[논문리뷰] Ref-Diff: Zero-shot Referring Image Segmentation with Generative Models
arXiv 2023. [Paper]
Minheng Ni, Yabo Zhang, Kailai Feng, Xiaoming Li, Yiwen Guo, Wangmeng Zuo
Harbin Institute of Technology | Pengcheng Laboratory
31 Aug 2023
Introduction
Referring Image Segmentation (RIS)은 주어진 텍스트 설명과 의미상 일치하는 참조 인스턴스 영역을 식별하는 것을 목표로 한다. Semantic segmentation과는 달리 이 task에는 종종 동일한 클래스의 구별되는 인스턴스가 필요하다. 정확한 쌍에 대한 주석을 작성하는 데는 비용과 시간이 많이 소요된다. 최근 weakly-supervised RIS 접근 방식은 주석의 어려움을 완화하기 위해 노력하지만 여전히 학습을 위해 특정 이미지 쌍과 참조 텍스트가 필요하다. 반대로, zero-shot 솔루션은 더 가치가 있지만 문제를 더욱 악화시킬 수 있다. 한편으로는 학습이 필요 없으며 참조 주석이 필요하지 않다. 반면에 텍스트와 이미지의 시각적 요소 사이의 관계에 대한 더 깊은 이해가 필요하다.
최근의 멀티모달 사전 학습 모델은 시각 및 언어 이해 분야에서 인상적인 능력을 보여주었다. 그 중 가장 대표적인 판별 모델 중 하나인 CLIP은 object detection, 이미지 검색, semantic segmentation을 포함한 다양한 task에서 상당한 개선을 보여주었다. 그러나 CLIP과 같은 모델을 zero-shot RIS에 직접 적용하는 것은 비실용적이다. 이는 참조 텍스트와 관련된 특정 시각적 요소를 잘 학습할 수 없는 텍스트와 이미지의 글로벌 유사성을 캡처하도록 학습되었기 때문이다.
이를 해결하기 위해 판별 모델과 픽셀 수준의 밀도 예측 간의 격차를 해소하기 위한 Global-Local CLIP이 제안되었다. 그럼에도 불구하고 저자들은 판별적 모델 자체가 시각적 요소를 정확하게 위치화하는 데 어려움을 겪고 있음을 관찰하였다. 최근에는 Stable Diffusion, DALL-E 2, Imagen과 같은 생성 모델도 사실적이거나 상상적인 이미지를 생성하는 능력으로 인해 큰 주목을 받고 있다. 생성된 이미지의 semantic 정렬은 이러한 생성 모델이 다양한 시각적 요소와 텍스트 간의 관계를 암시적으로 포착했음을 보여준다. 그러나 판별 모델과 달리 zero-shot RIS task에서는 거의 활용되지 않았다.
본 논문에서는 생성 모델이 zero-shot RIS task에 도움이 될 수 있는지 조사하였다. 이를 위해 새로운 Referring Diffusional segmentor (Rer-Diff)를 제안하였다. 생성 모델의 세밀한 멀티모달 정보를 활용하여 참조 표현과 이미지의 다양한 시각적 요소 간의 관계를 활용한다. 이전 연구들에서는 일반적으로 오프라인 proposal generator에서 proposal 순위를 매기기 위해 CLIP을 채택했다. 대조적으로 Rer-Diff는 본질적으로 생성 모델을 사용하여 이러한 instance proposal을 제공할 수 있다. 이는 Ref-Diff가 반드시 다른 proposal generator에 의존하지 않는다는 것을 나타낸다.
세 가지 데이터셋에 대한 실험에서는 오프라인 proposal generator를 사용하지 않고 Ref-diff의 생성 모델만으로 SOTA weakly-supervised 방법에 비해 비슷한 성능을 달성하였다. 또한 오프라인 proposal generator와 판별 모델을 통합할 때 Ref-Diff는 다른 방법들보다 훨씬 뛰어난 성능을 발휘하였다.
Methodology
1. Problem Formulation and Inference Pipeline
이미지 $x \in \mathbb{R}^{W \times H \times C}$와 참조 텍스트 $T$가 주어지면 referring segmentation은 이미지 $x$에서 텍스트 $T$의 참조 영역을 나타내는 segmentation mask \(m \in \{0, 1\}^{W \times H}\)를 출력하는 것을 목표로 한다. 여기서 $W$, $H$, $C$는 각각 이미지의 너비, 높이, 채널을 나타낸다. Zero-shot referring segmentation 설정에서 모델은 이미지, 참조 텍스트, 인스턴스 마스크 주석을 포함하여 referring segmentation의 학습 데이터에 액세스할 수 없다.
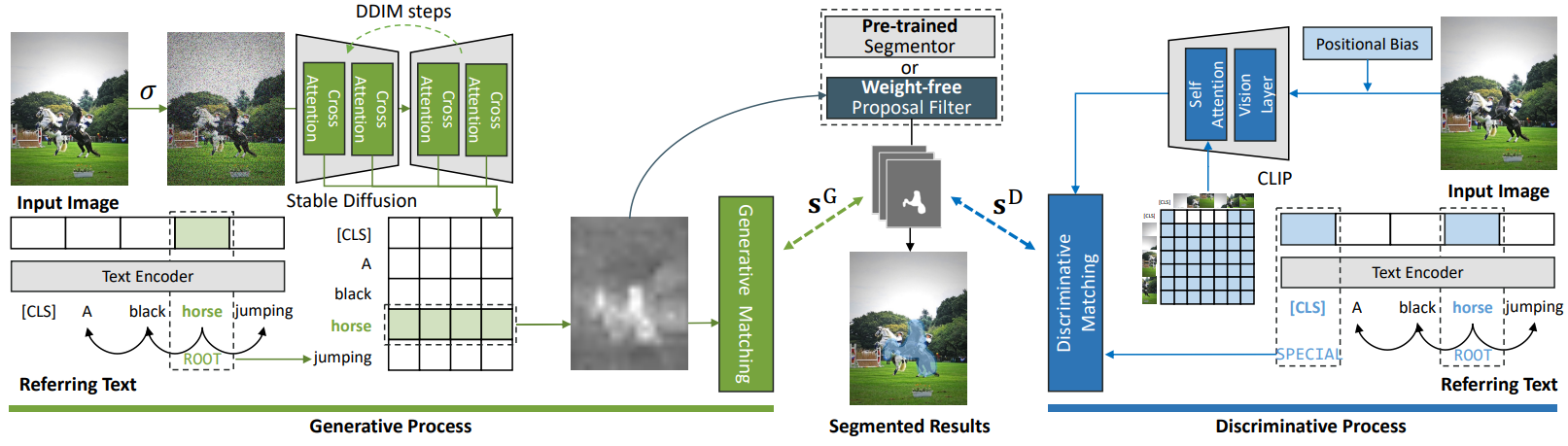
본 논문이 제안한 프레임워크는 위 그림에 나와 있다. 이미지와 참조 텍스트가 주어지면 Ref-Diff는 생성 프로세스를 사용하여
- 가중치 없는 proposal generator
- referring segmentation 후보의 집합
으로 사용할 수 있는 상관 행렬을 생성한다. 선택적으로 Ref-Diff는 판별 모델을 통합 프레임워크 내에서 제안된 생성 모델과 통합할 수 있다. 각 mask proposal의 최종 유사도는 다음과 같이 얻을 수 있다.
\[\begin{equation} s_i = \alpha s_i^G + (1 - \alpha) s_i^D \end{equation}\]여기서 $\alpha$는 hyperparamter이다. $s_i^G$와 $s_i^D$는 각각 참조 텍스트와 $i$번째 proposal 간의 생성 점수와 판별 점수이다. $\alpha$를 1로 설정하면 생성 모델만 채택된다. 최종 referring segmentation 결과는 유사도 점수가 가장 높은 proposal을 선택하여 결정된다.
\[\begin{equation} \hat{m} = \underset{\mathcal{M}_i}{\arg \max} s_i \end{equation}\]2. Generative Process
Stable Diffusion은 랜덤 Gaussian noise를 이미지로 점진적으로 변환하는 일련의 inverse diffusion step으로 구성된 효과적인 생성 모델이다. 따라서 실제 이미지를 직접 조작하여 latent 표현을 얻을 수 없다. 다행히도 diffusion process가 계산 가능하므로 실제 이미지를 diffusion model에 의해 생성된 하나의 중간 상태로 가져와 생성의 모든 단계로 거꾸로 실행할 수 있다. 본 논문에서는 특정 양의 Gaussian noise를 추가하여 $x_t$를 얻은 다음 정보를 손상시키지 않고 이 프로세스를 계속한다.
\[\begin{equation} x_t = \sigma_t (x) \end{equation}\]여기서 $\sigma_t$는 step $t$에서 noisy한 이미지를 얻는 함수이고 $t$는 hyperparamter이다.
Reverse process에서 \(\Psi_\textrm{lan}\)과 \(\Psi_\textrm{vis}\)를 각각 생성 모델의 텍스트 인코더와 이미지 인코더라 하자. 생성 모델에서 참조 텍스트 $T$는 \(K = \Psi_\textrm{lan}(T) \in \mathbb{R}^{l \times d}\)를 사용하여 텍스트 feature로 인코딩된다. 여기서 $l$은 토큰 수이고 $d$는 latent projection을 위한 차원 크기이다. 마찬가지로 $i$번째 step에서는 시각적 이미지 $x_i$가 \(Q = \Psi_\textrm{vis}(x_i) \in \mathbb{R}^{w \times h \times d}\)를 사용하여 이미지 feature에 project된다. 여기서 $w$와 $h$는 인코딩된 이미지 feature의 너비와 높이이다. 텍스트 feature와 이미지 feature 간의 cross-attention은 다음과 같이 쓸 수 있다.
\[\begin{equation} a = \textrm{Softmax} (\frac{QK^\top}{\sqrt{d}}) \in \mathbb{R}^{w \times h \times l \times N} \end{equation}\]여기서 $N$은 attention head의 수이다. 각 attention head의 값을 $\bar{a} \in \mathbb{R}^{w \times h \times l}$로 평균화하여 전체 cross-attention을 얻는다. Cross-attention 행렬 $a$는 참조 텍스트의 각 토큰과 이미지의 각 영역 feature 간에 감지된 상관 관계를 나타낸다. 일반적으로 $a$의 값이 높을수록 관련 참조 영역을 찾는 데 사용할 수 있는 토큰과 영역 feature 간의 상관 관계가 더 좋다는 것을 나타낸다.
Reverse process에서 생성 모델은 언어 조건의 전반적인 semantic을 포착한다. 그러나 각 토큰에 해당하는 attention 영역은 semantic 표현이 다르기 때문에 반드시 동일하지는 않다. 일반성을 잃지 않고 참조 텍스트 $T$가 특정 인스턴스의 특성을 설명하는 문장이라고 하자. 전체 텍스트 설명에서 기본 토큰을 얻으려면 구문 분석 (syntax analysis)을 사용하여 루트 토큰 (즉, syntax tree의 ROOT 요소)을 얻는다. 일반적으로 latent space의 ROOT 토큰은 문맥상 상관관계를 포착한다. 그러면 이 루트 토큰에 대해 예상되는 관심 영역이 추천 영역일 가능성이 더 높다. $k$를 루트 토큰의 인덱스라 하면, \(\bar{a}_k \in \mathbb{R}^{w \times h}\)를 루트 토큰의 cross-attention 행렬을 나타낸다. 다음 식을 사용하여 이 cross-attention 행렬을 정규화하고 resize한다.
\[\begin{equation} c = \phi_{w \times h \rightarrow W \times H} \bigg( \frac{\bar{a}_k - \min (\bar{a}_k)}{\max (\bar{a}_k) - \min (\bar{a}_k) + \epsilon} \bigg) \end{equation}\]여기서 $\epsilon$은 작은 상수 값이다. \(\phi_{w \times h \rightarrow W \times H}\)는 attention map의 크기를 주어진 이미지와 동일한 해상도로 조정하는 데 사용되는 bi-linear interpolation 함수이다.
3. Discriminative Process
판별 모델 CLIP에 의한 이미지 인코딩 프로세스에서 공간 위치는 필연적으로 약화된다. 저자들은 참조 텍스트 설명에는 일반적으로 가치가 있지만 이전 연구들에서는 무시되었던 명시적인 방향 단서 (ex. 왼쪽, 오른쪽, 위쪽, 아래쪽)가 포함되어 있음을 관찰하였다. 이러한 유형의 위치 정보를 강조하기 위해 주어진 방향 단서를 사용하여 이미지를 명시적으로 인코딩하는 위치 바이어스를 제안하였다. 이는 element-wise 곱셈을 통해 계산할 수 있다.
\[\begin{equation} x^\prime = x \odot P, \quad P \in \mathbb{R}^{W \times H \times C} \end{equation}\]여기서 $P \in \mathbb{R}^{W \times H \times C}$는 위치 바이어스 행렬이다. 특히, 구문 분석 후 텍스트에 명시적인 방향 단서가 포함되어 있는 경우 $P$는 지정된 방향 축을 따라 1에서 0 사이의 값을 갖는 소프트 마스크가 된다. 값이 낮을수록 관심을 덜 받아야 하는 영역을 나타낸다. 반대로 방향 단서가 감지되지 않으면 $P$는 1로 채워진 행렬이 된다.
마지막으로, 판별 프로세스에서 각 proposal \(\mathcal{M}_i\)에 대한 최종 표현 $v_i \in \mathbb{R}^d$는 다음과 같다.
\[\begin{equation} v_i = \beta f_{\mathcal{M}_i} (x \odot P) + (1 - \beta) f (x \odot \mathcal{M}_i) \end{equation}\]여기서 $f$와 \(f_{\mathcal{M}_i}\)는 각각 바닐라 CLIP 이미지 인코더와 mask proposal \(\mathcal{M}_i\)를 기반으로 수정된 self-attention을 갖춘 CLIP 이미지 인코더이다. 판별 모델 (즉, CLIP)은 교란을 줄이기 위해 다른 영역을 무시하고 각 proposal 영역 \(\mathcal{M}_i\) 내의 인스턴스를 인코딩할 것으로 예상된다. 이를 위해 현재 proposal \(\mathcal{M}_i\) 외부의 패치 토큰과 토큰 사이의 attention 값에 0의 가중치를 할당한다. 본 논문에서는 두 번째 레이어의 출력을 최종 표현으로 활용하는데, 이는 마지막 레이어의 표현이 해당 proposal 영역에 초점을 맞추기보다는 전체 이미지를 포함하는 경향이 있다는 관찰에 기반한다.
4. Proposals Extracting and Matching
Weight-free Proposal Filter
생성 모델은 본질적으로 인스턴스 표현을 인코딩하므로 cross-attention 행렬 $c$에서 proposal을 도출할 수 있다. 본 논문에서는 일련의 mask proposal을 생성하기 위해 가중치 없는 proposal filter를 도입한다.
\[\begin{equation} \mathcal{M} = \{\psi ( c \ge \mu ) \; \vert \; \mu \in \{5\%, 10\%, \ldots, 95\%\}\} \end{equation}\]여기서 $\psi$는 미리 정의된 임계값 $\mu$를 갖는 이진화 함수이다. 외부 proposal generator와 CLIP 필터에 의존하는 다른 방법들과 달리 본 논문의 생성 모델은 예상 proposal을 효율적이고 효과적으로 생성할 수 있다. 이 접근 방식은 추가 도구 없이도 고품질 proposal을 얻을 수 있는 간소화되고 통합된 솔루션을 제공한다.
Pre-trained Segmentor
신뢰할 수 있는 segmentor를 사용할 수 있는 경우 유연한 방식으로 proposal을 얻을 수도 있다. Semantic 이해를 위한 생성 모델과 판별 모델의 feature를 활용함으로써 proposal을 개선하고 주어진 참조 설명과 밀접하게 일치하는 proposal의 우선순위를 지정할 수 있다. 초기 proposal 생성을 위해 segmentor를 사용하는 이러한 결합된 접근 방식은 결과 proposal이 일관되고 주어진 참조 표현과 더 잘 정렬되도록 보장한다.
Generative Matching
가중치 없는 proposal filter 또는 사전 학습된 segmentor에서 proposal을 얻은 후 다음 단계는 cross-attention 행렬을 기반으로 가장 유사한 proposal을 찾는 것이다. 본 논문에서는 cross-attention 행렬 $c$와 \(\mathcal{M}_i\)의 거리를 측정하여 주어진 참조 텍스트와 모든 proposal 사이의 유사도를 정량화한다.
\[\begin{equation} s_i^G = \frac{\vert c \odot \mathcal{M}_i \vert}{\vert \mathcal{M}_i \vert} - \frac{c \odot (1 - \mathcal{M}_i)}{\vert 1 - \mathcal{M}_i \vert} \end{equation}\]Discriminative Matching
참조 텍스트가 주어지면, CLIP 텍스트 인코더를 사용하여 글로벌 텍스트와 로컬 주제 토큰의 평균 표현 $r \in \mathbb{R}^d$를 얻을 수 있으며, 이는 참조 텍스트의 feature가 된다. 판별 모델의 관점에서 가장 가능성 있는 proposal을 찾기 위해 $r$과 각 mask proposal \(\mathcal{M}_i\)의 시각적 표현 $v_i$ 간의 유사도를 계산한다.
\[\begin{equation} s_i^D = v_i r^\top \end{equation}\]이러한 유사도를 통해 참조 텍스트와 가장 잘 일치하는 proposal을 식별할 수 있다. 유사도 점수가 높을수록 proposal과 텍스트 간의 일치성이 더 강하다는 것을 의미하며 올바른 segmentation 결과가 될 가능성이 더 높다는 것을 나타낸다.
Experiments
- 구현 디테일
- Ref-Diff는 zero-shot 솔루션이므로 학습 이미지와 주석이 필요없으며 inference 과정만 필요함
- 모든 이미지는 1024$\times$1024로 resize되고 패딩됨
- 생성 모델: 사전 학습된 Stable Diffusion V1.5
- Segmentor: SAM
- 판별 모델: CLIP ViT-B/16
- Tesla A100 GPU 1개 사용
- $t$ = 2, $\alpha$ = 0.1, $\beta$ = 0.3
1. Results
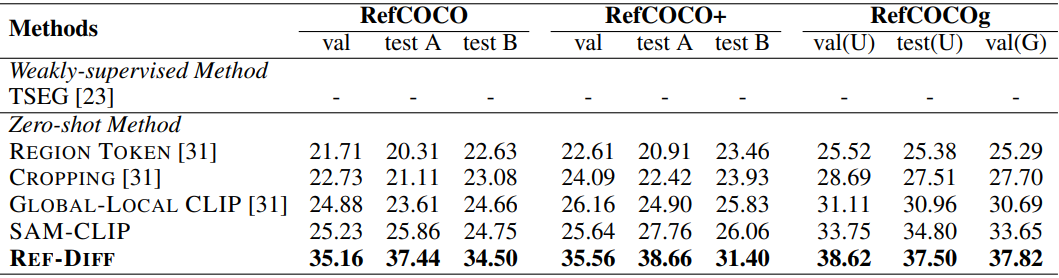
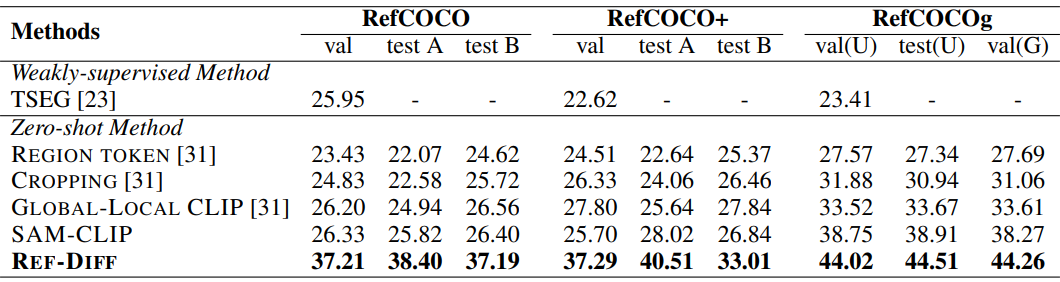
다음은 사전 학습된 segmentor와 CLIP을 사용할 때의 oIoU (위)와 mIoU (아래)를 비교한 표이다.
2. Ablation Study
다음은 PraseCut에서의 결과이다.

다음은 ablation 결과이다. (위: oIoU, 아래: mIoU)


3. Effect of Generative Model
다음은 segmentation 능력에 대한 생성 모델의 영향을 나타낸 그림이다.

다음은 localization 능력에 대한 생성 모델의 영향을 나타낸 그림이다.

4. Effect of Discriminative Model
다음은 판별 모델의 영향을 나타낸 그림이다.

5. Attention from Generative Model
다음은 생성 모델의 각 토큰에 대한 attention을 시각화한 것이다.

6. Case Study
다음은 다양한 난이도의 세 가지 예에 대한 결과이다.

첫 번째 예에서는 Ref-Diff가 유사한 객체 내에서 올바른 객체를 정확하게 식별하고 분할하는 능력을 보여 준다. 두 번째 예에서는 이미지에 수많은 객체가 존재하고 복잡한 공간 관계가 있음에도 불구하고 Ref-Diff는 생성 모델과 판별 모델의 정확한 이해를 통해 올바른 객체를 성공적으로 식별하였다. 마지막 예에서는 참조 표현에 어느 정도의 모호성이 존재하여 분할 실패가 발생했다. Ref-Diff는 가장 왼쪽 손을 첫 번째 팔로 잘못 식별하여 분할 오류를 발생하였다.
Limitations
- 사전 학습된 모듈들이 존재하기 때문에 inference 단계에서는 여전히 높은 계산 오버헤드가 발생한다.
- 참조 텍스트는 모호성에 민감하므로 눈에 띄는 분할 오류가 발생한다. (robustness가 떨어짐)