[논문리뷰] Prompt-Free Diffusion: Taking “Text” out of Text-to-Image Diffusion Models
CVPR 2024. [Paper] [Github]
Xingqian Xu, Jiayi Guo, Zhangyang Wang, Gao Huang, Irfan Essa, Humphrey Shi
SHI Labs | Tsinghua University | UT Austin | Georgia Tech | Picsart AI Research (PAIR)
25 May 2023
Introduction
개인화된 합성 결과에 대한 높은 수요로 인해 모델 fine-tuning, 프롬프트 엔지니어링, 제어 가능한 편집을 비롯한 여러 text-to-image (T2I) 관련 기술이 새로운 차원의 중요성으로 떠오르게 되었다. 다양한 각도에서 개인화 task를 다루기 위한 최근 연구들도 상당수 등장하였다. 간단한 접근 방식 중 하나는 예시 이미지로 T2I 모델을 fine-tuning하는 것이다. DreamBooth와 같은 개인화 튜닝 기술은 모델 가중치를 fine-tuning하여 유망한 품질을 보여주었다. 그들의 단점은 아직 명백하다. 모델을 fine-tuning하는 것은 보다 효율적인 튜닝 노력이 증가하고 있음에도 불구하고 일반 사용자에게는 여전히 리소스 비용이 많이 든다. 프롬프트 엔지니어링은 T2I 모델을 개인화하기 위한 가벼운 대안 역할을 한다. 비용이 거의 들지 않고 출력 품질이 향상되기 때문에 업계에서 널리 채택되었다. 그럼에도 불구하고 맞춤형 결과를 얻기 위해 고품질 텍스트 프롬프트를 검색하는 것은 과학이라기보다는 예술에 가깝다. 또한 원하는 이미지를 텍스트로 설명하려는 시도는 종종 모호해지고 섬세한 시각적 디테일을 포괄적으로 다룰 수 없다.
개인화된 요구 사항을 더 잘 처리하기 위해 몇 가지 T2I 제어 기술 및 적응 모델이 제안되었다. ControlNet, T2I-Adapter 등의 대표적인 연구들은 프롬프트에 추가로 사용자 정의된 구조적 조건 (즉, 캐니 에지, 깊이, 포즈 등)을 생성 guidance로 취하는 적응형 샴 네트워크 (siamese network)를 제안했다. 이러한 접근 방식은 다음과 같은 이유로 사용자들 사이에서 가장 인기 있는 것 중 하나가 되었다.
- 콘텐츠에서 구조를 분리하면 프롬프트보다 결과를 더 정확하게 제어할 수 있다.
- 이러한 plug-and-run 모듈은 대부분의 T2I 모델에 재사용할 수 있어 사용자를 추가 학습 단계에서 절약한다.
ControlNet 등과 같은 방법이 개인화된 T2I의 모든 문제를 해결하지는 못한다. 예를 들어, 여전히 다음과 같은 문제에 직면해 있다.
- 현재 접근 방식은 사용자 지정 텍스처, 객체, semantic을 생성하는 문제에 직면한다.
- 필요한 프롬프트 검색은 때때로 문제가 있고 불편하다.
- 품질 목적의 프롬프트 엔지니어링이 여전히 필요하다.
결론적으로 이러한 모든 문제는 시각과 언어 사이의 근본적인 지식 격차에서 비롯된다. 캡션만으로는 모든 시각적 신호를 포괄적으로 표현할 수 없으며 구조적 guidance를 제공한다고 해서 이 문제가 해결되지는 않는다.
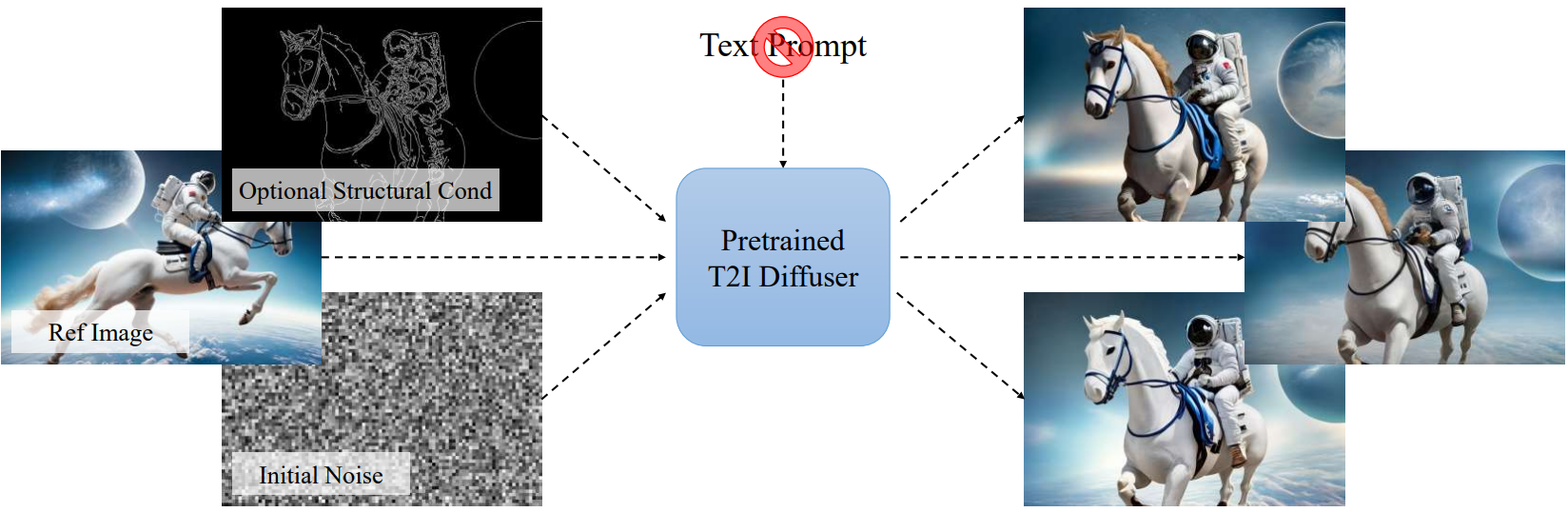
본 논문은 앞서 언급한 문제를 극복하기 위해 일반적인 프롬프트 입력을 레퍼런스 이미지로 대체하는 새로운 Prompt-Free Diffusion을 도입했다. 임의의 해상도를 가진 픽셀 기반 이미지를 의미 있는 시각적 임베딩으로 자동 변환할 수 있는 새로 제안된 Semantic Context Encoder (SeeCoder)를 활용한다. 이러한 임베딩은 텍스처, 효과 등과 같은 낮은 수준의 정보와 객체, semantic 등과 같은 높은 수준의 정보를 나타낼 수 있다. 그런 다음 이러한 시각적 임베딩을 임의의 T2I 모델의 조건부 입력으로 사용하여 현재 SOTA과 동등한 맞춤형 출력을 수행한다. Prompt-Free Diffusion은 예시 기반 이미지 생성 및 이미지 변형과 유사한 목표를 공유한다. 그러나 품질과 편의성 면에서 이전 접근 방식과 차별화된다. SeeCoder는 많은 노력 없이 T2I 파이프라인을 Prompt-Free 파이프라인으로 쉽게 변환할 수 있으며, 대부분의 오픈 소스 T2I 모델에 재사용할 수 있다. 이는 특정 도메인에 대한 특정 모델 또는 T2I 목적에서 벗어난 fine-tuning 모델이 필요한 이전 연구들에서는 대부분 실행 불가능하다.
Method
1. Prompt-Free Diffusion
본 논문은 이전 접근 방식의 모든 장점 (즉, 고품질, 학습이 필요하지 않음, 대부분의 오픈 소스 모델에 재사용 가능)을 적극적으로 유지하면서 오늘날 요구 사항이 높은 맞춤형 T2I를 처리할 수 있는 효과적인 솔루션을 제안하는 것을 목표로 한다.
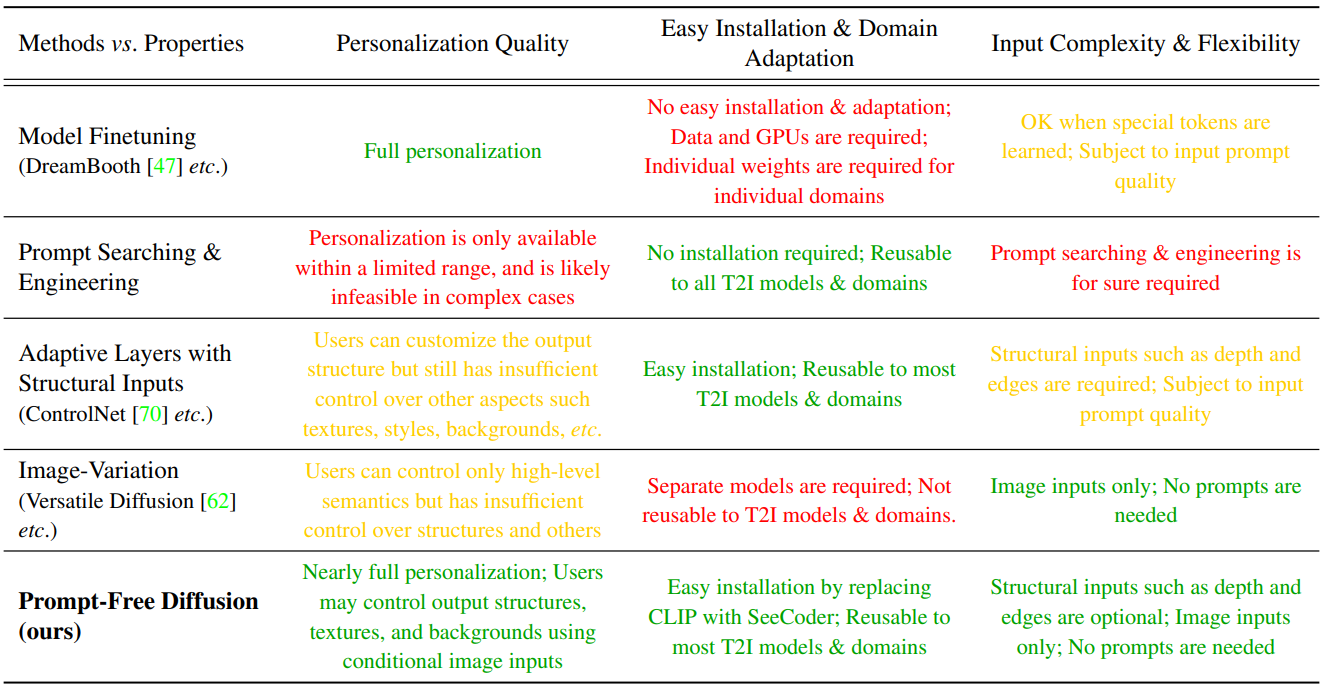
위 표는 개인화 품질, 손쉬운 설치, 도메인 적응, 입력 복잡성 및 유연성의 세 가지 각도에서 측정한 다양한 접근 방식의 장단점을 설명한다. Prompt-Free Diffusion의 디자인은 T2I 및 Image-Variation 모델을 계승하며 diffuser와 컨텍스트 인코더를 두 개의 핵심 모듈로 구성하고 diffusion의 차원을 줄이는 VAE 옵션을 제공한다.
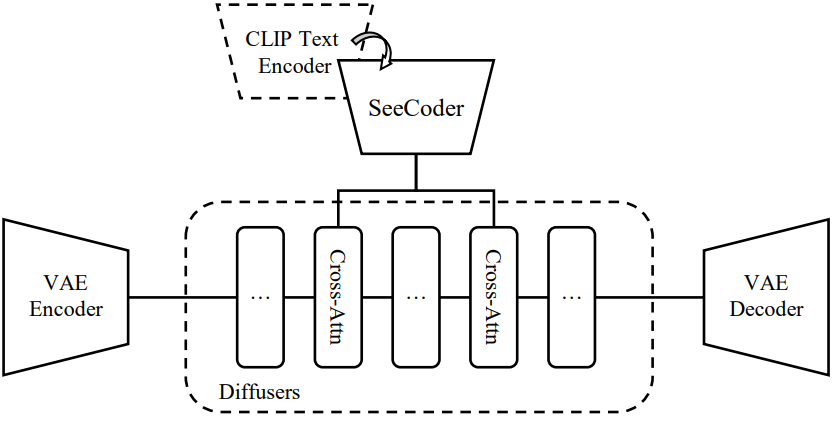
특히 본 논문에서는 위 그림과 같이 Stable Diffusion과 같은 정밀한 latent diffusion 구조를 유지했다.
텍스트 프롬프트는 먼저 토큰화된 다음 공통 T2I에서 CLIP을 사용하여 $N \times C$ 컨텍스트 임베딩으로 인코딩된다. $N$과 $C$는 임베딩의 개수와 차원을 나타낸다. 나중에 이러한 임베딩은 diffuser의 cross-attention layer에 입력으로 공급된다. Prompt-Free Diffusion에서는 CLIP 텍스트 인코더를 새로 제안된 SeeCoder로 교체한다. 텍스트 프롬프트 대신 SeeCoder는 이미지 입력만 받도록 설계되었다. 시각적 신호를 캡처하고 텍스처, 개체, 배경 등을 나타내는 호환 가능한 $N \times C$ 임베딩으로 변환한다. 그런 다음 diffuser에서 동일한 cross-attention layer로 진행한다. Prompt-Free Diffusion은 또한 SeeCoder가 unsupervised 방식으로 낮은 수준 및 높은 수준의 시각적 신호를 인코딩하는 적절한 방법을 결정할 수 있기 때문에 prior로 이미지 분리가 필요하지 않다.
2. Semantic Context Encoder
Prompt-Free Diffusion의 핵심 모듈인 Semantic Context Encoder (SeeCoder)는 이미지 입력만 받고 모든 시각적 신호를 임베딩으로 인코딩하는 것을 목표로 한다. CLIP이 이미지를 인코딩할 수도 있다. 그러나 실제로 CLIP의 ViT는 다음과 같은 한계점이 있다.
- 해상도 384$\times$384보다 높은 입력을 받을 수 없기 때문에 용량이 제한된다.
- 세부 텍스처, 개체 등을 캡처하지 않는다.
- 시각적 단서를 처리하는 간접적인 방법이 되도록 contrastive loss로 학습한다.
따라서 본 논문은 CLIP보다 비전 tak에 더 적합한 솔루션인 SeeCoder를 제안한다.
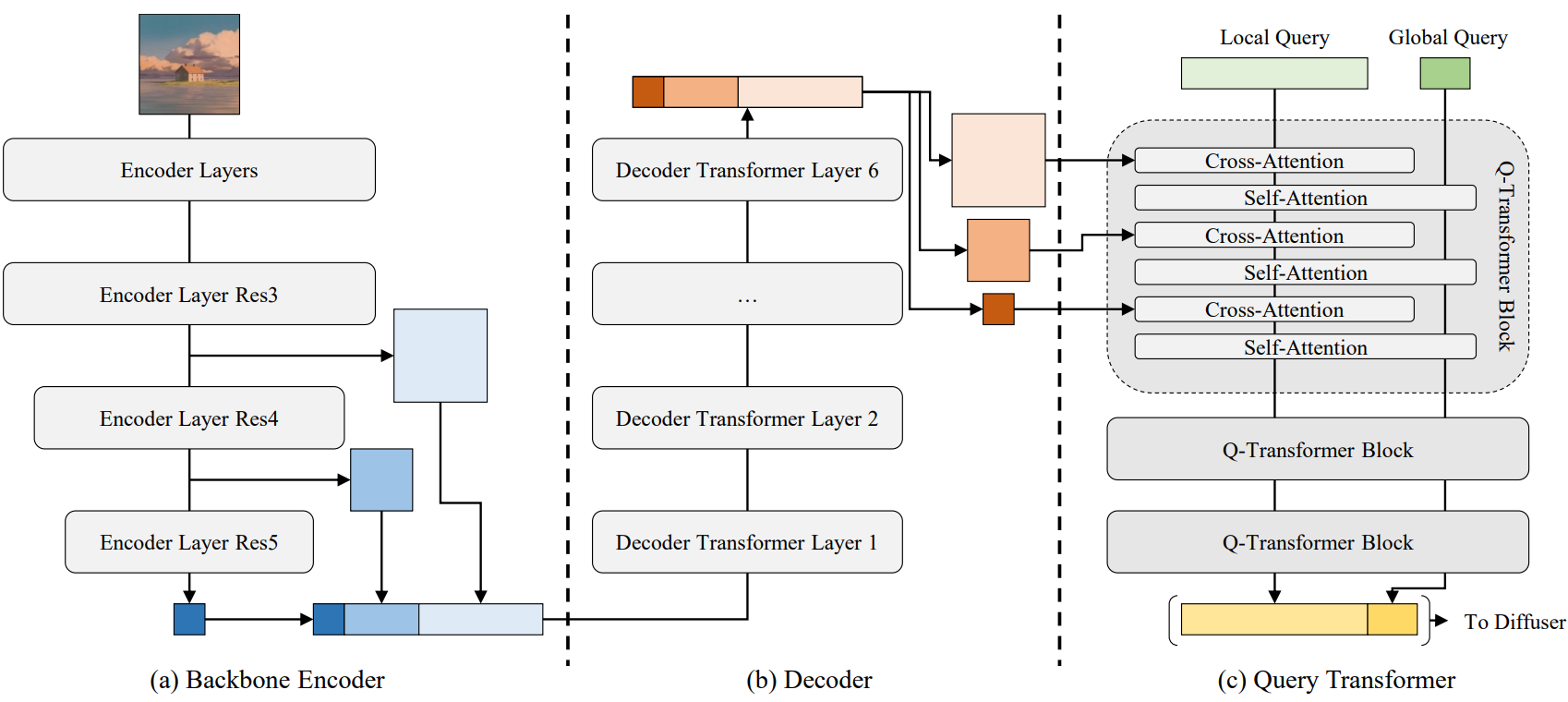
위 그림에서 볼 수 있듯이 SeeCoder는 Backbone Encoder, Decoder, Query Transformer의 세 가지 구성 요소로 분류할 수 있다.
Backbone Encoder는 임의 해상도 이미지를 다양한 스케일에서 시각적 신호를 더 잘 캡처하는 feature pyramid로 변환하기 때문에 SWIN-L을 사용한다.
Decoder의 경우 여러 convolution이 있는 transformer 기반 네트워크를 사용한다. 특히 Decoder는 다양한 레벨의 feature를 얻고, convolution을 사용하여 채널을 균등화하고, 모든 flatten된 feature들을 concat한다. 그런 다음 linear projection과 LayerNorms가 포함된 6개의 multi-head self-attention 모듈을 통과한다. 최종 출력은 분할되고 다시 2D로 모양이 된 다음 옆으로 연결된 입력 feature와 합산된다.
SeeCoder의 마지막 부분은 다단계 시각적 feature를 단일 1D 시각적 임베딩으로 마무리하는 Query Transformer이다. 네트워크는 4개의 자유 학습 글로벌 쿼리와 144개의 로컬 쿼리로 시작된다. Cross-attention layer와 self-attention layer가 차례로 혼합되어 있다. Cross-attention은 로컬 쿼리를 $Q$로, 시각적 feature를 $K$와 $V$로 취한다. self-attention은 글로벌 쿼리와 로컬 쿼리의 concatenation을 $Q$, $K$, $V$로 사용한다.
이러한 디자인은 cross-attention이 시각적 단서를 로컬 쿼리로 전환하고 self-attention이 로컬 쿼리를 글로벌 쿼리로 증류하는 계층적 지식 전달을 촉진한다. 게다가 네트워크에는 자유 학습 쿼리 임베딩, 레벨 임베딩, 선택적 2D 공간 임베딩도 포함된다. 선택적 공간 임베딩은 사인-코사인 인코딩과 여러 MLP layer이다. 2D 공간 임베딩이 있을 때 네트워크 이름을 SeeCoder-PA라 부른며, 여기서 PA는 Position-Aware의 약자이다. 마지막으로 글로벌 쿼리와 로컬 쿼리가 concat되어 콘텐츠 생성을 위해 diffuser로 전달된다.
Training
SeeCoder와 Prompt-Free Diffusion은 놀랍도록 간단하다. VLB loss로 일반적인 학습을 수행하며 SeeCoder의 Decoder와 Query Transformer에 대해서만 기울기가 필요하다. 다른 모든 가중치 (ex. VAE, Diffuser, SeeCoder의 Backbone Encoder)는 그대로 유지된다.
Experiments
- 데이터셋: Laion2B-en, COYO-700M
- 학습
- SeeCoder의 Backbone Encoder: SWIN-L
- VAE: Stable Diffusion 2.0의 VAE
- 자체 T2I diffuser 사용 (Stable Diffusion 1.5의 성능보다 우수)
- DDPM: $T = 1000$, $\beta_0 = 8.5 \times 10^{-5}$, $\beta_T = 1.2 \times 10^{-2}$ (linear schedule)
- learning rate: 5만 iteration동안 $10^{-4}$, 5만 iteration동안 $10^{-5}$
- batch size: 512 (GPU당 8)
- 16개의 A100 GPU 사용, gradient accumulation = 4
- SeeCoder-PA
- 50k SeeCoder 체크포인트에서 시작
- 추가 2만 iteration동안 learning rate $5 \times 10^{-5}$로 fine-tuning
1. Performance
다음은 Prompt-Free Diffusion의 결과이다.

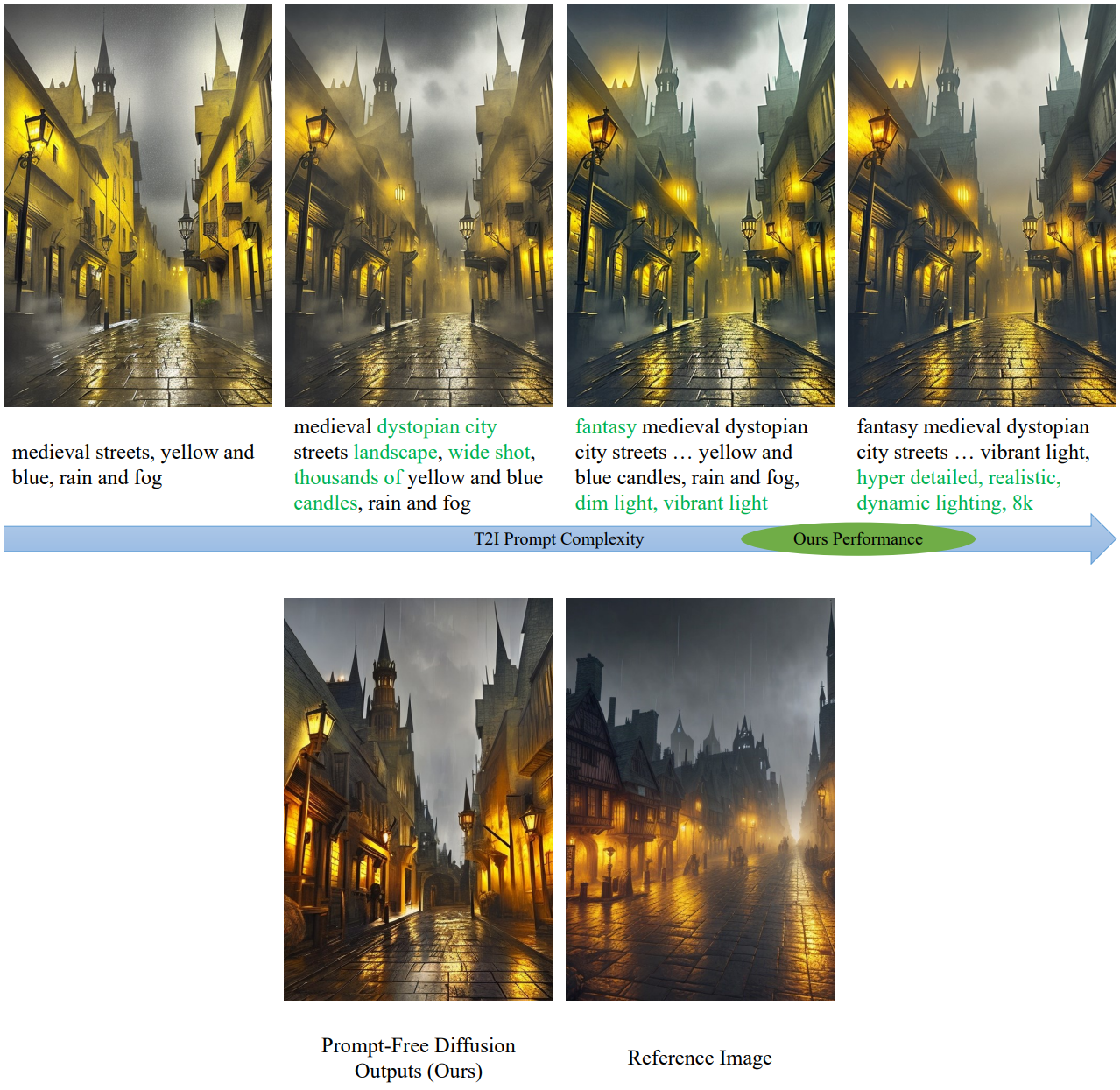
다음은 점차 복잡해지는 프롬프트를 사용하여 ControlNet+T2I의 성능을 비교한 것이다.
다음은 Image-Variation 결과를 VD, ControlNet과 비교한 것이다.

다음은 Dual-ControlNet과 Prompt-Free Diffusion의 성능을 비교한 것이다.

2. Reusability
다음은 7가지 오픈 소스 및 자체 모델에 대한 SeeCoder의 적응력을 검사한 것이다.
- (a) Stable Diffusion 1.5
- (b) OAM-V2
- (c) AnythingV4
- (d) 자체 모델
- (e) OpenJourney-V4
- (f) Deliberate-V2
- (g) RealisticVision-V2

3. Downstream Applications
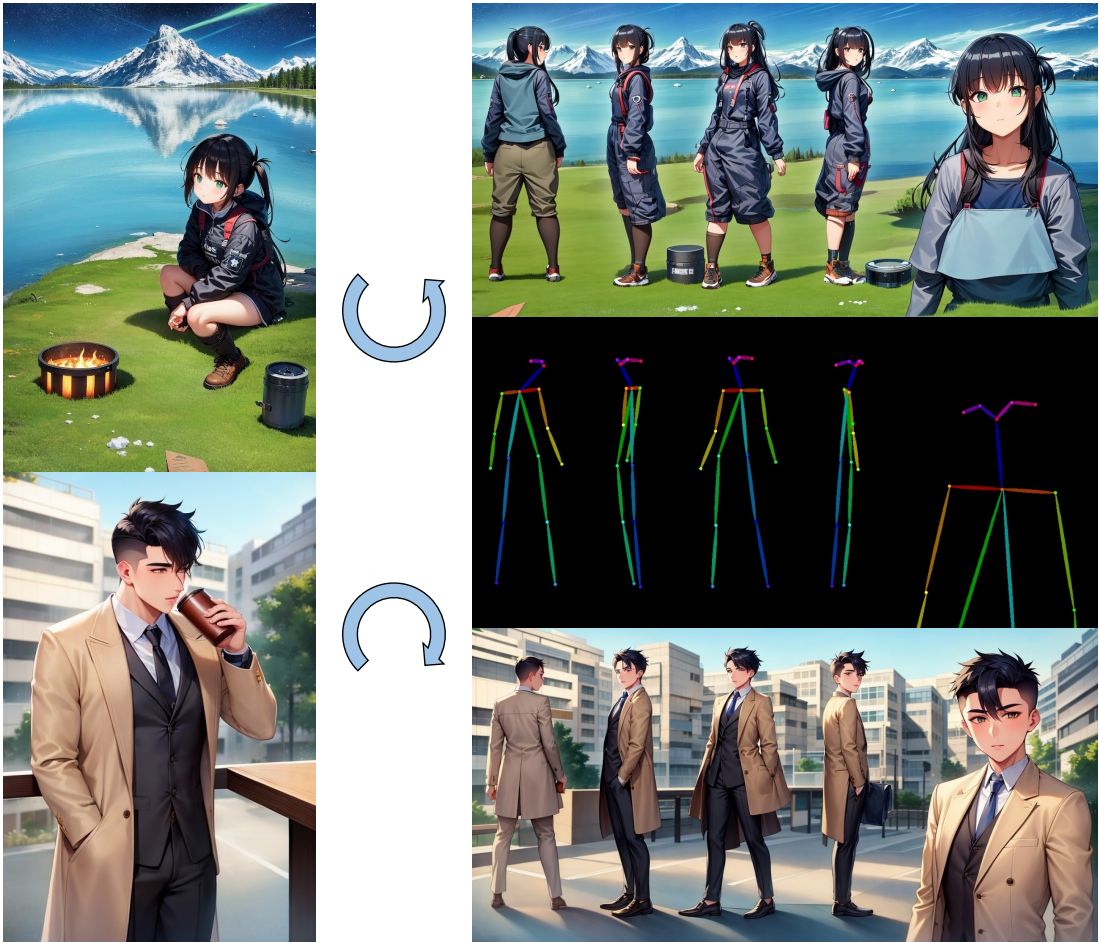
다음은 레퍼런스 이미지와 컨디셔닝 포즈와 함께 Prompt-Free Diffusion을 사용하여 애니메이션 그림을 생성한 데모이다.
다음은 Prompt-Free Diffusion과 SOTA 예시 기반 접근 방식을 사용한 가상 시착 데모이다.
