[논문리뷰] Optimizing Prompts for Text-to-Image Generation (Promptist)
NeurIPS 2023. [Paper] [Github]
Yaru Hao, Zewen Chi, Li Dong, Furu Wei
Microsoft Research
19 Dec 2022
Introduction
생성 기반 모델은 언어 모델 및 text-to-image 모델을 포함하여 사용자 지침을 따르도록 프롬프팅될 수 있다. 프롬프트 디자인이 생성 품질에 필수적인 역할을 한다는 것이 인식되었다. 모델이 의도를 더 잘 이해하고 더 높은 품질의 결과를 생성하도록 프롬프트를 조정해야 한다. Stable Diffusion의 CLIP 텍스트 인코더와 같은 텍스트 인코더의 용량이 상대적으로 작기 때문에 text-to-image 모델에서 문제가 심각하다. 또한 일반적인 사용자 입력이 현재 모델로 미적으로 만족스러운 이미지를 생성하기에는 종종 불충분하다.
이전의 연구들은 특정 text-to-image 모델에 대한 수동 프롬프트 엔지니어링을 구현하며 일반적으로 원래 입력에 일부 modifiers를 추가한다. 그러나 수동 프롬프트 엔지니어링을 수행하는 것은 힘들고 때로는 실행 불가능하다. 게다가 수동으로 엔지니어링된 프롬프트는 종종 다양한 모델 버전 간에 전송할 수 없다. 따라서 사용자의 의도와 다양한 모델 선호 프롬프트를 자동으로 정렬하는 체계적인 방법을 찾을 필요가 있다.
본 연구에서는 강화 학습을 통한 자동 프롬프트 엔지니어링을 위한 프롬프트 적응 프레임워크를 제안한다. 특히 수동으로 엔지니어링된 프롬프트의 작은 컬렉션에서 사전 학습된 언어 모델 (ex. GPT)을 사용하여 supervised fine-tuning을 먼저 수행한다. Fine-tuning된 모델은 강화 학습을 위한 프롬프트 정책 네트워크를 초기화하는 데 사용된다. 다음으로 모델은 사용자 입력의 최적화된 프롬프트를 탐색하여 학습되며 생성 품질과 다양성을 보장하기 위해 다양한 beam search가 사용된다. 목적 함수는 생성된 이미지의 관련성 점수와 미적 점수의 조합으로 정의되는 reward를 최대화한다. 관련성 점수는 즉각적인 적응 후에도 원래 사용자 의도가 얼마나 유지되는지를 반영한다. 미적 점수는 생성된 이미지가 미적으로 만족스러운 정도를 나타낸다.
저자들은 공개적으로 사용 가능한 Stable Diffusion 모델로 실험을 수행하였다. 자동 reward metric과 사람의 선호도 레이팅을 모두 사용하여 방법을 평가하였다. 실험 결과에 따르면 최적화된 프롬프트가 인간이 조작한 프롬프트와 원래 입력보다 성능이 뛰어났다. 사람의 선호도 레이팅도 in-domain과 out-of-domain의 외부 프롬프트에서 일관된 개선을 보여주었다. 또한 강화 학습이 supervised fine-tuning보다 특히 out-of-domain 사용자 입력에 대해 더 유리하다는 것을 발견했다. 전반적으로 언어 모델이 모델 선호 프롬프트에 대한 사용자 입력을 최적화하는 프롬프트 인터페이스 역할을 할 수 있음을 보여주었다.
Methods
프롬프트 적응 프레임워크의 목표는 프롬프트 엔지니어링을 자동으로 수행하는 것이다. Text-to-image generator의 사용자 입력이 주어지면 모델은 원래 의도를 유지하면서 더 나은 출력 이미지를 얻는 모델 선호 프롬프트를 생성하는 방법을 학습한다.
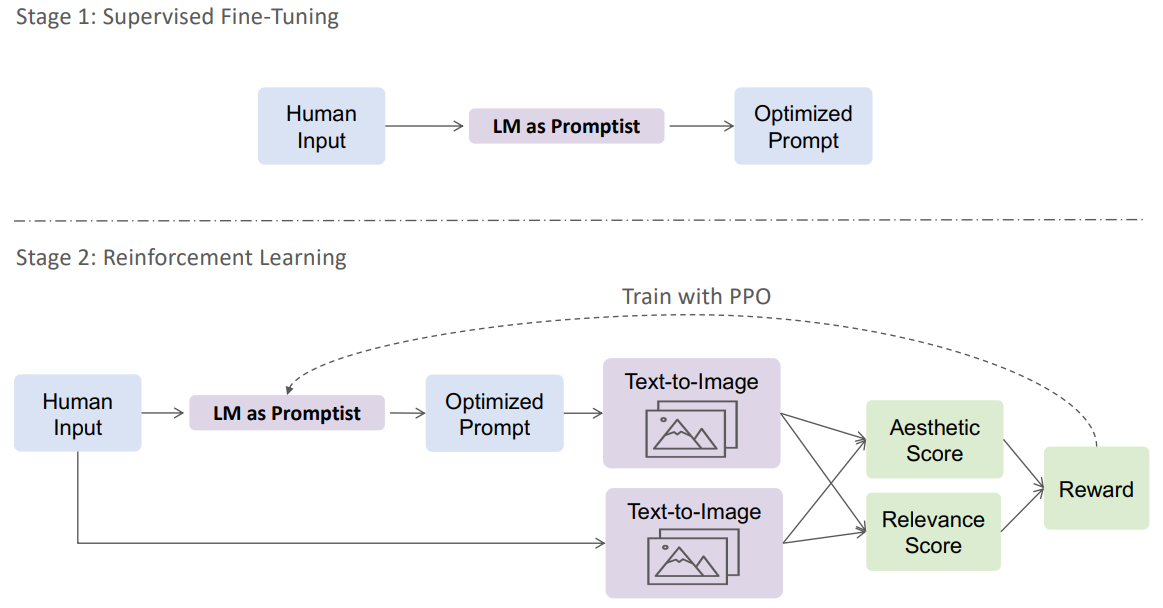
위 그림은 본 논문의 방법의 개요를 보여준다. 프롬프트 최적화 모델의 이름은 Promptist이며, GPT와 같은 사전 학습된 언어 모델을 기반으로 한다. 먼저 일련의 사람이 엔지니어링한 예제를 수집하고 supervised fine-tuning을 수행하는 데 사용한다. 다음으로 목표 reward를 최대화하기 위해 강화 학습을 수행하여 생성된 이미지의 관련성과 품질을 모두 향상시킨다.
1. Supervised Fine-tuning
사전 학습된 생성 언어 모델로 초기화된 policy 모델은 강화 학습 전에 프롬프트 쌍 세트에서 먼저 fine-tuning돤다. 병렬 프롬프트 코퍼스 \(D = \{(x, y)\}\)는 원래 사용자 입력 $x$와 수동으로 엔지니어링된 예제 $y$의 프롬프트 쌍을 포함한다. 목적 함수는 teacher forcing으로 log-likelihood를 최대화한다.
\[\begin{equation} \mathcal{L}_\textrm{SFT} = - \mathbb{E}_{(x, y) \sim \mathcal{D}} \log p (y \vert x) \end{equation}\]여기서 fine-tuning된 가중치는 강화 학습에서 policy 네트워크를 초기화하는 데 사용된다.
Collect Human Demonstrations
저자들은 Lexica에서 사람이 엔지니어링한 프롬프트를 수집한다. 대부분의 프롬프트는 두 부분, 즉 사용자의 의도를 설명하는 주요 콘텐츠와 아티스트 이름 및 인기 요소와 같은 아트 스타일을 커스터마이징하는 일부 modifier로 구성된다. 크롤링된 프롬프트를 타겟으로 사용한다. 병렬 데이터를 갖기 위해 세 가지 방법을 사용하여 소스 입력을 구성한다.
- 수식어를 다듬어 주요 콘텐츠를 추출하고 원래의 사용자 입력으로 간주한다.
- 일부 modifier를 무작위로 제거하거나 섞고 나머지 텍스트를 소스 입력으로 사용한다.
- OpenAI GPT를 사용하여 주요 콘텐츠와 프롬프트를 각각 다시 표현한다.
2. Reward Definition
관련성과 심미성이라는 두 가지 측면에서 최적화된 프롬프트의 품질을 측정한다. 두 가지 관점에서 reward function $\mathcal{R} (\cdot)$을 정의하도록 동기를 부여한다.
먼저 생성된 이미지가 프롬프트 적응 후 원래 입력 프롬프트와 관련이 있는지 측정한다. 구체적으로 말하면, 먼저 최적화된 프롬프트에 따라 text-to-image 모델로 이미지를 샘플링한다. 그런 다음 CLIP 유사도 점수를 계산하여 생성된 이미지와 원본 입력 프롬프트의 관련성을 측정한다. 관련성 점수는 다음과 같이 정의된다.
\[\begin{equation} f_\textrm{rel} (x, y) = \mathbb{E}_{i_y \sim \mathcal{G} (y)} [\min (20 \cdot g_\textrm{CLIP} (x, i_y) - 5.6, 0)] \end{equation}\]여기서 $i_y \sim \mathcal{G} (y)$는 $y$를 입력 프롬프트로 사용하여 text-to-image 모델 $\mathcal{G}$에서 이미지 $i_y$를 샘플링하는 것을 의미하고 $g_\textrm{CLIP}$은 CLIP 유사도 함수를 나타낸다. 항상 생성된 이미지와 원본 입력 프롬프트 간의 유사도를 계산하여 관련성 점수가 사용자 선호도를 반영하도록 한다. 관련성 점수가 상대적으로 합리적이면 모델이 미적으로 더 만족스러운 이미지를 생성하도록 권장한다.
둘째, 미적 선호도를 정량화하기 위해 미적 predictor를 사용한다. Predictor는 Aesthetic Visual Analysis 데이터셋에서 사람의 평가로 학습되는 고정된 CLIP 모델 위에 linear estimator를 구축한다. 미적 점수는 다음과 같이 정의된다.
\[\begin{equation} f_\textrm{aes} (x, y) = \mathbb{E}_{i_x \sim \mathcal{G} (x), i_y \sim \mathcal{G} (y)} [g_\textrm{aes} (i_y) - g_\textrm{aes} (i_x)] \end{equation}\]여기서 $g_\textrm{aes}$는 미적 predictor를 나타내고 $i_y$와 $i_x$는 프롬프트 $y$와 $x$에 의해 각각 생성된 이미지이다. $g_\textrm{CLIP}$과 $g_\textrm{aes}$ 모두 CLIP 모델이 필요하므로 reward 계산 중에 CLIP forward pass를 공유할 수 있다.
마지막으로, 계수 $\eta$로 policy 모델 $\pi_\theta$와 supervised fine-tuning 모델 $\pi_\textrm{SFT}$ 사이에 있는 추가 KL penalty와 위의 점수를 결합하여 전체 reward를 정의한다.
\[\begin{equation} \mathcal{R} (x, y) = f_\textrm{aes} (x, y) + f_\textrm{rel} (x, y) - \eta \log \frac{\pi_\theta (y \vert x)}{\pi_\textrm{SFT} (y \vert x)} \end{equation}\]과도한 최적화 문제를 완화하기 위해 KL 항이 추가되었다.
3. Reinforcement Learning
Supervised fine-tuning에서 시작하여 강화 학습으로 모델을 fine-tuning한다. 경험적으로 데이터 효율적이고 안정적인 성능을 제공하는 proximal policy optimization (PPO)를 사용한다. 텍스트 생성 문제로서 프롬프트 최적화는 Markov decision process (MDP) $\langle \mathcal{S}, \mathcal{A}, r, f_\textrm{st}, \gamma \rangle$로 볼 수 있다. 여기서 $\mathcal{S}$는 유한한 state space, $\mathcal{A}$는 action space, $r$은 reward function, $f_\textrm{st}$는 state-transition 확률 함수, $\gamma$는 discount factor이다.
프롬프트 적응의 episode에서 초기 state $x \in \mathcal{S}$는 $n$개의 토큰이 있는 입력 프롬프트 $x = (x_1, \ldots, x_n)$이며 각 토큰 $x$는 유한한 vocabulary $\mathcal{V}$에서 나온다. $t$번째 timestep에서 agent는 현재 policy 모델 $y_t \sim \pi (y \vert x, y_{< t})$에 따라 action $y_t \in \mathcal{V}$를 선택한다. 결정론적 state transition에서 다음 state는
\[\begin{equation} (x, y_{< t+1}) = (x_1, \ldots, x_n, y_1, \ldots, y_t) \end{equation}\]이다. Agent가 end-of-sentence action을 선택하면 episode가 종료된다. Agent의 목표는 누적된 reward 기대값
\[\begin{equation} \mathbb{E}_{x, y} \sum_t \gamma^t r (x, y_{< t}) = \mathbb{E}_{x, y} \mathcal{R} (x, y) \end{equation}\]를 최대화하는 것이다.
$\pi_\theta$가 학습될 policy 모델이라 하자. 학습 세트 \(\mathcal{D}' = \{x\}\)에 대한 누적된 reward 기대값을 최대화한다.
\[\begin{equation} \mathcal{J} = \mathbb{E}_{x \sim \mathcal{D}', y \sim \pi_\theta} [\mathcal{R} (x, y)] \end{equation}\]Policy 모델 $\pi_\theta$와 value function 모델을 각각 언어 모델링 head와 회귀 head를 사용하여 생성 언어 모델로 구현한다. 두 모델의 파라미터는 supervised fine-tuning policy 모델 $\pi_\textrm{SFT}$에서 초기화되고 강화 학습 중에 최적화된다. $\pi_\textrm{SFT}$와 score function 모델은 학습 중에 고정된다. 또한 대규모 policy 업데이트를 피하기 위해 clipped probability ratio를 사용한다.
Experiments
- 데이터 수집
- Supervised fint-tuning: 9만 개의 타겟 프롬프트를 수집하고 4가지 유형의 소스 프롬프트를 구성하여 총 36만 쌍의 데이터를 얻음
- 강화 학습: 소스 프롬프트만 필요하며 policy는 더 나은 표현 자체를 탐색할 수 있음
- 저자들은 세 가지 유형의 데이터를 사용
- DiffusionDB의 in-domain 프롬프트: 탐색을 위해 사용자 입력을 사용하고 비교를 위해 수동으로 엔지니어링된 프롬프트
- COCO 데이터셋의 out-of-domain 이미지 캡션
- ImageNet-21k의 이미지 레이블: 크기는 각각 60만, 60만, 4만
- 학습 설정
- Policy 모델의 경우 15억 개의 파라미터가 있는 GPT-2를 사용
- Supervised fint-tuning
- GPT-2를 fine-tuning하여 teacher forcing으로 소스 프롬프트로 컨디셔닝된 타겟 프롬프트를 예측
- 입력 형식: [Source] Rephrase:[Target]
- batch size = 256, learning rate = $5 \times 10^{-5}$, 최대 길이 = 512
- 15,000 step로 fine-tuning하고 validation loss에 따라 약간 underfitting된 체크포인트를 선택
- 강화 학습
- PPO로 policy 학습
- value network와 policy network는 supervised fine-tuning 모델에서 초기화
- value function의 파라미터는 두 목적 함수 사이의 과도한 경쟁을 피하기 위해 policy에서 분리됨
- 탐색의 품질과 다양성을 보장하기 위해 beam 크기 8과 다양성 페널티 1.0의 다양한 beam search를 채택
- 모델이 긴 문장만 탐색하는 것을 방지하기 위해 각 step의 최대 생성 길이는 15에서 75 사이의 임의 값으로 설정
- 반환된 프롬프트 중 하나를 랜덤하게 선택하여 policy를 업데이트
- 프롬프트당 3개의 이미지를 생성하고 분산을 줄이기 위해 평균 reward를 계산
- batch size = 512, learning rate = $5 \times 10^{-5}$
- episode는 12,000개, PPO epochs는 batch당 4개
- value loss 계수 = 2.3, KL reward 계수 = 0.2
1. Results
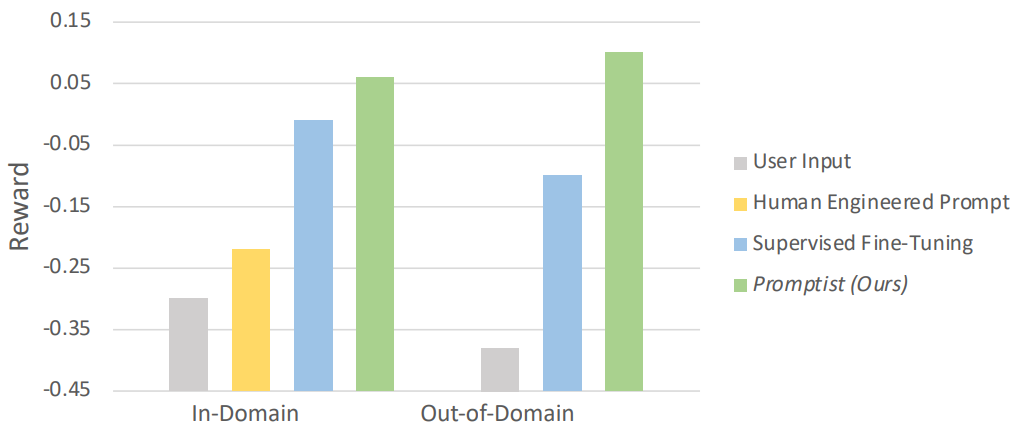
다음은 in-domian 및 out-of-domain 데이터에 대하여 다른 baseline과 최적화된 프롬프트의 reward를 비교한 그래프이다.
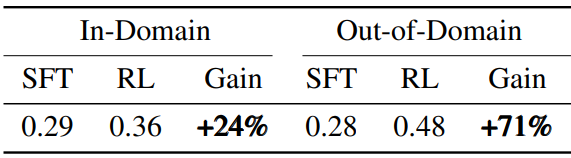
다음은 강화 학습 후의 reward 개선을 나타낸 표이다.
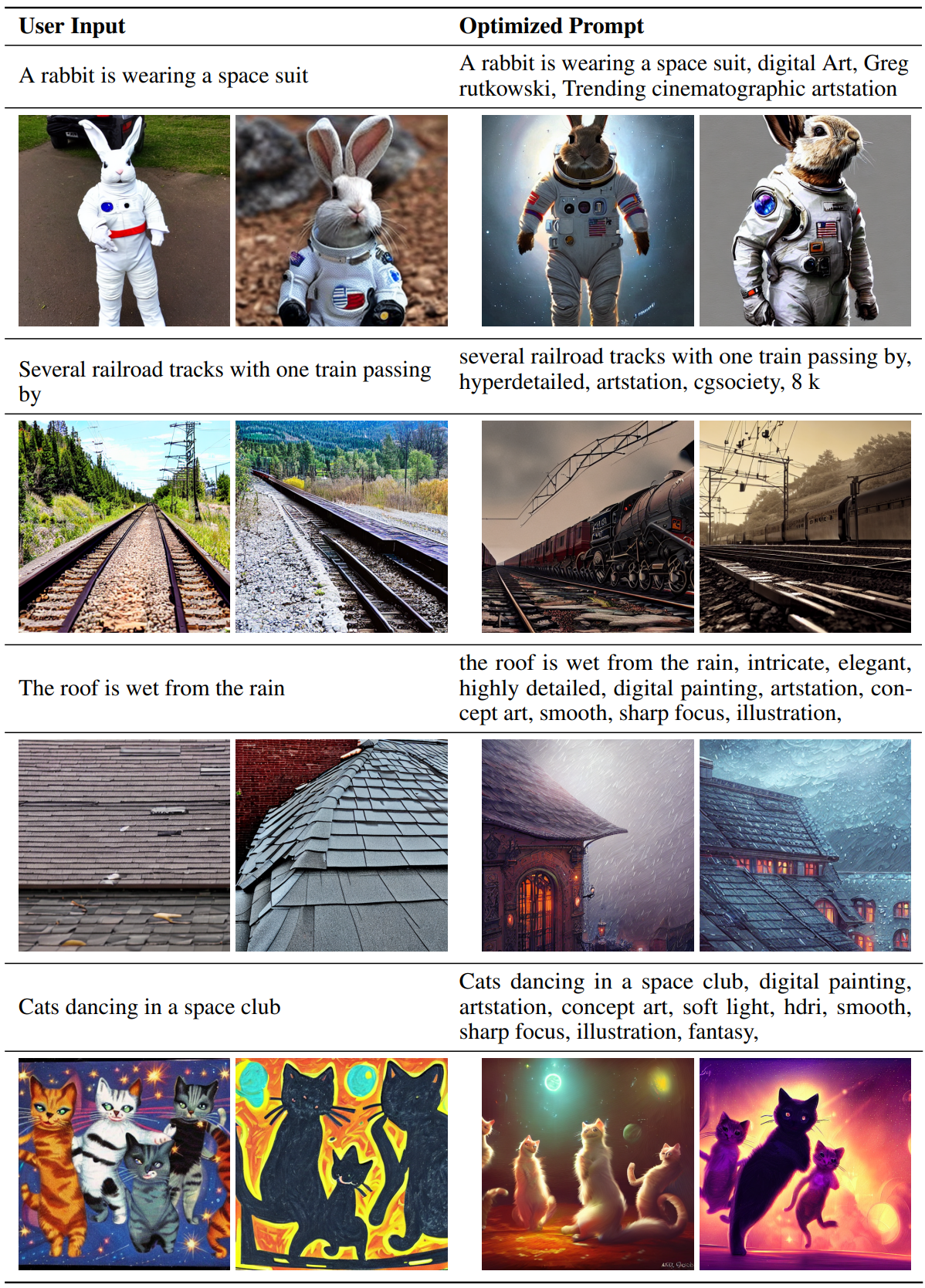
다음은 Stable Diffusion에서 사용자 입력과 최적화된 프롬프트에 의해 생성된 이미지이다.
2. Human Evaluation
다음은 human evaluation 결과이다. 주황색 블록은 두 프롬프트가 똑같이 만족스러운 이미지를 생성한다는 것을 의미한다.
