[논문리뷰] Pyramid Adversarial Training Improves ViT Performance (PyramidAT)
CVPR 2022. [Paper] [Page] [Github]
Charles Herrmann, Kyle Sargent, Lu Jiang, Ramin Zabih, Huiwen Chang, Ce Liu, Dilip Krishnan, Deqing Sun
Google Research
30 Nov 2021
Introduction
인간 지능의 흥미로운 측면 중 하나는 제한된 경험을 새로운 환경으로 일반화하는 능력이다. 딥러닝은 분류 작업에서 인간을 모방하거나 능가하는 데 놀라운 발전을 이루었지만 분산 데이터를 일반화하는 데 어려움이 있다. CNN은 어려운 상황, 비정상적인 색상 및 질감, 일반적이거나 적대적인 손상이 있는 이미지를 분류하지 못할 수 있다. 실제 세계의 다양한 작업에 신경망을 안정적으로 배포하려면 분포 외 (out-of-distribution) 데이터에 대한 견고성 (robustness)을 개선해야 한다.
연구의 주요 라인 중 하나는 네트워크 설계에 중점을 둔다. 최근 ViT와 그 변형은 다양한 컴퓨터 비전 task에서 SOTA를 발전시켰다. 특히 ViT 모델은 유사한 CNN 아키텍처보다 더 강력하다. 약한 inductive bias와 강력한 모델 용량을 갖춘 ViT는 더 나은 일반화를 달성하기 위해 강력한 data augmentation과 정규화에 크게 의존한다. 본 논문은 ViT 모델의 성능을 개선하기 위해 강력한 정규화 장치로 adversarial training을 사용하는 방법을 살펴보았다.
이전 연구들은 분포 내 (in-distribution) 일반화와 적대적 예시에 대한 견고성 사이에 성능 상충 관계가 있음을 보였으며, 분포 내 일반화와 분포 외 일반화 사이에 유사한 trade-off가 관찰되었다. 이러한 trade-off는 주로 CNN에서 관찰되었다. 그러나 최근의 연구는 trade-off가 깨질 수 있음을 보여주었다. AdvProp은 EfficientNet용 split batch norm을 사용하여 adversarial training을 통해 이를 달성하였다. 본 논문에서는 새로 도입된 ViT 아키텍처에 대한 trade-off가 깨질 수 있음을 보여준다.
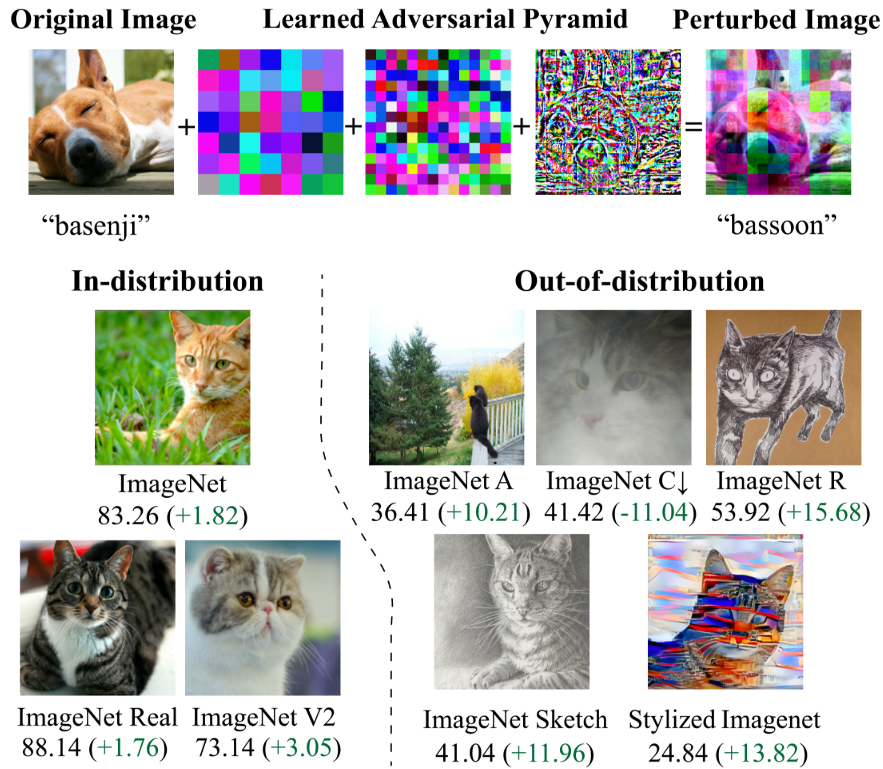
본 논문은 여러 공간 스케일에서 변경된 입력 이미지로 모델을 교육하는 pyramid adversarial training (PyramidAT)을 소개한다. Pyramid attack은 구조화되고 제어된 방식으로 이미지를 크게 편집하고 유연한 방식으로 이미지를 약간 편집하도록 설계되었다. 이러한 구조화된 멀티스케일 적대적 섭동을 사용하면 baseline과 픽셀별 적대적 섭동과 비교하여 상당한 성능 향상을 가져온다. 흥미롭게도 분포 내 정확도 (clean accuracy)와 분포 외 정확도 (robust accuracy) 모두에서 이러한 이득을 볼 수 있다. 추가 정규화 기술인 matched dropout과 stochastic depth를 사용하여 pyramid attack을 더욱 강화한다. Matched dropout은 mini-batch의 일반 샘플과 적대적 샘플 모두에 대해 동일한 dropout 구성을 사용한다. Stochastic depth는 네트워크에서 레이어를 무작위로 제거하고 matched dropout 및 멀티스케일 섭동과 일치하고 쌍을 이룰 때 추가 부스트를 제공한다.
Approach
저자들은 $x$와 해당 레이블 $y$로 표시되는 깨끗한 이미지로 구성된 학습 데이터셋 $\mathcal{D}$가 제공되는 supervised learning 설정에서 연구하였다. 고려되는 loss function은 cross-entropy loss $L(\theta, x, y)$이며, 여기서 $\theta$는 가중치 정규화 $f$를 사용하는 ViT 모델의 파라미터이다. Baseline model은 다음 loss를 최소화한다.
\[\begin{equation} \mathbb{E}_{(x, y) \sim \mathcal{D}} [L (\theta, \tilde{x}, y) + f (\theta)] \end{equation}\]여기서 $\tilde{x}$는 깨끗한 샘플 $x$에 data augmentation을 적용한 버전이고, RandAug와 같은 표준 data augmentation을 채택한다.
1. Adversarial Training
Adversarial training의 전반적인 목적 함수는 다음과 같다.
\[\begin{equation} \mathbb{E}_{(x, y) \sim \mathcal{D}} [\max_{\delta \in \mathcal{P}} L (\theta, \tilde{x} + \delta, y) + f (\theta)] \end{equation}\]여기서 $\delta$는 픽셀당, 색상 채널당 추가 섭동이고 $\mathcal{P}$는 섭동 분포이다. 적대적 이미지 $x^a$는 $\tilde{x} + \delta$로 주어진다. 섭동 $\delta$는 위 식의 최대화 내부에서 목적 함수를 최적화하여 계산된다. 이 목적 함수는 섭동과 관련하여 네트워크의 최악의 경우 성능을 개선하려고 시도한다. 결과적으로 결과 모델의 clean accuracy가 낮아진다.
이를 해결하기 위해 다음 목적 함수를 사용하여 깨끗한 이미지와 적대적 이미지 모두에 대해 학습할 수 있다.
\[\begin{equation} \mathbb{E}_{(x, y) \sim \mathcal{D}} [L (\theta, \tilde{x}, y) + \lambda \max_{\delta \in \mathcal{P}} L (\theta, \tilde{x} + \delta, y) + f(\theta)] \end{equation}\]이 목적 함수는 적대적 이미지를 정규화 또는 data augmentation의 한 형태로 사용하여 분산되지 않은 데이터에서 잘 수행되는 특정 표현으로 네트워크를 강제한다. 이러한 네트워크는 어느 정도의 견고성을 나타내지만 여전히 우수한 정확도를 가지고 있다. 보다 최근에는 깨끗하고 강력한 ImageNet 테스트 데이터셋 모두에서 CNN의 성능 향상을 가져오는 split batch norm이 제안되었다. 이는 적대적 견고성과는 관련이 없으며 본 논문에서도 마찬가지이다.
2. Pyramid Adversarial Training
픽셀별 적대적 이미지는 $x^a = x + \delta$로 정의되며 여기서 섭동 분포 $\mathcal{P}$는 지정된 $l_p$-norm에 대해 지정된 볼 \(\mathcal{B}_\epsilon\) 내부에 있도록 각 픽셀 위치에서 섭동을 클립하는 클리핑 함수 $C_{\mathcal{B}_\epsilon}로 구성되며, 여기서 $\epsilon$은 섭동의 최대 반경이다.
동기
픽셀별 적대적 이미지의 경우 $\epsilon$의 값 또는 목적 함수의 내부 루프 step 수를 늘리면 결국 clean accuracy가 떨어진다. 개념적으로 픽셀 공격은 매우 유연하며 큰 $L_2$ 거리 변경을 할 수 있는 경우 분류 중인 개체를 파괴할 수 있다. 이러한 이미지로 학습하면 네트워크가 손상될 수 있다. 대조적으로, 밝기와 같은 augmentation은 큰 $L_2$ 거리로 이어질 수 있지만 구조화되어 있기 때문에 객체를 보존한다. 주된 동기는 두 장점을 모두 갖춘 공격을 설계하는 것이다. 이 공격은 클래스 정체성을 유지하면서 큰 이미지 차이로 이어질 수 있다.
접근 방식
여러 스케일에서 입력 이미지를 섭동시켜 적대적 예시를 생성하는 pyramid adversarial training (PyramidAT)을 제안한다. 이 공격은 여러 스케일로 구성되어 있기 때문에 더 유연하면서도 더 구조화되어 있지만 섭동은 각 스케일에서 제한된다.
\[\begin{equation} x^a = C_{\mathcal{B}_1} (\tilde{x} + \sum_{s \in S} m_s \cdot C_{\mathcal{B}_{\epsilon_s}} (\delta_s)) \end{equation}\]여기서 \(C_{\mathcal{B}_1}\)는 정상 범위 내에서 이미지를 유지하는 클리핑 함수, $S$는 스케일의 집합, $m_s$는 스케일 $s$에 대한 곱셈 상수, $\delta_s$는 $x$와 동일한 모양의 학습된 섭동이다. 스케일 $s$의 경우 $\delta_s$의 가중치는 모든 $i \in [0, \textrm{width}/s]$와 $j \in [0, \textrm{height}/s]$에 대해 왼쪽 상단 모서리가 $[s \cdot i, s \cdot j]$인 $s \times s$의 정사각형 영역에 있는 픽셀에 대해 공유된다. 픽셀 adversarial training과 유사하게 각 채널 이미지가 독립적으로 섭동된다.
공격 설정
픽셀 공격과 피라미드 공격 모두에 대해 여러 step을 사용하여 임의 레이블에 Projected Gradient Descent (PGD)를 사용한다. Loss과 관련하여 ViT의 경우 실제 레이블의 negative loss을 최대화하면 공격적인 레이블 누출이 발생한다. 이를 방지하기 위해 임의 레이블을 선택한 다음 해당 임의 레이블에 대한 softmax cross-entropy loss를 최소화한다.
3. “Matched” Dropout and Stochastic Depth
ViT 모델에 대한 표준 학습은 dropout과 stochastic depth를 모두 regularizer로 사용한다. Adversarial training 동안 깨끗한 샘플과 적대적 샘플을 모두 mini-batch로 가지고 있다. 이는 adversarial training 중 dropout 처리에 대한 질문을 제기한다. Adversarial training 논문들의 일반적인 전략은 dropout 또는 stochastic depth를 사용하지 않고 적대적 샘플을 생성하는 것이다. 그러나 이로 인해 dropout으로 학습된 깨끗한 샘플과 dropout이 없는 적대적 샘플을 사용하여 둘 다 loss에 사용될 때 깨끗한 학습 경로와 적대적 학습 경로 사이에 학습 불일치가 발생한다. Mini-batch의 각 학습 인스턴스에 대해 깨끗한 분기는 네트워크의 부분 집합만 업데이트하고 적대적 분기는 전체 네트워크를 업데이트한다. 따라서 적대적 분기 업데이트는 평가 중에 모델 성능과 더 밀접하게 정렬되므로 clean accuracy를 희생시키면서 robust accuracy가 향상된다. 이 목적 함수는 다음과 같다.
\[\begin{equation} \mathbb{E}_{(x,y) \sim \mathcal{D}} [L (\mathcal{M} (\theta), \tilde{x}, y) + \lambda \max_{\delta \in \mathcal{P}} L (\theta, x^a, y) + f(\theta)] \end{equation}\]여기서 $\mathcal{M} (\theta)$는 임의의 dropout mask와 stochastic depth 구성이 있는 네트워크를 나타낸다. 위의 문제를 해결하기 위해 깨끗한 분기와 적대적 분기 모두에 대해 동일한 dropout 구성을 사용하는 “matched” dropout을 제안한다.
Experiments
- 모델: ViT-B/16
- 데이터셋: ImageNet-1K, ImageNet-21K
- 구현 디테일
- batch size: 4096
- learning rate: 0.001, cosine decay schedule, 처음 1만 step은 linear warmup
- optimizer: AdamW
- augmentation: RandAug (2, 15)
- dropout 확률: 0.1
- pixel attack
- learning rate = $1/255$, $\epsilon = 4/255$, SGD 5 step
- PGD를 사용하여 적대적 섭동을 생성
- pyramid attack
- $S = [32, 16, 1]$
- $m_s = [20, 10, 1]$
- $\epsilon_s = 6/255$
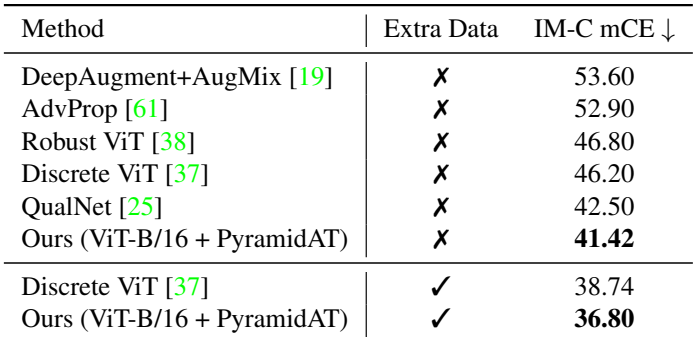
1. Experimental Results on ViT-B/16
다음은 ImageNet-1k에서의 결과이다.
다음은 ImageNet-C에서 SOTA와 mean Corruption Error (mCE)를 비교한 표이다.
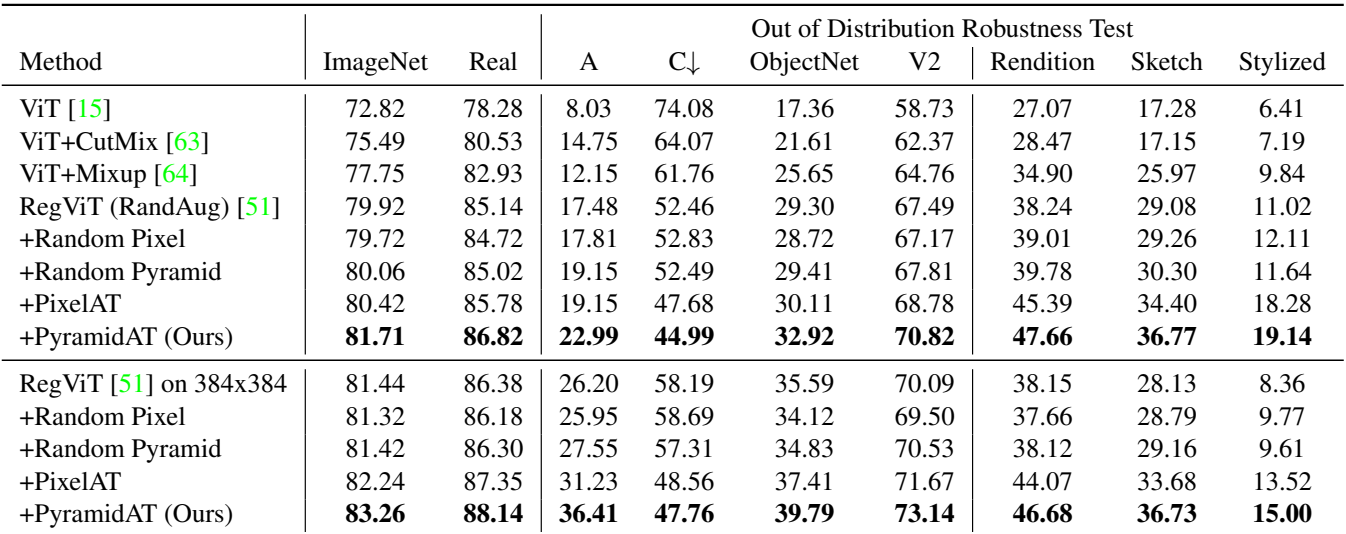
다음은 ImageNet-R에서 SOTA와 top-1 정확도를 비교한 표이다. Extra data는 ImageNet-21k이다.
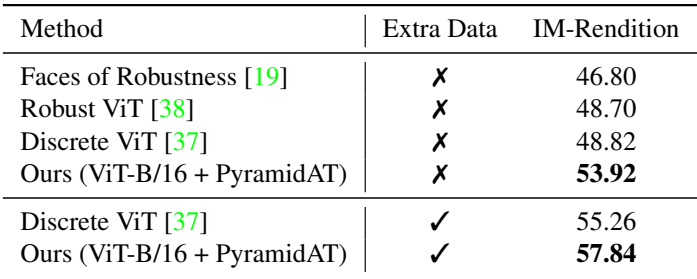
다음은 ImageNet-Sketch에서 SOTA와 top-1 정확도를 비교한 표이다. Extra data는 ImageNet-21k이다.
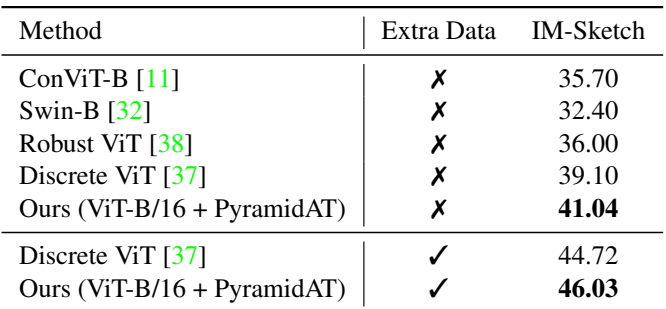
다음은 ImageNet-21K에서 사전 학습 후 ImageNet-1K에서 fine-tuning한 결과이다.

2. Ablations
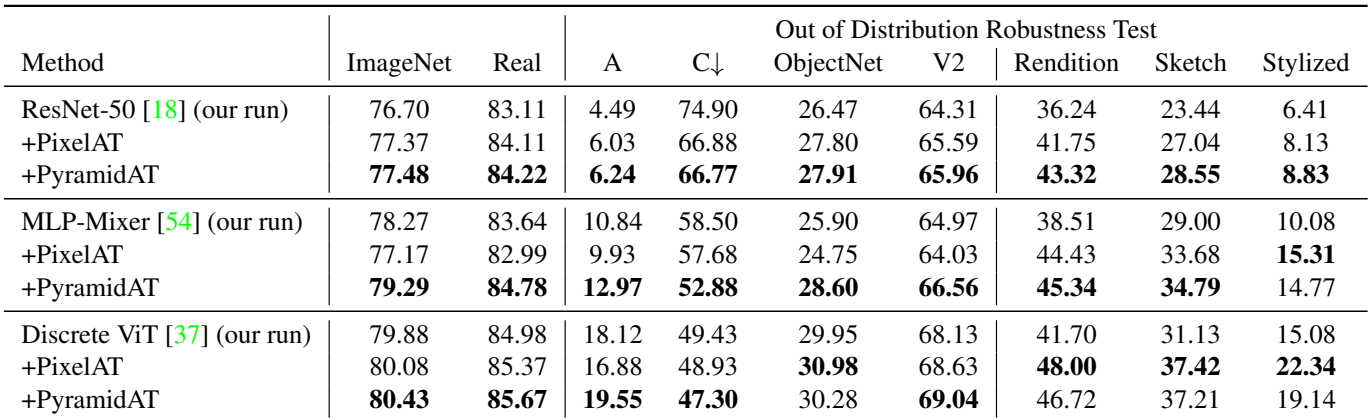
다음은 PixelAT와 PyramidAT를 ResNet-50, MLP-Mixer, Discrete ViT에 적용한 결과이다.
다음은 matched dropout에 대한 ablation 결과이다.

다음은 피라미드 구조에 대한 ablation 결과이다.

다음은 더 작은 강도의 random augmentation을 사용한 Ti/16에서의 결과이다.
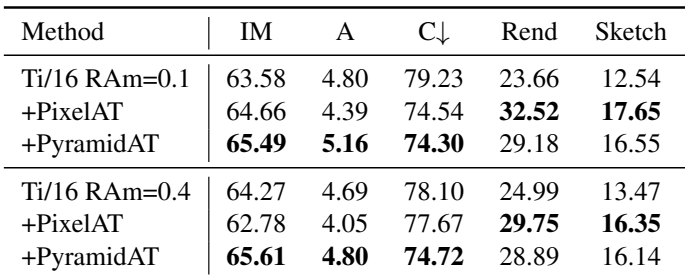
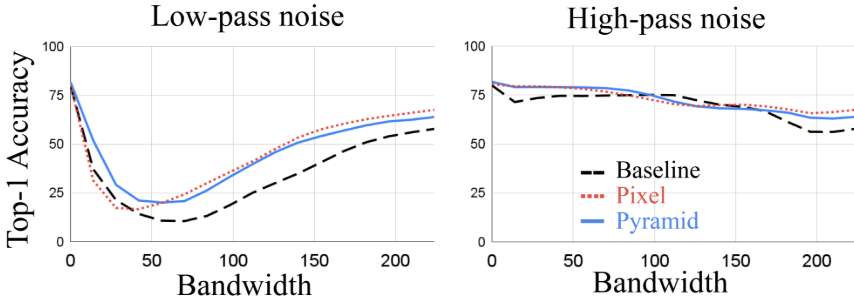
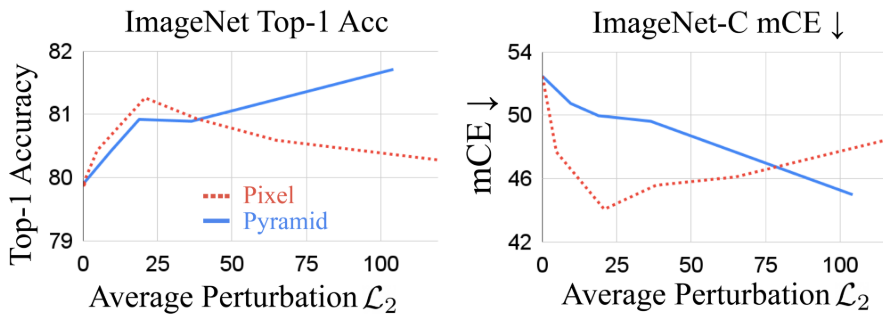
다음은 clean data와 robust data에 대한 성능을 섭동 크기에 따라 나타낸 그래프이다.
3. Analysis and Discussions
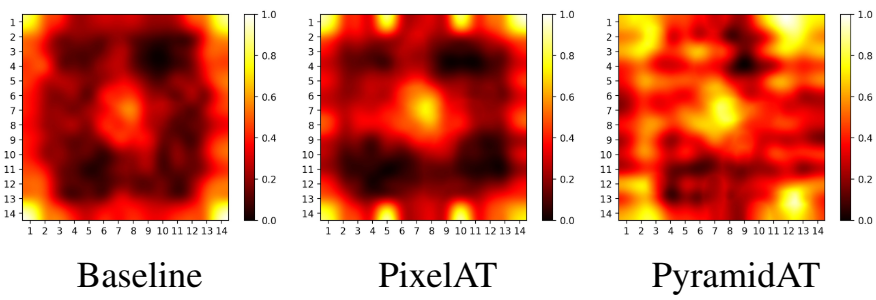
다음은 여러 모델에 대한 attention을 시각화한 것이다.

다음은 ImageNet-A에 대한 평균 attention이다.
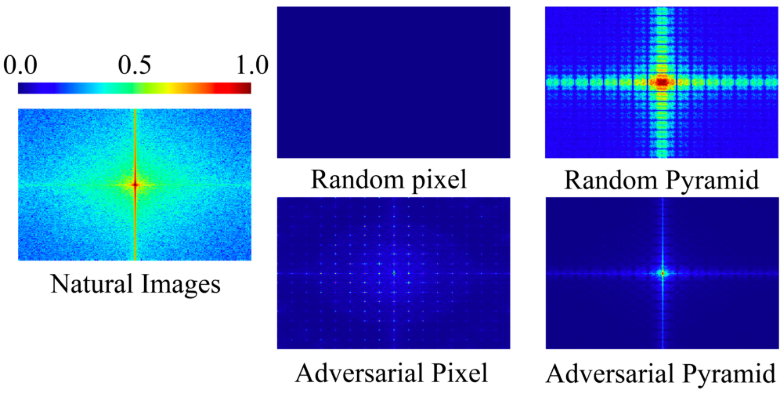
다음은 공격을 시각화한 것이다.

다음은 여러 섭동에 대한 푸리에 스펙트럼을 나타낸 히트맵이다.
다음은 low-pass filtering된 noise와 high-pass filtering된 noise에 대한 top-1 정확도를 나타낸 그래프이다.