[논문리뷰] RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment
arXiv 2023. [Paper]
Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, Tong Zhang
The Hong Kong University of Science and Technology
13 Apr 2023
Introduction
Generative foundation model은 이전에는 달성할 수 없었던 다양한 task를 수행할 수 있는 놀라운 능력을 보여주었으며 자연어 및 컴퓨터 비전 task에서 광범위한 능력을 보여주었다. 자연어 및 컴퓨터 비전에서 가장 인기 있는 모델인 대규모 언어 모델(LLM)과 diffusion model은 고품질의 의미 있는 출력을 생성할 수 있다. AI 생성 콘텐츠는 빠르게 진화하는 분야이며 궁극적으로 인류의 생산성을 향상시킨다. 그러나 오용 가능성 및 모델의 암시적 편향과 같은 윤리적 영향에 대한 우려도 있다. 연구자와 개발자가 이러한 모델의 한계를 계속 탐색하고 출력 생성을 제한하는 것이 중요하다.
현재 생성 모델의 가장 직접적인 제한 중 하나는 대규모 unsupervised 데이터셋에 대한 높은 의존도이다. 이러한 데이터셋에는 종종 모델의 출력에 나타날 수 있는 내재된 편향이 포함되어 부정확하거나 불공정한 결과를 초래할 수 있다. 이 문제를 해결하기 위해 사전 학습된 모델은 일반적으로 맞춤형 데이터를 사용하여 하위 task에서 fine-tuning되어 특수한 설정에서 성능을 개선하거나 원래 모델에서 잠재적 편향 및 독성을 제거한다.
한 가지 접근 방식은 supervised fine-tuning(SFT)으로 알려진 레이블이 지정된 데이터를 사용하여 supervised 방식으로 사전 학습된 모델을 fine-tuning하는 것이다. Instruction tuning은 LLM이 하위 task에 적응하도록 만드는 데 가장 널리 사용되는 접근 방식이다. 그러나 새로운 supervised 샘플을 수집하는 것은 특히 고품질 데이터를 생성하기 위해 전문가 참여가 필요한 경우 비용이 많이 들 수 있다.
보다 최근에는 Reinforcement Learning from Human Feedback (RLHF)가 사전 학습된 생성 모델을 fine-tuning하기 위한 유망한 방법으로 부상했다. LLM에 대한 최근 연구에서 RLHF는 정책 기반 심층 강화 학습(DRL) 알고리즘, 일반적으로 Proximal Policy Optimization (PPO)를 사용하여 사전 학습된 모델을 fine-tuning하는 데 널리 사용되었다. RLHF의 아이디어는 특정 인간 선호도를 반영하는 reward function을 최적화하여 언어 모델을 인간 선호도 및 사회적 가치에 맞추는 것이다.
여러 연구가 비전 생성 모델에서 RLHF를 실행하려고 시도했다. 이러한 alignment process는 diffusion model의 신속한 학습 또는 fine-tuning을 통해 달성할 수 있다. LLM과 달리 이미지 생성 프로세스는 일반적으로 순차적이지 않다 (diffusion model의 궤적 길이는 단 하나이다). 결과적으로 PPO는 비전 task에 잘 적응하지 못하며 비전 생성 모델을 위해 수많은 적응이 필요하다.
PPO는 그 효과를 보여주는 수많은 연구를 통해 잘 확립된 DRL 방법이지만 환경과 상호 작용하여 시행착오 방식으로 학습하며 일반적으로 supervised learning에 비해 훨씬 덜 안정적이고 덜 효율적이다. 반면에 미리 결정된 supervised 데이터셋이 아닌 reward function을 사용하여 생성 모델을 fine-tuning하는 경우 고품질 샘플 수집이 더 실현 가능할 수 있다. 특히 이 모델은 학습에 사용할 수 있는 많은 수의 샘플을 생성할 수 있다. 한편, reward function은 생성된 풀에서 고품질 샘플을 선택하는 데 유용한 기준을 제공한다.
Alignment process는 일반적으로 “alignment tax”라고 하는 생성 성능에 해로운 영향을 미친다. 특히, reward model이 특정 측면만 평가할 때 생성된 출력의 품질을 무시할 수 있다. 일반적이지 않은 reward function의 최적화는 생성된 결과의 품질 저하로 이어질 수 있다. 본 논문이 제안한 RAFT 프레임워크는 일반적으로 likelihood 측정을 사용하여 평가되는 reward와 품질 간의 균형을 고려한다.
Algorithm
1. Problem Setup
모델 파라미터 $w$로 이루어진 튜닝 가능한 생성 모델 $g(w, x)$를 고려하자. 이 생성 모델은 입력 $x$를 사용하여 생성 모델을 학습시킬 수 있다. 또한 분포 $p_G^\alpha (y \vert x)$에 따라 랜덤 출력 $y$를 생성할 수 있는 generator $G(x)$에 액세스할 수 있다고 가정하자. 여기서 $\alpha$는 generator의 다양성을 제어하는 temperature parameter이다. 이 generator $G$는 expert generator(ex. 인간 또는 GPT-4)일 수 있다. 또한 입력-출력 쌍 $(x, y)$에 대한 reward를 반환하는 reward function $r(x, y)$가 있다고 가정한다. Reward function을 사용하여 $g(w, x)$의 출력을 guide한다.
$p_g (y \vert w, x)$를 $g(w, x)$의 분포라고 하자. 학습 입력 셋 $\mathcal{X}$에 대하여 reward 최적화의 목적 함수는 다음과 같다.
\[\begin{equation} \max_w \sum_{x \in \mathcal{X}} \mathbb{E}_{y \sim p_g(\cdot \vert w, x)} r(x, y) \end{equation}\]그러나 일반적으로 reward 학습과 응답 품질의 trade-off가 있다. 이러한 품질 metric을 생성기 $g(w, \cdot)$의 품질을 측정하는 품질 함수 $Q(w)$에 통합할 수 있다. 전체 목적 함수는 다음과 같다.
\[\begin{equation} \max_w \bigg[ \sum_{x \in \mathcal{X}} \mathbb{E}_{y \sim p_g(\cdot \vert w, x)} r(x, y) + \lambda Q(w) \bigg] \end{equation}\]특히 유창성 품질을 고려할 수 있는데, 일반적으로 레이블이 지정된 데이터셋 $(x’, y’) \in S$에 대한 (negative) perplexity로 측정할 수 있다.
\[\begin{equation} Q(w) = \sum_{(x', y') \in S} \ln p(y' \vert w, x') \end{equation}\]여기서 $p(y \vert w, x)$는 $g(w, x)$의 분포다. 고품질 generator $G$가 주어지면 $y’ \sim p_G^\alpha (y’ \vert x’)$라고 가정하고 perplexity 측정을 다음과 같이 근사화할 수 있다.
\[\begin{equation} Q(w) = \sum_{x' \in S} \mathbb{E}_{y' \sim p_G^\alpha (\cdot \vert x')} \ln \frac{p_G^\alpha (y' \vert x')}{p(y' \vert w, x)} \end{equation}\]전체 목적 함수를 사용하여 reward $r$과 품질 $Q$ 사이의 최적의 trade-off를 달성할 수 있지만, 이를 위해서는 최적화 파라미터 $\lambda$를 신중하게 튜닝하고, perplexity 품질 측정에 대한 데이터셋 $S$를 알아야 한다. $\lambda$의 튜닝은 추가 복잡성을 도입하므로 $\epsilon$-small learning rate gradient boosting에 의한 간단한 계산 프로세스를 사용하지 않아도 된다. Learning rate가 작을수록 더 나은 성능의 gradient boosting 달성하고, 이 절차는 다른 정규화 강도 $\lambda$를 갖는 $L_1$ 정규화 경로와 유사한 정규화 경로를 제공한다.
유사하게, 제안된 RAFT의 해를 추적하기 위해 작은 learning rate와 early stopping을 사용하는 것을 고려할 수 있으며, 그런 다음 경로를 따라 reward-품질 trade-off를 측정할 수 있다. Learning rate가 작은 RAFT가 learning rate와 PPO가 큰 것보다 reward와 perplexity의 더 나은 trade-off를 제공한다. 이에 비해 작은 learning rate가 합리적인 계산 예산 하에서 PPO에 도움이 되지 않는다.
본 논문의 현재 구현에서 제시된 RAFT의 추가적인 장점은 $S$에 대한 지식이 필요하지 않다는 것이다. 일부 데이터 $(x’, y’) \in S$와 서로 다른 튜닝 파라미터 $\lambda$ 집합과 함께 직접 통합한다.
2. Algorithm
DRL 방법과 비교할 때 SFT는 샘플 효율성과 안정성면에서 유리하다. 그러나 SFT의 효율성은 데이터셋의 품질에 크게 좌우되며, 이는 높은 비용으로 전문가의 참여를 요구할 수 있다. 그러나 task에 사용할 수 있는 reward function을 사용하면 reward별로 샘플 순위를 매기고 fine-tuning을 위해 reward가 높은 샘플만 선택할 수 있다. Reward function이 있으면 저렴한 비용으로 유리한 샘플을 생성할 수 있으며 이러한 선택된 샘플에 대한 supervised fine-tuning정을 통해 생성 모델을 지속적으로 개선할 수 있다. 이를 고려하여 본 논문은 fine-tuning이 가능한 모든 생성 모델에 적용할 수 있는 Reward rAnked Fine-Tuning (RAFT)라는 일반적인 alignment 알고리즘을 제시한다. 데이터 샘플의 소스는 사람이 생성한 샘플, teacher model이 생성한 샘플 또는 현재 모델이 생성한 샘플을 포함하여 유연하게 선택할 수 있다.

RAFT의 목적은 fine-tuning된 모델 $g(w’, x)$가 reward function으로 측정되는 인간의 기대에 잘 적응되도록 튜닝 가능한 생성 모델을 파라미터 $w$와 align하는 것이다. \(\{x_1, \cdots, x_n\}\)은 $n$개의 학습 프롬프트의 집합이고, RAFT는 Algorithm 1에서와 같이 $w$를 반복적으로 업데이트한다. 각 stage $t$에서 RAFT는 프롬프트 배치를 샘플링하고 현재 generator 또는 입력 expert generator를 사용하여 응답을 생성한다. 이러한 샘플의 관련 reward는 reward function을 사용하여 계산된다 (line 3~11). 이후 RAFT는 수집된 샘플의 순위를 매기고 reward가 가장 높은 샘플의 $1/k$를 학습 샘플 $\mathcal{B}$로 선택한다 (line 12). 그런 다음 현재 생성 모델이 이 데이터셋에서 fine-tuning되고 (line 13) 다음 stage가 시작된다.
RAFT는 생성된 샘플의 대부분을 삭제하기 때문에 데이터 수집(forward 연산)에서 샘플 효율성이 떨어지지만, 생성된 데이터셋의 하위 집합에 대해서만 학습하기 때문에 역전파에 이롭다. 역전파는 일반적으로 forward 연산에 비해 계산적으로 더 광범위하기 때문에 RAFT에 계산상의 이점을 제공할 수 있다.

RAFT 알고리즘의 hyperparameter는 표 1에 요약되어 있다. 기존의 DRL 알고리즘에서 발견되는 복잡한 파라미터 구성과 달리 RAFT에는 4개의 기본 hyperparameter만 포함된다.
- Batch 크기
- Reward 선호도를 결정하는 수락 비율 (acceptance ratio): 비율이 작을수록 reward가 높은 샘플만 수락하게 됨
- 임의성 레벨을 조절하는 temperature: 더 큰 temperature를 사용하면 더 다양한 샘플로 이어지
- Reward의 overfitting을 방지하기 위해 도입된 regularizer $\lambda$.
Experiments
1. Language Models
다음은 IMDB 데이터셋에 대한 영화 리뷰 완성 실험의 결과이다.
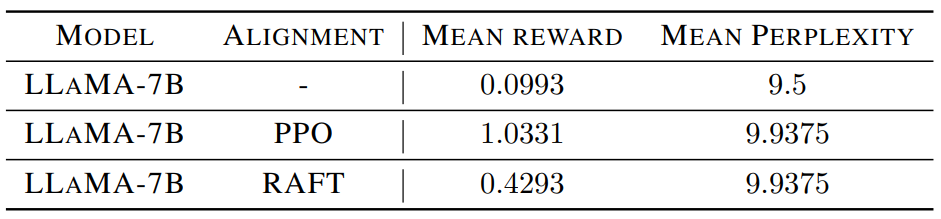
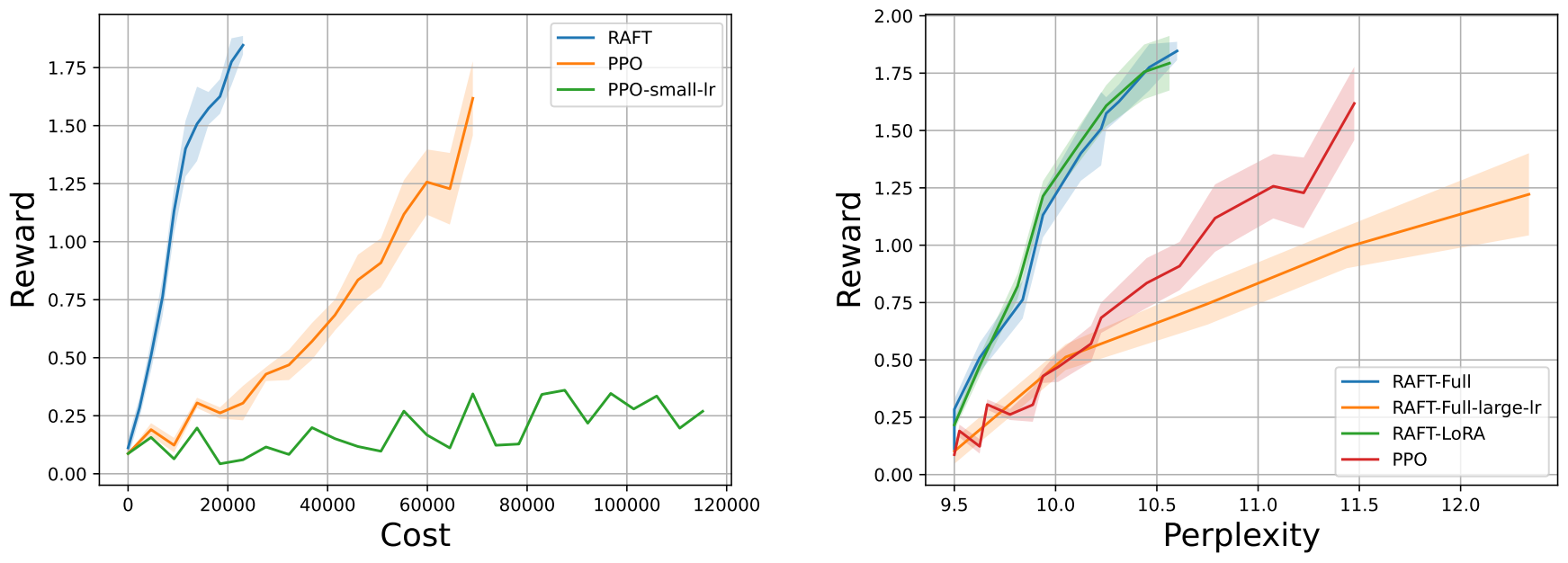
Cost는 학습 시간을 공정하게 비교하기 위해 도입한 값으로
로 정의된다.
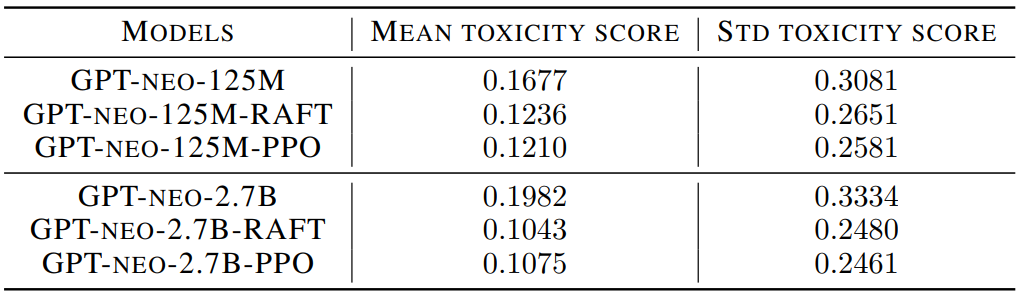
다음은 RealToxicityPrompts 데이터셋에 대한 model detoxification의 결과이다.
2. Diffusion Models
Stable Diffusion v1.5 (SD-1.5)은 초기에 256$\times$256에서 학습되기 때문에 256$\times$256에서 이미지를 생성하는 데 어려움을 겪는다. 다음은 256$\times$256에 대한 SD-1.5의 샘플들과 RAFT로 align된 SD-1.5의 샘플들을 비교한 것이다.

512$\times$512에서 SD-1.5은 좋은 결과를 생성하지만 데이터셋에 드물게 존재하는 특정 프롬프트에서 어려움을 겪는다. 다음은 이러한 프롬프트에 대한 SD-1.5의 샘플들과 RAFT로 align된 SD-1.5의 샘플들을 비교한 것이다. (프롬프트: “monet style cat”)

Limitations
- 완벽하지 않은 환경 모델링: 생성 모델을 위한 reward 모델링은 일반적으로 완벽하지 않다. 따라서 reward function의 overfitting은 일반적으로 원하지 않는 결과를 초래한다.
- Sparse Sampling 문제: RAFT가 초기 stage에서 reward function에 의해 샘플을 모으는 데에 generator의 다양성이 중요하다. 다양성이 부족하면 초기 stage를 제거하기 위해 원하는 샘플을 모을 수 없기 때문에 RAFT가 멈출 수 있다.