[논문리뷰] Prompt-to-Prompt Image Editing with Cross Attention Control
arXiv 2022. [Paper] [Page] [Github]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, Daniel Cohen-Or
Google Research | Tel Aviv University
2 Aug 2022

Introduction
최근 Imagen, DALL·E 2, Parti와 같은 대규모 언어 이미지 (LLI) 모델은 경이적인 생성 semantic 및 구성 능력을 보여주었다. 이러한 LLI 모델은 매우 큰 언어-이미지 데이터셋에서 학습되며 autoregressive model과 diffusion model을 포함한 최신 이미지 생성 모델을 사용한다. 그러나 이러한 모델은 간단한 편집 수단을 제공하지 않으며 일반적으로 주어진 이미지의 특정 semantic 영역에 대한 제어가 부족하다. 특히, 텍스트 프롬프트에 약간의 변화만 있어도 완전히 다른 출력 이미지로 이어질 수 있다.
이를 피하기 위해 LLI 기반 방식은 사용자가 인페인팅할 이미지의 일부를 명시적으로 마스킹하고 원래 이미지의 배경과 일치시키면서 마스킹된 영역에서만 변경되도록 이미지를 편집해야 한다. 이 접근 방식은 매력적인 결과를 제공했지만 마스킹 절차가 번거롭고 빠르고 직관적인 텍스트 기반 편집을 방해한다. 또한 이미지 콘텐츠를 마스킹하면 인페인팅 프로세스에서 완전히 무시되는 중요한 구조 정보가 제거된다. 따라서 특정 개체의 텍스처 수정과 같은 일부 편집 능력은 인페인팅 범위를 벗어난다.
본 논문에서는 Prompt-to-Prompt 조작을 통해 사전 학습된 텍스트 조건부 diffusion model에서 이미지를 의미론적으로 편집하는 직관적이고 강력한 텍스트 편집 방법을 소개한다. 이를 위해 cross-attention layer를 깊이 파고들고 생성된 이미지를 제어하는 핸들로서의 의미론적 강점을 탐구한다.
특히 프롬프트 텍스트에서 추출한 픽셀과 토큰을 결합하는 고차원 텐서인 내부 cross-attention map을 고려한다. 저자들은 이러한 맵이 생성된 이미지에 결정적으로 영향을 미치는 풍부한 의미론적 관계를 포함하고 있음을 발견했다.
핵심 아이디어는 diffusion process 중에 cross-attention map을 주입하여 이미지를 편집할 수 있다는 것이다. Diffusion step 중에 어떤 픽셀이 프롬프트 텍스트의 어떤 토큰에 attention 되는지 제어한다. 본 논문의 방법을 다양한 창의적 편집 애플리케이션에 적용하기 위해 간단하고 의미론적인 인터페이스를 통해 cross-attention map을 제어하는 몇 가지 방법을 보여준다.
- 장면 구성을 유지하기 위해 cross-attention map을 수정하는 동안 프롬프트에서 단일 토큰의 값을 변경
- 이미지를 전체적으로 편집
- 생성된 이미지에서 단어의 의미론적 효과를 증폭하거나 약화시킴
본 논문의 접근 방식은 텍스트 프롬프트만 편집하여 직관적인 이미지 편집 인터페이스를 구성하며, Prompt-to-Prompt라고 부른다. 이 방법을 사용하면 어려운 다양한 편집 작업이 가능하며 모델 학습, finetuning, 추가 데이터 또는 최적화가 필요하지 않다. 분석을 통해 편집된 프롬프트에 대한 충실도와 소스 이미지 사이의 trade-off를 인식하여 생성 프로세스에 대한 훨씬 더 많은 제어가 가능하다. 저자들은 기존의 reverse process를 사용하여 본 논문의 방법이 실제 이미지에 적용될 수 있음을 보여주었다.
Method
텍스트 프롬프트 $\mathcal{P}$와 랜덤 시드 $s$를 사용하여 text-guided diffusion model에 의해 생성된 이미지라고 가정하자. 본 논문의 목표는 편집된 프롬프트 $\mathcal{P}^\ast$에 의해서만 guide되는 입력 이미지를 편집하여 편집된 이미지 $\mathcal{I}^\ast$를 만드는 것이다. 저자들은 이전 연구들과 달리 편집이 발생해야 하는 위치를 지원하거나 표시하기 위해 사용자 정의 마스크에 의존하는 것을 피하려고 하였다. 내부 randomness를 수정하고 편집된 텍스트 프롬프트를 사용하여 재생성하면 간단하지만 실패한다.
저자들의 주요 관찰은 생성된 이미지의 구조와 모양이 임의의 시드뿐만 아니라 diffusion process를 통해 포함된 텍스트에 대한 픽셀 간의 상호 작용에도 의존한다는 것이다. Cross-attention layer에서 발생하는 픽셀-텍스트 상호 작용을 수정하여 Prompt-to-Prompt 이미지 편집을 가능하게 한다. 보다 구체적으로, 입력 이미지 $\mathcal{I}$의 cross-attention map을 주입하면 원본 구성과 구조를 보존할 수 있다.
1. Cross-attention in text-conditioned Diffusion Models
Imagen text-guided synthesis model을 backbone으로 사용한다. 구성과 기하학적인 요소는 대부분 64$\times$64 해상도에서 결정되기 때문에 super-resolution 프로세스를 그대로 사용하여 text-to-image diffusion model만 적용한다. 각 diffusion step $t$는 U자형 신경망을 사용하여 noisy한 이미지 $z_t$와 텍스트 임베딩 $\psi(\mathcal{P})$에서 noise를 예측하는 것으로 구성된다. 마지막 step에서 이 프로세스는 생성된 이미지 $\mathcal{I} = z_0$을 산출한다. 가장 중요한 것은 두 modality 간의 상호 작용이 noise 예측 중에 발생하며, 여기에서 시각적 및 텍스트 feature의 임베딩이 각 텍스트 토큰에 대한 spatial attention map을 생성하는 cross-attention layer를 사용하여 융합된다.
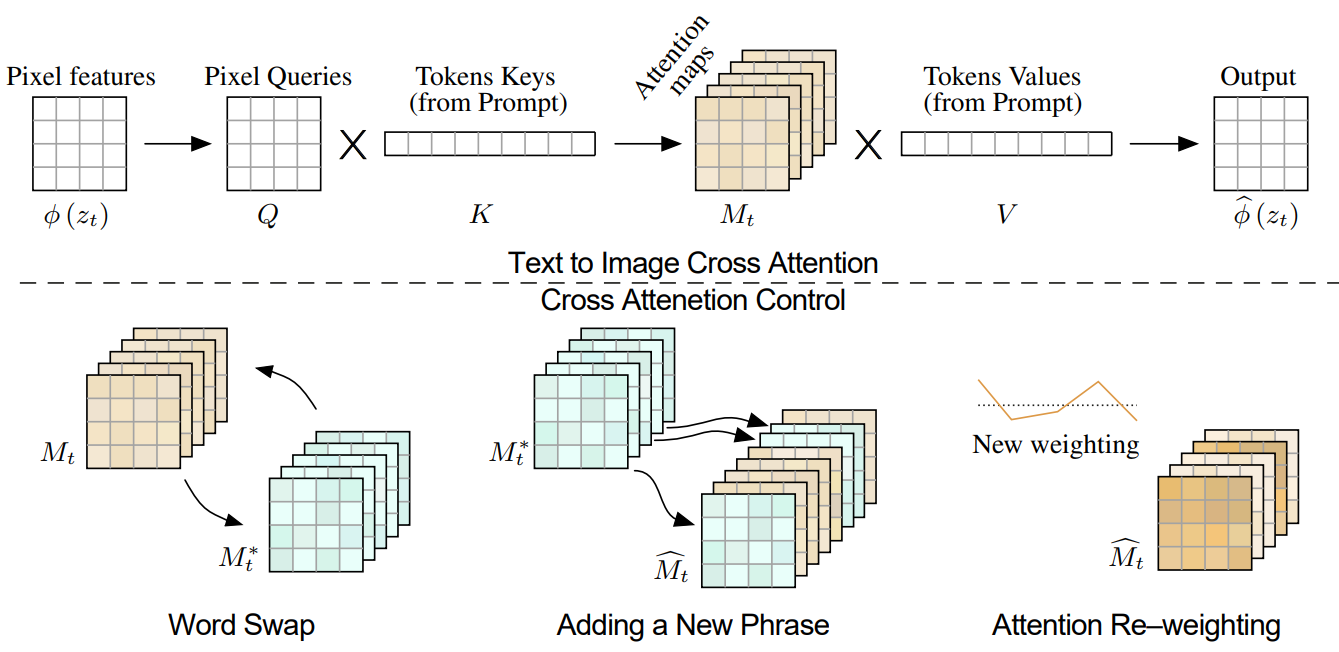
위 그림의 상단과 같이 noisy한 이미지 $\phi(z_t)$의 공간적 feature는 query 행렬 $Q = l_Q(\phi(z_t))$에 project되고 텍스트 임베딩은 key 행렬 $K = l_K(\psi(\mathcal{P}))$와 value 행렬 $V = l_V (\psi(\mathcal{P}))$에 project된다. 여기서 $l_Q$, $l_K$, $l_V$는 학습된 linear projection이다. 그러면 attention map은 다음과 같다.
여기서 $M_{ij}$는 픽셀 $i$에서 $j$번째 토큰 값의 가중치를 정의하고 $d$는 key와 query의 latent projection 차원이다. Cross-attention 출력은 $\hat{\phi} (z_t) = MV$로 정의되며, 공간적 feature $\phi(z_t)$를 업데이트하는 데 사용된다.
직관적으로 cross-attention 출력 $MV$는 $V$의 가중 평균이며 가중치는 attention map M이고 $Q$와 $K$의 유사도와 관련이 있다. 실제로는 표현력을 높이기 위해 multi-head attention을 사용한다. 그런 다음 결과를 concat하고 학습된 linear layer를 통과하여 최종 출력을 얻는다.
Imagen은 GLIDE와 유사하게 두 가지 유형의 attention layer를 통해 각 diffusion step의 noise 예측에 텍스트 프롬프트로 컨디셔닝된다.
- Cross-attention layer
- 단순히 각 self-attention layer의 key-value 쌍에 텍스트 임베딩 시퀀스를 concat하여 self-attention과 cross-attention으로 모두 작동하는 hybrid attention
본 논문의 방법은 hybrid attention의 cross-attention 부분에만 개입하기 때문에 둘 다 cross-attention이라고 한다. 즉, 텍스트 토큰을 참조하는 마지막 채널만 hybrid attention 모듈에서 수정된다.
2. Controlling the Cross-attention
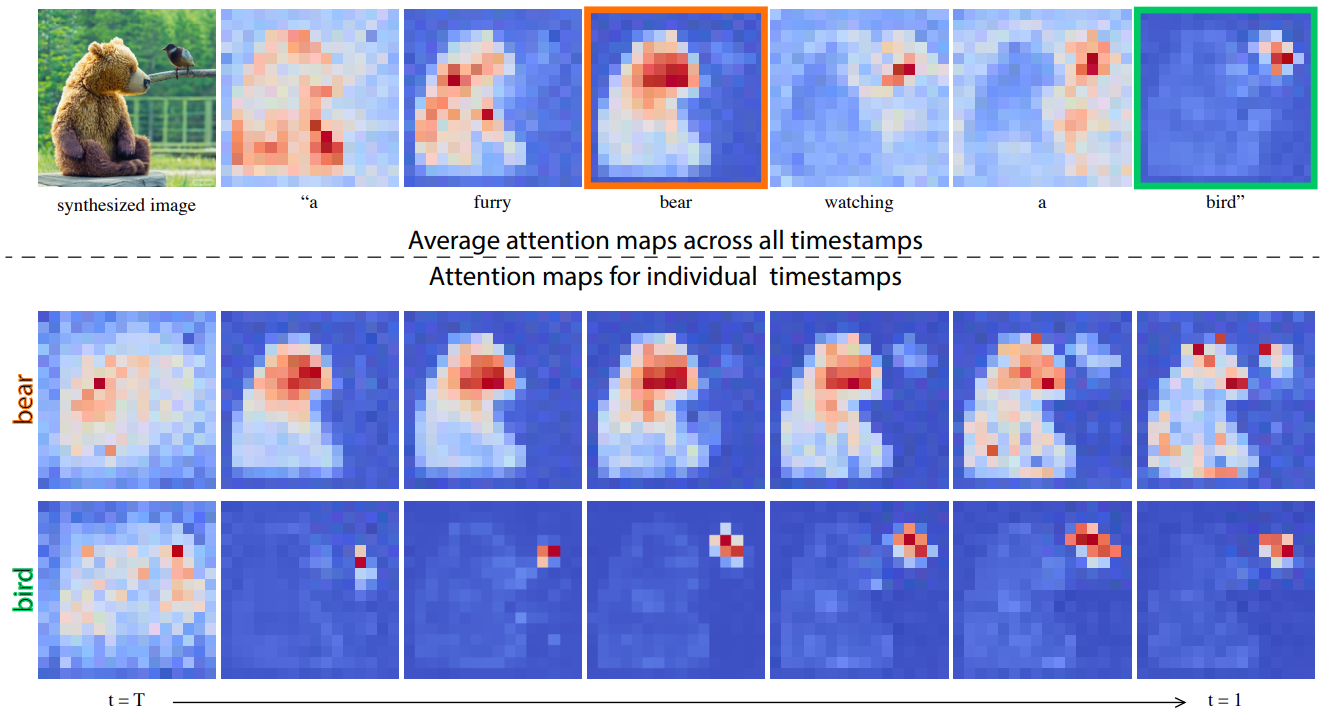
생성된 이미지의 공간 레이아웃과 기하학적인 요소는 cross-attention map에 따라 달라진다. 픽셀과 텍스트 사이의 이러한 상호 작용은 위 그림에 설명되어 있다 (평균 attention map). 볼 수 있듯이 픽셀은 픽셀을 설명하는 단어에 더 attention 된다. 평균은 시각화 목적으로 수행되며 attention map은 각 head에 대해 별도로 유지된다. 흥미롭게도 이미지의 구조는 diffusion process의 초기 step에서 이미 결정되어 있음을 알 수 있다.
Attention은 전체 구성을 반영하므로 원래 프롬프트 $\mathcal{P}$에 대한 생성에서 얻은 attention map $M$을 수정된 프롬프트 $\mathcal{P}^\ast$가 있는 두번째 생성에 주입할 수 있다. 이것은 편집된 프롬프트에 따라 조작될 뿐만 아니라 입력 이미지 $\mathcal{I}$의 구조를 보존하는 편집된 이미지 $\mathcal{I}^\ast$의 합성을 가능하게 한다.
$DM(z_t, \mathcal{P}, t, s)$는 noisy헌 이미지 $z_{t-1}$을 출력하는 diffusion process의 단일 step $t$와 attention map $M_t$(사용하지 않는 경우 생략됨)의 계산이라고 하자. Attention map $M$을 추가로 주어진 map $M_c$로 재정의하지만 제공된 프롬프트에서 value $V$를 유지하는 diffusion step을 \(DM(z_t, \mathcal{P}, t, s) \{M \leftarrow \hat{M}\}\)으로 표시한다. 또한 편집된 프롬프트 $\mathcal{P}^\ast$를 사용하여 생성된 attention map을 $M_t^\ast$로 표시한다. 마지막으로 $Edit (M_t, M_t^\ast, t)$를 일반적인 편집 함수로 정의하여 원본 이미지와 편집된 이미지의 $t$번째 attention map을 생성하는 동안 입력으로 받는다.
일반적인 알고리즘은 원하는 편집 작업에 따라 attention 기반 조작이 각 step에서 적용되는 두 프롬프트에 대해 동시에 반복적인 diffusion process를 수행하는 것으로 구성된다. 위의 방법이 작동하려면 내부 randomness를 수정해야 한다. 이는 동일한 프롬프트에 대해 두 개의 랜덤 시드가 크게 다른 출력을 생성하는 diffusion model의 특성 때문이다. 일반적인 알고리즘은 다음과 같다.

프롬프트 $\mathcal{P}$와 랜덤 시드 $s$에 의해 생성된 이미지 $\mathcal{I}$를 추가 입력으로 정의할 수도 있다. 그러나 알고리즘은 동일하게 유지된다. 더욱이 diffusion step은 동일한 batch에서 $z_t-1$와 $z_t^\ast$ 모두에 적용될 수 있으므로 diffusion model의 원래 inference와 관련하여 단 하나의 step 오버헤드가 있다.
특정 편집 연산을 처리하는 $Edit (M_t, M_t^\ast, t)$ 함수의 정의는 다음과 같다.
Word Swap
이 경우 사용자는 원래 프롬프트의 토큰을 다른 것과 교환한다 (ex. $\mathcal{P}$ = “a big red bicycle”, $\mathcal{P}^\ast$ = “a big red car”). 주요 과제는 원본 구성을 보존하면서 새로운 프롬프트의 내용을 다루는 것이다. 이를 위해 소스 이미지의 attention map을 수정된 프롬프트로 생성에 주입한다. 그러나 제안된 attention 주입은 대규모 구조 수정이 포함된 경우 기하학적 요소를 과도하게 제한할 수 있다. 더 부드러운 attention 제한을 제안하여 이 문제를 해결한다.
\[\begin{equation} Edit (M_t, M_t^\ast, t) := \begin{cases} M_t^\ast & \quad \textrm{if } t < \tau \\ M_t & \quad \textrm{otherwise} \end{cases} \end{equation}\]여기서 $\tau$는 주입이 적용되는 step까지를 결정하는 timestep 파라미터이다. 구성은 diffusion process의 초기 step에서 결정된다. 따라서 주입 step의 수를 제한함으로써 새로운 프롬프트에 적응하는 데 필요한 기하학적 자유를 허용하면서 새로 생성된 이미지의 구성을 guide할 수 있다. 알고리즘의 또 다른 완화 방법은 프롬프트의 다른 토큰에 대해 다른 수의 주입 timestep을 할당하는 것이다. 두 단어가 다른 수의 토큰을 사용하여 표현되는 경우 정렬 함수를 사용하여 필요에 따라 map을 복제/평균화할 수 있다.
Adding a New Phrase
또 다른 설정에서 사용자는 프롬프트에 새 토큰을 추가한다. 일반적인 디테일을 유지하기 위해 두 프롬프트의 공통 토큰에만 attention 주입을 적용한다. 대상 프롬프트 $\mathcal{P}^\ast$에서 토큰 인덱스를 수신하고 일치하는 항목이 없으면 $\mathcal{P}$ 또는 $None$으로 해당 토큰 인덱스를 출력하는 정렬 함수 $A$를 사용한다. 그러면 편집 함수는 다음과 같다.
\[\begin{equation} (Edit (M_t, M_t^\ast, t))_{i, j} := \begin{cases} (M_t^\ast)_{i, j} & \quad \textrm{if } A(j) = None \\ (M_t)_{i, A(j)} & \quad \textrm{otherwise} \end{cases} \end{equation}\]인덱스 $i$는 픽셀 값에 해당하고 $j$는 텍스트 토큰에 해당한다. 주입이 적용되는 diffusion step의 수를 제어하기 위해 timestep $\tau$를 설정할 수 있다. 이러한 종류의 편집을 통해 스타일 지정, 객체 속성 지정 또는 글로벌한 조작과 같은 다양한 Prompt-to-Prompt 능력을 사용할 수 있다.
Attention Re–weighting
마지막으로 사용자는 각 토큰이 결과 이미지에 영향을 미치는 정도를 강화하거나 약화시킬 수 있다. 예를 들어 프롬프트 $\mathcal{P}$ = “푹신한 빨간 공”에서 공을 조금 더 혹은 조금 덜 푹신하게 만들고 싶다고 하자. 이러한 조작을 위해서 파라미터 $c \in [-2, 2]$를 사용하여 할당된 토큰 $j^\ast$의 attention map을 확장하여 더 강하거나 약한 효과를 얻는다. 나머지 attention map은 변경되지 않는다.
\[\begin{equation} (Edit (M_t, M_t^\ast, t))_{i, j} := \begin{cases} c \cdot (M_t)_{i, j} & \quad \textrm{if } j = j^\ast \\ (M_t)_{i, j} & \quad \textrm{otherwise} \end{cases} \end{equation}\]Applications
Text-Only Localized Editing
다음은 attention 주입을 통해 컨텐츠를 수정한 결과이다.

다음은 왼쪽 상단 이미지에서 “나비”라는 단어의 attention 가중치만 주입하여 구조와 모양을 보존하면서 컨텍스트를 대체한 예시이다.

나비가 매우 그럴듯한 방식으로 모든 물체 위에 앉아 있다.
다음은 다양한 diffusion step의 수에 attention을 주입한 예시이다.

다음은 초기 프롬프트의 설명을 확장하여 로컬하게 편집한 예시이다.

Global editing
다음은 초기 프롬프트의 설명을 확장하여 글로벌하게 편집한 예시이다.

다음은 소스 attention map을 주입하면서 프롬프트에 스타일 설명을 추가하여 원본 이미지의 구조를 보존하면서 새로운 스타일을 적용한 예시이다.

Fader Control using Attention Re-weighting
다음은 fader 제어를 통한 텍스트 기반 이미지 편집 예시이다.

Real Image Editing
다음은 실제 이미지를 편집한 예시이다. 왼쪽은 DDIM 샘플링을 사용한 inversion 결과이다. 주어진 실제 이미지와 텍스트 프롬프트에서 초기화된 diffusion process를 reverse한다. 이로 인해 diffusion process에 공급될 때 입력 이미지에 대한 근사치를 생성하는 latent noise가 생긴다. 오른쪽은 Prompt-to-Prompt 기술을 적용하여 이미지를 편집한 것이다.

다음은 inversion 실패 케이스이다.

실제 이미지의 현재 DDIM 기반 inversion은 만족스럽지 못한 재구성을 초래할 수 있다.