[논문리뷰] REDUCIO! Generating 1024×1024 Video within 16 Seconds using Extremely Compressed Motion Latents
ICCV 2025. [Paper] [Github]
Rui Tian, Qi Dai, Jianmin Bao, Kai Qiu, Yifan Yang, Chong Luo, Zuxuan Wu, Yu-Gang Jiang
Fudan University | Microsoft Research
20 Nov 2024

Introduction
최근 동영상 생성을 위한 latent diffusion model (LDM)의 발전은 고무적인 결과를 제시했으며, 다양한 응용 분야에서 큰 잠재력을 보여주었다. Sora, Runway Gen3, Movie Gen, Kling과 같은 상용 모델은 이미 사실적이고 고해상도의 동영상 클립을 생성할 수 있다. 그러나 이러한 모델을 학습시키고 배포하는 것은 컴퓨팅 측면에서 까다롭다. 학습에는 수천 개의 GPU와 수백만 GPU 시간이 필요하고, 1초 클립에 대한 inference에는 몇 분이 걸린다. 이처럼 높은 비용은 연구와 대규모 실제 응용에 큰 장애물이 되고 있다.
효율적인 backbone 계산 모듈, diffusion 학습 전략 최적화, few-step 샘플링 방법 등 계산 부담을 덜어주기 위한 광범위한 노력이 이루어졌다. 그러나 본 논문에서는 문제의 본질 자체가 오랫동안 무시되어 왔다고 주장한다. 구체적으로, 대부분의 video LDM은 text-to-image diffusion의 패러다임, 예를 들어 Stable Diffusion (SD)을 고수하고 본질적으로 사전 학습된 2D VAE의 latent space를 사용한다. 이 방식은 각 공간 차원에서 입력 동영상을 8배 압축하는데, 이는 이미지에는 적합하지만 동영상에는 다소 과도하다.
동영상은 이미지보다 훨씬 더 많은 중복성을 지니므로 3D convolution에 기반한 VAE를 사용하면 훨씬 더 압축된 latent space에 projection할 수 있다. 놀랍게도 동영상의 경우 공간적으로 16배 압축해도 재구성 성능의 많은 부분을 희생하지 않는다. Latent space의 결과 분포가 사전 학습된 이미지 LDM의 분포에서 이동하더라도 조건 프레임을 사용하여 text-to-video 생성을 인수분해하여 잘 학습된 공간적 prior를 여전히 활용할 수 있다. 특히 기존 text-to-image LDM을 사용하여 콘텐츠 프레임을 얻은 다음 텍스트와 이미지를 공동 prior로 사용하여 video LDM으로 샘플을 생성할 수 있다.
더 중요한 것은, 이미지 prior가 동영상 콘텐츠의 풍부한 공간 정보를 제공하므로, 인수분해된 동영상 생성은 추가 압축의 잠재력을 제공한다는 것이다. 저자들은 동영상이 모션 변수를 나타내는 매우 적은 수의 motion latent들과 콘텐츠 이미지로 인코딩될 수 있다고 주장하였다.
본 논문은 입력 동영상을 4096배 다운샘플링된 컴팩트한 공간으로 압축하는 3D 인코더와 중간 프레임의 feature pyramid를 콘텐츠 조건으로서 융합하는 3D 디코더로 구성된 VAE를 구축하는 Reducio를 소개한다. Reducio-VAE는 64배 더 작은 latent space를 사용하면서도 PSNR에서 일반적인 2D VAE보다 5db 더 뛰어나다.
그 후, diffusion transformer (DiT)를 사용하여 LDM을 구축한다. T5 feature를 텍스트 조건으로 사용하는 것 외에도, 이미지 semantic 인코더와 컨텍스트 인코더를 사용하여 모델에 공간적 콘텐츠를 알려주는 추가 이미지 조건을 제공한다. 극도로 압축된 video latent 덕분에, Reducio-DiT는 빠른 학습 및 inference 속도와 높은 생성 품질을 모두 가진다.
Reducio-DiT는 이전 방법들의 상당수를 능가하는 동시에 훨씬 빠르다. 또한 저렴한 비용으로 더 큰 해상도(ex. 1024$\times$1024)로 쉽게 업스케일링할 수 있으며, 하나의 A100 GPU에서 15.5초 이내에 1024$\times$1024 해상도의 16프레임 동영상 클립을 생성할 수 있다.
Method
1. Reducio Video Autoencoder
VAE는 입력 이미지나 동영상을 특정 분포를 따르는 압축된 latent space에 projection하고, 획득한 분포에서 샘플링된 latent를 디코더를 사용하여 RGB 공간에 매핑한다. LDM은 VAE의 다운 샘플링된 latent space를 활용하여 향상된 효율성으로 생성을 지원한다. 본 논문에서는 일반적인 관행을 따르고 VAE를 기반으로 동영상 오토인코더를 구축하였다.
VAE의 temporal down-sampling factor를 $f_t$로, spatial down-sampling factor를 $f_s$라 하자. 입력 동영상 $V \in \mathbb{R}^{3 \times T \times H \times W}$가 주어지면, latent \(z_V \in \mathbb{R}^{\vert z \vert \times T / f_t \times H / f_s \times W / f_s}\)가 diffusion model에 입력된다.
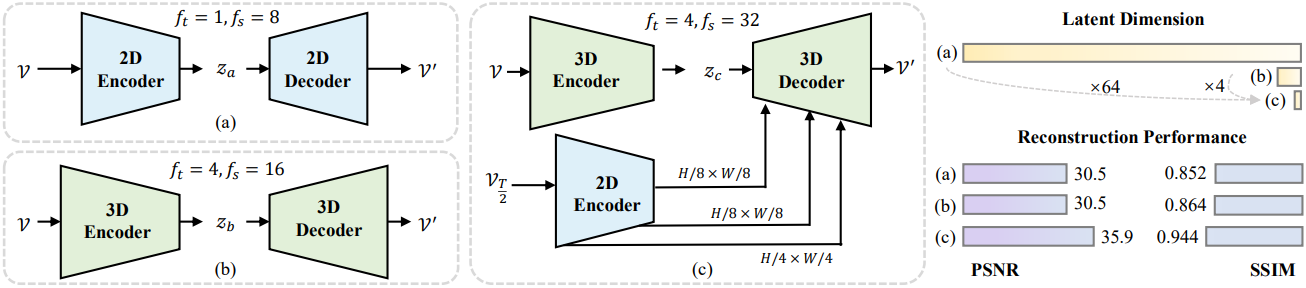
일반적인 관행은 Stable Diffusion (SD) 모델의 VAE를 활용하여 이미지와 동영상을 latent로 처리하는 것이다. SD-VAE는 위 그림의 (a)와 같이 $f_s = 8$, $f_t = 1$인 2D convolution을 기반으로 구축된다.
인접한 동영상 프레임이 픽셀 공간에서 큰 유사성을 공유하기 때문에 동영상 신호는 본질적으로 이미지보다 더 중복성이 크다. 이 아이디어를 바탕으로 동영상 오토인코더에 대해 보다 공격적인 down-sampling factor를 채택한다. 구체적으로, 2D convolution을 3D convolution으로 팽창시키고 오토인코더 블록의 수를 늘려 위 그림의 (b)에 나와 있듯이 $f_t = 4$와 $f_s = 16$으로 늘린다. 전체 down-sampling factor가 16배 증가하는 반면, 압축된 latent space는 비슷한 픽셀 공간 재구성 성능을 달성하기에 충분하여 latent의 차원을 극도로 축소시킬 수 있다.
Image-to-video 생성의 경우, 콘텐츠 이미지에 풍부한 시각적 디테일과 상당한 중복 정보가 포함되어 있으므로 latent를 추가로 압축할 수 있다. 이러한 시나리오에서 latent는 모션 정보를 나타내기 위해 더욱 단순화될 수 있다.
구체적으로, 위 그림의 (c)와 같이 콘텐츠 guidance로 중간 프레임 \(V_{T/2}\)를 선택하고 $f_s = 32$와 $f_t = 4$인 3D 인코더로 입력 동영상을 압축한 다음, 콘텐츠 프레임의 feature pyramid의 도움으로 latent space에서 재구성한다. 디코더 내에서 cross-attention을 통해 $H/8 \times W/8$, $H/4 \times W/4$로 다양한 크기의 콘텐츠 feature를 주입한다.
Reducio-VAE는 SDXL-VAE보다 64배 더 압축된 latent space에 동영상을 projection하지만, 재구성 성능 면에서 SDXL-VAE보다 상당히 우수한 성과를 보인다.
2. Reducio Diffusion Transformer
ReducioVAE의 압축 능력 덕분에 4096배로 압축된 latent space에 입력 동영상을 projection하고, 이를 통해 diffusion model의 학습과 inference를 상당히 빠르게 한다.
구체적으로, DiT-XL 모델을 채택하고 PixArt-$\alpha$에서 채택한 대부분의 디자인 선택, 즉 AdaLN-single modules, FlanT5-XXL 텍스트 조건을 사용하는 cross-attention layer를 따른다. 학습은 reverse diffusion process를 따른다.
\[\begin{equation} p_\theta (z_{t-1} \vert z_t) = \mathcal{N}(z_{t-1}; \mu_\theta (z_t, t) \sigma_t^2 I) \end{equation}\]($z$는 latent, $t$는 timestep, $\mu_\theta (z_t, t)$와 $\sigma_t^2$는 현재 timestep에서 샘플의 평균과 분산)
$\mu_\theta$를 noise prediction network $\epsilon_\theta$로 re-parameterize하면 예측 noise $\epsilon_\theta (z_t, t)$와 샘플링된 GT Gaussian noise $\epsilon$ 사이의 간단한 MSE를 사용하여 모델을 학습시킬 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{simple} = \mathbb{E}_{z_0, \epsilon, t} [\| \epsilon - \epsilon_\theta (z_t, t) \|^2] \end{equation}\]저자들은 이미지 diffusion model을 동영상에 적용하기 위해 두 가지 옵션을 고려하였다.
- 추가 파라미터를 추가하지 않고 2D attention을 3D attention으로 직접 변환
- Temporal layer를 추가하고 모델을 변환하여 2D spatial attention과 1D temporal attention을 수행
저자들은 기본적으로 첫 번째 옵션을 채택하였다.
또한, 이미지 조건부 동영상 생성에 맞게 조정하기 위해 추가 이미지 조건 모듈이 있는 Reducio-DiT를 도입했다.
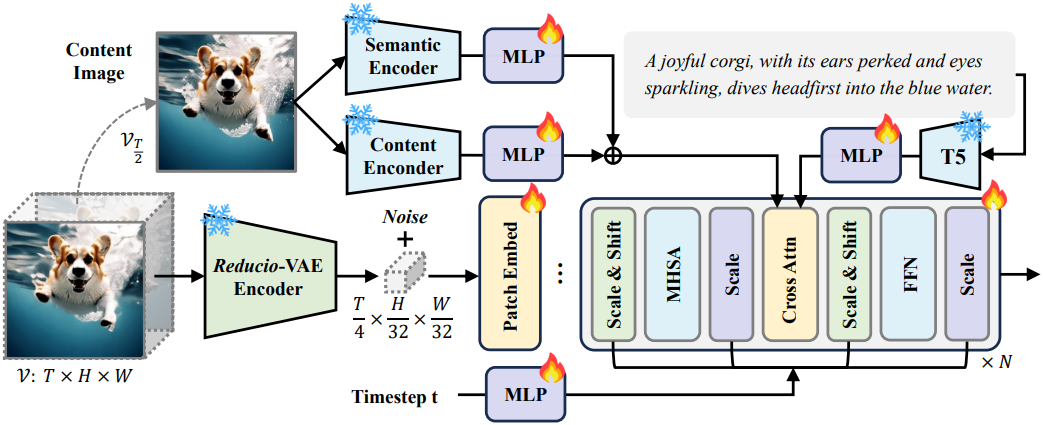
Content frame modules
콘텐츠 프레임 모듈은 사전 학습된 OpenCLIP ViT-H를 기반으로 구축된 semantic 인코더와 SD2.1-VAE로 초기화된 콘텐츠 인코더로 구성된다. Semantic 인코더는 콘텐츠 프레임을 high-level semantic space로 projection하는 반면, 콘텐츠 인코더는 주로 공간 정보 추출에 중점을 둔다. 획득한 feature를 T5에서 출력한 텍스트 토큰과 concat한 다음, noise가 있는 video latent와 cross-attention한다.
\[\begin{aligned} e_s &= \textrm{OpenCLIP}(V_{T/2}) \\ e_c &= \textrm{SD-VAE}(V_{T/2}) \\ e_\textrm{img} &= \textrm{MLP} (e_s) \oplus \textrm{MLP} (e_c) \\ e_p &= \textrm{MLP} (\textrm{T5} (\textrm{prompt})) \\ e &= [e_\textrm{img}, e_p] \\ z_i &= \textrm{CAttn} (z_i, e) \end{aligned}\]($V_{T/2}$는 조건 이미지, $\oplus$는 element-wise addition, $[\cdot]$는 concatenation, $\textrm{CAttn}(\cdot)$은 cross-attention)
고해상도 동영상으로 확장
고해상도 동영상으로 확장하는 경우, 일반 video diffusion model은 엄청난 계산 리소스가 소모된다. 반면 Reducio-DiT는 이 한계를 크게 완화한다. 고해상도(ex. 1024$\times$1024) 동영상 생성을 지원하기 위해 점진적인 학습 전략을 사용한다.
- 1단계: 256$\times$256 동영상을 입력으로 받아서 video latent space를 텍스트-이미지 prior와 정렬
- 2단계: 512$\times$512와 같이 더 높은 해상도의 동영상에서 모델을 fine-tuning
- 3단계: 다양한 종횡비로 augmentation하여 공간 해상도가 약 1024인 동영상에서 추가로 fine-tuning
다양한 종횡비의 동영상에 모델을 더 잘 맞추기 위해, DiT 모델에 임베딩으로 입력 동영상의 종횡비와 크기를 주입한다. 그런 다음 MLP에 공급하기 전에 크기 임베딩을 timestep 임베딩에 더한다. 1단계와 2단계의 모델에서는 콘텐츠 프레임의 $H/16 \times W/16$ 토큰을 noisy latent와 cross-attention한다.
해상도가 높아질수록 계산 비용이 급격히 증가하므로, 저자들은 각 cross-attention layer에서 콘텐츠 임베딩을 공간 차원에서 2배로 줄이는 것을 목표로 하였다. 구체적으로, Deepstack에서 영감을 얻어 입력 토큰을 4개의 그리드 그룹으로 나누고 각 $H/32 \times W/32$ 토큰 그룹을 다른 조건 토큰과 반복적으로 concat한다.
Experiments
- 학습 디테일
- Reducio-VAE
- 데이터: Pexels에서 모은 40만 개의 동영상
- 256$\times$256, 16FPS
- Reducio-DiT
- 데이터: 500만개의 동영상 (Pexels 데이터셋 + 내부 동영상)
- Reducio-DiT-256
- batch size: 512
- GPU: Nvidia A100 80G 4개 (900 A100 hour)
- 초기화: PixArt-$\alpha$-256
- Reducio-DiT-512
- batch size: 512
- GPU: Nvidia A100 80G 4개 (300 A100 hour)
- Reducio-DiT-1024
- batch size: 768
- 종횡비 버킷: 40개
- GPU: AMD MI300 8개 (1000 GPU hour)
- Reducio-VAE
- 샘플링: DPM-Solver++ (20 step)
1. Main Results
다음은 (위) SDXL-VAE와 (아래) Reducio-VAE의 동영상 재구성 결과를 비교한 것이다.

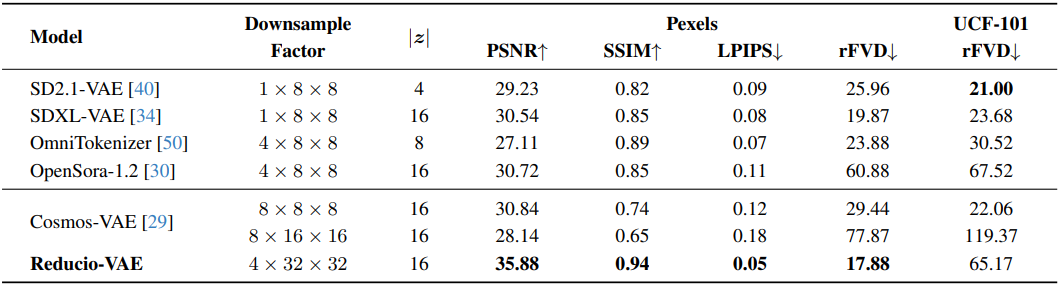
다음은 SOTA VAE와 Reducio-VAE를 비교한 표이다.
다음은 동일한 프레임과 프롬프트에 대하여 (a) DynamicCrafter, (b) SVD-XT, (c) Reducio-DiT의 생성 결과를 비교한 것이다.

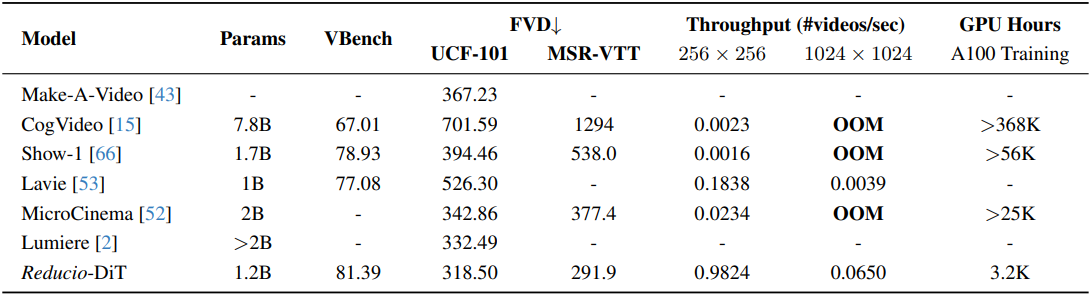
다음은 SOTA video LDM과 Reducio-DiT를 비교한 표이다.
2. Ablation Studies
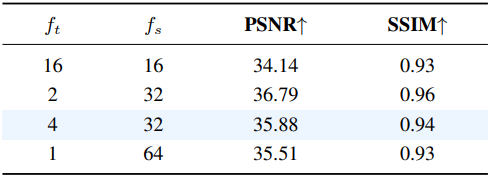
다음은 Reducio-VAE의 $f_t$와 $f_s$에 대한 ablation 결과이다. ($f_t \cdot f_s^2$는 일정)
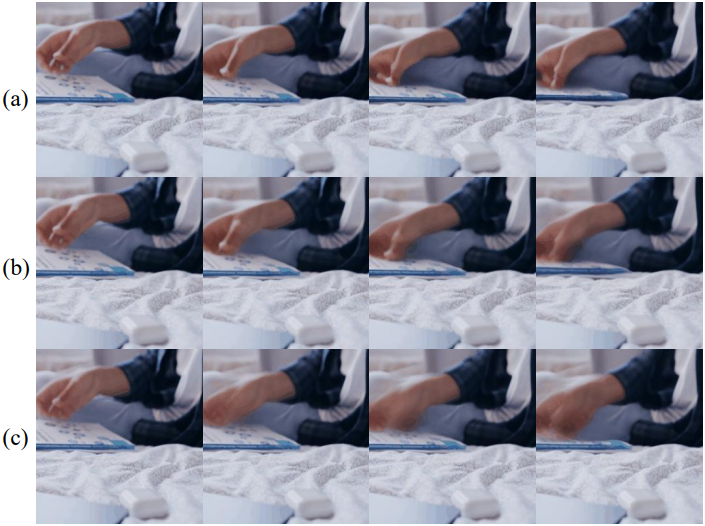
다음은 latent 채널 차원에 대한 ablation 결과이다. ((a)는 $\vert z \vert = 16$, (b)는 $\vert z \vert = 8$, (c)는 $\vert z \vert = 4$)
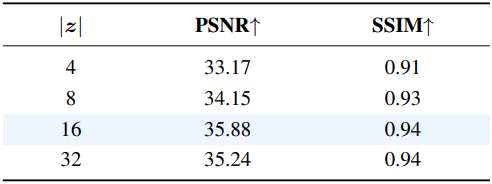
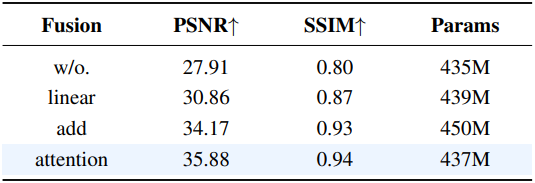
다음은 Reducio-VAE의 콘텐츠 이미지 융합 방식에 대한 ablation 결과이다.
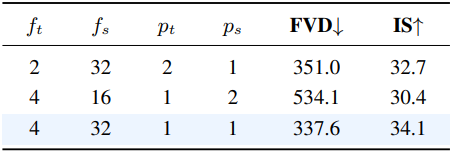
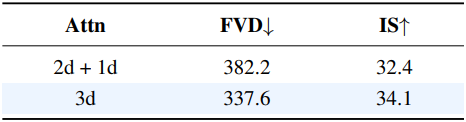
다음은 Reducio-DiT의 (a) 패치 크기 $p_t$, $p_s$와 (b) attention 유형에 대한 ablation 결과이다.
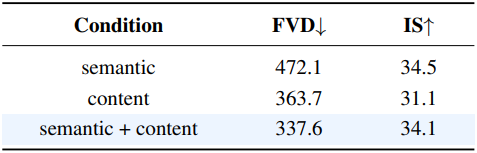
다음은 Reducio-DiT의 컨디셔닝 유형에 대한 ablation 결과이다. ((a)는 semantic + content, (b)는 semantic only)

Limitations
- 생성된 동영상이 여전히 짧다. (16fps의 16개 프레임, 즉 1초)
- 동영상의 길이가 짧아 모션의 크기도 어느 정도 제한된다.