[논문리뷰] ReferDINO: Referring Video Object Segmentation with Visual Grounding Foundations
ICCV 2025. [Paper] [Page] [Github]
Tianming Liang, Kun-Yu Lin, Chaolei Tan, Jianguo Zhang, Wei-Shi Zheng, Jian-Fang Hu
Sun Yat-sen University | Southern University of Science and Technology
24 Jan 2025

Introduction
이미지-텍스트 데이터에 대한 대규모 사전 학습의 이점을 활용하는 GroundingDINO와 같은 foundation model은 object 수준의 비전-언어 이해에서 심오한 역량을 보여주었다. 그러나 이를 단순히 referring video object segmentation (RVOS)을 처리하는 데 사용하는 것은 불가능하다. 주로 두 가지 과제가 있다.
- 영역 수준 예측에 적합하게 설계된 이러한 모델은 픽셀 수준의 dense한 예측 능력이 부족하다.
- 단일 프레임에서 관찰할 수 있는 정적 속성(ex. “흰 고양이”)을 이해하는 데는 뛰어나지만 동적 속성(ex. “꼬리를 흔드는 고양이”)으로 설명되는 대상 object를 식별하지 못한다.
이러한 과제를 해결하기 위해, GroundingDINO의 정적 object 인식을 계승하고 픽셀 단위의 dense segmentation 및 시공간 추론 기능을 추가로 갖춘 강력한 end-to-end RVOS 접근 방식인 ReferDINO를 제안하였다. 먼저, 저자들은 각 프레임에서 고품질 object 마스크를 생성하기 위해 grounding-guided deformable mask decoder를 개발하였다. 단순히 원래 박스 예측 branch와 병렬로 마스크 예측 branch를 추가하는 대신, 마스크 디코더는 두 branch를 grounding-deformation-segmentation 파이프라인으로 계단식으로 연결하였다. 사전 학습된 박스 예측을 위치 prior로 활용하여 deformable attention 메커니즘을 통해 마스크 예측을 점진적으로 개선하였다. 이 프로세스는 미분 가능하므로 마스크 학습이 박스 예측 branch로 피드백될 수 있다.
또한, 시간적 cross-modal 추론을 위해 시간에 따라 달라지는 사전 학습된 텍스트 feature를 프레임 간 상호작용에 주입하는 object-consistent temporal enhancer를 제시하였다. 이 두 모듈은 visual grounding과 RVOS 간의 격차를 메우기 위해 함께 작동하며, visual grounding foundation model과 기존 RVOS 방법의 한계를 효과적으로 극복하였다.
기존 foundation model의 또 다른 한계는 막대한 연산 오버헤드이다. 이 문제를 해결하기 위해, 신뢰도가 낮은 object query를 점진적으로 식별하고 제거함으로써 사전 학습된 지식을 손상시키지 않고 프레임당 연산량을 줄이는 confidence-aware query pruning 전략을 제안하였다.
ReferDINO는 5가지 RVOS 벤치마크에서 SOTA를 달성하였으며, 기존 방법보다 41.3% 적은 메모리를 사용하는 동시에 10배 빠른 속도로 작동한다.
Background: GroundingDINO
본 논문의 접근 방식은 visual grounding foundation model인 GroundingDINO를 기반으로 한다. GroundingDINO는 DETR 기반 object detector로, object detector에 언어를 도입하여 visual grounding을 구현하였다. 주로 이미지 backbone, 텍스트 backbone, cross-modal 인코더-디코더 Transformer 아키텍처, box head, classification head로 구성된다. 이미지-텍스트 쌍이 주어졌을 때, GroundingDINO의 작동 방식은 다음과 같다.
- 이중 backbone을 채택하여 기본 feature들을 추출한다.
- 기본 feature들을 cross-modal 인코더에 입력하여 향상된 이미지 feature \(\textbf{F}_\textrm{img}\)와 향상된 텍스트 feature \(\textbf{F}_\textrm{text}\)를 도출한다.
- 향상된 cross-modal feature는 query 임베딩 $\mathcal{Q}$를 초기화하는 데 사용되며, query 임베딩은 개별적으로 cross-modal 디코더에 입력되어 object feature $\mathcal{O}$를 생성한다.
- 각 object feature는 box head와 classification head로 전달되어 bounding box와 점수를 예측한다. 여기서 점수는 각 object feature와 텍스트 토큰 간의 유사도로 정의된다. RVOS의 경우, binary classification 확률을 모든 토큰에 대한 최대 점수로 정의한다.
Method
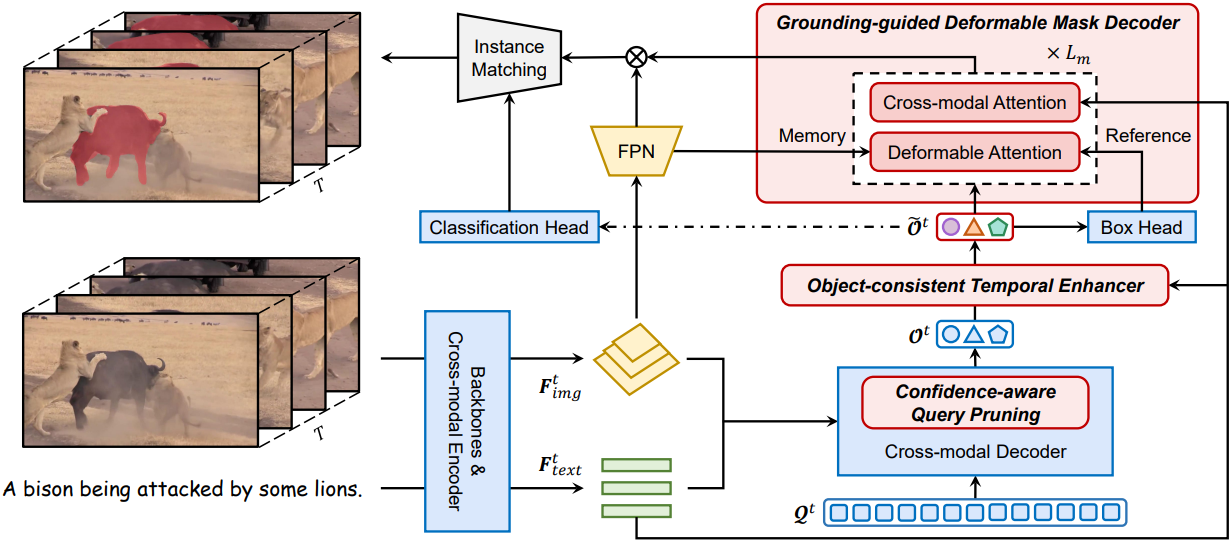
GroundingDINO 외에도, 모델은 세 가지 주요 구성 요소로 구성된다.
- Grounding-guided deformable mask decoder
- Object-consistent temporal enhancer
- Confidence-aware query pruning
$T$ 프레임의 동영상과 언어 query가 주어졌을 때, 모델의 전체 작동 방식은 다음과 같다.
- GroundingDINO를 각 프레임에 개별적으로 적용하여 object feature를 얻는다.
- 프레임별 효율성을 향상시키기 위해 confidence-aware query pruning을 사용하여 신뢰도가 낮은 object query를 점진적으로 제거함으로써 매우 간결한 object feature 집합을 얻는다.
- 모든 프레임의 object feature를 수집하고, object-consistent temporal enhancer를 사용하여 시간적 cross-modal 추론을 수행하고 시간 일관성을 보장한다.
- Grounding-guided deformable mask decoder를 사용하여 각 object의 박스 예측을 위치 조건으로 deformable cross-attention과 cross-modal attention을 통해 object feature를 점진적으로 개선한다.
- 각 object에 해당하는 출력 feature와 프레임별 feature map을 내적하여 마스크 시퀀스 \(\{\textbf{m}^t\}_{t=1}^T\)을 생성한다.
1. Grounding-guided Deformable Mask Decoder
이 디코더는 object feature를 입력으로 받아 각 프레임에 대해 픽셀 단위 예측을 생성한다. 단순히 원래 box head에 mask head를 병렬로 추가하는 대신, 마스크 디코더는 박스 및 마스크 예측을 grounding-deformation-segmentation 파이프라인으로 구성한다. Box 예측을 위치 정보로 활용하여 마스크 예측을 반복적으로 향상시키고, 텍스트 프롬프트를 통합하여 더욱 정교하게 개선한다. 이 과정은 미분 가능하므로 마스크 학습이 box head로 피드백된다.
임의의 object feature를 $\tilde{\textbf{o}}$라 하자. 마스크 디코더에 앞서, o˜를 box head에 입력하여 bounding box $\textbf{b} \in \mathbb{R}^4$를 예측한다. 여기서 \(\textbf{b} = \{b_x, b_y, b_w, b_h\}\)는 정규화된 박스 중심 좌표, 박스 높이와 너비를 인코딩한다. 한편, \(\textbf{F}_\textrm{img}\)에 feature pyramid network(FPN)를 적용하여 고해상도 feature map \(\textbf{F}_\textrm{seg} \in \mathbb{R}^{\frac{H}{4} \times \frac{W}{4} \times d}\)를 생성한다.
그런 다음, 이러한 feature와 박스 예측을 object 정제 및 마스크 생성을 위해 마스크 디코더에 입력한다. 마스크 디코더는 $L_m$개의 block으로 구성되며, 각 block은 deformable cross-attention과 cross-modal attention으로 구성된다. 이미지 feature map(메모리)에 attention을 적용할 때, deformable cross-attention은 레퍼런스 포인트 주변의 작은 샘플링 포인트 집합을 적응적으로 샘플링하여 feature를 집계한다. MLP를 통해 레퍼런스 포인트를 생성하는 일반적인 deformable cross-attention과 달리, 예측된 박스 중심 \(\{b_x, b_y\}\)를 레퍼런스 포인트로 직접 사용한다.
구체적으로, $\tilde{\textbf{o}}$를 query로, \(\textbf{F}_\textrm{seg}\)를 메모리로, 정규화된 박스 중심 \(\{b_x, b_y\}\)를 레퍼런스 포인트로 취급한다. 샘플링 프로세스는 bilinear interpolation으로 구현되므로 end-to-end로 미분 가능하다. 이러한 방식으로 사전 학습된 grounding 지식이 자연스럽게 통합되어 마스크 예측을 정제하고, segmentation의 gradient가 object grounding을 최적화하는 데에도 사용된다.
적응적 샘플링 과정에서 노이즈가 많은 feature가 포함될 수 있는데 (ex. 배경), 이는 마스크 품질을 저하시킬 수 있다. 이를 완화하기 위해 $\tilde{\textbf{o}}$를 query로, \(\textbf{F}_\textrm{text}\)를 key와 value로 사용하여 cross-modal attention을 적용하여 텍스트 조건을 통합한다. 이 두 attention 메커니즘은 마스크 예측이 텍스트 프롬프트 및 object 위치와 밀접하게 결합되도록 함께 작동한다. 마지막으로, 각 object query에 대해 정제된 마스크 임베딩 \(\textbf{o}_m \in \mathbb{R}^d\)를 구하고, 이를 고해상도 feature map \(\textbf{F}_\textrm{seg}\)와 내적하여 인스턴스 마스크 $\textbf{m}$을 생성한다.
Discussion
Dynamic mask head는 feature map과 각 object의 상대적 좌표를 개별적으로 concat하여 object 위치 정보를 마스크 예측에 통합하며, 이는 여러 연구에서 채택되었다. 그러나 이 접근 방식은 object별 고해상도 feature map의 저장 공간 요구로 인해 메모리 비용이 매우 높다. 특히 일반적으로 많은 object query를 사용하는 foundation model에서는 이러한 비용이 매우 높다.
이와 대조적으로, 본 논문에서 제안하는 마스크 디코더는 공유 feature map에서 위치 기반 샘플링을 통해 다양한 object의 위치 정보를 효율적으로 통합한다. 이러한 설계는 추가적인 메모리 부담을 필요로 하지 않으므로 foundation model 적응에 특히 적합하다.
2. Object-consistent Temporal Enhancer
GroundingDINO는 하나의 이미지에서 레퍼런스 object를 감지할 수 있지만, RVOS에서는 충분히 신뢰할 수 없다.
- 설명의 동적 속성을 이해하지 못한다.
- 동영상 프레임에는 카메라 모션 블러와 제한된 시점이 포함되는 경우가 많아 시간적 일관성이 크게 저하된다.

따라서 저자들은 시간적 cross-modal 추론을 가능하게 하는 object-consistent temporal enhancer를 도입하였다. 이 모듈은 memory-augmented tracker와 cross-modal temporal decoder로 구성된다. 모듈은 모든 object embedding \(\{\mathcal{O}^t\}_{t=1}^T\)와 시간에 따라 변하는 문장 feature \(\{\textbf{f}_\textrm{cls}^t\}_{t=1}^T\)를 입력으로 받는다. \(\textbf{f}_\textrm{cls}^t\)는 \(\textbf{F}_\textrm{text}^t\)의 [CLS] 토큰에 해당한다.
Memory-augmented Tracker
시간적 상호작용 전에, tracker 메커니즘을 사용하여 여러 프레임에 걸쳐 object를 정렬한다. \(\mathcal{M}^t\)를 $t$번째 프레임의 메모리라 하고, \(\mathcal{M}^1 = \mathcal{O}^1\)이라 하자. Tracker는 object 정렬과 메모리 업데이트의 두 단계로 구성된다. 첫 번째 단계에서는 \(\mathcal{M}^{t-1}\)과 \(\mathcal{O}^t\) 사이의 코사인 유사도를 assignment cost로 계산하고, Hungarian 알고리즘을 적용하여 object를 메모리에 정렬한다.
\[\begin{equation} \hat{\mathcal{O}}^t = \textrm{Hungarian} (\mathcal{M}^{t-1}, \mathcal{O}^t) \end{equation}\]두 번째 단계에서는 정렬된 object embedding \(\hat{\mathcal{O}}^t\)을 사용하여 메모리를 모멘텀 방식으로 업데이트한다. 한편, object에 표시되지 않는 프레임이 메모리를 방해하지 않도록 텍스트 관련성을 통합한다.
\[\begin{equation} \mathcal{M}^t = (1 - \alpha \cdot \textbf{c}^t) \cdot \mathcal{M}^{t-1} + \alpha \cdot \textbf{c}^t \cdot \hat{\mathcal{O}}^t \end{equation}\]($\alpha$는 모멘텀 계수, \(\textbf{c} \in \mathbb{R}^{N_s}\)는 \(\hat{\mathcal{O}}^t \in \mathbb{R}^{N_s \times d}\)와 \(\textbf{f}_\textrm{cls}^t \in \mathbb{R}^d\) 사이의 코사인 유사도)
Cross-modal Temporal Decoder
이 모듈은 시간에 따라 변하는 텍스트 임베딩을 사용하여 프레임 간 상호작용 및 시간적 향상을 수행한다. 구체적으로, 이 모듈은 $L_t$개의 block으로 구성된다. 각 block에서 정렬된 object embedding \(\{\hat{\mathcal{O}}^t\}_{t=1}^T\)와 문장 임베딩 \(\{\textbf{f}_\textrm{cls}^t\}_{t=1}^T\)가 주어지면, 시간 차원에 따라 self-attention을 사용하여 프레임 간 상호작용을 구현한다. 다음으로, cross-attention 모듈을 사용하여 동적 정보를 추출한다. 이 모듈은 문장 임베딩을 query로, object embedding을 key와 value로 사용하여 시간적으로 향상된 object feature \(\{\mathcal{O}_v^t\}_{t=1}^T\)을 도출한다. 효과적인 시간 정보를 포함하는 \(\{\mathcal{O}_v^t\}_{t=1}^T\)는 다음과 같이 프레임별 object embedding을 향상시키는 데 사용된다.
\[\begin{equation} \tilde{\mathcal{O}}^t = \textrm{LayerNorm}(\hat{\mathcal{O}}^t + \mathcal{O}_v^t) \end{equation}\]Discussion
본 논문의 temporal enhancer는 두 가지 측면에서 RVOS 모델의 기존 시간 모듈을 개선한다.
- 기존 방법들은 object tracking을 무시하거나 인접 프레임에서만 tracking하는 반면, 본 논문에서는 안정적인 장기적 일관성을 위해 memory-augmented tracker를 사용한다.
- 시간적 cross-modal 상호작용에서 기존 방법들은 서로 다른 프레임의 모든 object에 대해 텍스트 인코더의 정적 텍스트 임베딩을 사용하는 반면, 본 논문의 temporal enhancer는 시간에 따라 변하는 텍스트 임베딩을 사용하여 세밀한 시간 역학을 더욱 효과적으로 포착한다.
이 두 가지 설계를 통해 본 논문의 temporal enhancer는 효과적인 시공간 추론 및 object 일관성을 위해 foundation model의 사전 학습된 object 지식과 cross-modal feature를 최대한 활용한다.
3. Confidence-aware Query Pruning
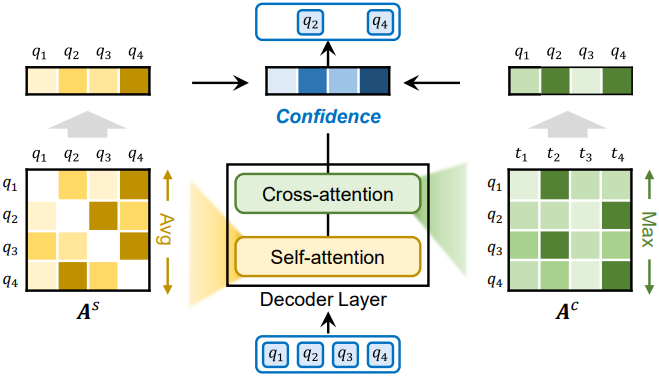
Visual grounding foundation model은 일반적으로 방대한 object 정보를 저장하기 위해 대량의 query 임베딩을 활용한다. 예를 들어, GroundingDINO는 $N_q = 900$개의 query를 사용한다. 이처럼 방대한 양의 query를 반복적으로 처리하면 특히 동영상 처리에서 효율성이 크게 저하된다. 그러나 이러한 query를 직접 줄이면 잘 사전 학습된 object 지식이 손상될 수 있다. 저자들은 이러한 딜레마를 해결하기 위해, 각 디코더 레이어에서 신뢰도가 낮은 query를 점진적으로 식별하고 제거하는 신뢰도 기반 query pruning 전략을 설계했다.
구체적으로, cross-modal 디코더는 $L$개의 레이어로 구성되며, 각 레이어는 self-attention, 이미지 feature를 사용하는 cross-attention, 텍스트 feature를 사용하는 cross-attention으로 구성된다. \(\textbf{Q}_l \in \mathbb{R}^{N_l \times d}\)를 $l$번째 디코더 레이어의 출력 query 임베딩이라 하자. 여기서 $N_0 = N_q$이다. 디코더 레이어의 attention 가중치를 재사용하여 각 query에 대한 신뢰도 점수를 다음과 같이 계산한다.
\[\begin{equation} s_j = \frac{1}{N_l - 1} \sum_{i=1, i \ne j}^{N_l} \textbf{A}_{ij}^s + \max_k \textbf{A}_{kj}^c \end{equation}\]($s_j$는 $j$번째 query의 신뢰도, \(\textbf{A}^s \in \mathbb{R}^{N_l \times N_l}\)은 self-attention 가중치, \(\textbf{A}^c \in \mathbb{R}^{K \times N_l}\)은 $K$개의 텍스트 토큰에 대한 transpose된 cross-attention 가중치)
첫 번째 항은 $j$번째 query가 다른 query로부터 받는 평균 attention을 나타낸다. 다른 query로부터 높은 attention을 받는 query는 일반적으로 대체 불가능함을 의미한다. 두 번째 항은 $j$번째 object query가 텍스트에서 언급될 확률을 측정한다. 이 두 항의 조합은 query 중요도를 종합적으로 반영한다.
이 점수를 기반으로 각 레이어에서 $1/k$의 고신뢰도 object query만을 유지하여 최종적으로 $N_q$보다 훨씬 적은 수의 $N_s$개의 object embedding으로 구성된 컴팩트한 세트를 생성한다. 이 전략은 사전 학습된 object 지식을 보존하는 동시에 계산 비용을 크게 줄여 ReferDINO가 실시간 효율성을 달성할 수 있도록 한다.
시간 복잡도 분석
$N = N_q$일 때, 원래 디코더의 총 시간 복잡도는 $O (L(N^2 d + N d^2))$이다. 레이어당 $1/k$의 query만 유지하는 경우 총 query 수는 기하급수적으로 감소하고 총 시간 복잡도는 디코더 깊이 $L$에 관계없이
\[\begin{equation} O((\frac{k^2}{k^2 - 1}) N^2 d + (\frac{k}{k-1}) N d^2) \end{equation}\]가 된다. 실제로 이러한 계산적 개선은 상당하다. $N = 900$, $L = 6$, $d = 256$인 GroundingDINO의 경우 $k = 2$일 때에도 디코더 계산 비용을 24.7%까지 줄일 수 있다.
4. Training and Inference
ReferDINO는 궁극적으로 동영상-텍스트 쌍에 대해 $N_s$개의 object 예측 시퀀스 \(\textbf{p} = \{\textbf{p}_i\}_{i=1}^{N_s}\)을 생성하고 각 시퀀스는 \(\textbf{p}_i = \{\textbf{c}_i^t, \textbf{b}_i^t, \textbf{m}_i^t\}_{t=1}^T\)로 표현된다. 각각 $t$번째 프레임의 $i$번째 object query에 대한 binary classification 확률, bounding box, 마스크를 나타낸다.
학습
GT object 시퀀스를 \(\textbf{y} = \{\textbf{c}^t, \textbf{b}^t, \textbf{m}^t\}_{t=1}^T\)라고 하자. 기존 방법들을 따라 인스턴스 매칭에 Hungarian 알고리즘을 적용한다. 구체적으로, 매칭 비용이 가장 낮은 인스턴스 시퀀스를 positive로 선택하고 나머지 시퀀스를 negative로 지정한다. 매칭 비용은 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_\textrm{total} (\textbf{y}, \textbf{p}_i) = \lambda_\textrm{cls} \mathcal{L}_\textrm{cls} (\textbf{y}, \textbf{p}_i) + \lambda_\textrm{box} \mathcal{L}_\textrm{box} (\textbf{y}, \textbf{p}_i) + \lambda_\textrm{mask} \mathcal{L}_\textrm{mask} (\textbf{y}, \textbf{p}_i) \end{equation}\]이 매칭 비용은 개별 프레임에서 계산되고 프레임 수로 정규화된다. \(\lambda_\textrm{cls}\)는 binary classification 예측에 대한 focal loss이다. \(\mathcal{L}_\textrm{box}\)는 L1 loss와 GIoU loss의 합이다. \(\mathcal{L}_\textrm{mask}\)는 DICE loss, binary mask focal loss, projection loss의 조합이다. 이 모델은 positive 시퀀스의 총 loss \(\mathcal{L}_\textrm{total}\)을 최소화하고 negative 시퀀스의 \(\lambda_\textrm{cls}\)만 최소화하여 end-to-end로 최적화된다.
Inference
Inference 단계에서는 다음과 같이 가장 높은 평균 classification 점수를 가진 최상의 시퀀스를 선택한다.
\[\begin{equation} \sigma = \underset{i \in [1, N_s]}{\arg \max} \frac{1}{T} \sum_{t=1}^T \textbf{c}_i^t \end{equation}\]출력 마스크 시퀀스는 \(\{\textbf{m}_\sigma^t\}_{t=1}^T\)로 형성된다.
Experiments
- 데이터셋: Ref-YouTube-VOS, Ref-DAVIS17, A2D-Sentences, JHMDB-Sentences
- 구현 디테일
- 이미지 backbone: Swin Transformer
- 텍스트 backbone: BERT
- backbone을 고정하고 cross-modal Transformer를 LoRA로 fine-tuning
- $\alpha = 0.1$, $L_t = 3$, $L_m = 3$
- 샘플링 포인트 개수: 16
- Query pruning 제거 비율: 50%
- threshold $\sigma = 0.3$
1. Main Results
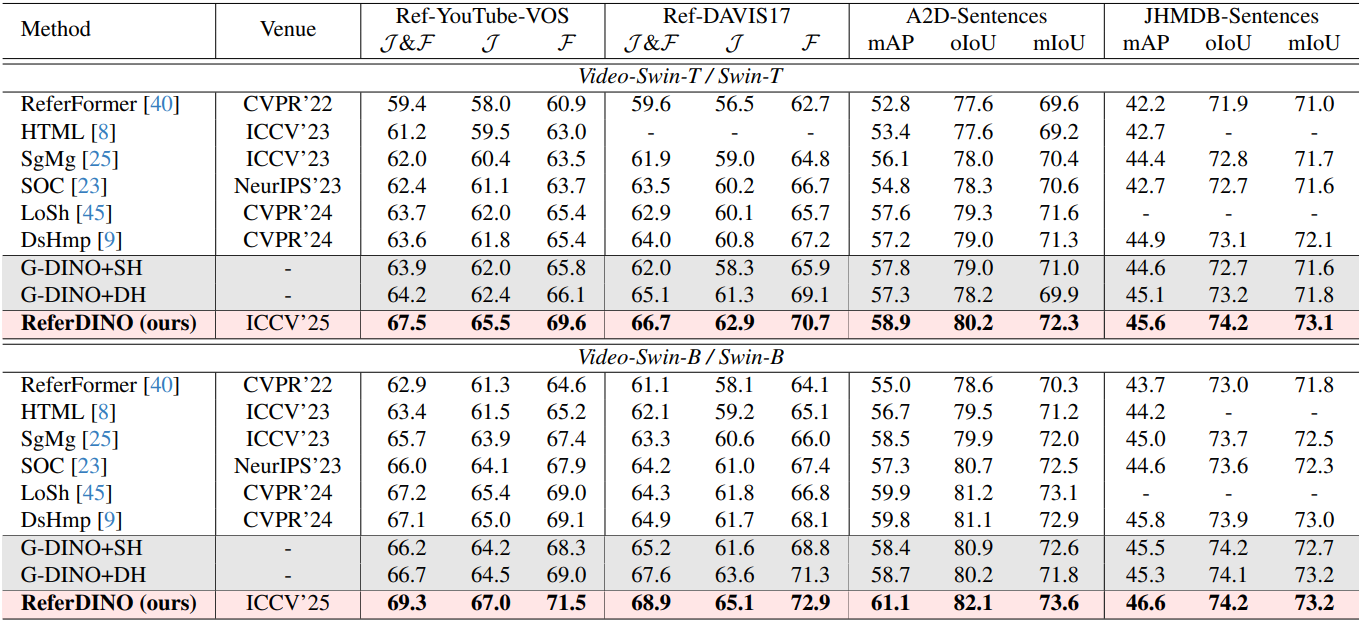
다음은 Ref-YouTube-VOS, Ref-DAVIS17, A2D-Sentences, JHMDB-Sentences에서의 성능 비교 결과이다.
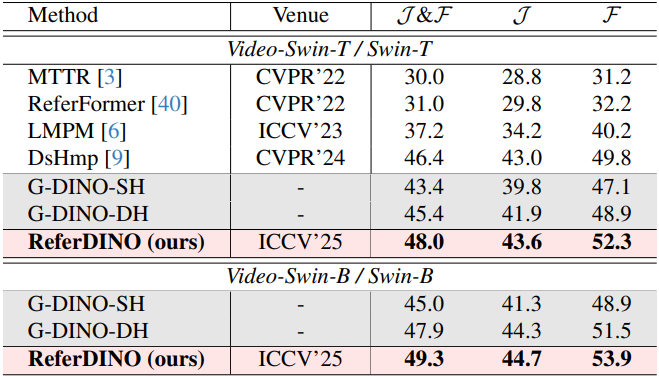
다음은 MeViS에서의 성능 비교 결과이다.
2. Ablation Studies
다음은 마스크 디코더에 대한 ablation study 결과이다. (MeViS)

다음은 temporal enhancer에 대한 ablation study 결과이다. (MeViS)

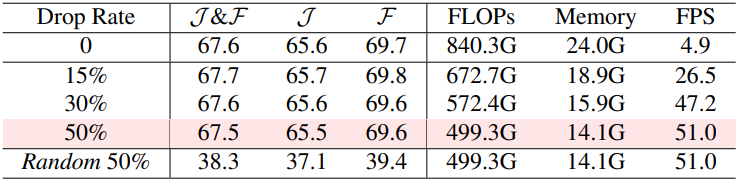
다음은 query pruning에 대한 ablation study 결과이다. (Ref-YouTube-VOS)
3. Qualitative Analysis
다음은 SOTA 방법과 비교한 예시들이다.

다음은 여러 텍스트 시퀀스에 대한 ReferDINO의 결과를 시각화한 것이다.
