[논문리뷰] Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
arXiv 2023. [Paper]
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, Tim Rocktäschel
Google DeepMind
28 Sep 2023
Introduction
프롬프트는 foundation model의 다운스트림 성능에 핵심이다. 예를 들어, 다양한 프롬프트 전략은 모델의 추론 능력, 멀티모달 처리 능력, 도구 사용 능력에 중요한 영향을 미칠 수 있다. 또한 프롬프트는 모델 distillation를 개선할 수 있으며 에이전트 동작을 시뮬레이션하는 데 사용될 수 있다.
그러나 이러한 프롬프트 전략은 수동으로 설계된다. 프롬프트를 표현하는 구체적인 방식은 그 유용성에 극적인 영향을 미칠 수 있으므로 프롬프트 엔지니어링이 자동화될 수 있는지에 대한 의문이 제기된다. Automatic Prompt Engineer (APE)는 데이터셋의 여러 입출력 예에서 문제를 추론하는 또 다른 프롬프트를 사용하여 프롬프트의 초기 분포를 생성함으로써 이 문제를 해결하려고 한다. 그러나 APE는 3 라운드 후에 품질이 안정화되는 것처럼 보이므로 추가 선택 라운드에서의 리턴이 감소한다는 점을 발견하였고 결과적으로 반복적인 APE의 사용을 포기했다. 본 논문은 LLM 프롬프트의 자기 참조적 자체 개선을 위한 진화 알고리즘 (evolutionary algorithm)을 유지하는 다양성을 통해 리턴 감소 문제에 대한 솔루션을 제안한다.
신경망의 프로그램은 가중치 행렬이다. 결과적으로 이 “프로그램”은 신경망 자체에 의해 자기 참조 방식으로 변경될 수 있다. 스스로를 개선하고 스스로 개선하는 방식을 개선하는 신경망은 AI의 개방형 자기 참조적 자체 개선을 향한 중요한 디딤돌이 될 수 있다. 그러나 자기 참조 가중치 행렬을 통한 자체 개선에는 모델의 모든 파라미터를 수정하는 추가 파라미터가 필요하므로 비용이 많이 든다. LLM의 행동과 능력은 제공하는 프롬프트에 의해 크게 영향을 받기 때문에 프롬프트를 LLM의 프로그램으로 유사하게 생각할 수 있다. 이러한 관점에서 Scratchpad 방법이나 Chain-of-Thought Prompting와 같은 프롬프트 전략을 변경하는 것은 LLM의 “프로그램”을 변경하는 것과 같다. 이 비유를 더 발전시키면 LLM 자체를 사용하여 프롬프트를 변경할 수 있을 뿐만 아니라 이러한 프롬프트를 변경하는 방식을 통해 LLM에 기반을 둔 완전히 자기 참조적인 자체 개선 시스템으로 이동할 수 있다.
본 논문에서는 LLM의 자기 참조적 자체 개선을 위한 Promptbreeder (PB)를 소개한다. Mutation-prompt (ex. task-prompt를 수정하기 위한 명령), thinking-style (ex. 일반 인지 휴리스틱에 대한 텍스트 설명), 도메인별 문제 설명의 시드 집합이 주어지면 PB는 task prompt들의 변형과 mutation-prompt들을 생성하며, LLM이 돌연변이 연산자 (mutation operator) 역할을 하도록 유도될 수 있다는 사실을 활용하여 프롬프팅한다. 학습 세트에서 측정된 진화된 task-prompt의 적합성을 기반으로 task-prompt와 관련 mutation-prompt로 구성된 진화 unit의 부분집합을 선택하여 미래 세대에 전달할 수 있다. 여러 세대의 PB에 걸쳐 현재 도메인에 적응하는 프롬프트를 관찰할 수 있다. 예를 들어, PB는 GSM8K에서 task-prompt를 다음과 같이 발전시켰다.
“Show all your working. II. You should use the correct mathematical notation and vocabulary, where appropriate. III. You should write your answer in full sentences and in words. IV. You should use examples to illustrate your points and prove your answers. V. Your workings out should be neat and legible”
상식 추론, 산술, 윤리를 포괄하는 일반적으로 사용되는 광범위한 벤치마크에서 PB는 Chain-of-Thought이나 Plan-and-Solve prompting과 같은 SOTA 방법들을 능가한다. PB는 자기 참조적 자체 개선을 위해 파라미터 업데이트를 요구하지 않기 때문에 더 크고 더 유능한 LLM이 이 접근 방식의 이점을 더욱 증폭시킬 수 있다.
Promptbreeder
본 논문은 특정 도메인에 대한 프롬프트를 자동으로 탐색하고 해당 도메인의 질문에 대한 답변을 도출하는 LLM의 능력을 향상시키는 task-prompt를 찾을 수 있는 프롬프트 진화 시스템인 Promptbreeder를 소개한다. Promptbreeder는 동일한 시스템이 다양한 도메인에 적응할 수 있다는 점에서 범용적이다.
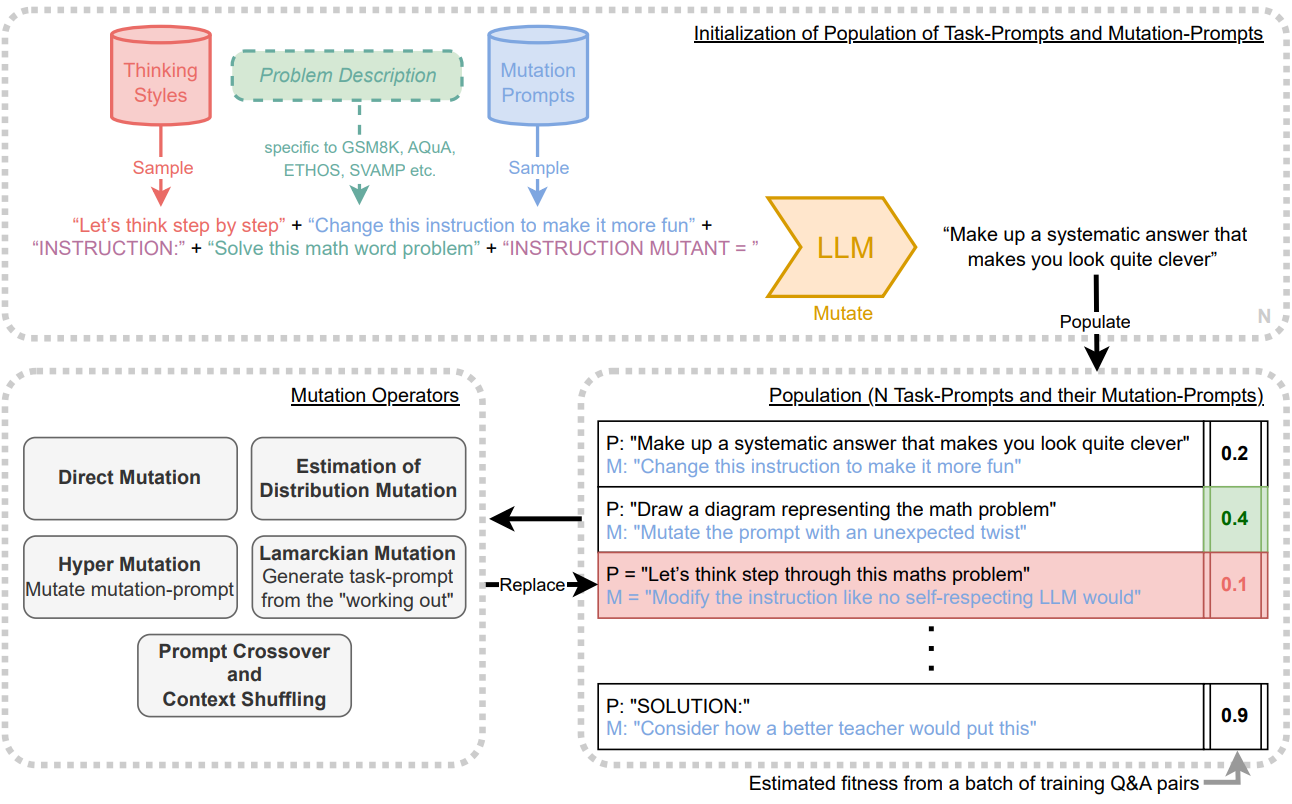
Promptbreeder는 LLM을 사용하여 입력 텍스트의 변형을 생성할 수 있다는 관찰을 활용한다. 위 그림은 Promptbreeder의 개요를 제공한다. 본 논문은 진화하는 task-prompt에 관심이 있다. Task-prompt $P$는 추가 입력 $Q$에 앞서 LLM의 컨텍스트를 컨디셔닝하는 데 사용되는 문자열로, $P$가 없을 때 $Q$가 제시된 경우보다 더 나은 응답을 보장하기 위한 것이다. 진화된 각 task-prompt의 적합성을 평가하기 위해 현재 도메인의 전체 학습 세트에서 100개의 Q&A 쌍 batch를 샘플링한다.
Promptbreeder는 진화 알고리즘 (evolutionary algorithm)에 따라 task-prompt를 생성한다. 이 알고리즘의 돌연변이 연산자(mutation operator)는 그 자체로 mutation-prompt $M$으로 컨디셔닝된 LLM이다. 즉, 돌연변이된 task-prompt $P^\prime$은 $P^\prime = \textrm{LLM}(M + P)$로 정의된다. 여기서 ‘+’는 문자열 concatenation에 해당한다.
Promptbreeder의 주요 자기 참조 메커니즘은 task-prompt뿐만 아니라 mutation-prompt에도 진화 알고리즘을 적용하는 것에서 비롯된다. 이 메타 레벨 알고리즘의 돌연변이 연산자는 다시 LLM이며, 이제 hyper-mutation-prompt $H$를 조건으로 한다. 즉, $M^\prime = \textrm{LLM}(H + M)$을 통해 돌연변이된 mutation-prompt $M^\prime$을 얻는다.
일련의 “thinking-style” $\mathcal{T}$와 초기 mutation-prompt의 집합 $\mathcal{M}$, 도메인별 문제 설명 $D$가 주어지면 Promptbreeder는 돌연변이된 task-prompt의 모집단을 초기화한다. 이는 task-prompt와 mutation-prompt가 1:1로 대응된다는 의미이다. 이 모집단을 발전시키기 위해 이진 토너먼트 유전자 알고리즘 프레임워크를 사용한다. 모집단에서 두 명의 구성원을 샘플링하고 적합도가 더 높은 구성원을 선택하여 돌연변이를 만들고 패자를 승자의 돌연변이 복사본으로 덮어쓴다.
1. Promptbreeder Initialization
구체적인 예를 들기 위해 GSM8K (초등학교 수학 단어 문제 데이터셋)에 대한 task-prompt와 mutation prompt를 생성하는 데 사용되는 초기화 단계를 고려하자. 문제 설명은 “답을 아라비아 숫자로 제공하여 수학 단어 문제를 해결하세요”이다. Plan-and-Solve는 두 개의 task-prompt를 사용하기 때문에 본 논문도 진화 unit당 두 개의 task-prompt와 mutation-prompt를 진화시킨다. 초기 프롬프트의 다양성을 위해 무작위로 뽑은 ‘mutation-prompt’ (ex. “Make a variant of the prompt.”)와 무작위로 뽑은 ‘thinking-style’ (ex. “Let’s think step by step”)을 문제 설명에 추가하고, 이를 LLM에 제공하여 continuation을 생성하면 초기 task-prompt가 생성된다. unit당 두 개의 초기 task-prompt를 생성하기 위해 이 작업을 두 번 수행한다. Mutation-prompt와 thinking-style은 모두 초기 mutation-prompt 집합과 thinking-style 집합에서 무작위로 샘플링된다. Mutation-prompt는 진화 unit에 추가되므로 진화 실행 전반에 걸쳐 특정 task-prompt와 연결된다.
위의 예에서 초기 task-prompt를 만들기 위해 LLM에 대한 전체 입력 문자열은 다음과 같을 수 있다.
“Make a variant of the prompt. Let’s think step by step. INSTRUCTION: Solve the math word problem, giving your answer as an arabic numeral. INSTRUCTION MUTANT:”
적절한 continuation을 장려하기 위해 “INSTRUCTION”과 “INSTRUCTION MUTANT”가 추가된다.
2. Mutation Operators
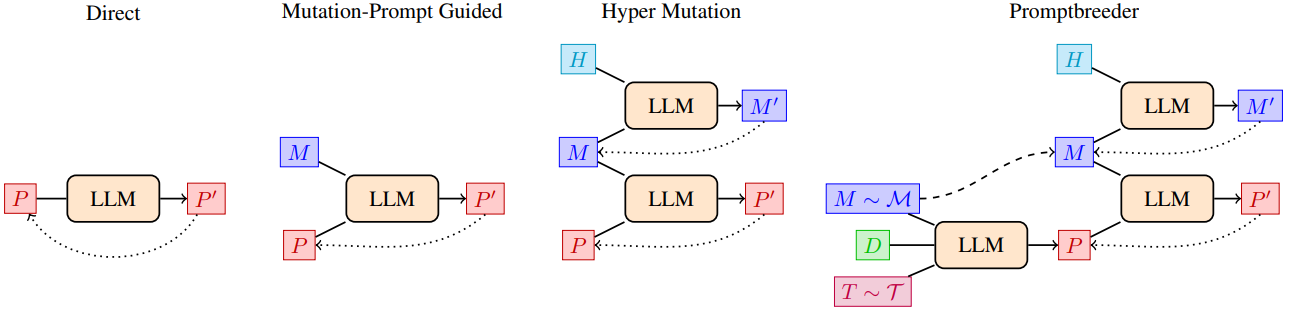
프롬프트 전략 탐색을 주도하는 5개의 광범위한 클래스에 속하는 9개의 연산자가 있다. 각 복제 이벤트에 대해 9개의 돌연변이 연산자 중 하나만 적용된다. 적용할 돌연변이 연산자를 결정하기 위해 9개의 연산자에 대해 균일한 확률로 샘플링한다. 이러한 다양한 연산자 집합을 사용하는 이유는 LLM이 문제의 틀을 반복적으로 변경하고 주어진 추론 문제 해결에 도움이 될 수 있는 자연어로 표현된 모델을 검색함으로써 스스로 질문하는 방법의 넓은 공간을 탐색할 수 있도록 하는 것이다. 위 그림은 Promptbreeder가 자기 참조적인 방식을 보여준다.
2.1 Direct Mutation
가장 간단한 종류의 돌연변이 연산자는 하나의 기존 task-prompt $P$ (1차 프롬프트 생성) 또는 새로운 task-prompt의 자유 형식 생성을 장려하는 일반 프롬프트 (0차 프롬프트 생성)에서 직접 새로운 task-prompt $P^\prime$를 생성한다.
Zero-order Prompt Generation: 문제 설명 $D$ (ex. “Solve the math word problem, giving your answer as an arabic numeral”)를 “A list of 100 hints:”이라는 프롬프트와 연결하여 새로운 task-prompt를 생성한다. 이는 LLM에게 주어진 문제 도메인의 문제를 해결하는 데 도움이 될 수 있는 새로운 힌트를 제공한다. 첫 번째로 생성된 힌트를 새 task-prompt로 추출한다. 결정적으로 이 새로운 task-prompt는 이전에 발견된 task-prompt에 의존하지 않는다. 대신 매번 문제 설명에서 다시 생성된다. 이 0차 연산자를 포함하는 이유는 프롬프트 진화가 분기되는 경우 이 연산자를 사용하면 원래 문제 설명과 밀접하게 관련된 새로운 task-prompt를 생성할 수 있기 때문이다.
First-order Prompt Generation: Mutation-prompt를 부모 task-prompt에 연결하고 이를 LLM에 전달하여 돌연변이된 task-prompt를 생성한다.
“Say that instruction again in another way. DON’T use any of the words in the original instruction there’s a good chap. INSTRUCTION: Solve the math word problem, giving your answer as an arabic numeral. INSTRUCTION MUTANT:”
이 절차는 무작위로 샘플링된 thinking-style 문자열을 사용하지 않는다는 점을 제외하면 초기화 방법과 동일하다. 1차 프롬프트 생성은 Promptbreeder의 표준 무성 돌연변이 연산자이며 모든 유전 알고리즘의 핵심이다. 하나의 부모 유전자형 (task-prompt)을 가져와 여기에 돌연변이를 적용한다 (이 경우 mutation-prompt의 영향을 받음).
2.2 Estimation of Distribution Mutation
돌연변이 연산자의 다음 클래스는 0개 또는 1개의 부모를 조건으로 삼는 것이 아니라 부모 집합을 조건으로 한다. 따라서 모집단의 패턴을 고려하면 표현력이 더 높아질 수 있다.
Estimation of Distribution (EDA) Mutation: 현재 task-prompt 모집단의 필터링되고 번호가 매겨진 목록을 LLM에 제공하고 새로운 task-prompt로 이 목록을 계속하도록 요청한다. 프롬프트 간의 코사인 유사도를 포함하는 BERT를 기반으로 프롬프트 모집단을 필터링한다. 목록의 다른 항목과 0.95 이상 유사한 구성원은 목록에 포함되지 않으므로 다양성이 장려된다. 프롬프트는 무작위 순서로 나열되며 모집단 내 구성원의 적합도 (fitness) 값에 대한 LLM 액세스 권한을 부여하지 않는다. 저자들은 예비 실험에서 LLM이 이러한 적합도 값을 이해하지 못하고 목록에 있는 항목의 복사본을 생성하는 데 의존했다는 사실을 발견했다.
EDA Rank and Index Mutation: Task-prompt가 적합도 순서로 나열되는 위의 변형이다. 예비 실험에서는 LLM이 목록의 뒷부분에 나타나는 요소와 유사한 항목을 생성할 가능성이 더 높다는 것을 보여주었다. 이는 LLM의 최근 효과에 대한 유사한 연구 결과와 일치한다. 따라서 이전과 같은 방식으로 필터링한 후 모집단의 task-prompt를 적합도 오름차순으로 정렬했다. 목록 맨 위에는 다음과 같은 프롬프트가 앞에 붙는다.
“INSTRUCTION: “ + $\langle\langle$mutation-prompt$\rangle\rangle$ + “\n A List of Responses in descending order of score.” + $\langle\langle$last index + 1$\rangle\rangle$ + “is the best response. It resembles” + $\langle\langle$ last index$\rangle\rangle$ + “more than it does (1)”
순서가 내림차순이라고 LLM에게 말함으로써 LLM에 ‘거짓말’을 하고 있다. 그렇지 않으면 최종 항목과 너무 유사한 새 항목을 생성하는 쪽으로 너무 편향되기 때문이다. 이 모순은 샘플링의 다양성을 향상시키는 것으로 보인다. 이 연산자의 이론적 근거는 LLM이 제안한 높은 적합도와 다양한 외삽(extrapolation)으로 현재 분포를 다시 표현한다는 것이다.
Lineage Based Mutation: 각 진화 unit에 대해 모집단 중 최고였던 혈통의 구성원의 역사, 즉 엘리트의 역사적 연대순 목록을 저장한다. 이 목록은 계속해서 새로운 프롬프트를 생성하기 위해 “GENOTYPES FOUND IN ASCENDING ORDER OF QUALITY”이라는 제목과 함께 연대순 (다양성으로 필터링되지 않음)으로 LLM에 제공된다. 이 연산자의 이론적 근거는 유전자형 프롬프트를 개선한다는 신호가 현재 모집단의 프롬프트에서 나오는 신호보다 더 강할 수 있다고 기대한다는 것이다. 왜냐하면 이 신호는 따라갈 수 있는 나쁜 프롬프트에서 좋은 프롬프트로의 기울기를 제공하기 때문이다 (이 신호가 LLM에서 사용될 수 있다고 가정).
2.3 Hypermutation: Mutation of Mutation-Prompts
앞서 설명한 돌연변이 연산자는 이미 다양한 task-prompt를 탐색했을 수 있지만, 자체 개선 시스템은 이상적으로 자기 참조 방식으로 자체 개선 방식도 개선해야 한다. 돌연변이 연산자의 세 번째 클래스에는 진화 가능성의 진화와 관련된 hyper-mutation 연산자가 포함된다. 이 연산자는 task reward 획득 프로세스가 아닌 검색/탐색 프로세스를 직접 수정한다.
Zero-order Hyper-Mutation: 원래의 문제 설명을 무작위로 샘플링된 thinking-style에 연결하고 이를 LLM에 제공하여 새로운 mutation-prompt를 생성한다. 이 mutation-prompt는 task-prompt에 적용되어 1차 프롬프트 생성에서와 같이 task-prompt의 변형을 만든다. 이 0차 메타 돌연변이 연산자는 초기화 중에 사용된 것과 동일하다. 이 연산자의 이론적 근거는 초기화와 유사한 방식으로 돌연변이 연산자를 생성하는 동시에 일련의 thinking-style에서 지식을 가져온다는 것이다.
First-order Hyper-Mutation: LLM이 새로운 돌연변이 프롬프트를 생성할 수 있도록 hyper-mutation-prompt “Please summarize and improve the following instruction:”를 mutation-prompt에 연결한다. 새로 생성된 이 mutation-prompt는 해당 unit의 task-prompt에 적용된다. 이러한 방식으로 새로 생성된 mutation-prompt를 통해 진화된 다운스트림 task-prompt의 품질에 대한 hyper-mutation의 영향을 한 번에 평가할 수 있다.
2.4 Lamarckian Mutation
이 돌연변이 연산자 클래스는 Lamarckian process를 모방한다. 성공적인 표현형 (즉, 진화된 task-prompt에 의해 유도된 정답을 생성하는 데 사용되는 구체적인 working out(산출 과정))을 사용하여 새로운 유전자형 (즉, 돌연변이 task-prompt)을 생성하려고 한다. 이 형태의 여러 프로세스가 LLM 연구에 나타났다 (ex. STaR, APO, APE).
Working Out to Task-Prompt: APE의 instruction induction과 유사한 Lamarckian 돌연변이 연산자이다. 다음과 같은 프롬프트를 통해 정답으로 이어지는 이전에 생성된 working out을 LLM에 제공한다.
“I gave a friend an instruction and some advice. Here are the correct examples of his workings out + $\langle\langle$correct working out$\rangle\rangle$ + The instruction was:”
이는 주어진 working out에서 task-prompt를 효과적으로 리버스 엔지니어링하는 것이다. 이러한 종류의 연산자는 문제 설명이 없거나 불충분하거나 오해의 소지가 있는 경우 매우 중요하다.
2.5 Prompt Crossover and Context Shuffling
돌연변이 연산자의 마지막 클래스는 교차 (crossover) 연산자와 진화 unit에 존재하는 few-shot 컨텍스트 예제를 섞는 연산자이다.
Prompt Crossover: 돌연변이 연산자가 적용된 후 task prompt가 모집단의 다른 구성원에서 무작위로 선택된 task-prompt로 대체될 확률은 10%이다. 이 구성원은 적합도에 비례하여 선택된다. 교차는 mutation-prompt에는 적용되지 않고 task-prompt에만 적용된다.
Context Shuffling: Promptbreeder는 task-prompt, mutation-prompt, few-shot 컨텍스트로 알려진 올바른 working out 집합을 동시에 발전시킬 수 있다. 후자를 달성하기 위해 정답을 도출하는 연습만으로 few-shot 컨텍스트를 채운다. 평가하는 동안 task-prompt 전에 few-shot 컨텍스트를 제공하여 원하는 working out 형식에 대한 guidance를 제공한다. Few-shot 컨텍스트 목록이 가득 찬 경우 무작위로 샘플링된 새로운 올바른 working out은 새로운 질문 세트에 대한 unit의 적합도 평가 후 목록의 기존 working out을 대체한다. 또한 10% 확률로 전체 컨텍스트 목록을 최대 컨텍스트 목록 길이에 반비례하는 확률로 다시 샘플링한다.
Experiments
- 모집단 크기: 50 unit
- 세대 수: 일반적으로 20~30 (세대는 모집단의 모든 구성원의 무작위 쌍을 형성하고 서로 경쟁하는 것을 포함)
- 데이터셋
- 산술적인 추론: GSM8K, SVAMP, MultiArith, AddSub, AQuA-RAT, SingleEq
- 상식적인 추론: CommonsenseQA (CSQA), StrategyQA (SQA)
- Instruction induction
- 증오심 표현 분류: ETHOS
다음은 Promptbreeder (PB)와 다른 프롬프팅 방법들을 비교한 표이다.
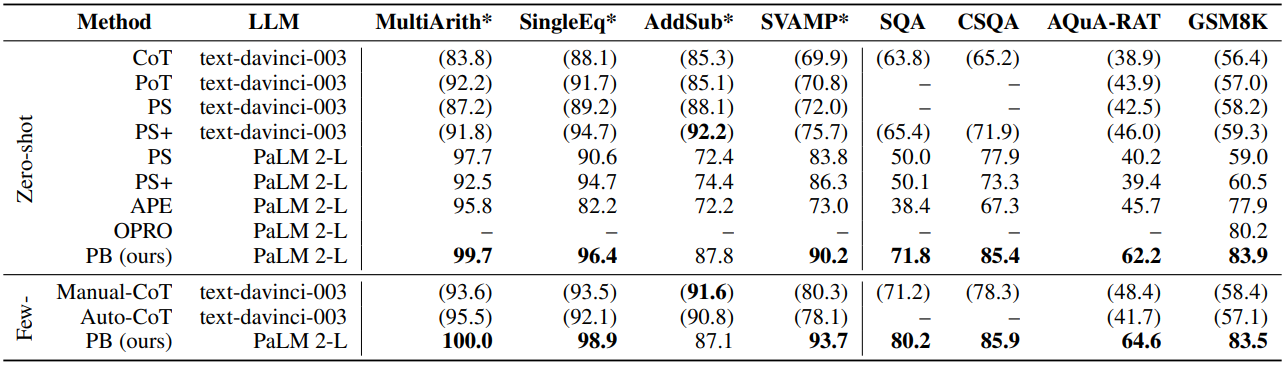
비교한 프롬프팅 방법들은 다음과 같다.
- Manual-CoT: Chain-of-Thought
- PoT: Program-of-Thoughts
- Auto-CoT
- OPRO
- APE: Automatic Prompt Engineer
- PS: Plan-and-Solve (PS+는 개선된 프롬프트 사용)
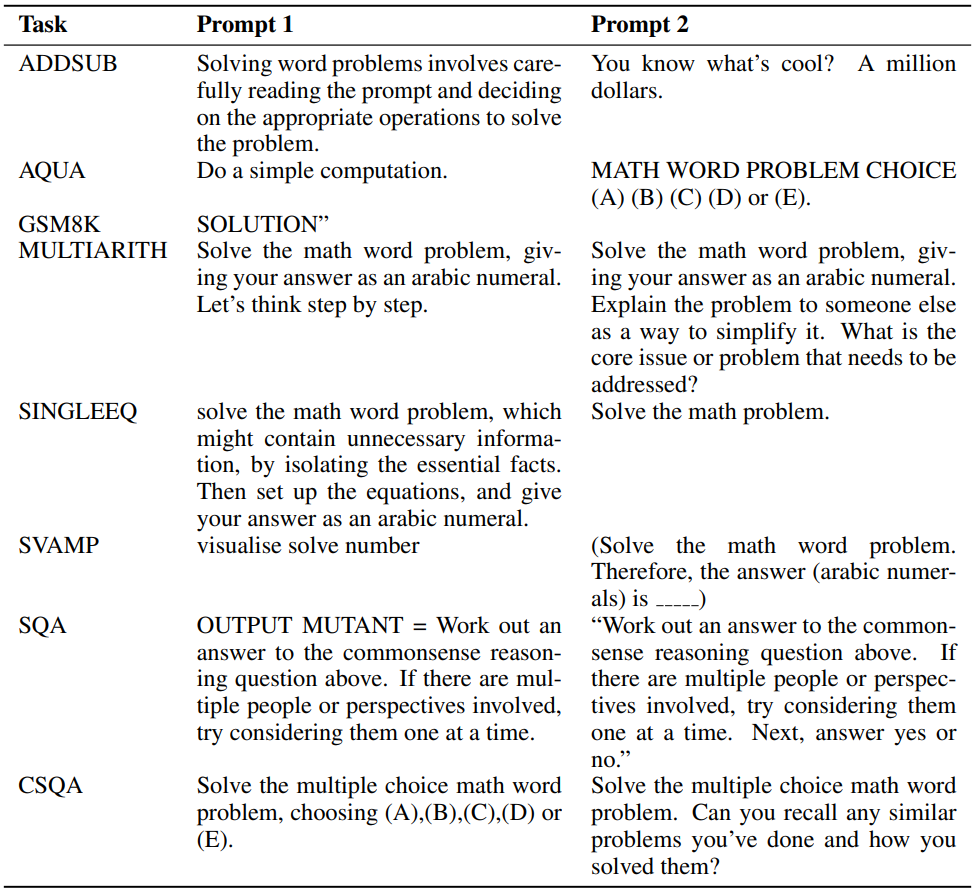
다음은 다양한 산술 task를 위해 진화된 2단계 task-prompt 결과이다.
다음은 GSM8K에서 Promptbreeder 학습을 하는 동안 자기 참조 방식으로 진화한 가장 성공적인 mutation-prompt들이다.

다음은 적용된 각 유형의 돌연변이 연산자에 대해 부모보다 적합도가 더 큰 자손이 생성되는 횟수의 비율이다. (GSM8k)
