[논문리뷰] Tile-wise vs. Image-wise: Random-Tile Loss and Training Paradigm for Gaussian Splatting
ICCV 2025. [Paper]
Xiaoyu Zhang, Weihong Pan, Xiaojun Xiang, Hongjia Zhai, Liyang Zhou, Hanqing Jiang, Guofeng Zhang
SenseTime Research | Zhejiang University

Introduction
3DGS의 splatting 알고리즘은 렌더링 속도를 크게 향상시키지만, 타일 기반 멀티뷰 제약 조건을 통합하는 잠재력은 아직 충분히 탐구되지 않았다. 타일 기반 splatting은 모든 카메라 광선을 쿼리하는 대신 카메라 뷰에 보이는 Gaussian을 직접 splatting함으로써 실시간 렌더링을 달성하는 데 중요한 역할을 한다. 결과적으로 각 학습 이미지에 loss function을 정의하는 것은 직관적이고 간단한 선택이다.
이 접근 방식은 이미지 전체에 걸쳐 SSIM loss를 계산하는 데 이점이 있지만, 여러 시점의 gradient를 하나의 최적화 step에서 통합할 수 없다는 단점도 있다. 이와 대조적으로 NeRF는 일반적으로 pixel-wise loss를 최적화하며, mini-batch의 각 개별 광선은 전체 학습 데이터셋에서 무작위로 샘플링된다. 랜덤한 시점에서의 포인트별 샘플링은 보다 포괄적인 gradient를 제공하지만, 전체 장면의 구조적 정보를 간과하게 된다.
이 문제를 해결하기 위해, 저자들은 멀티뷰 제약 조건과 구조적 정보를 splatting 과정에 통합하는 타일 기반 학습 패러다임을 제안하였다. 여러 학습 시점에서 타일들을 샘플링하며, 각 타일은 splatting의 최소 단위이다. 타일 기반 학습 패러다임은 3DGS 렌더링 프로세스의 학습 효율성을 유지한다.
Methods
1. Tile-based Training via RT-Loss
본 논문의 목표는 구조적 정보를 보존하면서 각 학습 batch 내에 무작위 시점 관측값을 통합하여 보다 포괄적인 제약 조건을 적용하는 것이다. 개별 픽셀 광선을 사용하여 ray marching을 수행하는 NeRF와 달리, Gaussian Splatting은 전체 화면에 Gaussian을 projection하는 타일 기반 splatting 프로세스를 사용한다. 따라서 loss 계산의 최소 단위는 splatting 렌더링과 일치해야 하며, 이는 16$\times$16 타일 $\textbf{t}$로 설정된다. 데이터셋을 이미지가 아닌 타일로 로드하고, $N$개의 타일을 무작위로 샘플링하여 학습 batch $\mathcal{T}$를 생성한 후, 렌더링된 타일 집합 $\mathcal{T} (\hat{\mathcal{C}})$와 대응되는 GT $\mathcal{T} (\mathcal{C})$를 얻는다. 여기서 \(\hat{\mathcal{C}} = \{\hat{\textbf{C}}(\textbf{t}) \vert \textbf{t} \in \mathcal{T}\}\)이고 \(\mathcal{C} = \{\textbf{C}(\textbf{t}) \vert \textbf{t} \in \mathcal{T}\}\)이다. Color loss로는 MAE를 사용한다.
\[\begin{equation} L_\textrm{RT-MAE} = \frac{1}{\| \mathcal{T} \|} \sum_{\textbf{t} \in \mathcal{T}} \| \hat{\textbf{C}}(\textbf{t}) - \textbf{C}(\textbf{t}) \|_1 \end{equation}\]S3IM에서 랜덤 광선에 대해 SSIM을 적용한 방식에서 영감을 받아, 저자들은 무작위 타일에 내재된 구조적 정보를 유지하기 위해 3DGS용 RT-SSIM을 제안하였다. 전체 batch size는 그대로 유지하면서, kernel 크기를 $K \times K$로 설정하고 (ex. 전체 구조의 경우 9$\times$9, 미세한 구조의 경우 3$\times$3), stride를 $s$로 설정하여 서로 다른 시점에서 촬영된 여러 개의 독립적이고 겹치지 않는 랜덤 타일에 대해 SSIM을 계산하고 평균을 낸다.
\[\begin{equation} \textrm{RT-SSIM} (\hat{\mathcal{T}}, \mathcal{T}) = \frac{1}{N} \sum_{\textbf{t} \in \mathcal{T}, v \in \textbf{V}} \textrm{SSIM} \left( \textbf{t}^{(v)} (\hat{\mathcal{C}}), \textbf{t}^{(v)} (\mathcal{C}) \right) \end{equation}\]($V$는 모든 $N$개 타일의 뷰 개수, $V = N$이면 모든 타일이 서로 다른 뷰에서 선택됨)
RT-SSIM은 이미지 유사도와 양의 상관관계를 가지므로, structure loss \(L_\textrm{RT-SSIM}\)은 다음과 같이 정의된다.
\[\begin{equation} L_\textrm{RT-SSIM} (\Theta, \mathcal{T}) = 1 - \textrm{RT-SSIM} (\hat{\mathcal{T}}, \mathcal{T}) \end{equation}\]타일은 병렬 처리에 특히 적합하므로 타일 기반 학습의 추가 계산 비용은 최소화된다. 최종 loss function $L_\textrm{RT}$는 다음과 같다.
\[\begin{equation} L_\textrm{RT} = (1 - \lambda_s) L_\textrm{RT-MAE} + \lambda_s L_\textrm{RT-SSIM} \end{equation}\]표준 3DGS 학습 패러다임에서는 동일한 뷰 파라미터를 사용하여 타일을 병렬로 렌더링한다. 이와 대조적으로, 본 논문에서는 멀티뷰 제약 조건을 통합하기 위해 여러 다른 뷰에서 타일을 샘플링한다. 본 논문의 랜덤 타일 학습 패러다임에서는 두 개의 추가 hyperparameter \(\lambda_s\)와 $\textbf{V}$를 도입한다. $V = N$일 때, 각 타일은 서로 다른 뷰에서 샘플링되며, 렌더링 프로세스 속도를 높이기 위해 전처리 과정에서 타일의 visibility가 병렬로 계산된다. 본 논문의 랜덤 타일 전략은 각 뷰에 걸쳐 타일을 균일하게 샘플링하여 각 시점에 대한 관측치의 균형을 맞춘다.

2. Tile-based Adaptive Density Control
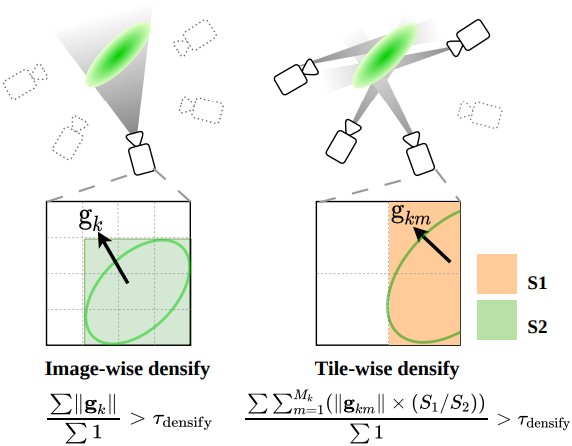
3DGS에서는 일정 수의 iteration에 걸쳐 NDC 좌표 \(\sum \vert \vert \textbf{g}_i \vert \vert\)에 대한 누적 2D gradient의 평균값이 지정된 threshold \(\tau_\textrm{densify}\)를 초과하는지 여부에 따라 Gaussian을 분할하거나 복제한다. 타일 기반 학습 과정에서, 한 iteration 내의 Gaussian은 서로 다른 학습 뷰에서 얻은 여러 개의 NDC gradient를 갖게 된다. 따라서 densify gradient를 계산하는 방법에는 Tile-Count Densification과 Iteration-Count Densification의 두 가지가 있다.
($\textrm{Iter}$는 각 densification 구간 내에서 알파 블렌딩에 참여하는 iteration 수)
Tile-Count Densification에서는 NDC gradient가 관찰된 타일 개수 $M_k$에 대해 평균화되는 반면, Iteration-Count Densification에서는 관찰된 iteration에 대해 평균화된다. 또한 Iteration-Count Densification에서 NDC gradient는 projection 면적 비율 $r_m$으로 가중된다.
Experiments
1. Results
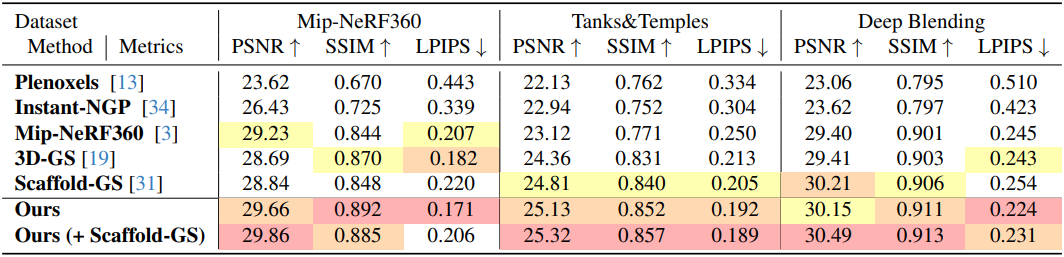
다음은 기존 방법들과의 비교 결과이다.
다음은 3DGS와의 비교 결과이다.

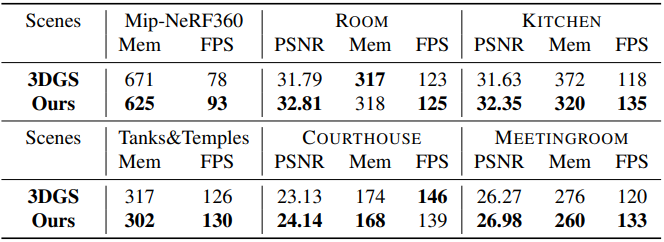
다음은 렌더링 FPS와 저장 용량을 비교한 결과이다.
다음은 3DGS와 수렴 성능을 비교한 결과이다.
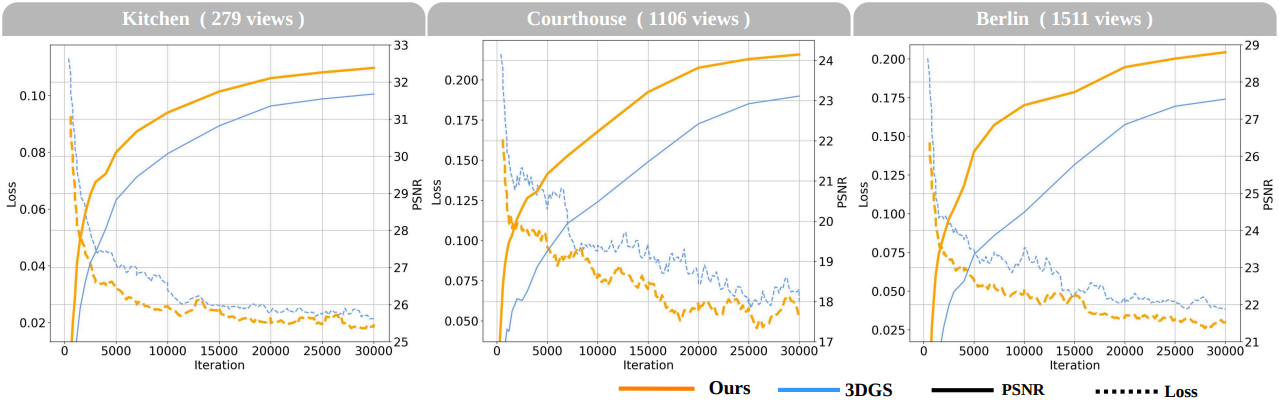
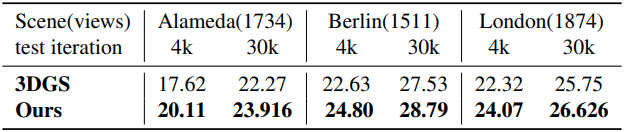
다음은 학습 뷰가 많은 장면에 대한 비교 결과이다.
다음은 Gaussian 구조를 비교한 예시이다.

다음은 동적 장면에 대한 비교 결과이다.


2. Ablation Studies
다음은 (왼쪽) RT-Loss와 (오른쪽) Adaptive Density Control에 대한 ablation study 결과이다.
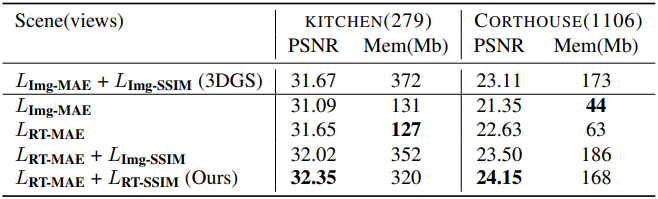
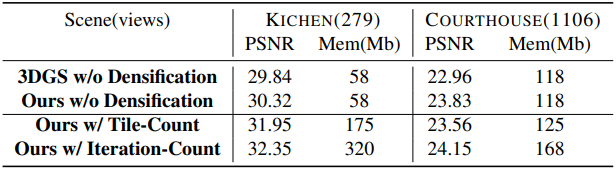
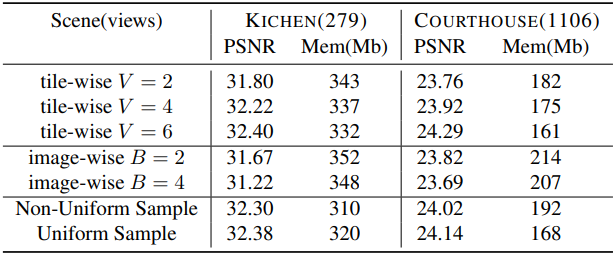
다음은 타일 샘플링과 batch 학습에 대한 효과를 비교한 결과이다.
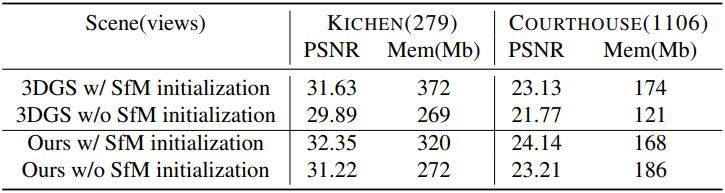
다음은 SfM 초기화에 따른 효과를 비교한 결과이다.