[논문리뷰] Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
ICLR 2023. [Paper]
Xingchao Liu, Chengyue Gong, Qiang Liu
University of Texas at Austin
7 Sep 2022

Introduction
본 논문은 transport mapping problem에 대한 놀라울 정도로 간단한 접근 방식인 rectified flow를 소개하였으며, 이는 생성 모델링과 도메인 전송을 통합적으로 해결한다. Rectified flow는 가능한 한 직선 경로를 따라 분포 $\pi_0$에서 $\pi_1$로 전송하는 상미분 방정식 (ODE) 모델이다. 직선 경로는 이론적으로 두 점 사이의 가장 짧은 경로이며, 계산적으로는 시간을 discretize할 필요 없이 정확하게 시뮬레이션할 수 있기 때문에 선호된다. 따라서 직선 경로의 flow는 1-step 모델과 continuous-time 모델 간의 격차를 메운다.
Transport mapping problem: $\mathbb{R}^d$에서의 두 분포의 경험적 관찰 $X_0 \sim \pi_0$, $X_1 \sim \pi_1$이 주어졌을 때, $Z_0 \sim \pi_0$일 때 $Z_1 = T(Z_0) \sim \pi_1$인 transport map $T : \mathbb{R}^d \rightarrow \mathbb{R}^d$를 찾는 문제.
Rectified flow는 간단한 제약 없는 최소 제곱 최적화 절차로 학습되며, 이는 GAN의 불안정성 문제, MLE 방법의 다루기 힘든 likelihood, 그리고 diffusion model의 hyperparameter 선택의 어려움을 피한다. 학습 데이터에서 rectified flow를 얻는 절차는 다음과 같다.
- 모든 convex cost $c$에 대해 transport cost가 증가하지 않는 쌍을 생성한다.
- Flow의 경로를 점점 더 직선으로 만들어 numerical solver로 오차를 줄인다.
따라서 이전에 얻은 rectified flow에서 시뮬레이션한 데이터로 새로운 rectified flow를 반복적으로 학습시키는 reflow 절차를 통해 하나의 Euler step에서도 좋은 결과를 내는 거의 직선인 flow를 얻는다. 이 방법은 순전히 ODE 기반이며, SDE 기반 접근 방식보다 개념적으로 더 간단하고 inference 시에 더 빠르다.
경험적으로, rectified flow는 매우 적은 수의 Euler step으로 시뮬레이션될 때 이미지 생성에 대한 고품질 결과를 낼 수 있다. 게다가, 단 한 step의 reflow만으로도 flow가 거의 직선이 되어 하나의 Euler step으로 좋은 결과를 낼 수 있다. 이는 diffusion 방법보다 상당히 개선되었다. Rectified flow는 CIFAR10에서 1-step diffusion model에 대한 SOTA (FID 4.85, recall 0.51)를 달성하였다. 또한 image-to-image translation과 transfer learning과 같은 task에서도 뛰어난 결과를 달성하였다.
Method
1. Overview
경험적 관찰 $X_0 \sim \pi_0$, $X_1 \sim \pi_1$이 주어지면 $(X_0, X_1)$에서 유도된 rectified flow는 시간 $t \in [0, 1]$에서의 상미분 방정식(ODE)으로 표현되는 모델이다.
\[\begin{equation} \textrm{d}Z_t = v (Z_t, t) \textrm{d}t \end{equation}\]이는 $Z_0$를 $\pi_0$에서 $\pi_1$을 따르는 $Z_1$로 변환한다. Drift force $v : \mathbb{R}^d \rightarrow \mathbb{R}^d$는 가능한 한 flow가 $X_0$에서 $X_1$을 가리키는 선형 경로의 방향 $X_1 − X_0$를 따르도록 하며, 간단한 최소 제곱 회귀 문제를 풀어서 얻을 수 있다.
\[\begin{equation} \min_v \int_0^1 \mathbb{E} [\| (X_1 - X_0) - v (X_t, t) \|^2] \textrm{d}t, \quad \textrm{with} \; X_t = t X_1 + (1 - t) X_0 \end{equation}\]$X_t$는 $\textrm{d}X_t = (X_1 − X_0) \textrm{d}t$의 ODE를 따르는데, 이는 $X_t$의 업데이트에 최종 지점 $X_1$의 정보가 필요하기 때문에 non-causal, 즉 미래를 알아야 한다. Rectified flow는 drift $v$를 $X_1 − X_0$에 fitting하여 $X_t$의 경로를 미래를 보지 않고도 시뮬레이션할 수 있는 ODE flow를 생성한다.

실제로는 신경망이나 다른 비선형 모델로 $v$를 parameterize하고, stochastic gradient descent (SGD)와 같은 최적화 도구로 위의 최적화 문제를 푼다.
$v$를 구한 후, $Z_0 \sim \pi_0$에서 시작하여 $\pi_0$를 $\pi_1$로 옮기려면 ODE를 풀면 되고, $Z_1 \sim \pi_1$에서 시작하여 $\pi_1$을 $\pi_0$으로 옮기려면 ODE를 역방향으로 풀면 된다. 구체적으로, 역방향 샘플링의 경우, \(X_t = \tilde{X}_{1-t}\)로 설정하고 \(\tilde{X}_0 \sim \pi_1\)에서 초기화한 뒤 \(\textrm{d}\tilde{X}_t = −v(\tilde{X}_t, t)\textrm{d}t\)를 풀면 된다. 순방향 샘플링과 역방향 샘플링은 학습 알고리즘에서 동등하게 선호되는데, 그 이유는 위 최적화 문제에서 $X_0$와 $X_1$를 바꾸고 $v$의 부호를 뒤집으면 동등한 문제를 생성한다는 점에서 시간 대칭적이기 때문이다.
Flow들은 서로 교차하지 않는다.

잘 정의된 ODE $\textrm{d}Z_t = v(Z_t, t)\textrm{d}t$를 따르는 서로 다른 경로는 해가 존재하고 고유하며, 시간 $t \in [0, 1)$에서 서로 교차할 수 없다. 구체적으로, 두 경로가 시간 $t$에서 서로 다른 방향으로 $z$에서 교차하는 그러한 위치 $z \in \mathbb{R}^d$와 시간 $t \in [0, 1)$은 존재하지 않는다. 그렇지 않으면 ODE의 해가 고유하지 않기 때문이다.
반면, interpolation process의 경로는 서로 교차할 수 있으며, 이로 인해 non-causal해진다. 따라서 rectified flow는 교차점을 통과하는 개별 궤적을 다시 연결하여 교차를 피하는 동시에 interpolation 경로와 동일한 density map을 추적한다. 이는 $X_0$와 $X_1$이 어떻게 쌍을 이루는지에 대한 글로벌한 경로 정보를 무시하고 $(Z_0, Z_1)$의 더욱 deterministic한 쌍을 재구축할 수 있게 한다.
Rectified flow는 transport cost를 줄인다.
최적화 문제를 정확히 풀면 rectified flow의 쌍 $(Z_0, Z_1)$은 $\pi_0$, $\pi_1$의 유효한 결합이 보장된다. 즉, $Z_0 \sim \pi_0$이면 $Z_1$이 $\pi_1$을 따른다. 또한, $(Z_0, Z_1)$은 모든 convex cost function $c$에 대해 데이터 쌍 $(X_0, X_1)$보다 더 큰 transport cost를 생성하지 않음을 보장한다.
데이터 쌍 $(X_0, X_1)$은 $\pi_0$, $\pi_1$의 임의의 결합이 될 수 있으며, 실제 문제에서 의미 있게 쌍을 이룬 관찰이 부족하기 때문에 일반적으로 독립적이다 (즉, $(X_0, X_1) \sim \pi_0 \times \pi_1$). 이에 비해 $(Z_0, Z_1)$은 ODE 모델에서 구성되므로 deterministic한 종속성이 있다. $(Z_0, Z_1) = \textrm{Rectify}((X_0, X_1))$로 $(X_0, X_1)$에서 $(Z_0, Z_1)$로의 매핑을 표시하면, $\textrm{Rectify}(\cdot)$는 임의의 결합을 더 낮은 convex transport cost를 가지는 deterministic한 결합으로 변환한다.
직선인 flow는 빠른 시뮬레이션을 제공한다.
$\textrm{Rectify}(\cdot)$를 재귀적으로 적용하면 rectified flow의 시퀀스 $\textbf{Z}^{k+1} = (Z_0^{k+1}, Z_1^{k+1}) = \textrm{RectFlow}((Z_0^k, Z_1^k))$가 생성되고 여기서 $(Z_0^0, Z_1^0) = (X_0, X_1)$이 된다. 여기서 $\textbf{Z}^k$는 $(X_0, X_1)$에서 유도된 $k$번째 rectified flow ($k$-rectified flow)이다.
이 reflow 절차는 transport cost를 줄일 뿐만 아니라 rectified flow의 경로를 직선화하는 중요한 효과가 있다. 이는 거의 직선 경로를 가진 flow가 수치적 시뮬레이션에서 작은 시간 discretization 오차를 발생시키기 때문에 계산적으로 매우 매력적이다. 완벽하게 직선인 경로는 하나의 Euler step으로 정확하게 시뮬레이션할 수 있으며 1-step 모델이다. 이는 기존 continuous-time ODE/SDE 모델의 높은 inference 비용 문제를 해결한다.
2. Main Results and Properties
주어진 입력 쌍 $(X_0, X_1)$의 경우, 최적화 문제의 정확한 최소값은 시간 $t$에서 $X_t = x$를 지나는 선 방향 $X_1 − X_0$의 기대값이다.
\[\begin{equation} v^X (x, t) = \mathbb{E} [X_1 - X_0 \vert X_t = x] \end{equation}\]Marginal 보존 성질
임의의 시간 $t$에서 $Z_t$의 marginal distribution은 $X_t$의 marginal distribution과 항상 같다.
직관적으로, 이는 $v^X$의 정의에 따라 모든 위치와 시간에 모든 무한소 체적을 통과하는 질량의 기대값이 $X_t$와 $Z_t$의 동역학에 따라 동일하기 때문이며, 이는 이들이 동일한 marginal distribution을 추적함을 보장한다.
반면, $Z_t$의 전체 궤적과 $X_t$의 궤적의 joint distribution은 일반적으로 다르다. 특히, $X_t$는 일반적으로 non-causal한 non-Markov process이며, $(X_0, X_1)$은 stochastic한 쌍이고, $Z_t$는 $X_t$를 causal한 Markov process로 만들며, deterministic하게 만들면서 항상 marginal distribution을 보존한다.
Transport cost 감소
$(Z_0, Z_1)$의 convex transport cost는 $(X_0, X_1)$보다 작거나 같다. 즉, 임의의 convex cost $c: \mathbb{R}^d \rightarrow \mathbb{R}$에 대하여 다음 부등식이 성립한다.
\[\begin{equation} \mathbb{E}[c (Z_1 - Z_0)] \le \mathbb{E} [c (X_1 - X_0)] \end{equation}\]증명)
$X_t$와 $Z_t$의 marginal distribution이 같으므로 다음 식이 성립한다. $$ \begin{equation} \mathbb{E} \left[ \int_0^1 c (v^X (X_t, t) \textrm{d}t) \right] = \mathbb{E} \left[ \int_0^1 c (v^X (Z_t, t) \textrm{d}t) \right] \end{equation} $$ $v$와 $v^X$의 정의, 즉 $\textrm{d}Z_t = v (Z_t, t) \textrm{d}t$와 $v^X (x, t) = \mathbb{E} [X_1 - X_0 \vert X_t = x]$를 활용하면 다음과 같이 증명이 가능하다. $$ \begin{aligned} \mathbb{E} [c(Z_1 - Z_0)] &= \mathbb{E} \left[ c \left( \int_0^1 v^X (Z_t, t) \textrm{d}t \right) \right] \\ &\le \mathbb{E} \left[ \int_0^1 c (v^X (Z_t, t) \textrm{d}t) \right] \\ &= \mathbb{E} \left[ \int_0^1 c (v^X (X_t, t) \textrm{d}t) \right] \\ &= \mathbb{E} \left[ \int_0^1 c (\mathbb{E} [(X_1 - X_0) \vert X_t]) \textrm{d}t \right] \\ &\le \mathbb{E} \left[ \int_0^1 \mathbb{E} [ c (X_1 - X_0) \vert X_t] \textrm{d}t \right] \\ &= \int_0^1 \mathbb{E} [c (X_1 - X_0)] \textrm{d}t \\ &= \mathbb{E} [c (X_1 - X_0)] \end{aligned} $$ 두 부등식은 모두 Jensen's inequality에 의해 성립한다.
직관적으로, rectified flow $Z_t$의 경로가 $(X_0, X_1)$을 연결하는 직선 경로이므로 convex transport cost가 감소하는 것이 보장된다.
Reflow를 통한 직선화 및 빠른 시뮬레이션
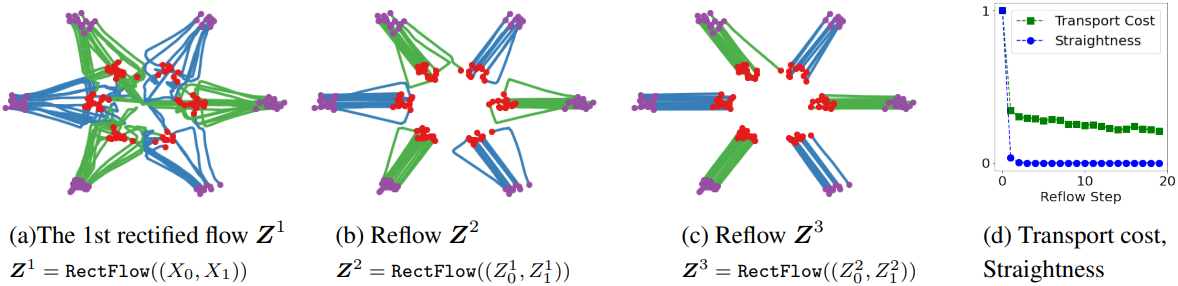
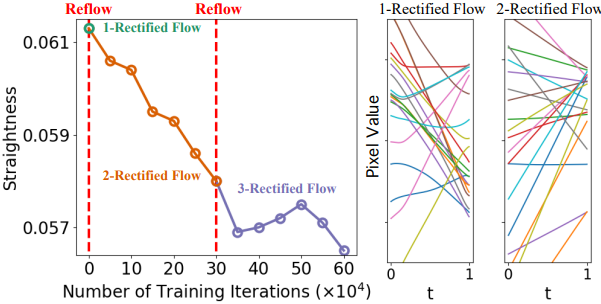
위 그림에서 볼 수 있듯이, \(\mathbf{Z}^{k+1} = \textrm{RectFlow}((Z_0^k, Z_1^k))\) 절차를 재귀적으로 적용할 때, $k$-rectified flow $\mathbf{Z}^k$의 경로는 $k$가 증가함에 따라 점점 더 직선적이 되므로 수치적으로 시뮬레이션하기가 더 쉬워진다. Linear interpolation \(\{X_t\}\)는 직선이지만 casual한 flow가 아니므로 $\pi_0$와 $\pi_1$에 대한 접근 없이는 시뮬레이션할 수 없다.
임의의 연속적으로 미분 가능한 프로세스 \(\mathbf{Z} = \{Z_t\}\)의 직선성을 다음과 같이 측정할 수 있다.
\[\begin{equation} S(\mathbf{Z}) = \int_0^1 \mathbb{E} [\| (Z_1 - Z_0) - \dot{Z}_t \|^2] \textrm{d}t \end{equation}\]$S(\mathbf{Z}) = 0$은 정확한 직선을 의미한다. $S(\mathbf{Z})$가 작은 flow는 거의 직선 경로를 가지므로 적은 수의 discretization step을 가진 numerical solver를 사용하여 정확하게 시뮬레이션할 수 있다.
$\mathbf{Z}^k$가 $(X_0, X_1)$에서 유도된 $k$-rectified flow라고 가정하면, 다음이 성립한다.
\[\begin{equation} \min_{k \in \{0 \cdots K\}} S(\mathbf{Z}^k) \le \frac{\mathbb{E} [\| X_1 - X_0 \|^2]}{K} \end{equation}\]증명)
$V((X_0, X_1))$를 다음과 같이 정의하자. $$ \begin{equation} V((X_0, X_1)) := \int_0^1 \mathbb{E} [\| X_1 - X_0 - \mathbb{E} [X_1 - X_0 \vert X_t] \|^2] \textrm{d}t \\ \end{equation} $$ $X_t$가 주어졌을 때, $X_1 - X_0$에 대한 조건부 분산은 다음과 같다. $$ \begin{aligned} \textrm{Var}(X_1 - X_0 \vert X_t) &= \mathbb{E} [\| X_1 - X_0 - \mathbb{E} [X_1 - X_0 \vert X_t] \|^2 \vert X_t]\\ &= \mathbb{E} [\| X_1 - X_0 \|^2 \vert X_t] - \| \mathbb{E} [X_1 - X_0 \vert X_t] \|^2 \end{aligned} $$ 이를 활용하여 $V((X_0, X_1))$를 정리하면 다음과 같다. $$ \begin{aligned} V((X_0, X_1)) &= \int_0^1 \mathbb{E} [\| X_1 - X_0 - \mathbb{E} [X_1 - X_0 \vert X_t] \|^2] \textrm{d}t \\ &= \int_0^1 \mathbb{E} [ \mathbb{E} [\| X_1 - X_0 - \mathbb{E} [X_1 - X_0 \vert X_t] \|^2 \vert X_t] ] \textrm{d}t \\ &= \int_0^1 \mathbb{E} [ \mathbb{E} [\| X_1 - X_0 \|^2 \vert X_t] - \| \mathbb{E} [X_1 - X_0 \vert X_t] \|^2 ] \textrm{d}t \\ &= \mathbb{E} \left[ \int_0^1 \left( \mathbb{E} [\| X_1 - X_0 \|^2 \vert X_t] - \| \mathbb{E} [X_1 - X_0 \vert X_t] \|^2 \right) \textrm{d}t \right] \\ &= \mathbb{E} \left[ \int_0^1 \mathbb{E} [\| X_1 - X_0 \|^2 \vert X_t] \textrm{d}t \right] - \mathbb{E} \left[ \int_0^1 \| \mathbb{E} [ X_1 - X_0 \vert X_t] \|^2 \textrm{d}t \right] \end{aligned} $$ $Z_1 - Z_0$은 $\dot{Z}_t$의 평균이므로, $S(\textbf{Z})$를 분산의 성질을 사용하여 전개하면 다음과 같다. $$ \begin{aligned} S(\textbf{Z}) &= \int_0^1 \mathbb{E} [\| \dot{Z}_t - (Z_1 - Z_0) \|^2] \textrm{d}t \\ &= \int_0^1 \mathbb{E} \left[ \| \dot{Z}_t \|^2 \right] \textrm{d}t - \int_0^1 \mathbb{E} \left[ \| Z_1 - Z_0 \|^2 \right] \textrm{d}t \\ &= \mathbb{E} \left[ \int_0^1 \| \dot{Z}_t \|^2 \textrm{d}t \right] - \mathbb{E} [ \| Z_1 - Z_0 \|^2 ] \\ &= \mathbb{E} \left[ \int_0^1 \| v^X (Z_t, t) \|^2 \textrm{d}t \right] - \mathbb{E} [ \| Z_1 - Z_0 \|^2 ] \end{aligned} $$ 하나로 정리하면 다음과 같다. $$ \begin{aligned} \mathbb{E} \left[\| X_1 - X_0 \|^2\right] &= \int_0^1 \mathbb{E} \left[\| X_1 - X_0 \|^2 \right] \textrm{d}t \\ &= \mathbb{E} \left[ \int_0^1 \mathbb{E} \left[ \| X_1 - X_0 \|^2 \vert X_t \right] \textrm{d}t \right] \\ &= \mathbb{E} \left[ \int_0^1 \| \mathbb{E} [ X_1 - X_0 \vert X_t] \|^2 \textrm{d}t \right] + V((X_0, X_1)) \\ &= \mathbb{E} \left[ \int_0^1 \| v^X (X_t, t) \|^2 \textrm{d}t \right] + V((X_0, X_1)) \\ &= \mathbb{E} \left[ \int_0^1 \| v^X (Z_t, t) \|^2 \textrm{d}t \right] + V((X_0, X_1)) \\ &= \mathbb{E} \left[ \| Z_1 - Z_0 \|^2 \right] + S(\textbf{Z}) + V((X_0, X_1)) \end{aligned} $$ 마찬가지로 다음 식이 성립한다. $$ \begin{equation} \mathbb{E} [\| Z_1^k - Z_0^k \|^2] = \mathbb{E} \left[ \left\| Z_1^{k+1} - Z_0^{k+1} \right\|^2 \right] + S(\textbf{Z}^{k+1}) + V((Z_0^k, Z_1^k)) \end{equation} $$ $k = 0$부터 $k = K-1$까지의 식을 모두 더하면 다음과 같다. $$ \begin{aligned} \mathbb{E} \left[\| X_1 - X_0 \|^2\right] &= \mathbb{E} \left[ \left\| Z_1^K - Z_0^K \right\|^2 \right] + \sum_{k=0}^{K-1} \left( S(\textbf{Z}^{k+1}) + V((Z_0^k, Z_1^k)) \right) \\ &\ge \sum_{k=0}^{K-1} S(\textbf{Z}^{k+1}) = \sum_{k=1}^K S(\textbf{Z}^k) \\ &\ge K \min_{k = \{1 \cdots K\}} S(\textbf{Z}^k) = K \min_{k = \{0 \cdots K\}} S(\textbf{Z}^k) \end{aligned} $$ 따라서, $$ \begin{equation} \min_{k = \{0 \cdots K\}} S(\textbf{Z}^k) \le \frac{\mathbb{E} \left[\| X_1 - X_0 \|^2\right]}{K} = O (1 / K) \end{equation} $$
즉, rectification을 재귀적으로 적용하면 $S(\mathbf{Z})$가 점점 0으로 감소한다.
Reflow를 한 번만 적용하여도 거의 직선적인 flow가 되어 하나의 Euler step으로 시뮬레이션할 때 좋은 성능을 낼 수 있다. 너무 많은 reflow를 적용하면 $v^X$에 대한 추정 오차가 누적될 수 있어 권장되지 않는다.
Distillation
$k$-rectified flow $\textbf{Z}^k$를 얻은 후, $(Z_0^k, Z_1^k)$의 관계를 신경망 $\hat{T}$로 distillation하여 flow를 시뮬레이션하지 않고도 $Z_0^k$에서 $Z_1^k$를 직접 예측함으로써 inference 속도를 더욱 향상시킬 수 있다. Flow가 이미 거의 직선이라 1-step으로 잘 근사되기 때문에 distillation을 효율적으로 수행할 수 있다. 특히 $\hat{T} (z_0) = z_0 + v(z_0, 0)$인 경우 $\textbf{Z}^k$를 distillation하기 위한 loss function은
\[\begin{equation} \mathbb{E} \left[ \| (Z_1^k − Z_0^k) − v(Z_0^k, 0) \|^2 \right] \end{equation}\]이고, 이는 $t = 0$일 때의 원래 최적화 식과 같다.
Distillation은 $(Z_0^k, Z_1^k)$을 충실하게 근사화하려고 시도하는 반면 rectification은 더 낮은 transport cost와 더 직선적인 flow로 다른 $(Z_0^{k+1}, Z_1^{k+1})$을 생성한다. 따라서 빠른 1-step inference를 위해 모델을 fine-tuning하려는 최종 단계에서만 distillation을 적용해야 한다.
Velocity field $v^X$
$X_0$가 $X_1 = x_1$을 조건으로 하는 density function $\rho (x_0 \vert x_1)$을 생성하는 경우 optimal velocity field $v^X (z, t) = \mathbb{E}[X_1 - X_0 \vert X_t = z]$는 다음과 같이 표현될 수 있다.
\[\begin{equation} v^X (z, t) = \mathbb{E}_{X_1 \sim \pi_1} \left[ \frac{X_1-z}{1-t} \eta_t (X_1, z) \right], \quad \eta_t (X_1, z) = \frac{\rho ( \frac{z-tX_1}{1-t} \vert X_1)}{\mathbb{E}_{X_1 \sim \pi_1} [\rho ( \frac{z-tX_1}{1-t} \vert X_1)]} \end{equation}\]이는 $X_0 = \frac{z−tX_1}{1−t}$이고 $X_1 − X_0 = \frac{X_1−z}{1-t}$인 경우로 볼 수 있다. 따라서 $\rho$가 항상 양의 값을 가지고 모든 곳에서 연속이면 $v^X$는 잘 정의되고 \(\mathbb{R}^d \times [0, 1)\)에서 연속이다. 또한 \(\log \eta_t\)가 $z$에 대해 미분 가능하면 다음 식이 성립한다.
\[\begin{equation} \nabla_z v^X (z, t) = \frac{1}{1-t} \mathbb{E} [((X_1 - z) \nabla_z \log \eta_t (X_1, z) - 1) \eta_t (X_1, z)] \end{equation}\]3. A Nonlinear Extension
저자들은 linear interpolation $X_t$를 $X_0$와 $X_1$을 연결하는 시간 미분 가능한 곡선으로 대체하는 rectified flow의 비선형 버전을 제시하였다. 이러한 일반화된 rectified flow는 여전히 $\pi_0$를 $\pi_1$로 전송할 수 있지만, 더 이상 convex transport cost를 감소시키거나 직선화 효과를 보장하지 않는다. 중요한 점은 probability flow ODE와 DDIM은 이 프레임워크의 특수한 경우로 대략적으로 볼 수 있으며, 이러한 방법들과의 연결과 이점을 명확히 할 수 있다는 것이다.
\(\textbf{X} = \{X_t : t \in \}\)가 $X_0$와 $X_1$을 연결하는 시간 미분 가능한 임의의 프로세스라고 하자. $\textbf{X}$에서 유도된 rectified flow는 다음과 같이 정의된다.
\[\begin{equation} \textrm{d} Z_t = v^X (Z_t, t) \textrm{d}t, \quad \textrm{with } \; Z_0 = X_0, \; \textrm{ and } \; v^X (z, t) = \mathbb{E} [\dot{X}_t \vert X_t = z] \end{equation}\]다음 식을 풀면 $v^X$를 추정할 수 있다.
\[\begin{equation} \min_v \int_0^1 \mathbb{E} \left[ w_t \left\| v (X_t, t) - \dot{X}_t \right\|^2 \right] \textrm{d}t \end{equation}\]여기서 $w_t : (0, 1) \rightarrow (0, +\infty)$는 양의 가중치 시퀀스이다. 이 방법으로 유도된 flow $\textbf{Z}$는 여전히 $\textbf{X}$의 marginal distribution을 보존한다.
간단한 interpolation 방법은 \(X_t = \alpha_t X_1 + \beta_t X_0\)이다. 여기서 \(\alpha_t\)와 \(\beta_t\)는 \(\alpha_1 = \beta_0 = 1\)과 \(\alpha_0 = \beta_1 = 0\)을 만족하는 두 미분 가능한 수열로, 이 과정은 시작점과 끝점에서 $X_0$, $X_1$과 같다. 이 경우 위 식에서 \(\dot{X}_t = \dot{\alpha}_t X_1 + \dot{\beta}_t X_0\)가 된다. 곡선의 모양은 \(\alpha_t\)와 \(\beta_t\)의 관계에 의해 제어된다. 모든 $t$에 대해 \(\beta_t = 1 − \alpha_t\)를 취하면 $X_t$는 직선 경로를 가지지만 일정한 속도로 이동하지는 않는다.
Probability Flow ODE (PF-ODE)
모든 종류의 PF-ODE는 \(X_t = \alpha_t X_1 + \beta_t \xi\)로 볼 수 있다. 이때 \(\alpha_1 = 1\), \(\beta_1 = 0\)인 \(\alpha_t\), \(\beta_t\)에 대해 $\xi \sim \mathcal{N}(0,I)$은 표준 Gaussian 확률 변수이다.
Score-Based Generative Modeling through Stochastic Differential Equations에서 제안된 VP ODE와 sub-VP ODE의 $\alpha_t$는 다음과 같다.
\[\begin{equation} \alpha_t = \exp \left( - \frac{1}{4}a(1-t)^2 - \frac{1}{2}b(1-t) \right), \quad \textrm{default values}: a = 19.9, b = 0.1 \end{equation}\]VP ODE와 sub-VP ODE의 \(\beta_t\)는 다음과 같다.
\[\begin{equation} \textrm{VP ODE}: \; \beta_t = \sqrt{1 - \alpha_t^2}, \quad \textrm{sub-VP ODE}: \; \beta_t = 1 - \alpha_t^2 \end{equation}\]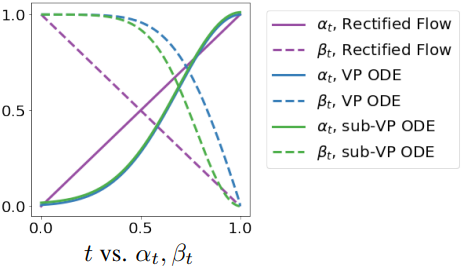
아래는 toy experiment에 대한 결과들이다.
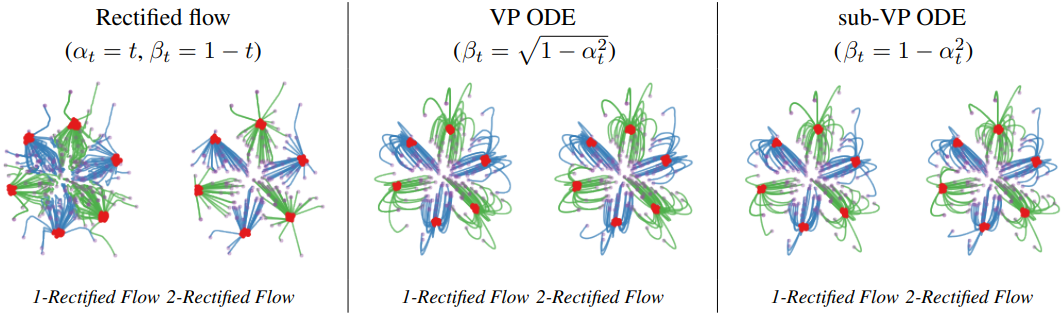

VE ODE의 경우 \(\alpha_t = 1\), \(\beta_t = \sigma_\textrm{min} \sqrt{r^{2(1-t)}-1}\)이며, \(\sigma_\textrm{min} = 0.01\)이고 \(\sigma_\textrm{max} = r \sigma_\textrm{min}\)이다.
Experiments
1. Unconditioned Image Generation
다음은 CIFAR10에서 다른 방법들과 이미지 생성 결과를 비교한 표이다.
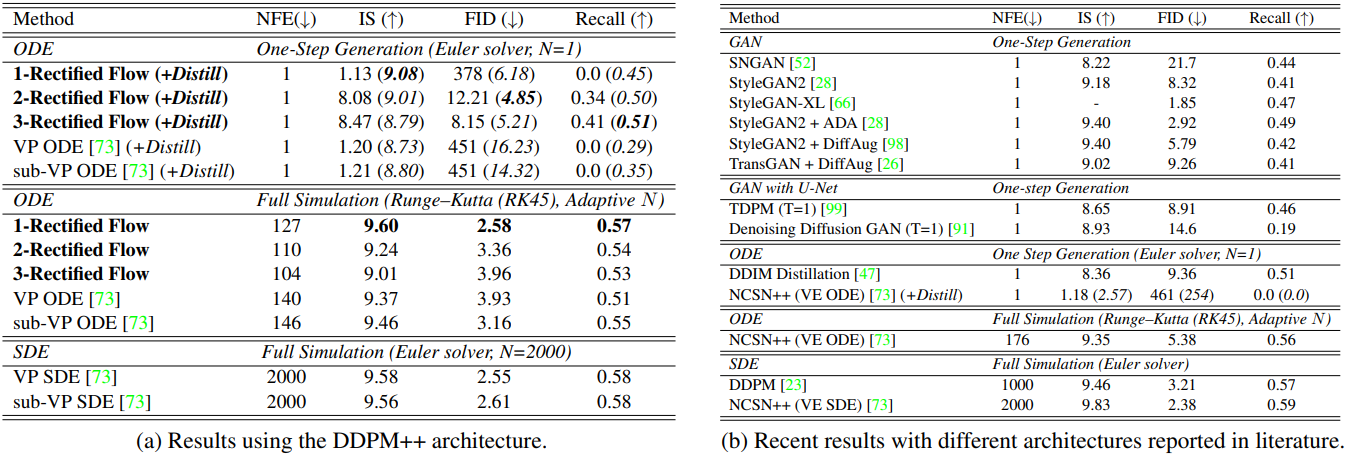
다음은 CIFAR10에서의 여러 PF-ODE들과 이미지 생성 결과를 비교한 그래프이다.
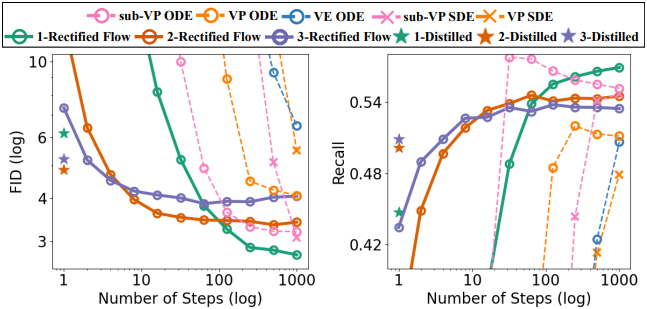
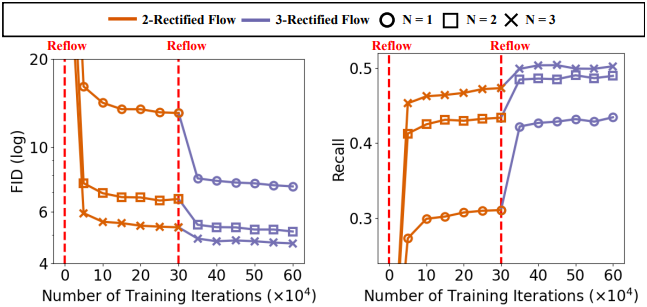
다음은 CIFAR10에서의 직선화 효과를 나타낸 그래프이다.
다음은 256$\times$256 해상도의 데이터셋들에서 1-rectified flow로 이미지를 생성한 예시들이다.

다음은 1-rectified flow로 이미지를 편집한 예시들이다.

2. Image-to-Image Translation
Image-to-image translation의 주요 목표는 좋은 시각적 결과를 얻는 것이므로, $X_0 \sim \pi_0$를 $\pi_1$을 정확히 따르는 $X_1$로 충실하게 옮기는 데 관심이 없다. 그 대신, 이미지에서 identity를 유지하면서 이미지 스타일을 옮기는 데 관심이 있다.
이를 위해, $h(x)$를 전송하고자 하는 스타일을 나타내는 이미지 $x$의 feature mapping이라고 하자. $X_t = tX_1 + (1 − t)X_0$라고 하면, $H_t = h(X_t)$는 다음과 같은 ODE를 따른다.
\[\begin{equation} \textrm{d}H_t = \nabla h (X_t)^\top (X_1 − X_0) \textrm{d}t \end{equation}\]따라서 스타일이 올바르게 전송되도록 하기 위해, $H_t^\prime = h(Z_t)$이고 \(\textrm{d}Z_t = v(Z_t, t)\textrm{d}t\)가 가능한 한 $H_t$에 근접하도록 $v$를 학습시킨다.
\[\begin{equation} \textrm{d} H_t^\prime = \nabla h(Z_t)^\top v(Z_t, t)\textrm{d}t \end{equation}\]이기 때문에, 다음과 같은 loss를 최소화한다.
\[\begin{equation} \min_v \int_0^1 \mathbb{E} \left[ \| \nabla h (X_t)^\top (X_1 - X_0 - v (X_t, t)) \|_2^2 \right] \textrm{d}t \end{equation}\]다음은 다양한 도메인 간에 $N = 100$ Euler step으로 시뮬레이션된 1-rectified flow의 샘플들이다.

다음은 1-rectified flow와 2-rectified flow의 샘플들이다.


3. Domain Adaptation
저자들은 domain adaptation을 적용하기 위해 먼저 학습 데이터와 테스트 데이터를 모두 사전 학습된 모델의 latent 표현에 매핑하고, latent 표현에 대한 rectified-flow를 구성하였다.
다음은 다른 방법들과 domain adaptation 성능을 비교한 표이다. (정확도가 높을수록 성능이 좋음)
