[논문리뷰] Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation
CVPR 2025. [Paper] [Page] [Github]
Haotong Lin, Sida Peng, Jingxiao Chen, Songyou Peng, Jiaming Sun, Minghuan Liu, Hujun Bao, Jiashi Feng, Xiaowei Zhou, Bingyi Kang
Zhejiang University | ByteDance Seed | Shanghai Jiao Tong University | ETH Zurich
18 Dec 2024
Introduction
최근 monocular depth estimation은 모델이나 데이터의 스케일링을 통해 상당한 도약을 이루었으며, 이는 depth foundation model의 발전으로 이어졌다. 이러한 모델은 고품질의 relative depth를 생성하는 데 강력한 능력을 보여주지만, 스케일 모호성으로 인해 실제 적용에 어려움을 겪는다. 따라서, metric 데이터셋을 기반으로 depth foundation model을 fine-tuning하거나 이미지 intrinsic을 추가 입력으로 사용하여 모델을 학습시키는 등 metric depth 추정을 위한 많은 노력이 있어 왔다. 그러나 두 방법 모두 문제를 제대로 해결할 수 없다.
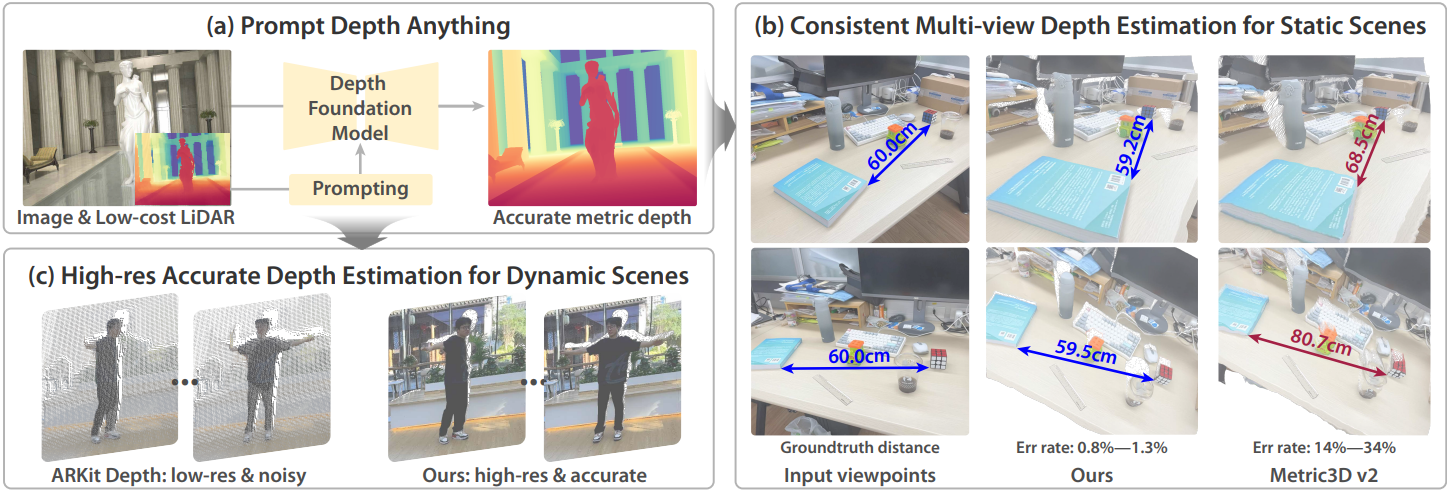
본 논문은 metric depth 추정을 다운스트림 task로 취급하여 metric 정보로 depth foundation model을 프롬프팅하는 새로운 패러다임을 제안하였다. 이 프롬프트는 스케일 정보가 제공되는 한 어떤 형태로든 구현될 수 있지만, 본 논문에서는 두 가지 이유로 저비용 LiDAR를 프롬프트로 선택하여 패러다임의 타당성을 검증하였다.
- 정확한 스케일 정보를 제공
- 일반적인 모바일 기기에서도 널리 사용 (ex. iPhone)
구체적으로, 본 논문은 Depth Anything V2 기반 4K 해상도의 정확한 metric depth 추정을 달성하는 Prompt Depth Anything을 제안하였다. 방법의 핵심은 DPT 기반 depth foundation model에 맞춰 디자인된 간결한 프롬프트 융합 아키텍처이다. 프롬프트 융합 아키텍처는 DPT 디코더 내에서 다양한 스케일의 LiDAR 깊이 정보를 통합하여 깊이 디코딩을 위한 LiDAR feature들을 융합한다. Metric 프롬프트는 정확한 공간적 거리 정보를 제공하여, depth foundation model이 정확하고 고해상도의 metric depth를 추정하도록 한다.
Prompt Depth Anything의 학습은 LiDAR depth와 정밀한 GT depth를 모두 필요로 한다. 그러나 기존 합성 데이터는 LiDAR depth가 부족하고, LiDAR를 사용한 실제 데이터는 좋지 못한 edge로 구성된 부정확한 GT depth만 가지고 있다. 저자들은 이 문제를 해결하기 위해, 합성 데이터에는 LiDAR를 시뮬레이션하고, 실제 데이터에는 3D reconstruction 방법을 사용하여 고품질 edge를 가진 pseudo GT depth를 생성하는 데이터 파이프라인을 제안하였다. 3D reconstruction에서 발생하는 pseudo GT depth의 오차를 줄이기 위해, edge에서 커지는 pseudo GT depth의 gradient만을 활용하는 edge-aware depth loss를 도입하였다.
Prompt Depth Anything은 모든 데이터셋과 metric에서 지속적으로 SOTA 성능을 보여준다. 심지어 zero-shot 모델조차도 다른 방법들의 non-zero-shot 모델보다 더 나은 성능을 보이며, 이는 depth foundation model을 프롬프팅하는 일반화 능력을 보여준다. 또한, Prompt Depth Anything의 foundation model과 프롬프팅은 각각 DepthPro와 차량 LiDAR로 대체할 수 있으며, 3D reconstruction과 로봇 물체 파악을 포함한 여러 후속 응용 분야에 도움이 된다.
Method
1. Prompt Depth Anything
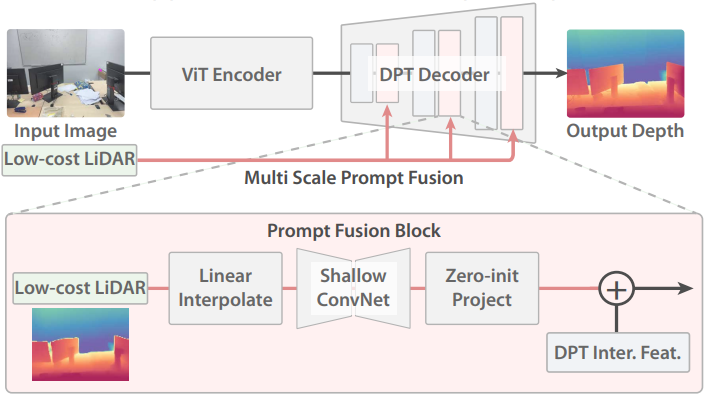
본 논문은 저비용 LiDAR의 저해상도 및 노이즈가 있는 depth map을 프롬프트로 DPT 기반 depth foundation model에 통합하기 위해 간결한 프롬프트 융합 아키텍처를 제안하였다. 프롬프트 융합 아키텍처는 DPT 디코더 내에서 여러 스케일의 저해상도 깊이 정보를 통합한다.
구체적으로, DPT 디코더의 각 스케일 $S_i$에 대해 저해상도 depth map \(\textbf{L} \in \mathbb{R}^{1 \times H_L \times W_L}\)을 먼저 bilinear interpolation하여 현재 scale의 차원 $\mathbb{R}^{1 \times H_i \times W_i}$과 일치시킨다. 그런 다음 resize된 depth map을 얕은 ConvNet에 전달하여 depth feature를 추출한다. 추출된 feature는 0으로 초기화된 convolutional layer를 사용하여 이미지 feature의 차원인 $F_i \in \mathbb{R}^{C_i \times H_i \times W_i}$로 projection된다. 마지막으로, depth feature들을 DPT 중간 feature들에 더해져 깊이 디코딩을 수행한다.
제안된 디자인은 다음과 같은 장점을 가지고 있다.
- 기존 depth foundation model에 비해 5.7%의 추가적인 연산 오버헤드만 발생시키고, depth foundation model에 내재된 모호성 문제를 효과적으로 해결한다.
- 인코더와 디코더가 foundation model로부터 초기화되고, 제안된 융합 아키텍처가 0으로 초기화되어 초기 출력이 foundation model의 출력과 동일하기 때문에 depth foundation model의 능력을 완전히 상속한다.
선택적 디자인
저자들은 depth foundation model에 다양한 프롬프트 컨디셔닝 디자인을 적용하는 방안을 모색하였다.
- Adaptive LayerNorm: 컨디셔닝 입력에 따라 인코더 블록의 layer normalization 파라미터를 조정
- CrossAttention: 각 self-attention block 뒤에 cross-attention block을 삽입하고 cross-attention 메커니즘을 통해 컨디셔닝 입력을 통합
- ControlNet: 인코더 블록을 복사하고 복사된 블록에 제어 신호를 입력하여 출력 깊이를 제어
실험 결과, 이러한 디자인들은 제안된 융합 블록만큼 성능이 좋지 않았다. 그럴듯한 이유는 이러한 디자인이 모달리티 간 정보를 통합하도록 설계되었기 때문이며, 이는 입력 저해상도 LiDAR와 출력 깊이 간의 픽셀 정렬 특성을 효과적으로 활용하지 못하기 때문이다.
2. Training Prompt Depth Anything
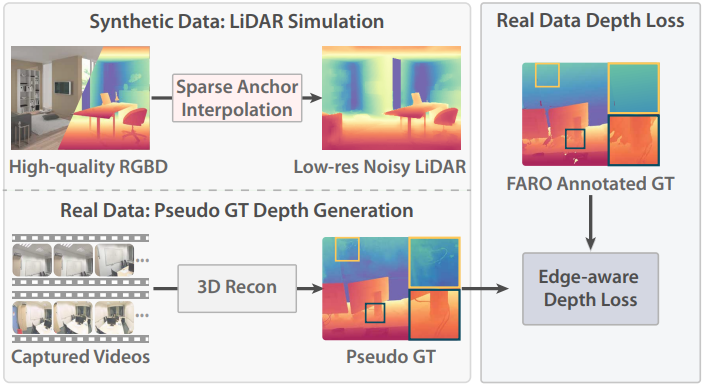
Prompt Depth Anything의 학습에는 저비용 LiDAR와 정밀한 GT depth를 동시에 필요로 한다. 그러나 합성 데이터에는 LiDAR depth가 포함되지 않으며, 노이즈가 있는 LiDAR depth를 가진 실제 데이터는 부정확한 깊이 주석만 포함한다. 따라서 합성 데이터는 LiDAR 시뮬레이션을 사용하고, 실제 데이터는 edge-aware depth loss를 적용하여 ZipNeRF로부터 pseudo GT depth를 생성한다.

합성 데이터: LiDAR 시뮬레이션
LiDAR depth map은 해상도가 낮고 노이즈가 많다. 이를 시뮬레이션하는 단순한 방법은 합성 데이터의 depth map을 직접 다운샘플링하는 것이다. 그러나 이 방법은 위 그림과 같이 모델이 depth super-resolution을 학습하게 되므로, 모델이 LiDAR 노이즈를 보정하지 못한다.
저자들은 노이즈를 시뮬레이션하기 위해 sparse anchor interpolation을 도입하였다. 구체적으로, 먼저 GT depth map을 저해상도(192$\times$256, iPhone ARKit Depth의 해상도)로 다운샘플링한다. 그런 다음, stride가 7인 왜곡된 그리드를 사용하여 이 depth map의 점들을 샘플링한다. 나머지 깊이 값은 KNN을 이용한 RGB 유사도를 사용하여 이 점들로부터 interpolation된다. 이 방법은 LiDAR 노이즈를 효과적으로 시뮬레이션하고 더 나은 깊이 예측을 가능하게 한다.
실제 데이터: Pseudo GT depth 생성
저자들은 실제 데이터도 학습 데이터에 추가하였다. ScanNet++의 주석이 달린 깊이 정보는 고출력 LiDAR 센서로 스캔한 메쉬를 기반으로 다시 렌더링된다. 장면에 많은 occlusion이 존재하기 때문에, 여러 스캔 위치로 인해 스캔된 메시가 불완전하게 생성되어, 수많은 구멍과 낮은 edge 품질을 가진 depth map이 생성되었다.
저자들은 Zip-NeRF를 사용하여 고품질 depth map을 복원하는 방법을 제안하였다. 구체적으로, ScanNet++에서 각 장면에 대해 Zip-NeRF를 학습시키고 pseudo GT depth 정보를 다시 렌더링한다. Zip-NeRF에 고품질의 dense한 관측값을 제공하기 위해, Scannet++ iPhone 동영상에서 흐릿하지 않은 프레임을 검출하고, DSLR 동영상을 활용하여 고품질의 dense-view 이미지를 제공하였다.
실제 데이터: Edge-aware depth loss
Zip-NeRF는 고품질 edge 깊이를 생성할 수 있지만, 텍스처가 없고 반사되는 영역을 재구성하는 것은 여전히 어렵다. 반면, 이러한 영역은 일반적으로 평면이고 occlusion이 거의 없으며, 메쉬에서 얻은 깊이는 이러한 영역에서 양호하다. 따라서 두 가지의 장점을 모두 활용하고자 edge-aware depth loss를 사용한다. 구체적으로, 메쉬에서 얻은 깊이와 pseudo GT depth의 gradient를 사용하여 각각 출력 깊이와 출력 깊이의 gradient를 학습시킨다.
\[\begin{aligned} \mathcal{L}_\textrm{edge} &= L_1 (\textbf{D}_\textrm{gt}, \hat{\textbf{D}}) + \lambda \cdot \mathcal{L}_\textrm{grad} (\textbf{D}_\textrm{pseudo}, \hat{\textbf{D}}) \\ \mathcal{L}_\textrm{grad} (\textbf{D}_\textrm{pseudo}, \hat{\textbf{D}}) &= \left( \left\vert \frac{\partial (\hat{\textbf{D}} - \textbf{D}_\textrm{pseudo})}{\partial x} \right\vert + \left\vert \frac{\partial (\hat{\textbf{D}} - \textbf{D}_\textrm{pseudo})}{\partial y} \right\vert \right) \end{aligned}\]($\lambda = 0.5$)
Depth gradient는 주로 edge에서 두드러지는데, 이는 pseudo GT depth가 탁월한 이유이다. Gradient loss는 모델이 pseudo GT depth로부터 정확한 edge를 학습하도록 유도하는 반면, L1 loss는 모델이 전체 깊이를 학습하도록 유도하여 궁극적으로 탁월한 깊이 예측을 가능하게 한다.
Experiments
- 구현 디테일
- Backbone: ViT-large
- ConvNet: convolutional layer 2개 (kernel size 3, stride 1)
- batch size: 2
- optimizer: AdamW
- learning rate: ViT backbone은 $5 \times 10^{-6}$, 다른 파라미터는 $5 \times 10^{-5}$
- GPU: NVIDIA A100 8개
1. Comparisons with the State of the Art
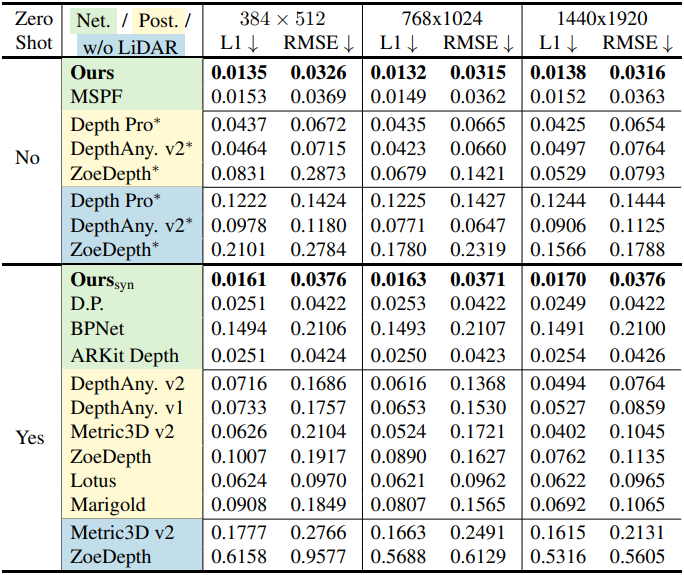
다음은 ARKitScenes 데이터셋에서의 정량적 비교 결과이다. (Net은 네트워크 융합, Post는 RANSAC을 사용한 후처리, w/o LiDAR는 출력이 metric depth)
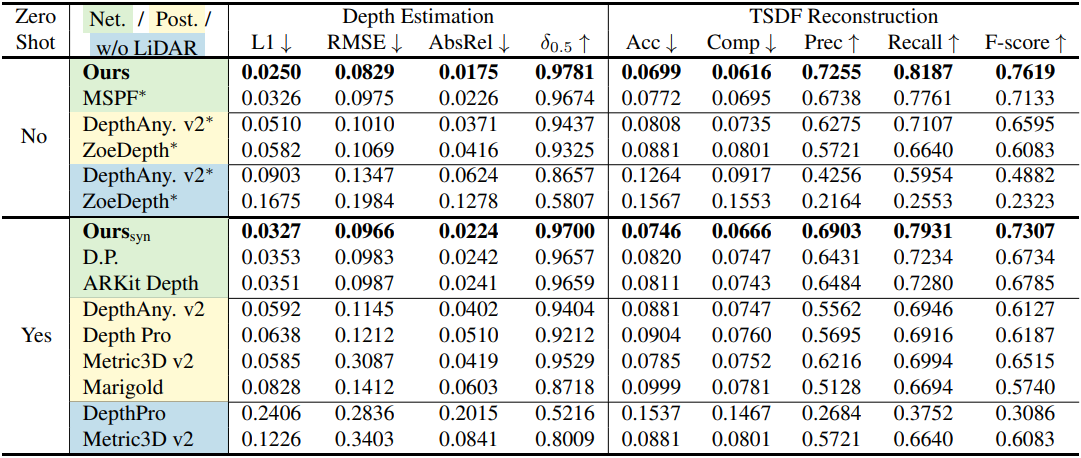
다음은 ScanNet++ 데이터셋에서의 정량적 비교 결과이다.
다음은 SOTA와의 정성적 비교 결과이다.

다음은 TSDF reconstruction을 비교한 결과이다.

2. Ablations and Analysis
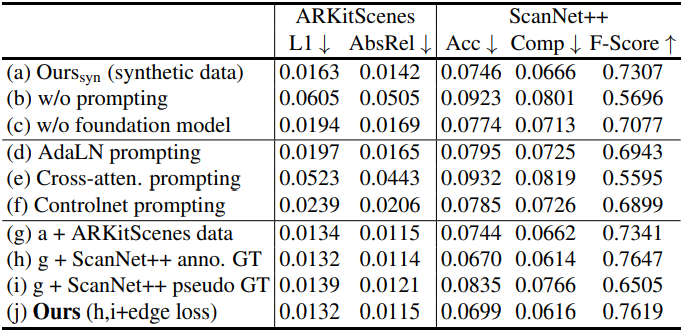
다음은 ablation 결과이다.
3. Zero-shot Testing on Diverse Scenes
다음은 다양한 장면에서의 zero-shot 결과들이다.

4. Application
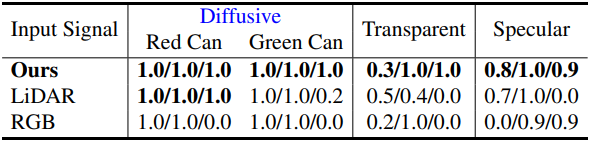
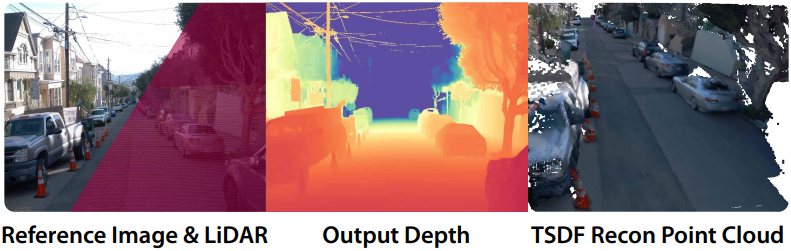
다음은 차량 LiDAR를 metric 프롬프트로 사용하였을 때의 reconstruction 결과이다.
다음은 사용한 깊이에 따른 로봇 grasping 성공률을 비교한 결과이다.