[논문리뷰] Ranni: Taming Text-to-Image Diffusion for Accurate Instruction Following
CVPR 2024. [Paper] [Page] [Github]
Yutong Feng, Biao Gong, Di Chen, Yujun Shen, Yu Liu, Jingren Zhou
Alibaba Group | Ant Group
28 Nov 2023
Introduction
언어는 관점과 창의성을 전달하는 가장 직접적인 방법이다. 상상 속의 장면을 현실로 만들고자 할 때 첫 번째 선택은 언어 설명을 통해서이다. 최근 diffusion model의 발전으로 T2I 합성은 높은 충실도와 다양성 측면에서 유망한 결과를 보여준다. 그러나 보다 다양하게 분포되어 있는 구조화된 픽셀 기반의 이미지에 비해 언어의 표현력은 제한적이다. 이는 텍스트 설명을 정확하게 해당 이미지로 충실하게 변환하는 text-to-image (T2I) 합성을 방해한다. 따라서 현재 모델은 quantity-awareness, attribute binding, spatial relationship, multi-object와 같은 복잡한 프롬프트를 생성할 때 문제에 직면한다.
전문 화가와 디자이너의 경우 언어뿐만 아니라 CSS, 디자인 소프트웨어 등 다양한 도구를 사용하여 상상한 장면을 유형의 형태로 표현한다. 이러한 도구를 사용하면 공간적 위치, 크기, 관계, 스타일 등의 관점에서 물체를 정확하고 풍부하게 표현할 수 있다. 이미지에 가까워짐으로써 보다 정확한 표현과 보다 쉬운 조작이 가능해진다.
본 논문의 목표는 T2I 방식의 편리함을 제공하는 동시에 전문 도구와 유사한 정확한 표현과 풍부한 조작 기능을 제공하는 새로운 이미지 생성 접근 방식을 도입하는 것이다. 이를 위해 LLM의 도움으로 자연어를 미들웨어로 변환하는 향상된 T2I 생성 프레임워크인 Ranni를 제시하였다. Semantic panel이라고 부르는 미들웨어는 텍스트와 이미지 사이의 다리 역할을 한다. 텍스트 설명에 대한 정확한 이해를 제공하고 직관적인 이미지 편집이 가능하다. Semantic panel은 이미지에 나타나는 모든 시각적 개념으로 구성된다. 각 개념은 물체의 구조화된 표현을 나타낸다. 텍스트 설명, bounding box, 색상, 키포인트와 같은 다양한 속성을 사용하여 설명한다.
Semantic panel을 도입함으로써 text-to-panel과 panel-to-image라는 두 가지 하위 task를 통해 text-to-image 생성을 완화한다. Text-to-panel 중에 텍스트 설명은 LLM에 의해 시각적 개념으로 파싱되며, 이는 semantic panel 내부에 수집되고 정렬된다. Panel-to-image 프로세스는 panel을 제어 신호로 인코딩하여 diffusion model이 각 개념의 디테일을 캡처하도록 가이드한다. 효율적인 학습을 위해 자동 데이터 준비 파이프라인을 사용한다. 인식 모델들을 사용하여 시각적 개념을 추출하여 기존 데이터셋의 텍스트-이미지 쌍을 확장한다.
Ranni는 semantic panel을 기반으로 생성된 이미지를 추가로 편집할 수 있는 보다 직관적인 방법도 제공한다. 기존 diffusion 기반 방법은 수정된 프롬프트나 텍스트 명령을 통해 편집 의도를 암시적으로 이해한다. 반면, Ranni는 semantic panel의 업데이트를 통해 편집 의도를 명시적으로 매핑한다. 시각적 개념의 풍부한 속성을 사용하여 추가, 제거, 크기 조정, 위치 변경, 교체, 속성 수정의 6가지 단위 연산을 구성하여 대부분의 편집 명령을 통합할 수 있다. Semantic panel 업데이트는 사용자 인터페이스를 통해 수동으로 수행하거나 LLM을 통해 자동으로 수행할 수 있다.
Methodology

1. Bridging Text and Image with Semantic Panel
Semantic panel을 이미지의 모든 시각적 개념을 조작하기 위한 작업 공간으로 정의한다. 각 시각적 개념은 물체를 나타내며 위치나 색상과 같은 시각적으로 접근 가능한 속성을 포함한다. Semantic panel은 텍스트와 이미지 사이의 미들웨어 역할을 하며 텍스트에 대한 구조화된 모델링과 이미지에 대한 압축 모델링을 제공한다. Panel을 통합함으로써 텍스트를 이미지에 직접 매핑해야 하는 부담을 덜어준다. 각 개념에는
- Semantic 정보에 대한 텍스트 설명
- 위치 및 크기에 대한 bounding box
- 스타일에 대한 기본 색상
- 모양에 대한 키포인트
등의 속성이 포함된다. 그런 다음 T2I 생성은 자연스럽게 text-to-panel과 panel-to-image라는 두 가지 하위 task로 나뉜다.
Text-to-Panel을 사용하려면 프롬프트를 이해하는 능력과 시각적 콘텐츠에 대한 풍부한 지식이 필요하다. 이 task에 LLM을 사용한다. 저자들은 입력 텍스트에 해당하는 시각적 개념을 상상하기 위해 LLM을 요청하는 시스템 프롬프트를 설계하였다. Chain-of-Thought에서 영감을 받아 개념의 여러 속성을 생성할 때 이를 순차적으로 수행한다. 전체 물체 세트는 먼저 텍스트 설명을 사용하여 생성된다. 그런 다음 경계 상자와 같은 세부 속성이 생성되어 각 물체를 향해 정렬된다. 채팅 템플릿 디자인과 전체 대화의 예는 보충 자료에서 확인할 수 있다. LLM의 zero-shot 능력 덕분에 올바른 출력 형식으로 상세한 semantic panel을 생성할 수 있다. 또한 보다 세부적인 속성에 대해 시각적 개념을 더 잘 이해할 수 있도록 이미지-텍스트-panel로 구성된 대규모 데이터셋으로 fine-tuning하여 LLM의 성능을 향상시킨다.
Panel-to-Image는 조건부 이미지 생성에 초점을 맞춘다. 저자들은 latent diffusion model (LDM)을 backbone으로 사용하여 이를 구현하였다. 먼저 semantic panel 내의 모든 시각적 개념이 이미지 latent와 동일한 모양을 갖는 조건 맵으로 인코딩된다. 다양한 속성의 인코딩은 다음과 같다.
- 텍스트 설명: CLIP 텍스트 임베딩
- Bounding box: 박스 안에 1이 있는 바이너리 마스크
- 색상: 인덱싱된 학습 가능한 임베딩
- 키포인트: 키포인트에 1이 있는 바이너리 히트맵
이러한 조건은 학습 가능한 convolution layer를 사용하여 집계된다. 마지막으로 모든 물체의 상태 맵을 평균하여 제어 신호를 만든다.
Diffusion model을 제어하기 위해 입력에 조건 맵을 추가한다. 그런 다음 모델은 semantic panel 데이터셋에서 fine-tuning된다. Inference하는 동안 diffusion model의 cross-attention layer를 조작하여 제어를 더욱 강화한다. 특히, 각 시각적 개념에 대해 텍스트 설명 단어에 우선순위를 부여하여 bounding box 내부의 이미지 패치의 attention map을 제한한다.
2. Interactive Editing with Panel Manipulation
사용자는 추가 이미지 편집을 위해 semantic panel에 액세스할 수 있다. 프롬프트 엔지니어링과 달리 Ranni를 사용한 이미지 편집은 더 자연스럽고 간단하다. 각 편집 연산은 semantic panel 내의 시각적 개념 업데이트에 해당한다. Semantic panel의 구조를 고려하여
- 새 물체 추가
- 기존 물체 제거
- 다른 물체 교체
- 물체 크기 조정
- 물체 이동
- 물체 속성 재편집
의 6가지 단위 연산을 정의한다. 사용자는 이러한 연산을 수동으로 수행하거나 LLM의 도움을 받을 수 있다. 또한 semantic panel을 지속적으로 업데이트하여 이미지를 점진적으로 개선하여 보다 정확하고 개인화된 출력을 얻을 수도 있다.
Semantic panel을 업데이트한 후 새로운 시각적 개념을 활용하여 편집된 이미지 latent를 생성한다. 원본 이미지에 대한 불필요한 변경을 피하기 위해 바이너리 마스크 \(\textbf{M}_e\)를 사용하여 편집 가능한 영역으로 편집을 제한한다. 이전 semantic panel과 새 semantic panel의 차이를 기반으로 편집 가능한 영역, 즉 조정된 시각적 개념의 bounding box를 쉽게 결정할 수 있다. 원래 latent 표현과 현재 latent 표현을 각각 \(\textbf{x}_t^\textrm{old}\)와 \(\textbf{x}_t^\textrm{new}\)라 하면 업데이트된 표현은 다음과 같다.
\[\begin{equation} \hat{\textbf{x}}_t^\textrm{new} = \textbf{M}_e \textbf{x}_t^\textrm{new} + (1 - \textbf{M}_e) \textbf{x}_t^\textrm{old} \end{equation}\]3. Semantic Panel Dataset
저자들은 Ranni의 효율적인 학습을 위해 데이터셋 준비를 위한 완전 자동 파이프라인을 구축하였다.
Attribute Extraction
먼저 여러 리소스 (ex. LAION, WebVision)에서 5천만 개의 이미지-텍스트 쌍을 수집한다. 각 이미지-텍스트 쌍에 대해 모든 시각적 개념의 속성은 다음 순서로 추출된다.
- 텍스트 설명과 bounding box: Grounding DINO를 사용하여 텍스트 설명과 bounding box가 있는 물체 목록을 추출한다. 그런 다음 의미 없는 설명을 필터링하고 동일한 설명이 포함된 중복되는 박스를 제거한다.
- 색상: 각 bounding box에 대해 먼저 SAM을 사용하여 segmentation mask를 얻는다. 마스크 내부의 각 픽셀은 156색 팔레트에서 가장 가까운 색상의 인덱스에 매핑된다. 인덱스 빈도를 계산하고 비율이 5%보다 큰 상위 6개 색상을 선택한다.
- 키포인트: 키포인트는 Point++의 FPS 알고리즘을 사용하여 SAM 마스크 내에서 샘플링된다. 8개의 포인트가 샘플링되며, 가장 먼 FPS 거리가 threshold 0.1에 도달하면 조기에 중지된다.
Dataset Augmentation
저자들은 경험적으로 다음 전략을 사용하여 데이터셋을 늘리는 것이 효율적이라는 것을 알았다.
- 합성된 캡션: 이미지의 원래 캡션은 일부 물체를 무시하여 semantic panel이 불완전해질 수 있다. 이 문제를 해결하기 위해 LLaVA를 활용하여 여러 물체가 포함된 이미지를 찾고 이에 대한 보다 자세한 캡션을 생성한다.
- Pseudo 데이터 혼합: 공간 배치 능력을 향상시키기 위해 수동 규칙을 사용하여 pseudo 샘플을 만든다. 다양한 방향, 색상, 숫자를 가진 물체 풀에서 무작위 프롬프트를 생성한다. 그런 다음 지정된 규칙에 따라 무작위로 배열하여 semantic panel을 합성한다.
Experiments
1. Evaluation on Text-to-Image Alignment
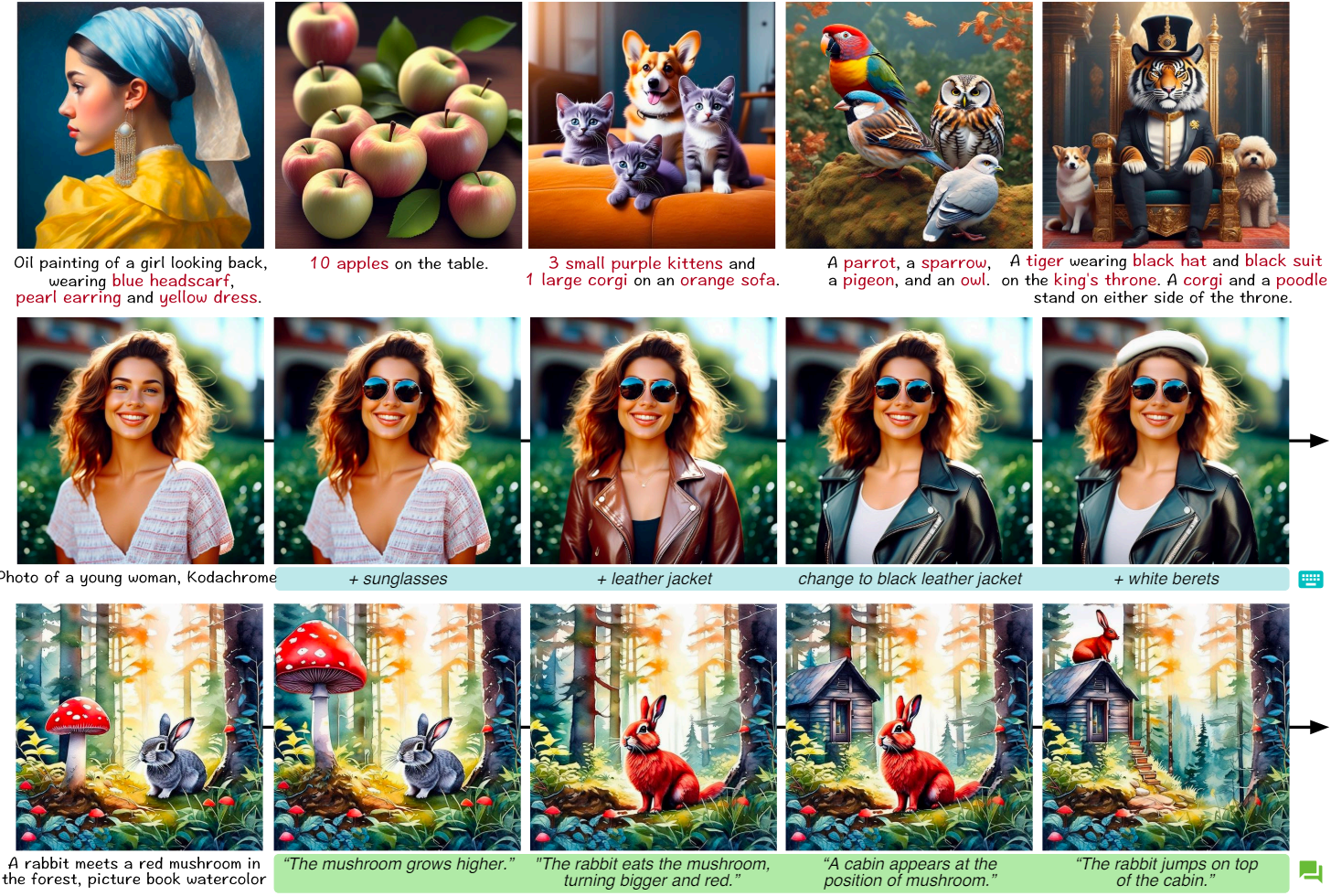
다음은 quantity-awareness 프롬프트에 대해 생성된 샘플들이다.

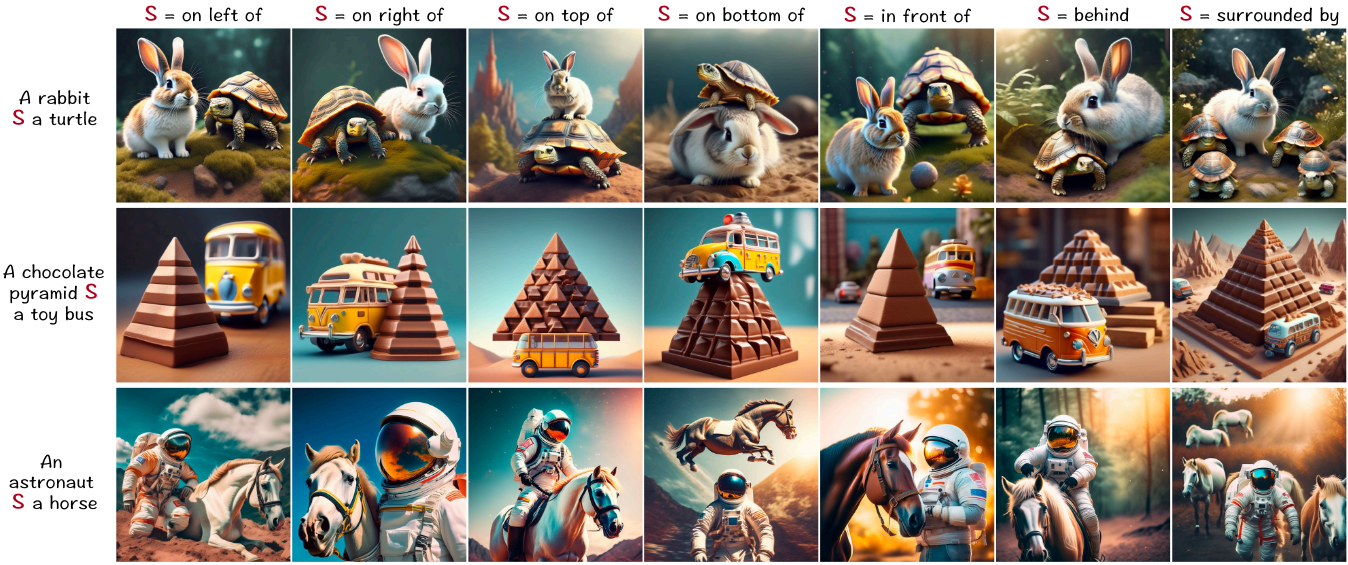
다음은 spatial relationship 프롬프트에 대해 생성된 샘플들이다.
다음은 attribute binding 프롬프트에 대해 생성된 샘플들이다. (a)는 색상 바인딩 프롬프트, (b)는 텍스처 바인딩 프롬프트이다.

다음은 multi-object 프롬프트에 대해 생성된 샘플들이다.

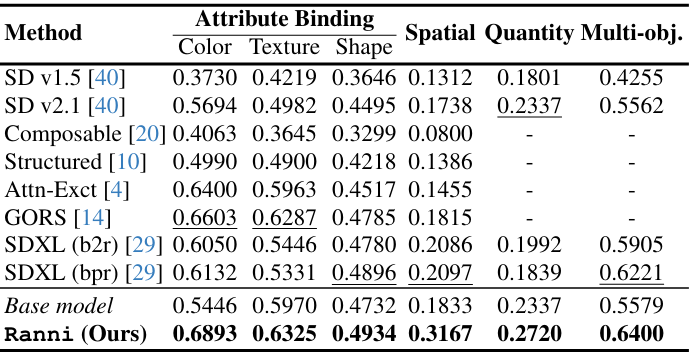
다음은 다양한 벤치마크에서 정렬 평가 결과를 비교한 표이다.
다음은 다른 방법들과 T2I 생성 결과를 비교한 것이다.

2. Evaluation on Interactive Generation
다음은 각 단위 연산에 대한 편집 결과와 panel 업데이트이다.

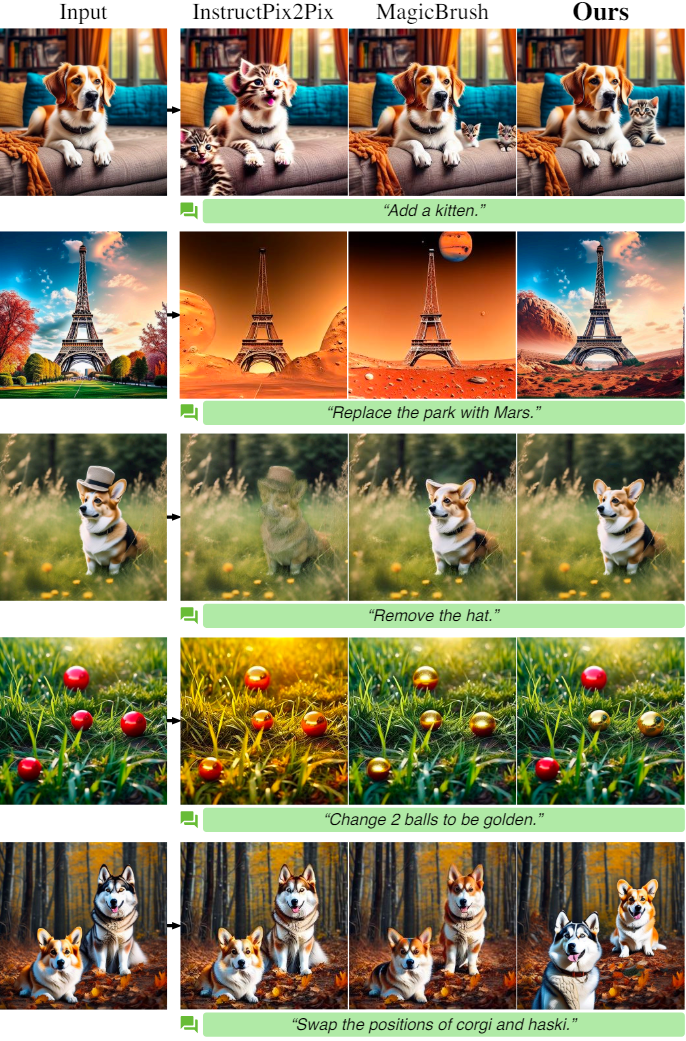
다음은 다른 방법들과 명령을 사용한 편집 결과를 비교한 것이다.
다음은 단위 연산으로 구성된 multi-round 편집 체인을 사용한 연속 생성 결과이다.

다음은 비슷한 레이아웃에서 생성된 샘플들이다.

다음은 다양한 LLM을 사용한 채팅 기반 생성 결과들이다.
