을 통해 이미지 마스크를 직접 생성한다는 점에서 일치 또는 프로토타입 기반 discriminative model들(a)과 근본적으로 다르다. 그러나 이러한 접근 방식에는 그러한 쌍을 학습하기 위해 항상 대규모 데이터셋이 필요하다.

가장 최근에는 latent diffusion model (LDM)이 생성 task에 대한 큰 잠재력을 보여주었다. 여러 연구들이 조건부 이미지 콘텐츠 제작에 탁월한 성능을 보여주고 있다. LDM은 처음에는 생성을 위해 제안되었지만 이를 perceptual task에 사용하려는 시도가 몇 가지 있었다. 위 그림은 LDM 기반 segmentation을 위한 주류 파이프라인을 보여준다. 일반적으로 semantic guidance를 위한 텍스트 프롬프트와 LDM을 지원하는 추가 신경망에 의존한다. 그러나 전자는 실제 시나리오에서 항상 사용 가능한 것은 아니며 후자는 LDM의 자체 segmentation 능력을 탐색하는 데 방해가 된다. 이러한 보조 구성 요소에 의존하면 해당 구성 요소가 없을 때 모델 성능이 저하될 수 있다. 저자들은 LDM을 feature 추출기로 채택하는 기본 모델을 설계하고 이 가설을 테스트하였다. 또한, latent diffusion segmentation은 이러한 추가 설계 없이 segmentation 프로세스를 모델링하면 in-context segmentation 능력이 부족하다는 것을 보였다. 저자들은 in-context segmentation이 LDM의 생성 잠재력을 완전히 탐색할 수 있는 이미지 마스크 생성 프로세스로 공식화될 수 있는지 여부를 논의하였다.
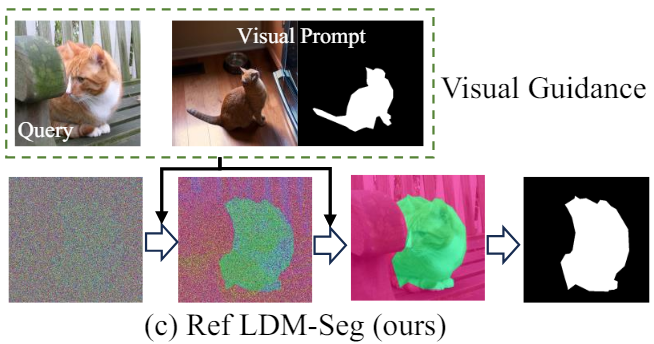
본 논문에서는 처음으로 위 그림과 같이 in-context segmentation을 위한 diffusion model의 잠재력을 탐구하였다. 본 논문은 다음과 같은 새로운 질문에 답하는 것을 목표로 한다.
- LDM이 in-context segmentation을 수행하고 충분한 결과를 얻을 수 있는가
- In-context segmentation에 가장 적합한 LDM의 메타 아키텍처는 무엇인가
- In-context instruction과 output alignment가 LDM 성능에 어떤 영향을 미치는가
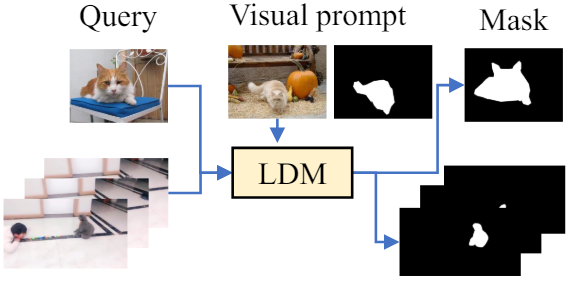
본 논문은 위의 질문을 해결하기 위해 위 그림과 같이 최소한의 LDM 기반 in-context segmentation 프레임워크인 Ref LDM-Seg를 제안하였다. Ref LDM-Seg는 후속 신경망 없이 guidance를 위해 시각적 프롬프트에 의존한다. 저자들은 instruction 추출, output alignment, 메타 아키텍처라는 세 가지 중요한 요소를 분석하였다.
먼저, 간단하지만 효과적인 instruction 추출 전략을 제안하였다. 이러한 방식으로 얻은 instruction은 효과적인 guidance를 제공할 수 있으며, 잘못된 instruction에 대한 robustness를 가진다. 다음으로 binary segmentation mask와 3채널 이미지를 정렬하기 위해 pseudo masking modeling을 통해 새로운 output alignment 타겟을 설계하였다. 그런 다음 Ref LDM-Seg-f와 Ref LDM-Seg-n이라는 두 가지 메타 아키텍처를 제안하였다. 둘은 입력 공식, denoising step, 최적화 목표가 다르다. 특히 픽셀 space와 latent space에서 Ref LDM-Seg-f에 대한 두 가지 최적화 목표를 각각 설계하였다.
실험들은 output alignment의 중요성을 보여준다. 저자들은 주로 데이터보다는 아키텍처의 영향에 중점을 두었다. 따라서 few-shot 학습 데이터셋보다 크지만 foundation model보다는 훨씬 작은 일정량의 학습 데이터를 유지하려고 하였다. 이를 위해 마지막으로 image semantic segmentation, video object segmentation, video semantic segmentation로 구성된 크기가 제한되어 있는 in-context segmentation 벤치마크를 제안하였다.
Method
LDM은 생성 task를 위해 설계되었다. Segmentation에 LDM을 적용하는 대부분의 연구에는 중간 feature 또는 불완전한 분할 결과를 처리하기 위한 후속 신경망이 필요하다. 그러나 생성 모델로서 이러한 설계를 채택한다고 해서 LDM의 생성 잠재력이 실현되는 것은 아니다. 이를 위해 저자들은 이러한 잠재력을 탐색하기 위해 최소한의 변경을 적용한 기본 모델로 Stable Diffusion을 선택했다.
Instruction Extraction
Instruction은 LDM에서 중요한 역할을 한다. 이는 프롬프트의 압축된 표현 역할을 하며 관심 영역에 초점을 맞추도록 모델을 제어하고 denoising process를 가이드한다. Stable Diffusion은 CLIP을 사용하여 텍스트 프롬프트를 instruction으로 인코딩한다. 사전 학습된 가중치를 정렬하기 위해 CLIP ViT를 프롬프트 인코더로 사용한다. Instruction들은 첫 번째 토큰을 제외한 마지막 hidden layer의 출력이다. Instruction의 차원을 변환하기 위해 linear layer를 어댑터로 사용한다. 주석 마스크 $M_s$는 cross-attention layer들에서 attention map으로 사용되어 모델이 전경 영역에 속하는 토큰에 집중하도록 한다.
\[\begin{equation} \tau = E_\tau (I_s), \quad \tau_i = F_i (\tau) \end{equation}\]여기서 $F_i$는 $i$번째 어댑터를 나타내고 $\tau_i$는 $i$번째 cross-attention layer에 해당하는 instruction들이다.
Output Alignment
Segmentation task에 LDM을 사용하므로 1채널 마스크와 3채널 이미지 간의 불일치는 무시할 수 없다. Pseudo mask는 binary segmentation mask를 향한 중간 단계로 간격을 정렬하도록 설계되어야 한다. 좋은 pseudo mask 전략이 다음 요구 사항을 충족해야 한다.
- 간단한 산술 연산을 통해 pseudo mask로부터 binary mask를 얻을 수 있다.
- Pseudo mask는 바이너리 값 이상의 정보를 제공해야 한다.
직관적인 방법은 binary mask $M$을 3채널 pseudo mask \(PM_v\)로 변환하는 매핑 규칙을 따른다.
\[\begin{equation} PM_\textrm{vi} = \begin{cases} (b, a, (a+b)/2) & \quad M_i \in \textrm{background} \\ (a, b, (a+b)/2) & \quad M_i \in \textrm{foreground} \\ \end{cases} \end{equation}\]$M_i$는 위치 $i$의 값이다. $a$, $b$는 모두 pseudo mask의 특정 채널 값을 나타내는 스칼라이며 $a < b$이다.
간단한 산술 연산으로 binary segmentation mask를 쉽게 복구할 수 있다.
\[\begin{equation} \tilde{M} = \tilde{PM}_v [1] > \tilde{PM}_v [0] \end{equation}\]여기서 $\tilde{M}$과 \(\tilde{PM}_v\)는 각각 예측된 segmentation mask와 pseudo mask이다. $[k]$는 $k$번째 채널의 값을 의미한다.
저자들은 바닐라 디자인 외에도 이미지 정보를 pseudo mask로 융합하는 augmentation 전략도 제안하였다. 이미지를 $I$라고 하면 augmented pseudo mask는 다음과 같다.
\[\begin{equation} PM_\textrm{ai} = \begin{cases} (b, a, (a+b)/2) + I_i / \alpha & \quad M_i \in \textrm{background} \\ (a, b, (a+b)/2) + I_i / \alpha & \quad M_i \in \textrm{foreground} \\ \end{cases} \end{equation}\]여기서 $\alpha$는 이미지 정보의 강도를 제어하고 $I_i$는 위치 $i$의 값이다. $\alpha > 1$이며 $a < b$이다.
간단한 산술 연산을 통해 binary segmentation mask $\tilde{M}$을 얻을 수 있다.
\[\begin{aligned} PM_a^{-} &= \tilde{PM}_a - I_i / \alpha \\ \tilde{M} &= PM_a^{-} [1] > PM_a^{-} [0] \end{aligned}\]Meta-architectures

저자들은 위 그림에서 볼 수 있듯이 Ref LDM-Seg-f와 Ref LDM-Seg-n이라는 두 가지 대표적인 메타 아키텍처를 탐색하였다. 둘 사이의 차이점은 주로 최적화 목표와 denoising timestep에 있다.
Ref LDM-Seg-f는 one-step denoising process를 나타내며 최적화 대상은 segmentation mask 자체이다. (a)에 표시된 것처럼 latent $z_q$에 noise $\epsilon_t$가 추가된다. In-context segmentation 모델인 U-Net $f$는 noisy latent $z_t = z_q + \epsilon_t$를 입력으로 사용한다. 여기서 $\epsilon_t$는 noise scheduler의 출력이고 $t$는 noise 강도를 제어한다.
사전 학습된 가중치에 대한 지식을 유지하고 치명적인 망각(catastrophic forgetting)을 피하기 위해 low-rank adaptation (LoRA) 전략을 채택한다. Attention 레이어의 $q$, $k$, $v$, $o$ projection을 제외한 모든 파라미터는 고정된다. 저자들은 모델 출력을 픽셀 space 또는 latent space의 ground truth와 정렬하는 두 가지 최적화 전략을 제안하였다. 명시적인 segmentation loss 대신 LDM에서 일반적으로 사용되는 L2 loss를 사용한다.
\[\begin{equation} \mathcal{L}_\textrm{fp} = \mathbb{E}_{z_t, \tau} [\| PM - \tilde{PM}_t \|_2^2], \quad \mathcal{L}_\textrm{fl} = \mathbb{E}_{z_t, \tau} [\| z_\textrm{pm} - \tilde{z}_t \|_2^2] \\ \textrm{where} \quad \tilde{PM}_t = \mathcal{D} (\tilde{z}_t), \quad z_\textrm{pm} = \mathcal{E} (PM) \end{equation}\]Inference 단계에서 Ref LDM-Seg-f는 한 번의 timestep만 수행하고 segmentation pseudo mask를 출력한다. 동영상은 일련의 이미지로 처리된다. 첫 번째 프레임과 해당 주석은 프롬프트로 사용되며 후속 프레임은 이를 조건으로 inference된다. 여러 카테고리가 포함된 동영상의 경우 먼저 각 카테고리의 확률을 전경으로 계산한 다음 확률이 가장 높은 카테고리를 선택한다.
\[\begin{aligned} \tilde{p}_c &= \frac{\exp (PM[1])}{\exp (PM[0])} \\ p_c &= \frac{\tilde{p}_c}{1 + \sum_{i=1}^C \tilde{p}_i} \end{aligned}\]여기서 \(\tilde{p}_c\)는 카테고리 $c$에 대한 정규화된 전경 확률 맵이다. $PM[i]$은 pseudo mask의 채널 $i$에 있는 값을 의미한다. 배경 확률인 \(\tilde{p}_0\)이 1이라는 것은 명백하다.
Ref LDM-Seg-n은 multi-step denoising process를 나타내며 간접적인 최적화 전략을 사용한다. Ref LDM-Seg-f와 달리 Gaussian noise에서 시작하여 점차적으로 noise를 제거하여 최종 segmentation mask를 얻는다.
일반 Stable Diffusion 아키텍처는 Ref LDM-Seg-n에 적합하지 않다. 따라서 입력 차원을 4에서 8로 확장하여 아키텍처에 최소한이지만 필요한 수정을 한다. 특히 쿼리 이미지와 pseudo mask의 latent 표현을 $z_q \in \mathbb{R}^{4 \times H \times W}$와 $z_\textrm{pm} \in \mathbb{R}^{4 \times H \times W}$라 하면, 채널 차원에서 noisy pseudo mask latent를 $z_q$와 concatenate하여 $z_t \in \mathbb{R}^{8 \times H \times W}$를 얻는다. Noisy pseudo mask latent는 noise $\epsilon_t$를 $z_\textrm{pm}$에 추가하여 얻는다.
\[\begin{equation} z_t = \textrm{concat} ((z_\textrm{pm} + \epsilon_t); z_q) \end{equation}\]여기서 noise scheduler가 $t$를 결정한다.
Ref LDM-Seg-f와 유사하게 in-context segmentation 모델 $f$는 latent 변수 $z_t$와 instruction $\tau$를 입력으로 사용하지만 pseudo mask가 아닌 noise 추정치를 출력한다. 또한 다음과 같이 L2 loss를 채택한다.
\[\begin{equation} \mathcal{L}_n = \mathbb{E}_{z_t, t, \tau} [\| \epsilon_t - \tilde{z}_t \|_2^2] \end{equation}\]초기 noise로 인한 랜덤성을 최소화하고 in-context instruction의 guidance를 강화하며 출력과 쿼리 간의 일관성을 유지하기 위해 classifier-free guidance (CFG)를 채택한다. 학습 단계에서 쿼리 latent $z_q$와 조건 $\tau$는 $p = 0.05$의 확률로 null 임베딩으로 랜덤하게 설정된다.
Inference 단계에서도 CFG를 채택한다. 구체적으로, Ref LDM-Seg-n은 3개의 조건부 출력 \(\tilde{z}_t (z_q, \tau)\), \(\tilde{z}_t (\varnothing, \varnothing)\), \(\tilde{z}_t (z_q, \varnothing)\)를 기반으로 \(\tilde{z}_t (z_q, \tau)\)를 출력한다.
\[\begin{aligned} \tilde{z}_t (z_q, \tau) &= \tilde{z}_t (\varnothing, \varnothing) \\ &+ \gamma_q \cdot (\tilde{z}_t (z_q, \varnothing) - \tilde{z}_t (\varnothing, \varnothing)) \\ &+ \gamma_\tau \cdot (\tilde{z}_t (z_q, \tau) - \tilde{z}_t (z_q, \varnothing)) \end{aligned}\]여기서 $\gamma_q$와 $\gamma_\tau$는 각각 쿼리와 in-context instruction의 guidance를 제어한다.
Experiments

- 데이터셋: PASCAL, COCO, DAVIS-16, VSPW
- 구현 디테일
- Stable Diffusion 1.5로 초기화 (VAE는 fine-tuning 없이 고정)
- 해상도 256$\times$256
- iteration: 80,000
- batch size: 16
- optimizer: Adam
- 프롬프트 인코더: CLIP ViT/L-14
- CFG 계수: $\gamma_q = 1.5$, $\gamma_\tau = 7$
- LoRA rank: 4
1. Study on Framework Design
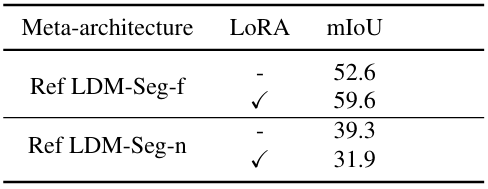
다음은 메타 아키텍처와 LoRA에 대한 효과를 비교한 표이다.
다음은 output alignment에 대한 효과를 비교한 표이다.

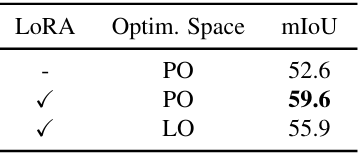
다음은 최적화 공간에 대한 효과를 비교한 표이다.
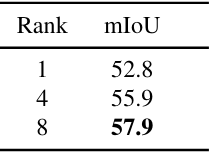
다음은 LoRA rank에 대한 효과를 비교한 표이다.
2. Study on Various Datasets
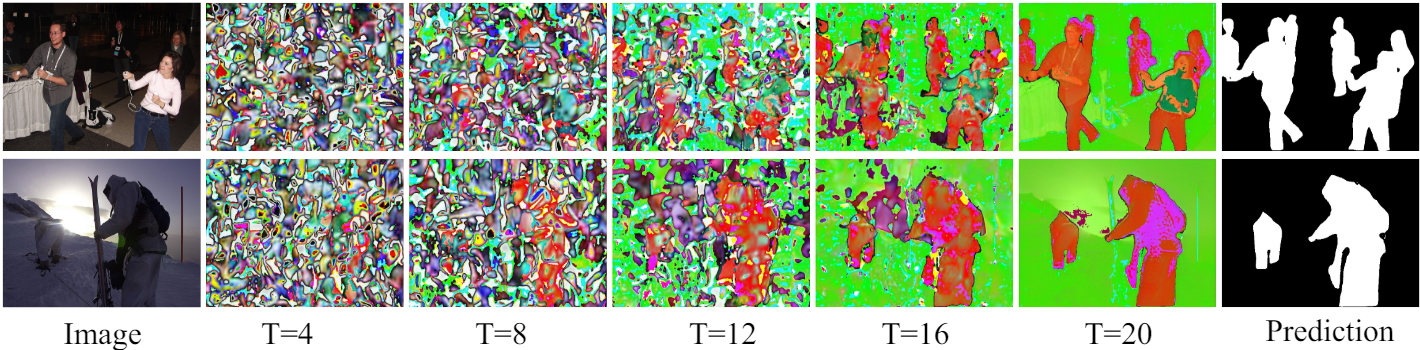
다음은 여러 timestep에 대한 Ref LDM-Seg-n의 출력을 시각화한 것이다.
다음은 여러 instruction을 조합하여 사용한 결과이다. (Ref LDM-Seg-f)

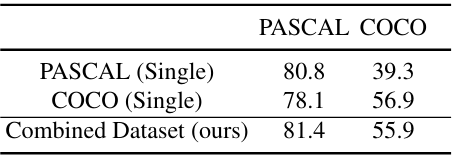
다음은 결합된 데이터셋에 대한 성능을 비교한 표이다. (Ref LDM-Seg-f)
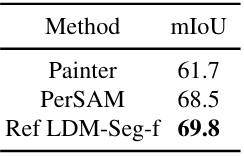
다음은 out-of-domain 데이터셋인 FSS1000에서의 성능을 비교한 표이다.
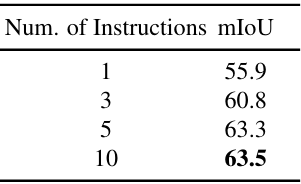
다음은 instruction 수에 따른 mIoU를 비교한 표이다.
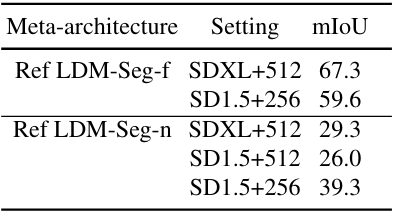
다음은 사전 학습된 가중치에 따른 효과를 비교한 표이다.
3. Comparison with Previous Methods
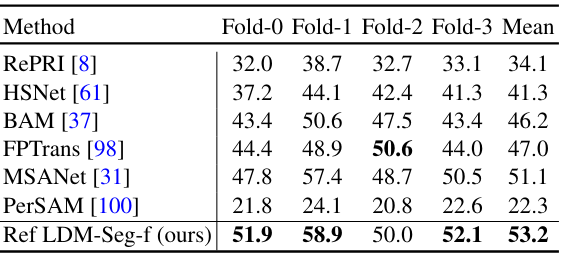
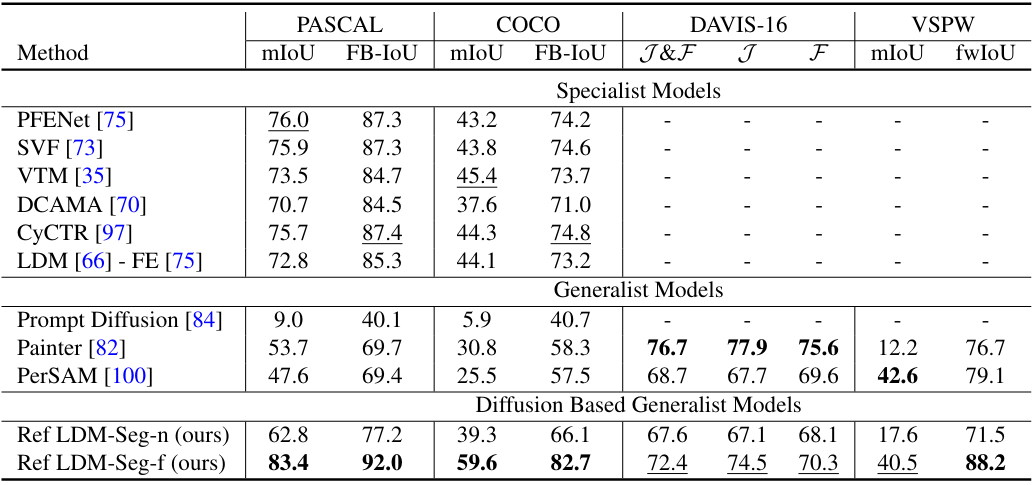
다음은 다른 방법들과 segmentation 성능을 비교한 표이다.
다음은 COCO 데이터셋에서 segmentation 결과를 시각화한 것이다. (Ref LDM-Seg-f)

다음은 VSPW 데이터셋에서 segmentation 결과를 시각화한 것이다. (Ref LDM-Seg-f)

다음은 COCO-20i 데이터셋에서 1-shot segmentation 성능(mIoU)을 비교한 표이다.