[논문리뷰] Random Conditioning with Distillation for Data-Efficient Diffusion Model Compression
CVPR 2025. [Paper] [Page] [Github]
Dohyun Kim, Sehwan Park, Geonhee Han, Seung Wook Kim, Paul Hongsuck Seo
Korea University | NVIDIA
2 Apr 2025

Introduction
Knowledge distillation은 teacher라고 불리는 복잡한 모델에서 student라고 불리는 보다 단순한 네트워크로 지식을 전달하는 기술이다. 인식 모델에 대한 distillation 기술은 개념 간의 관계를 포착하는 teacher model의 soft target 또는 중간 feature를 사용하여 처음 보는 개념도 student model로 전달하는 것으로 알려져 있다. 즉, 단일 도메인의 데이터를 사용하여 distillation을 수행하더라도 teacher의 여러 도메인에 걸친 지식이 student model로 전달될 수 있다. 처음 보는 개념에 대한 지식을 전달하는 이 기능은 제한된 데이터로도 효과적인 student model을 학습시킬 수 있게 한다.
그러나 인식 모델과 달리 이 현상은 조건부 diffusion model의 맥락에서는 관찰되지 않는다. 조건부 diffusion model의 생성 함수는 semantic 조건 공간을 훨씬 더 큰 이미지 공간에 매핑하여 student model이 처음 보는 개념으로 일반화하기 어렵게 만든다. 출력 noise도 현재 입력에 따라 달라지므로 서로 다른 출력 이미지에서 최소한의 관계를 포착한다. 또한 각 denoising step은 입력 조건뿐만 아니라 중간 noise 이미지에도 의존하므로 매핑 함수가 더욱 복잡해진다.
결과적으로 student model이 distillation을 통해 처음 보는 개념을 효과적으로 추론하는 것이 어려워지고 teacher model의 생성 용량을 완전히 distillation하기 위해 많은 조건-이미지 쌍으로 전체 조건 공간을 탐색해야 한다. 그러나 이러한 대규모 텍스트-이미지 쌍을 얻는 것은 복잡하고 어려우며, teacher model을 사용하여 텍스트만 있는 데이터셋에서 이미지를 생성하는 경우에도 가능한 모든 텍스트 프롬프트에 대해 이미지를 합성하는 것은 계산 리소스와 시간 측면에서 엄청나게 비용이 많이 들 수 있다.
이러한 문제를 해결하기 위해, 본 논문은 random conditioning이라는 새로운 테크닉을 제안하였다. 여기서 noise가 추가된 이미지는 학습 중에 랜덤하게 선택된, 잠재적으로 관련이 없는 텍스트 조건과 쌍을 이룬다. 이 방법을 사용하면 모델은 데이터셋의 모든 텍스트 프롬프트에 대해 이미지를 생성할 필요 없이 일반화 가능한 패턴을 학습할 수 있어 효율적인으로 이미지 없이 distillation이 가능하다. Random conditioning은 전체 이미지-텍스트 매핑과 관련된 계산 및 저장 요구 사항을 줄임으로써 리소스 요구 사항을 크게 낮추는 동시에 강력한 성능을 유지한다. 결과적으로, student는 distillation 프로세스 중에 처음 보는 개념의 이미지가 전혀 제공되지 않더라도 이러한 이미지를 생성하는 법을 배운다.
Method
1. Distilling Diffusion Models for Compression
본 논문의 목표는 조건부 diffusion model을 압축하는 것이고, 저자들은 가장 널리 사용되는 조건부 diffusion model 중 하나인 text-to-image 생성을 위한 Stable Diffusion을 사용하였다. 즉, 학습된 teacher diffusion model $\mathcal{T}$ 내의 지식을 파라미터 수가 상당히 적고 다른 아키텍처일 수 있는 임의의 student model $\mathcal{S}$로 distillation한다.
본 논문은 이미지가 없는 설정에서 이 문제에 접근하였으며, 텍스트 프롬프트만 사용할 수 있다. 이 구성이 유용한 이유는 대규모 이미지-텍스트 쌍을 수집하는 것이 비용이 많이 들고 노동 집약적이며 라이선스 제한으로 인해 복잡하고 어렵기 때문이다. 특정 도메인에서는 이러한 문제가 더욱 두드러지는데, 데이터가 부족하거나 개인정보 보호에 대한 우려가 커져서 주석이 잘 달린 이미지-텍스트 쌍을 얻는 것이 특히 어렵다.
이미지 없이 diffusion model에 knowledge distillation을 적용하면 denoising process의 반복적 특성으로 인해 추가적인 문제가 발생한다. 텍스트 조건 $c$가 주어지면 teacher model은 각 timestep $t ∈ [0, T]$에서 \(\textbf{x}_t\)에서 제거될 noise \(\epsilon_\mathcal{T} (\textbf{x}_t, t, c)\)를 예측한다. 따라서 teacher model에서 student model로의 지식 전달은 각 timestep $t$에서 발생해야 한다. 그러나 이미지가 없으면 \(\textbf{x}_t\)를 생성할 수 없다. 이러한 제한으로 인해 중간 timestep에서 필요한 입력 이미지가 없기 때문에 $t \ne T$에 대해 knowledge distillation을 수행할 수 없다.
2. Naive Baseline Approach
이미지 없이 distillation하기 위한 단순한 접근 방식은 사용 가능한 모든 텍스트 프롬프트에 대한 이미지를 생성하여 쌍 데이터셋 \(\mathcal{D} = \{(\textbf{x}^n, c^n)\}_{n=1}^N\)을 구성하는 것이다. 여기서 $\textbf{x}^n$은 텍스트 조건 $c^n$에 대한 원본 이미지 \(\textbf{x}_0\) 역할을 하는 생성된 이미지로, 이를 통해 모든 timestep $t$와 조건 $c^n$에 대해 noise가 있는 입력 이미지 \(\textbf{x}_t\)를 구성할 수 있다. Diffusion model은 이미지 생성에 시간이 많이 걸리므로 데이터셋을 구축하기 위해 이러한 이미지를 미리 생성하고 캐싱해야 한다.
Teacher model을 다음 loss를 사용하여 student model로 distillation할 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{out} = \mathbb{E}_{(\textbf{x}_t, c) \in \mathcal{D}, t} \left[\| \epsilon_\mathcal{T} (\textbf{x}_t, c, t) - \epsilon_\mathcal{S} (\textbf{x}_t, c, t) \|_2^2 \right] \end{equation}\](\(\epsilon_\mathcal{T}\)와 \(\epsilon_\mathcal{S}\)는 각각 teacher와 student model이 예측한 noise이고 $t$는 0과 $T$ 사이에 균일하게 분포)
또한, 다음과 같은 feature-level knowledge distillation loss를 통합할 수 있다.
\[\begin{equation} \mathcal{L}_\textrm{feat} = \mathbb{E}_{(\textbf{x}_t, c) \in \mathcal{D}, t} \left[ \sum_l \| \textbf{f}_\mathcal{T}^l (\textbf{x}_t, c, t) - \textbf{f}_\mathcal{S}^l (\textbf{x}_t, c, t) \|_2^2 \right] \end{equation}\](\(\textbf{f}_\mathcal{T}^l\)와 \(\textbf{f}_\mathcal{S}^l\)는 각각 teacher model과 student model의 레이어 $l$에서 온 feature map)
$\mathcal{T}$와 $\mathcal{S}$는 동일한 아키텍처를 가질 필요가 없다. $\mathcal{S}$의 임의의 중간 feature를 \(\textbf{f}_\mathcal{T}^l\)와 동일한 차원의 \(\textbf{f}_\mathcal{S}^l\)로 projection하기 위해 distillation을 위한 추가 임시 모듈을 통합할 수 있다. 이러한 추가 projection 모듈은 distillation 프로세스 후에 삭제된다. 이 feature-level loss는 noise 예측 loss와 결합되어 student model이 teacher model의 외부 출력과 내부 처리를 모두 복제하도록 장려한다. 이를 통해 student는 distillation 프로세스 중에 발생한 텍스트 조건 $c$에 대한 teacher model의 denoising 동작을 학습하고 복제할 수 있다.
이러한 단순한 접근 방식은 teacher에서 student로의 효과적인 지식 전달을 가능하게 하지만, 몇 가지 한계가 있다. 이 방법은 텍스트 조건 공간을 충분히 포괄하기 위해 다양한 텍스트 프롬프트 세트에 대한 이미지 \(\textbf{x}_0\)를 생성해야 한다. 전체 조건 공간을 포괄하지 않으면 student model은 distillation 중에 관찰되지 않은 조건에 대한 이미지를 생성하지 못할 수 있다.

위 그림의 MNIST에 대한 예비 실험은 조건 공간을 포괄하는 것의 중요성을 보여준다. Teacher model은 숫자 3을 생성할 수 있지만, student model은 distillation 중에 3에 노출되지 않으면 3을 생성하지 못한다. 텍스트 조건 공간은 MNIST의 조건 공간 보다 매우 크기 때문에 가능한 모든 프롬프트에 대해 \(\textbf{x}_0\)를 합성하면 계산, 시간, 저장 측면에서 엄청나게 비용이 많이 든다.
3. Random Conditioning
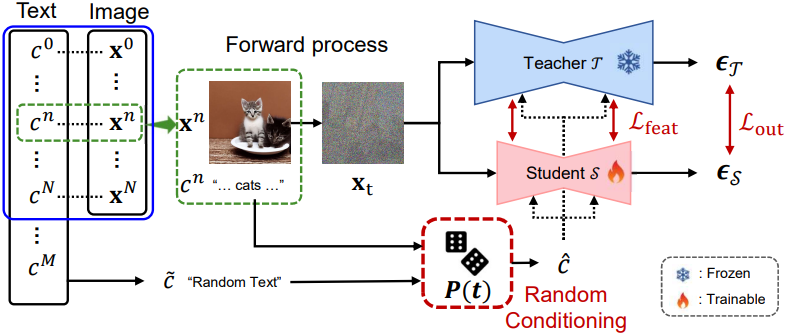
본 논문은 위의 한계점을 해결하기 위해 random conditioning을 제안하였다. 이는 텍스트 프롬프트의 부분집합(파란 박스)에서만 생성된 이미지를 캐싱할 수 있게 해준다. 구체적으로, 광범위한 $M$개의 텍스트 프롬프트 집합 $\mathcal{C}$가 주어지면, $M$보다 훨씬 작은 $N$개의 이미지-텍스트 쌍 \(\mathcal{D} = \{(\textbf{x}^n, c^n)\}\)의 데이터셋을 구성한다. 앞서 논의했듯이, $\mathcal{D}$에서 student model을 학습시키면 $\mathcal{C}$의 텍스트 조건 공간을 모두 커버하지 못하기 때문에 distillation에서 지식 전달이 제한된다. 이러한 제한은 일반적으로 이미지 \(\textbf{x}_0\)에서 구성되는 noise가 추가된 이미지 \(\textbf{x}_t\)가 없기 때문에 발생한다.
본 논문의 접근 방식에서는 $\mathcal{D}$ 뿐만 아니라 $\mathcal{C}$도 활용하여 student model이 $\mathcal{D}$의 모든 텍스트 조건을 탐색할 수 있도록 한다. 이 접근 방식은 distillation된 지식을 향상시켜 모델이 전체 조건 공간에서 일반화할 수 있게 한다.
먼저 $\mathcal{D}$에서 \((\textbf{x}^n, c^n)\)을 샘플링하고 $\textbf{x}^n$에서 \(\textbf{x}_t\)를 구성한다. 그런 다음 distillation을 수행하기 전에 미리 정의된 random conditioning 확률 $p(t)$를 적용하여 $\mathcal{C}$에서 랜덤한 텍스트를 샘플링한다. 구체적으로, 텍스트 조건 $\hat{c}$는 다음에 의해 결정된다.
\[\begin{equation} \hat{c} = \begin{cases} c^n & \textrm{with probability} \; 1 - p(t) \\ \tilde{c} \in \mathcal{C} \textrm{with probability} \; p(t) \end{cases} \end{equation}\]$\hat{c}$는 \(\textbf{x}_t\)와 쌍을 이루어 두 distillation loss가 계산된다.
관찰과 동기
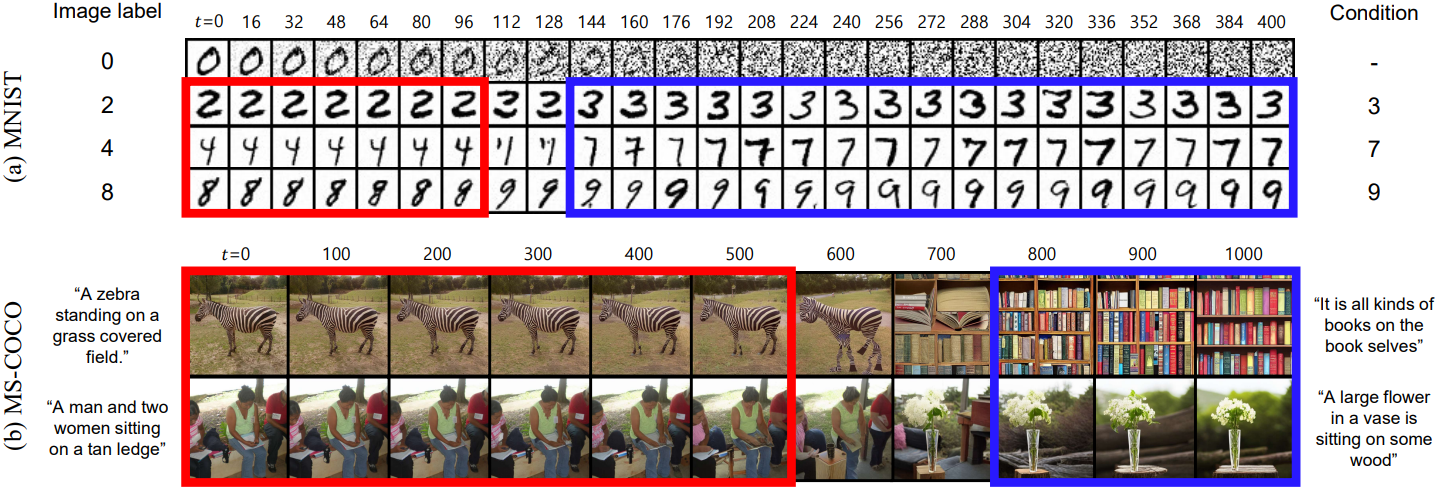
제안된 random conditioning 테크닉은 직관적이지 않게 보일 수 있지만, diffusion model이 timestep $t$에 따라 달라지는 방식으로 컨디셔닝 정보를 통합한다는 경험적 관찰에 근거한다. 위 그림은 MNIST와 MS-COCO 데이터셋에서 다양한 timestep $t$의 \(\textbf{x}_t\)에서 시작하여 denoising process 동안 생성된 출력을 보여준다. 각 \(\textbf{x}_t\)는 가장 왼쪽 열에 해당하는 초기 이미지 \(\textbf{x}_0\)에서 파생되고 생성된 출력은 가장 오른쪽 열에 표시된 조건을 동일하게 공유한다. 특히 이 조건은 원본 \(\textbf{x}_0\)와 관련 없는 텍스트 조건이다.
생성된 이미지는 주로 원본 이미지나 텍스트 조건과 일치하며 좁은 범위의 $t$만이 눈에 띄는 아티팩트가 있는 출력을 생성한다. 특히 $t$가 작을 때 생성된 이미지는 denoising process의 나중 step의 noise의 크기가 낮기 때문에 원본 이미지를 반영하는 경향이 있다 (빨간 박스). 반대로 $t$가 클 때 생성된 이미지는 입력 \(\textbf{x}_t\)가 순수한 noise와 거의 구별할 수 없게 되면서 주로 텍스트 조건을 따른다 (파란 박스).
이러한 결과는 조건 $c$가 제안된 random conditioning 테크닉을 지원하는 \(\textbf{x}_t\)와 강하게 상관될 필요가 없음을 나타낸다. 이는 $t$가 클 때 모델이 조건 $c$에 거의 전적으로 의존하며, $t$가 작을 때 모델이 조건 $c$를 무시하면서 주로 \(\textbf{x}_t\)의 noise를 제거하는 데 초점을 맞추기 때문이다.
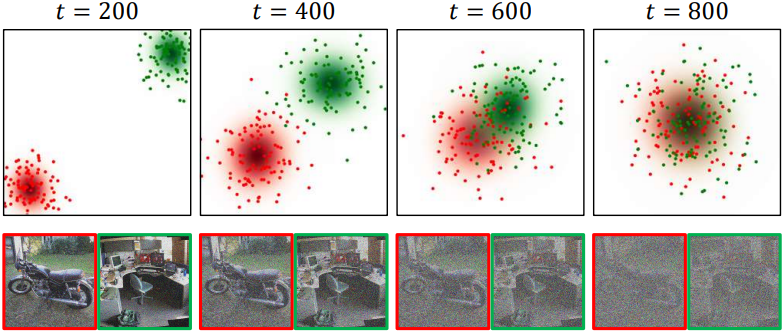
또한 위 그림은 forward process 동안 timestep $t$가 증가함에 따라 \(p(\textbf{x}_t \vert c^n)\)과 \(p(\textbf{x}_t \vert \hat{c})\)가 서로 가까워지고, 결국 $t$가 $T$에 접근함에 따라 동일한 Gaussian 분포로 병합됨을 보여준다. 이 관찰은 입력 이미지와 조건이 모든 timestep에서 직접 정렬될 필요가 없음을 의미한다. 이는 random conditioning의 효과성과 타당성을 모두 뒷받침하며, 다양한 입력과 조건을 연관시키는 데 있어서 그 유연성을 강조한다.
저자들은 이러한 관찰과 동기를 바탕으로, 경험적으로 $p(t)$를 탐구했다. $p(t)$를 $p(t) = 1$과 같은 상수 값으로 설정했을 때, 결과는 최적이 아니었다. 특히, 이미지와 조건 간의 페어링이 비교적 더 중요해지는 중간 timestep에 대해 $p(t)$를 줄이면 성능이 향상되었다. 저자들은 $p(t)$에 대해 지수 함수를 사용했다.
조건 공간의 확장된 탐색
Student model은 distillation 중에 $\mathcal{D}$에서 명시적으로 다루는 조건에 대한 이미지를 생성하는 법을 효과적으로 학습하지만, $\mathcal{C}$의 모든 텍스트 프롬프트에 대한 이미지를 생성하지 못한다. Random conditioning은 $\mathcal{D}$에 포함되지 않은 조건을 사용할 수 있도록 허용하여 이를 완화한다. 결과적으로, student는 이미지와 쌍을 이룬 텍스트 외의 다른 텍스트 프롬프트를 탐색할 수 있게 되며, 새로운 조건에서 teacher의 행동을 복제하는 데 도움이 되므로 생성 능력이 확장된다.
Experiments
- 데이터셋
- $\mathcal{D}$: LAION-Aesthetics V2 (L-Aes) 6.5+의 21.2만 개의 텍스트에 대해 이미지 생성
- $\mathcal{C}$: LAION의 4억 개의 이미지-텍스트 쌍에서 2천만 개의 추가 텍스트를 샘플링
- teacher model: Stable Diffusion (SD) v1.4
- student model 아키텍처: BK-SDM
- 구현 디테일
- null 조건 비율을 제외하고 BK-SDM과 동일한 hyperparameter
- batch size: 256
- optimizer: AdamW
- learning rate: $5 \times 10^{-5}$
Results
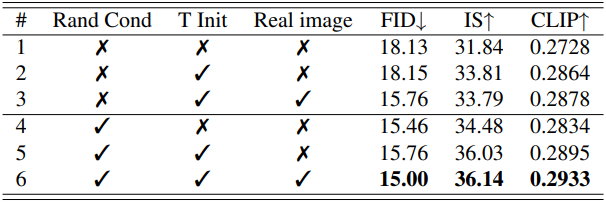
다음은 random conditioning 유무에 따른 효과를 비교한 표이다. “T init”은 student를 teacher로부터 초기화한 것이고, “Real image”는 실제 이미지를 학습 사용하는 지를 나타낸 것이다. 3행은 BK-SDM과 동일하다.
다음은 처음 보는 개념에 대한 실험 결과이다. 저자들은 $\mathcal{D}$를 구성할 때 동물과 관련 없는 텍스트 18.8만 개만 사용하였으며, 나머지 2.4만 개의 동물과 관련된 텍스트는 $\mathcal{C}$에 추가하였다.

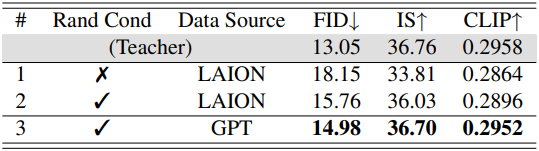
다음은 GPT로 자동 생성한 텍스트를 $\mathcal{C}$로 사용하는 구성에 대한 비교 결과이다.
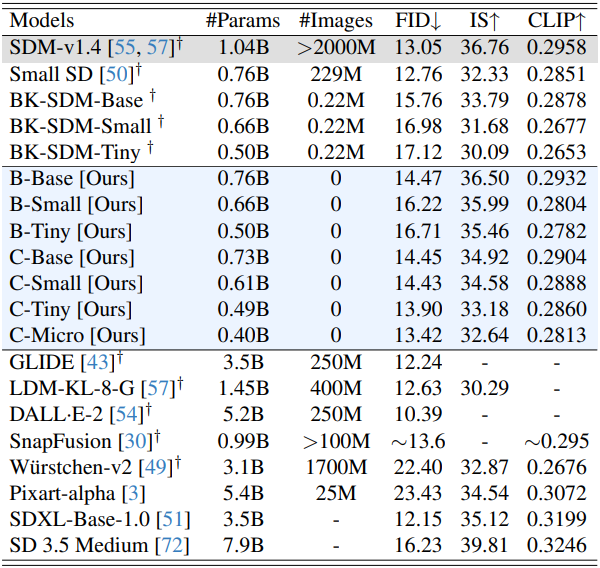
다음은 MS-COCO 30K에서 다른 모델들과 비교한 결과이다.
다음은 BK-SDM과 이미지 생성 결과를 비교한 것이다.

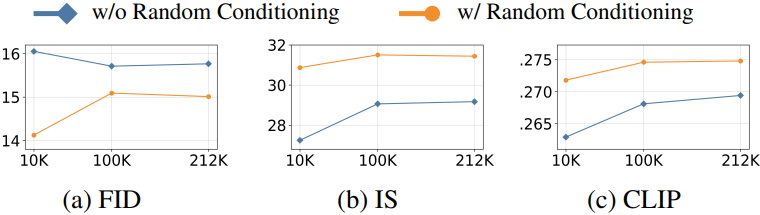
다음은 $\mathcal{D}$의 크기에 따른 이미지 품질을 비교한 그래프이다.