[논문리뷰] ReVideo: Remake a Video with Motion and Content Control
NeurIPS 2024. [Paper] [Page] [Github]
Chong Mou, Mingdeng Cao, Xintao Wang, Zhaoyang Zhang, Ying Shan, Jian Zhang
Peking University | ARC Lab, Tencent PCG | University of Tokyo
22 May 2024

Introduction
모션은 동영상의 중요한 측면이지만 동영상 모션 편집에 대한 연구는 여전히 제한적이다. 일부 방법들은 궤적 기반 또는 박스 기반의 모션 가이드와 박스 기반 모션 guidance를 사용한 동영상 생성을 탐색하지만 모션 편집을 지원하지 않는다. 또한 다른 방법들은 한 동영상에서 다른 동영상으로 모션을 전송할 수 있지만 수정할 수는 없다.
본 논문의 목표는 동영상의 특정 영역에서 콘텐츠와 모션을 정확하게 편집하는 것이다. 저자들은 첫 번째 프레임을 수정하고 궤적 선을 모션 제어 신호로 설정하여 상호 작용하기 쉬운 파이프라인을 만들었다. 모든 프레임의 다른 편집되지 않은 콘텐츠는 편집 결과에 유지되어야 하며 편집 효과와 병합되어야 한다.
그러나 편집되지 않은 콘텐츠를 모션이 지정된 새 콘텐츠와 융합하는 것은 어려우며, 그 이유는 주로 두 가지이다.
- 학습 불균형: 편집되지 않은 콘텐츠는 dense하고 배우기 쉬운 반면, 모션 궤적은 sparse하고 추상적이어서 배우기 어렵다.
- 조건 coupling: 편집되지 않은 콘텐츠는 시각적 및 프레임 간 모션 정보를 모두 제공하므로 모델은 모션 추정에 이를 의존하게 되고. 배우기 어려운 궤적 선을 무시한다.
이러한 과제를 해결하기 위해, 저자들은 편집되지 않은 콘텐츠와 모션이 정의된 새로운 콘텐츠를 조화롭게 하는 3단계 학습 전략을 설계하여 다양한 조건을 조화롭게 제어할 수 있도록 하였다. 또한, 이 두 조건을 서로 다른 diffusion step과 공간적 위치에서 융합하는 Spatiotemporal Adaptive Fusion Module을 설계하였다. 나아가, 단일 제어 모듈을 통해 모션 및 콘텐츠 조건을 동영상 생성에 컴팩트하게 주입할 수 있다.
이러한 기술을 사용하면 사용자는 첫 번째 프레임을 수정하고 궤적 선을 그려 동영상의 특정 영역을 편리하게 편집할 수 있다. 특히, ReVideo는 단일 영역 편집에 국한되지 않고 여러 영역을 병렬로 편집할 수 있다.
Method
1. Task Formulation and Some Insights
Task 정의
본 논문의 목적은 시각 정보와 모션 정보를 포함하여 동영상을 로컬로 편집하는 것이다. 또한 동영상의 편집되지 않은 콘텐츠는 변경되지 않아야 한다. 따라서 조건부 동영상 생성에는 세 가지 제어 신호가 포함된다.
- 편집된 콘텐츠
- 편집되지 않은 영역의 콘텐츠
- 편집된 영역의 모션 조건
동영상의 첫 번째 프레임을 수정한 다음 후속 동영상 프레임에 전파하여 콘텐츠를 편집한다. 모션 조건의 경우 궤적 선을 제어 신호로 사용한다. 구체적으로 모션 조건에는 $N$ 프레임 동영상에 대한 $N$개의 map도 포함된다. 각 map은 2개의 채널로 구성되어 이전 프레임에 비해 수평 및 수직 방향으로 이동한 포인트의 움직임을 나타낸다. 편집되지 않은 콘텐츠는 마스킹된 동영상으로 제공된다.
Notation
- 편집된 첫 번째 프레임: \(\textbf{c}_\textrm{ref} \in \mathbb{R}^{3 \times W \times H}\)
- 모션 조건: \(\textbf{c}_\textrm{mot} \in \mathbb{R}^{N \times 2 \times W \times H}\)
- 편집되지 않은 콘텐츠: \(\textbf{c}_\textrm{con} = \textbf{V} \cdot \textbf{M}\)
- 원본 동영상: $\textbf{V} \in \mathbb{R}^{N \times 3 \times W \times H}$
- 편집 영역 마스크: $\textbf{M} \in \mathbb{R}^{1 \times 1 \times W \times H}$
SVD를 사전 학습된 base model로 채택했기 때문에 image-to-video 기능이 자연스럽게 편집된 첫 번째 프레임의 입력 포트로 작용할 수 있다. 편집되지 않은 콘텐츠와 모션 궤적의 경우, 추가 제어 모듈을 학습시켜 이를 생성 프로세스로 가져온다.
궤적 샘플링
학습하는 동안 동영상에서 궤적을 추출하여 모션 조건 \(\textbf{c}_\textrm{mot}\)을 제공하는 것이 필수적이다.
- 궤적 샘플링을 시작할 때 grid를 사용하여 dense한 샘플링 포인트를 sparsify하여 \(N_\textrm{init}\)개의 초기 포인트를 얻는다.
- 이러한 포인트 중에서 움직임이 큰 포인트는 궤적 제어를 학습하는 데 유익하다. 이러한 포인트를 필터링하기 위해 먼저 각 포인트에 모션 트래킹을 적용하여 경로 길이, 즉 \(\{l_0, \ldots, l_{N_\textrm{init}-1}\}\)을 얻는다.
- 이러한 길이들의 평균을 threshold \(l_\textrm{Th}\)로 사용하여 모션 길이가 \(l_\textrm{Th}\)보다 큰 포인트를 추출한다.
- 이러한 포인트들의 정규화된 길이를 샘플링 확률로 사용하여 $N$개의 포인트를 무작위로 샘플링한다.
- 높은 sparsity는 모델이 이러한 궤적에서 학습하는 데 도움이 되지 않으므로 Gaussian filter를 적용하여 부드러운 궤적 맵 \(\textbf{c}_\textrm{mot}\)을 얻는다.
Insights
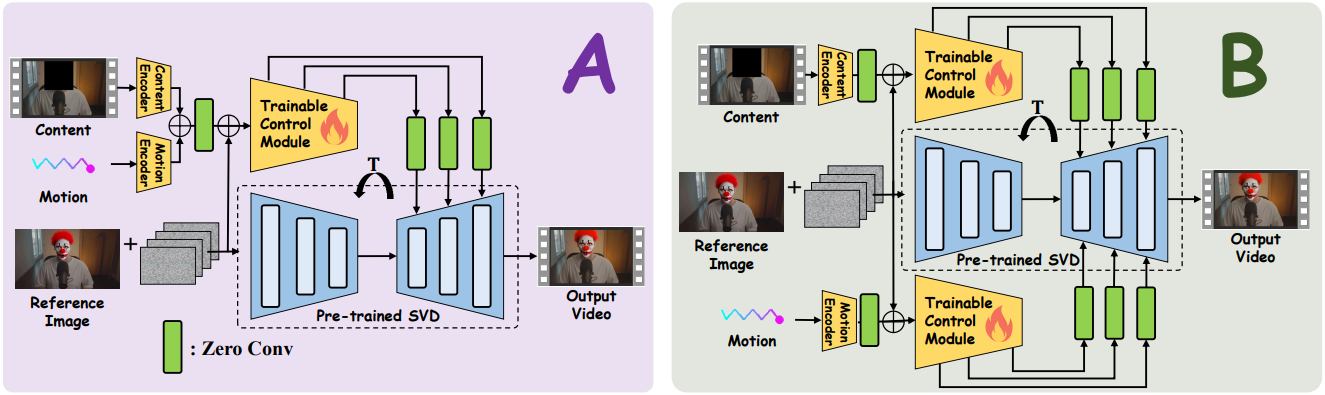
Naive한 구현은 ControlNet과 같은 추가 제어 모듈을 직접 학습시켜 모션 조건과 콘텐츠 조건을 diffusion 생성 프로세스에 주입하는 것이다. 이 디자인은 위 그림의 구조 A에 해당한다.
구체적으로, 입력에서 콘텐츠 인코더 $E_c$와 모션 인코더 $E_m$은 편집되지 않은 영역의 콘텐츠 조건 \(\textbf{c}_\textrm{con}\)과 편집 영역의 모션 조건 \(\textbf{c}_\textrm{mot}\)을 각각 임베딩한다. 이 두 임베딩은 직접 합산되어 융합된 조건 feature \(\mathbf{f}_c\)를 얻는다. 그런 다음 UNet 인코더의 복사본은 \(\mathbf{f}_c\)에서 멀티스케일 중간 feature를 추출하여 diffusion model의 해당 레이어에 더한다.
\[\begin{equation} \mathbf{y}_c = \mathcal{F} (\mathbf{z}_t, t, \mathbf{c}_\textrm{ref}; \Theta) + \mathcal{Z} (\mathcal{F} (\mathbf{z}_t + \mathcal{Z} (\mathbf{f}_c), t, \mathbf{c}_\textrm{ref}; \Theta)) \end{equation}\](\(\textbf{y}_c\)는 새로운 diffusion feature, $\mathcal{Z}$는 zero-conv의 함수, $\Theta$와 \(\Theta_c\)는 SVD 모델과 추가 제어 모듈의 파라미터)
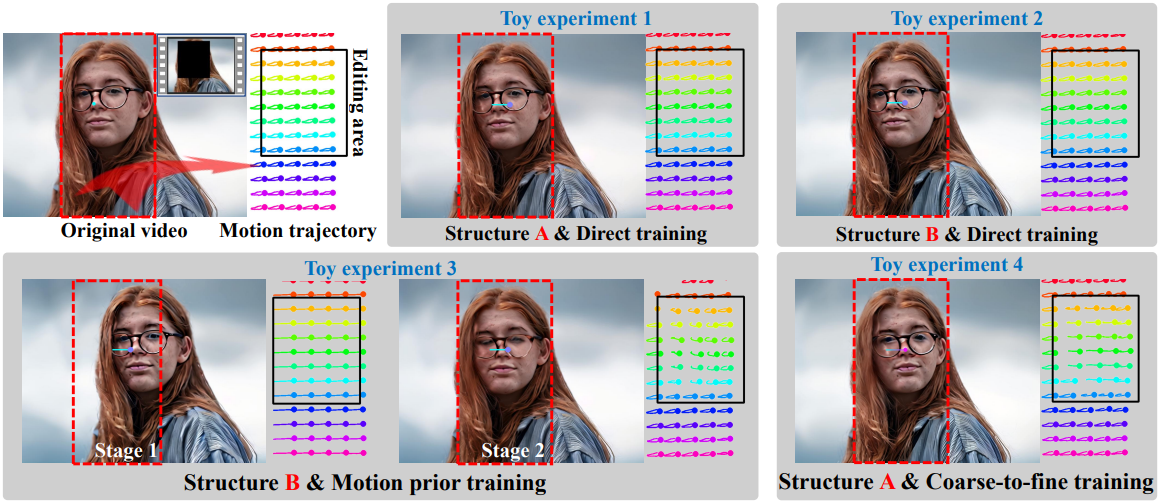
위 그림에서 볼 수 있듯이, 저자들은 이 아이디어를 기반으로 여러 가지 toy experiment들을 수행하였다. 입력 동영상에는 처음에 왼쪽으로 이동한 다음 오른쪽으로 이동하는 여성이 포함되어 있다. 편집 목표는 다른 콘텐츠는 변경하지 않고 얼굴 모션을 오른쪽으로 변경하는 것이다.
Toy experiment 1에서는 SVD를 고정하고 denoising score matching을 사용하여 제어 모듈을 학습시켰다. 그 결과, 콘텐츠 조건이 생성된 동영상의 편집되지 않은 영역을 정확하게 제어한다. 그러나 모션 조건에는 제어 효과가 없으며 편집 영역의 궤적 선(검은색 상자)은 편집되지 않은 영역과 일치한다. 가능한 이유는 하나의 제어 분기가 두 제어 조건을 동시에 처리하는 데 어려움이 있기 때문이다.
저자들은 이 가설을 확인하기 위해 구조 B를 학습시켜 이 두 조건을 별도로 처리하였다. Toy experiment 2는 모션 제어가 여전히 효과적이지 않음을 보여주며, 이는 문제가 네트워크 구조보다는 제어 학습에 기인한다는 것을 시사한다.
저자들은 모션 제어 학습을 강화하기 위해 구조 B의 학습을 두 단계로 나누었다. 첫 번째 단계에서는 모션 제어 모듈만 학습시켜 모션 제어 prior를 부여한다. 두 번째 단계에서는 모션 제어와 콘텐츠 제어를 함께 학습시킨다. Toy experiment 3의 결과는 모션 prior 학습이 좋은 동작 제어 능력을 생성하지만 제어 정확도가 약화되고 콘텐츠 제어를 도입한 후 편집되지 않은 콘텐츠의 영향을 받는다는 것을 보여준다.
이러한 toy experiment들 후에 저자들은 다음과 같은 통찰력을 얻었다.
- 편집되지 않은 콘텐츠의 조건은 시각적 정보를 포함할 뿐만 아니라 풍부한 프레임 간 모션 정보도 포함한다. Diffusion model은 sparse한 모션 궤적 제어를 무시하고, 더 쉽게 학습할 수 있는 조건으로서 편집되지 않은 콘텐츠를 통해 편집 영역의 모션을 예측하는 경향이 있다.
- 모션에 맞게 조정된 새 콘텐츠와 편집되지 않은 콘텐츠 간의 결합이 강해서 모션 prior와 별도 제어 분기를 사용하더라도 극복하기 어렵다.
- 모션 prior 학습은 모션에 맞게 조정된 콘텐츠와 편집되지 않은 콘텐츠를 분리하는 데 도움이 된다.
2. Coarse-to-fine Training Strategy
모션 제어 무시를 바로잡기 위해 저자들은 coarse-to-fine 학습 전략을 설계하였다. 구조 B는 높은 계산 비용이 있으며, 간결한 구조 A에서 편집되지 않은 콘텐츠와 모션에 맞게 조정된 새 콘텐츠를 공동 제어하고자 하였다.
모션 prior 학습
모션 궤적은 sparse하고 학습하기 어려운 제어 신호이다. Toy experiment 3은 모션 prior 학습이 모션에 맞게 조정된 콘텐츠와 편집되지 않은 콘텐츠 간의 결합을 완화할 수 있음을 보여준다. 따라서 첫 번째 단계에서는 모션 궤적 제어만 학습시켜 제어 모듈이 좋은 모션 제어 prior를 가질 수 있도록 한다.
Decoupling 학습

첫 번째 단계의 제어 모듈을 기반으로 두 번째 단계의 학습은 편집되지 않은 영역의 콘텐츠 제어를 추가하는 것을 목표로 한다. Toy experiment 3은 좋은 모션 제어 prior가 있더라도 편집되지 않은 콘텐츠 조건을 도입한 후에는 모션 제어의 정밀도가 여전히 저하됨을 보여준다.
따라서 저자들은 이 단계에서 모션 제어와 콘텐츠 제어를 분리하기 위한 학습 전략을 설계하였다. 학습 샘플 $\textbf{V}$의 편집 부분과 편집되지 않은 부분을 두 개의 다른 동영상, 즉 \(\textbf{V}_1\)과 \(\textbf{V}_2\)로 설정한다. 위 그림에서 볼 수 있듯이 \(\textbf{V}_1\)과 \(\textbf{V}_2\)는 편집 마스크 $\textbf{M}$을 통해 결합된다.
\[\begin{equation} \textbf{V} = \textbf{V}_1 \cdot \textbf{M} + \textbf{V}_2 \cdot (1 - \textbf{M}) \end{equation}\]편집 영역과 편집되지 않은 영역은 두 개의 다른 동영상에서 나오기 때문에 편집 영역의 모션 정보는 편집되지 않은 콘텐츠를 통해 예측할 수 없다. 따라서 학습 중에 콘텐츠 제어와 동작 제어를 분리할 수 있다.
Deblocking 학습
위 그림에서 볼 수 있듯이, decoupling 학습은 높은 정확도로 모션과 편집되지 않은 콘텐츠의 공동 제어를 달성하지만, 편집된 영역과 편집되지 않은 영역 간의 일관성이 깨져 경계에 블록 아티팩트가 생성된다. 이 문제를 바로잡기 위해 세 번째 학습 단계를 설계하여 블록 아티팩트를 제거한다.
이 단계의 학습은 두 번째 단계의 모델로 초기화되고 일반 동영상 데이터로 학습된다. 두 번째 단계의 분리된 모션 및 콘텐츠 제어를 보존하기 위해 제어 모듈과 SVD 모델의 temporal self-attention layer에서 key embedding \(\textbf{W}_k\)와 value embedding \(\textbf{W}_v\)만 fine-tuning한다. Toy experiment 4는 이 단계의 학습 후 모델이 블록 아티팩트를 제거하고 편집되지 않은 콘텐츠와 모션의 공동 제어를 유지함을 보여준다.
3. Spatiotemporal Adaptive Fusion Module
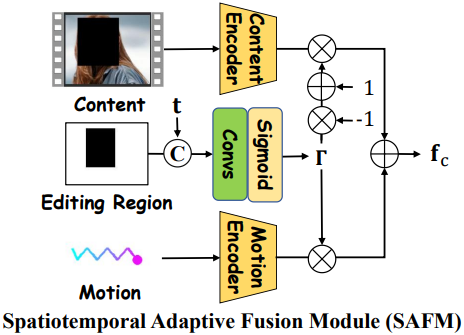
비록 coarse-to-fine 학습 전략이 콘텐츠 제어와 모션 제어의 분리를 달성하지만, 일부 복잡한 모션 궤적에서 상당한 실패 사례가 관찰된다. 저자들은 생성에서 편집되지 않은 콘텐츠와 모션 궤적의 제어 역할을 더욱 구별하기 위해, Spatiotemporal Adaptive Fusion Module (SAFM)을 설계하였다.
구체적으로, SAFM은 직접 합산하는 대신 편집 마스크 $\textbf{M}$을 통해 가중치 맵 $\Gamma$를 예측하여 모션 제어와 콘텐츠 제어를 융합한다. 게다가, diffusion 생성은 여러 step의 반복 프로세스이기 때문에, timestep 간의 제어 조건 융합은 적응적으로 조정되어야 한다. 따라서, 채널 차원에서 timestep $t$와 $\textbf{M}$을 연결하여 $\Gamma$ 예측을 가이드하는 시공간적 조건을 형성한다.
\[\begin{equation} \mathbf{f}_c = E_c (\mathbf{c}_\textrm{con}) \cdot \Gamma + E_m (\mathbf{c}_\textrm{mot}) \cdot (1 - \Gamma), \quad \Gamma = \mathcal{H} (\mathbf{M}, t) \end{equation}\]여기서 $\mathcal{H}$는 시공간 임베딩 함수이다. $\mathcal{H}$는 deblocking 학습 단계에서 \(\textbf{W}_k\), \(\textbf{W}_v\)와 공동으로 학습되어야 한다.
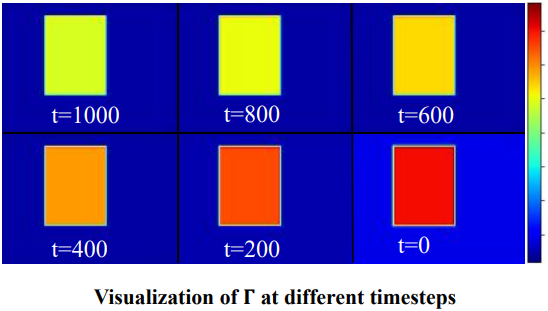
위 그림은 $\Gamma$를 여러 timestep에서 시각화한 것이며, $\Gamma$가 편집 영역의 공간적 특성을 학습하는 것을 볼 수 있다. 편집 영역에서는 모션 조건에 더 높은 가중치를 할당하고 편집되지 않은 영역에서는 콘텐츠 조건에 더 높은 가중치를 할당한다. 또한 $\Gamma$는 timestep $t$를 구별하는 법을 학습하고 $t$에 따라 선형적으로 조정된다.
Experiments
- 데이터셋: WebVid (텍스트-동영상 쌍 약 1,000만 개)
- 구현 디테일
- 해상도: 512$\times$320
- 편집 영역 크기: 최소 64$\times$64
- 궤적 개수: 1 ~ 10
- batch size: 각 GPU마다 4
- optimizer: Adam
- iteration: 각 단계마다 4만, 3만, 2만
- NVIDIA A100 GPU 4개에서 6일 소요
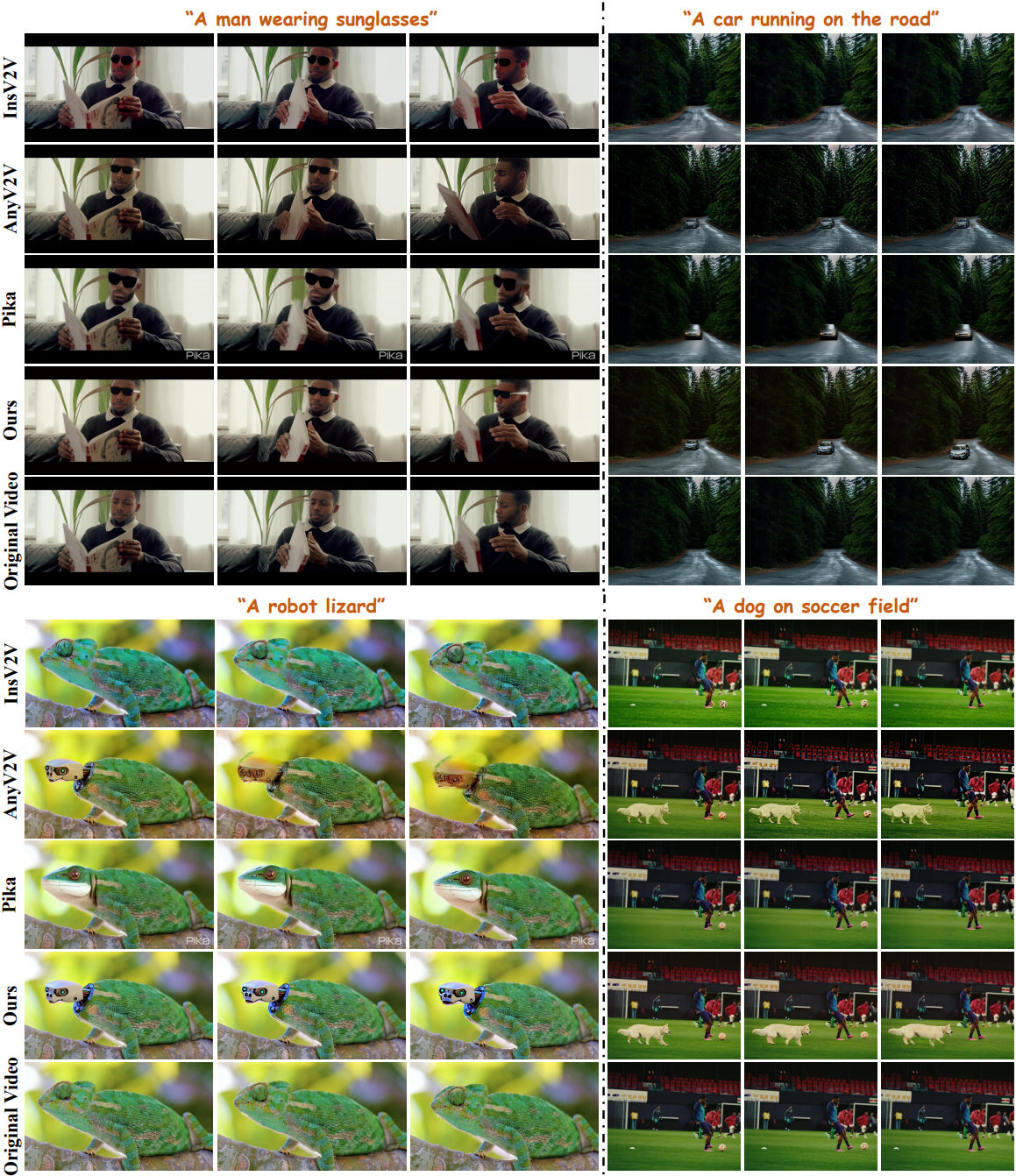
1. Comparison
다음은 다른 방법들과 ReVideo를 비교한 결과이다.

2. Ablation Study
다음은 ablation study 결과이다.
