[논문리뷰] RealFill: Reference-Driven Generation for Authentic Image Completion
SIGGRAPH 2024. [Paper] [Page]
Luming Tang, Nataniel Ruiz, Qinghao Chu, Yuanzhen Li, Aleksander Holynski, David E. Jacobs, Bharath Hariharan, Yael Pritch, Neal Wadhwa, Kfir Aberman, Michael Rubinstein
Google Research | Cornell University
28 Sep 2023

Introduction
대부분의 경우 단 한 장의 사진으로 완벽한 각도, 구도, 타이밍을 포착할 수 없다. 불행하게도 경험 자체를 다시 할 수 없는 것처럼 캡처된 이미지의 이러한 요소도 마찬가지로 변경할 수 없다. 본 논문에서는 Authentic Image Completion (진정한 이미지 완성)이라고 부르는 이 문제에 초점을 맞추었다. 몇 개의 레퍼런스 이미지(최대 5개)와 대략 동일한 장면(그러나 배열이나 모양이 다름)을 캡처하는 하나의 타겟 이미지가 주어지면 타겟 이미지의 누락된 영역을 원래 장면에 충실한 고품질 이미지 콘텐츠로 채우는 것을 목표로 한다. 실질적인 이점을 위해 타겟 이미지와 레퍼런스 이미지가 매우 다른 시점, 환경 조건, 카메라 조리개, 이미지 스타일 또는 심지어 움직이는 물체를 가질 수 있는 보다 까다롭고 제한되지 않은 설정에 특히 중점을 두었다.
이 문제의 변형을 해결하기 위한 접근 방식들은 고전적인 기하학 기반 파이프라인을 사용하여 제안되었다. 이러한 방법은 장면 구조를 정확하게 추정할 수 없는 경우 치명적인 실패에 직면하는 경향이 있다. 반면, 최근의 생성 모델, 특히 diffusion model은 이미지 인페인팅 및 아웃페인팅에서 강력한 성능을 보여주었다. 그러나 diffusion model은 텍스트 프롬프트에 의해서만 가이드되고 레퍼런스 이미지의 콘텐츠를 활용하기 위한 메커니즘이 부족하기 때문에 실제 장면 구조와 세밀한 디테일을 복구하는 데 어려움을 겪는다.
본 논문은 RealFill이라는 간단하면서도 효과적인 레퍼런스 기반 이미지 완성 프레임워크를 제시하였다. 특정 장면에 대해 먼저 레퍼런스 이미지와 타겟 이미지에 대해 사전 학습된 인페인팅 diffusion model을 fine-tuning하여 개인화된 생성 모델을 만든다. 이러한 fine-tuning 과정은 적응된 모델이 좋은 이미지 prior를 유지할 뿐만 아니라 입력 이미지에서 장면의 콘텐츠, 조명, 스타일을 학습하도록 설계되었다. 그런 다음 이 fine-tuning된 모델을 사용하여 표준 diffusion 샘플링 프로세스를 통해 타겟 이미지에서 누락된 영역을 채운다. 생성적 inference의 확률론적 특성 때문에 저자들은 생성된 콘텐츠와 레퍼런스 이미지 간에 correspondence가 존재해야 한다는 사실을 활용하여 고품질 생성의 작은 집합을 자동으로 선택하는 correspondence 기반 시드 선택을 제안하였다. 특히, 레퍼런스 이미지와 키포인트 correspondence가 너무 적은 샘플을 필터링한다. 필터링 프로세스는 고품질 모델 출력을 선택하는 데 사람이 개입할 필요성을 크게 줄인다.
RealFill은 실제 장면 콘텐츠로 타겟 이미지를 매우 효과적으로 인페인팅하거나 아웃페인팅할 수 있다. 가장 중요한 것은 레퍼런스 이미지와 타겟 이미지 간의 큰 차이를 처리할 수 있다는 것이다. 이는 이전의 기하학적 기반 접근 방식에서는 매우 어려운 일이다. 이미지 완성을 위한 기존 벤치마크는 주로 작은 인페인팅과 레퍼런스 이미지와 타겟 이미지 간의 최소 변경에 중점을 두었다. 앞서 언급한 까다로운 예시를 정량적으로 평가하기 위해 저자들은 ground-truth와 함께 10개의 인페인팅 및 23개의 아웃페인팅 예제가 포함된 데이터셋을 수집하고 RealFill이 여러 이미지 유사성 측정 항목에서 큰 차이로 baseline보다 성능이 우수하다는 것을 보여주었다.
Method
1. Reference-Driven Image Completion
무작위로 캡처된 레퍼런스 이미지 세트(최대 5개)가 주어지면 대략 동일한 장면의 타겟 이미지를 완성 (즉, 아웃페인팅 또는 인페인팅)하는 것이 목표이다. 출력 이미지는 그럴듯하고 사실적일 뿐만 아니라 레퍼런스 이미지에 충실하여 실제 장면에 있었던 콘텐츠와 장면 디테일을 복원해야 한다. 본질적으로 저자들은 ‘있을 수 있었던 것’ 대신에 ‘있었어야 했던 것’을 생성하는 진정한 이미지 완성을 달성하고자 하였다. 저자들은 이를 의도적으로 입력에 대한 제약이 거의 없는 광범위하고 어려운 문제로 제시하였다. 예를 들어, 알 수 없는 카메라 포즈를 사용하여 매우 다른 시점에서 이미지를 촬영할 수 있다. 또한 조명 조건이나 스타일이 다를 수 있으며 장면은 잠재적으로 비정적일 수 있으며 이미지에 따라 레이아웃이 크게 다를 수 있다.
2. Problem Setup
모델에는 $n$ ($n \le 5$) 개의 레퍼런스 이미지 \(X_\textrm{ref} := \{I_\textrm{ref}^k\}_{k=1}^n\), 타겟 이미지 $I_\textrm{tgt} \in \mathbb{R}^{H \times W \times 3}$, 관련된 바이너리 마스크 \(M_\textrm{tgt} \in \{0, 1\}^{H \times W}\)가 제공된다. $M_\textrm{tgt}$에서 1은 채울 영역을 나타내고 0은 $I_\textrm{tgt}$의 기존 영역을 나타낸다. 모델은 마스크가 0인 $I_\textrm{tgt}$와 최대한 유사하게 픽셀이 유지되는 동시에 마스크가 1인 $X_\textrm{ref}$의 해당 콘텐츠에 충실한 조화된 이미지 $I_\textrm{out} \in \mathbb{R}^{H \times W \times 3}$을 생성할 것으로 예상된다. $X_\textrm{ref}$와 $I_\textrm{tgt}$의 콘텐츠 사이에는 인간이 그럴듯한 $I_\textrm{out}$을 상상할 수 있을 만큼 충분히 겹치는 부분이 있다고 가정한다.
3. RealFill
$X_\textrm{ref}$와 $I_\textrm{tgt}$ 사이에 기하학적 제약이 거의 없고 입력으로 사용할 수 있는 이미지가 거의 없으며 레퍼런스 이미지의 스타일, 조명 조건, 타겟의 포즈가 다를 수 있기 때문에 기하학 기반 접근 방식과 재구성 기반 접근 방식 모두에서 어렵다. 한 가지 대안은 제어 가능한 인페인팅 또는 아웃페인팅 방법을 사용하는 것이다. 그러나 이러한 방법은 프롬프트 기반이거나 단일 이미지 객체 중심이므로 복잡한 장면 수준 구조 및 디테일을 복구하는 데 사용하기 어렵다.
이를 위해 저자들은 먼저 레퍼런스 이미지 세트의 장면에 대한 지식을 주입하여 사전 학습된 생성 모델을 fine-tuning하였으며, 이를 통해 모델이 $I_\textrm{tgt}$와 $M_\textrm{tgt}$을 조건으로 $I_\textrm{out}$을 생성할 때 장면의 콘텐츠를 인식하도록 제안하였다.
Training
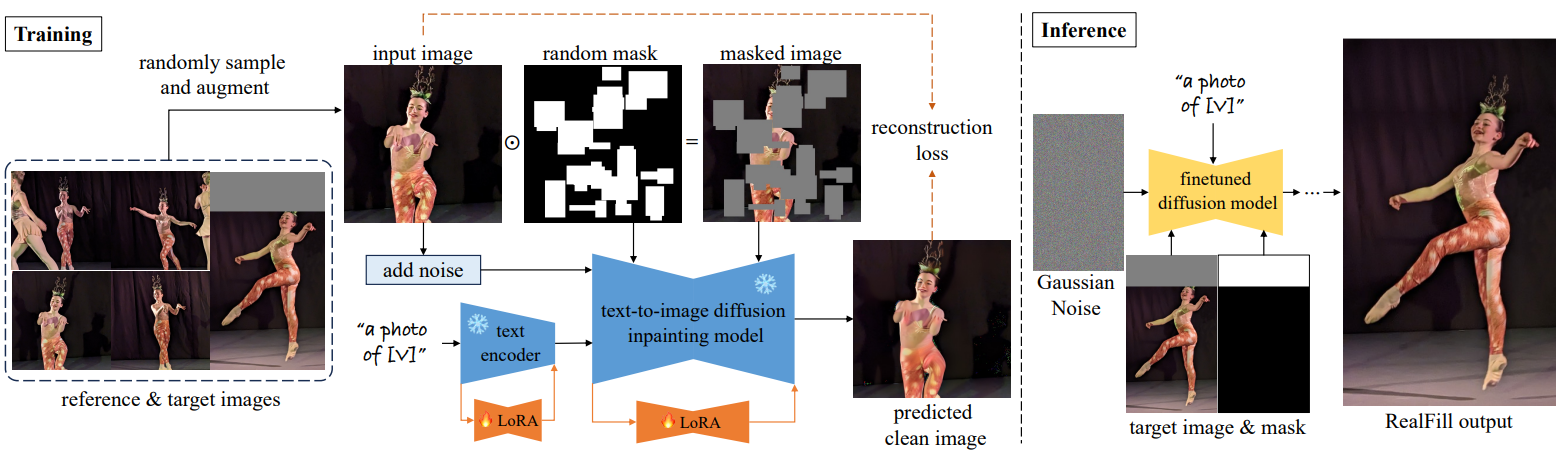
SOTA T2I diffusion 인페인팅 모델에서 시작하여 LoRA 가중치를 주입하고 무작위로 생성된 바이너리 마스크 \(m \in \{0, 1\}^{H \times W}\)를 사용하여 $X_\textrm{ref}$와 $I_\textrm{tgt}$ 모두에 대해 모델을 fine-tuning한다. Loss function은 다음과 같다.
여기서 \(x \in X_\textrm{ref} \cup \{I_\textrm{tgt}\}\)이고, $p$는 고정된 언어 프롬프트이고, $\odot$은 element-wise 곱셈을 나타내므로 $(1−m) \odot x$는 마스킹된 깨끗한 이미지이다. $I_\textrm{tgt}$의 경우 loss는 기존 영역, 즉 $M_\textrm{tgt}$의 0인 영역에서만 계산된다. 저자들은 Stable Diffusion v2 인페인팅 모델을 사용하고 LoRA 레이어를 텍스트 인코더와 U-Net에 주입하여 fine-tuning한다. Dreambooth를 따라 $p$를 희귀 토큰, 즉 “a photo of [$V$]”를 포함하는 문장으로 수정한다. 각 학습 예제에 대해 여러 개의 무작위 직사각형을 생성하고 합집합이나 합집합의 여집합을 취하여 최종 무작위 마스크 $m$을 얻는다. Fine-tuning 파이프라인은 위 그림에 나와 있다.
Inference
학습 후에는 DDPM sampler를 사용하여 $p$, $I_\textrm{tgt}$, $M_\textrm{tgt}$을 조건으로 이미지 $I_\textrm{gen}$을 생성한다. 그러나 $I_\textrm{tgt}$의 기존 영역이 $I_\textrm{gen}$에서 왜곡된다. 이 문제를 해결하기 위해 먼저 마스크 $M_\textrm{tgt}$를 흐리게 한 다음 이를 사용하여 $I_\textrm{gen}$과 $I_\textrm{tgt}$를 알파 합성한다. 그러면 기존 영역이 완전히 복구되고 생성된 영역 경계에서 부드러운 전환이 이루어지는 최종 $I_\textrm{out}$이 생성된다.
Correspondence-Based Seed Selection
Diffusion inference process는 확률론적이다. 즉, 동일한 입력 이미지 조건이 샘플링 프로세스에 대한 입력 시드에 따라 생성된 이미지 수에 관계없이 생성될 수 있다. 이러한 확률론적 특성으로 인해 생성된 결과의 품질에 차이가 발생하는 경우가 많으며 고품질 샘플을 선택하기 위해 사람의 개입이 필요한 경우가 많다. 생성된 출력 모음에서 좋은 샘플을 식별하는 연구가 있지만 이는 아직 해결되지 않은 문제로 남아 있다.
그럼에도 불구하고 본 논문이 제안한 진정한 이미지 완성 문제는 보다 일반적인 문제 설명의 특별한 경우이다. 특히 레퍼런스 이미지는 장면의 실제 콘텐츠에 대한 groung-truth 신호를 제공하며 고품질 출력을 식별하는 데 사용될 수 있다. 특히, 저자들은 $I_\textrm{out}$과 $X_\textrm{ref}$ 사이의 이미지 feature correspondence 수는 결과가 레퍼런스 이미지에 충실한지 대략적으로 정량화하는 측정 기준으로 사용될 수 있음을 발견했다.
저자들은 correspondence 기반 시드 선택을 제안하였다. 먼저 출력 batch (ex. \(\{I_\textrm{out}\}\))를 생성하고 $X_\textrm{ref}$와 각 $I_\textrm{out}$의 채워진 영역 간의 correspondence 집합을 추출한다. 그런 다음 일치하는 키포인트 수에 따라 생성된 결과 \(\{I_\textrm{out}\}\)의 순위를 매긴다. 이를 통해 생성을 자동으로 고품질 결과로 필터링할 수 있다. 이 방법은 최상의 샘플을 선택하는 데 인간 개입의 필요성을 크게 완화한다.
Experiments
- Fine-tuning
- iteration: 2,000
- batch size: 16
- GPU: NVIDIA A100 1개
- LoRA rank: 8
- dropout: 0.1
- learning rate
- U-Net: $2 \times 10^{-4}$
- 텍스트 인코더: $4 \times 10^{-5}$
1. Qualitative Results
다음은 RealFill로 레퍼런스 기반 아웃페인팅을 수행한 결과이다.

다음은 RealFill로 레퍼런스 기반 인페인팅을 수행한 결과이다.

2. Comparisons
레퍼런스 기반 이미지 완성을 위한 기존 벤치마크는 주로 작은 영역을 다시 그리는 데 중점을 두고 레퍼런스 이미지와 타겟 이미지 사이에 기껏해야 아주 사소한 변경이 있다고 가정한다. 본 논문이 타겟으로 한 예시를 더 잘 평가하기 위해 저자들은 자체 데이터셋인 RealBench를 만들었다. RealBench는 33개 장면 (아웃페인팅 23개, 인페인팅 10개)으로 구성되며, 각 장면에는 레퍼런스 이미지 세트 $X_\textrm{ref}$, 채울 타겟 이미지 $I_\textrm{tgt}$, 누락된 영역을 나타내는 바이너리 마스크 $M_\textrm{tgt}$, ground-truth 결과 $I_\textrm{gt}$가 포함된다. 각 장면의 레퍼런스 이미지 수는 1에서 5까지 다양하다. 데이터셋에는 시점 변경, 초점 흐려짐, 조명 변경, 스타일 변경, 피사체 포즈 변경과 같이 레퍼런스 이미지와 타겟 이미지 간의 상당한 차이가 있는 다양하고 까다로운 시나리오가 포함되어 있다.
Quantitative Comparison
다음은 RealBench에서 RealFill을 다른 basline들과 비교한 표이다.

Qualitative Comparison
다음은 RealBench에서 RealFill을 다른 basline들과 비교한 결과이다.

Correspondence-Based Seed Selection
다음은 correspondence 기반 시드 선택에서 필터링 비율에 따른 결과를 비교한 표이다.

다음은 주어진 레퍼런스 이미지에 대한 여러 RealFill 출력을 매칭된 키포인트 수와 함께 나타낸 것이다.

Discussion
1. Would other baselines work?
Image Stitching

상업용 이미지 스티칭 소프트웨어는 위 그림에서 조명 변화가 큰 경우처럼 레퍼런스 이미지와 타겟 이미지 사이에 극적인 차이가 있는 경우 출력을 생성하지 못한다. 반면 RealFill은 충실하고 고품질의 결과를 생성한다.
Vanilla DreamBooth

Vanilla Dreambooth, 즉 레퍼런스 이미지에서 표준 Stable Diffusion 모델을 fine-tuning하고 이를 사용하여 누락된 영역을 채우는 것은 RealFill에 비해 훨씬 더 나쁜 결과를 가져온다. 위 그림은 다양한 수준의 강도 hyperparameter에 대한 다양한 샘플을 보여준다.
2. What makes RealFill work?

RealFill은 빈 이미지를 입력으로 컨디셔닝할 때 여러 장면 변형을 생성할 수 있다. 예를 들어 첫 번째 행과 두 번째 행에 사람이 추가되거나 제거된다. 이는 fine-tuning된 모델이 장면 내부의 요소를 연관시킬 수 있음을 시사한다.

레퍼런스 이미지와 타겟 이미지가 동일한 장면을 묘사하지 않는 경우에도 fine-tuning 모델은 의미상 합리적인 방식으로 레퍼런스 콘텐츠를 타겟 이미지에 융합할 수 있으며, 이는 입력 이미지 간의 실제 또는 가상의 correspondence들을 모두 캡처한다는 것을 의미한다.
3. Limitations

- RealFill은 입력 이미지에 대해 기울기 기반의 fine-tuning 과정을 거쳐야 하기 때문에 상대적으로 느리고 실시간과는 거리가 멀다.
- 레퍼런스 이미지와 타겟 이미지 간의 시점 변화가 급격할 때 3D 장면을 충실하게 복구하지 못한다. 특히 단일 참조 이미지만 있는 경우에는 더욱 그렇다. 예를 들어, 위 그림의 첫 번째 행에서 볼 수 있듯이 레퍼런스 이미지는 측면에서 촬영되고 타겟 이미지는 중앙에서 촬영되었다. RealFill 출력은 얼핏 그럴듯해 보이지만 허스키의 포즈는 레퍼런스와 다르다. 예를 들어 왼쪽 발은 쿠션 사이의 틈에 있어야 한다.
- RealFill은 사전 학습된 기본 모델에서 상속된 이미지 prior에 주로 의존하기 때문에 기본 모델이 어려워하는 케이스를 처리하지 못한다. 예를 들어 Stable Diffusion은 텍스트, 사람 얼굴, 신체 부위와 같은 세밀한 이미지 디테일을 생성하는 경우 효율성이 떨어지는 것으로 알려져 있다. 위 그림의 두 번째 행에서 매장 표시의 철자가 틀린 경우는 RealFill의 경우에도 마찬가지이다.