[논문리뷰] Progressive Radiance Distillation for Inverse Rendering with Gaussian Splatting
arXiv 2024. [Paper]
Keyang Ye, Qiming Hou, Kun Zhou
Zhejiang University
14 Aug 2024

Introduction
Inverse rendering은 관찰된 이미지를 조명 조건, 재료 속성, 형상과 같은 물리 기반 성분으로 분해하기 위해 렌더링 방정식을 푼다. 그러나 회귀 문제로 해석할 경우 렌더링 방정식은 상당한 수학적 모호성을 가진다. 빛과 재료는 항상 동일한 적분에 나타나고 무한히 많은 조합이 동일한 픽셀 색상을 생성할 수 있으므로 분해하기 어려울 수 있다. 이러한 모호성으로 인해 빛-재료 가정의 근사 오차에 모델 파라미터가 영향을 받아 새 이미지를 합성할 때 눈에 띄는 아티팩트가 발생할 수 있다.
이러한 모호성 문제는 공간적 위치와 뷰 방향에 대해 학습된 함수인 radiance field를 통해 빛-재료 분해를 삭제함으로써 피할 수 있다. Radiance field는 학습시키기에 훨씬 더 robust하여 고충실도의 새로운 뷰 합성이 가능하다. 그러나 빛과 재료가 얽힌 상태로 남아 있고 이미지 합성 중에 독립적으로 변경될 수 없다.
Radiance field를 inverse rendering에 적용하려는 많은 시도가 있었다. 그 중 여러 접근 방식은 간접 조명의 근사로서 원래의 해석되지 않은 radiance를 유지하고 전체 모델을 처음부터 학습시킨다. 이러한 radiance 항은 물리 기반 렌더링 모델의 한계로 인해 발생하는 문제를 완화한다. 그러나 해석되지 않은 radiance는 또 다른 모호성을 추가한다.
본 논문은 radiance field와 물리 기반 모델을 보완적인 것이 아니라 상호 교환 가능한 것으로 취급하여 모호성 문제를 해결하였다. 구체적으로, 모든 성분을 한 번에 분해하지 않고 distillation을 통해 다양한 성분 사이의 모호성을 효과적으로 분리하여 더 정확하게 분해한다.
본 논문은 3D Gaussian Splatting (3DGS)을 사용한 inverse rendering 방법인 progressive radiance distillation를 제안하였다. 사전 학습된 Gaussian 기반 radiance field로 초기화하고 radiance field에서 물리 기반 조명 및 재료 파라미터를 distillation한다. 구체적으로, 각 학습 이미지에 대해 한 이미지를 radiance field를 사용하여 렌더링하고 다른 이미지는 물리 기반 파라미터를 사용하여 렌더링한다. 학습된 distillation progress map으로 두 렌더링 이미지를 linear interpolation하여 최종 이미지를 얻고 loss fucntion을 계산하며, 이는 radiance 분포를 최적화하여 사전 학습된 radiance field보다 더 좋거나 같은 이미지 품질을 보장한다.
Distillation progress map은 작은 값으로 초기화되어 radiance field를 선호하고 미미한 양의 물리 기반 렌더링만 도입한다. 물리 기반 파라미터가 수렴에서 여전히 멀리 떨어져 있는 초기 iteration 중에 radiance field는 이미지 loss 기울기의 건전성을 보장하고 underfitting을 유발하는 local minima를 방지한다. 조명 및 재료 파라미터가 비슷한 수준의 정확도로 수렴함에 따라 물리 기반 모델이 점차 이를 받아들이고 distillation 진행률이 그에 따라 증가한다.
물리 기반 모델에 의해 모델링되지 않은 빛 경로가 있는 경우 영향을 받는 픽셀에서 distillation 진행률이 100%에 도달하지 못하고 학습된 radiance field는 최종 렌더링에 그대로 유지된다. 이러한 설계를 통해 모델링되지 않은 색상 성분이 조명 및 재료 파라미터로 누출되는 것을 방지하여 모호성 문제를 완화하고 더 나은 relighting이 가능해진다. 한편, 나머지 radiance field는 물리 기반 모델의 한계점을 보상하여 고품질의 새로운 뷰 합성을 보장한다.
모호성을 더욱 줄이기 위해, 보다 일반적인 공동 최적화와는 반대로 specular 파라미터와 diffuse 파라미터를 별도로 fitting한다. 이를 통해 각 최적화 단계에서는 fitting할 성분이 가장 두드러지는 픽셀에 집중할 수 있다. Specular 성분이 학습된 radiance를 더 빨리 능가하여 distillation하기가 더 쉽기 때문에 specular 성분을 먼저 fitting한다.
Method
1. Rendering Model
Gaussian 파라미터를 geometry 파라미터와 shading 파라미터로 분류된다. Geometry 파라미터는 각 Gaussian의 위치, 회전, 크기, 불투명도로 구성되며, 결합하면 Gaussian에서 픽셀로의 매핑을 완전히 정의한다. 이 매핑 함수를 사용하여 shading 파라미터를 화면 공간에 splatting하고 블렌딩한다. 그런 다음 deferred shading을 사용하여 splatting된 화면 공간에서 최종 픽셀 색상을 계산한다.
전체 렌더링 모델은 다음과 같다.
\[\begin{equation} I (x, \omega_o) = \alpha_x I_\textrm{phy} (x, \omega_o) + (1 - \alpha_x) I_\textrm{raw} (x, \omega_o) \end{equation}\]여기서 $I (x, \omega_o)$는 공간적 위치 $x$와 뷰 방향 $\omega_o$에 대한 최종 radiance이다. \(I_\textrm{phy}\)는 물리 기반 항이고 \(I_\textrm{raw}\)는 distillation 중에 fine-tuning하는 radiance field 항이다. $\alpha_x$는 distillation 진행 값이다.
\(I_\textrm{raw}\)는 원래 3DGS를 따라 4-order Spherical Harmonics (SH) 함수를 사용한다.
\[\begin{equation} I_\textrm{raw} (x, \omega_o) = \sum_{l = 0}^3 \sum_{m = -l}^l y_{l,x}^m Y_l^m (\omega_o) \end{equation}\]\(I_\textrm{phy}\)는 Cook-Torrance microfacet model을 기반으로 한다.
\[\begin{aligned} I_\textrm{phy} (x, \omega_o) &= (1 - m_x) I_\textrm{diff} (x) + I_\textrm{spec} (x, \omega_o) \\ I_\textrm{diff} (x) &= \frac{c_x}{\pi} \int_\Omega V (x, \omega_i) L (\omega_i) (n_x \cdot \omega_i) d \omega_i \\ I_\textrm{spec} (x, \omega_o) &= \int_\Omega \rho (\omega_i, \omega_o; c_x, r_x, m_x) L (\omega_i) (n_x \cdot \omega_i) d \omega_i \end{aligned}\]- $c_x$, $r_x$, $m_x$: diffuse albedo map, roughness map, metallic map
- $n_x$: surface normal (카메라를 향하는 shortest axis)
- $L(\omega_i)$: 학습된 incident radiance
- $V (x, \omega_i)$: 베이킹된 visibility
- $\rho$: microfacet BRDF
$c_x$, $r_x$, $m_x$는 모두 shading 파라미터로 구현된다. $L(\omega_i)$는 environment map으로 구현된다. \(I_\textrm{diff}\) 적분은 SH triple product로 근사화되며, 이 때 $L(\omega_i)$는 SH로 projection된다. $V$는 regular grid ($120^3$)에서 미리 계산되며, 각 셀은 splatting된 불투명도 cubemap을 projection하여 SH 계수들을 계산한다. $V$는 초기화 시에 한 번만 계산되고 학습 중에 고정된다. Geometry 파라미터를 fine-tuning하는 동안 shading에 집중하고 학습하는 동안 visibility 변화는 최소화된다. Visibility 근사값은 저주파이므로 specular 항에서 제외한다. Specular 성분은 사전 필터링된 환경 조명을 사용하여 split-sum 프로세스로 계산된다. (자세한 수식은 논문의 Appendix 참조)
2. Training
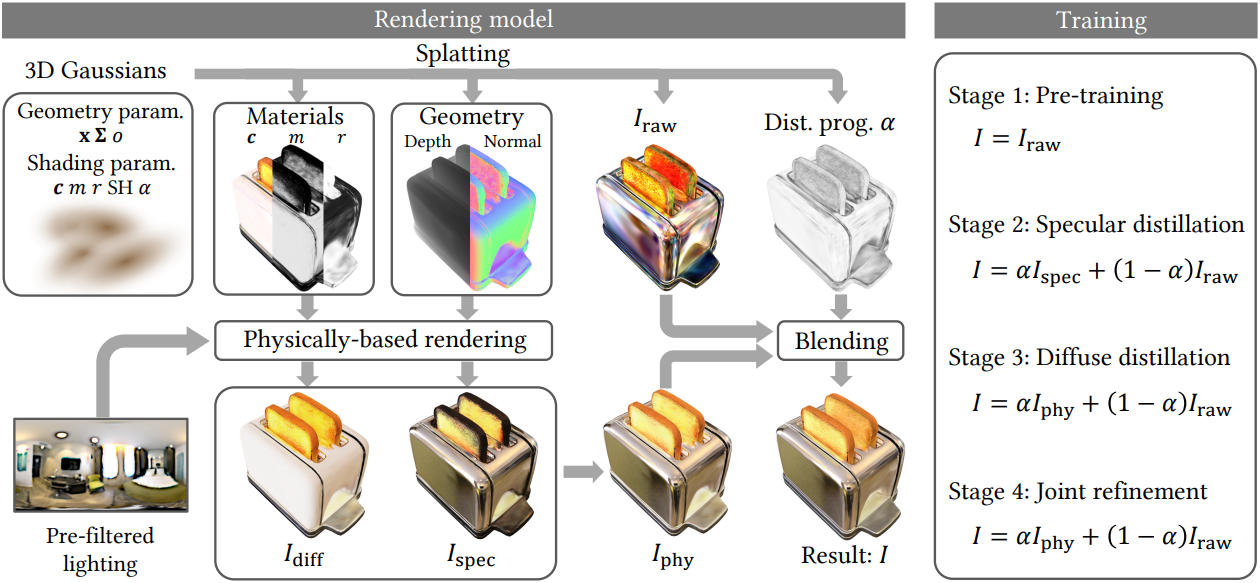
학습은 네 단계로 나뉜다. 각 단계는 고정된 수의 epoch 동안 독립적으로 loss를 최소화한다. 모든 학습된 파라미터는 모든 단계에서 공유되지만 각 단계는 일부 파라미터를 고정할 수 있다. 모든 단계는 원래 3DGS와 동일한 이미지 loss 항 \(\mathcal{L}_\textrm{rgb}\)를 최종 radiance \(I(x, \omega_o)\)에 대해 정의하여 사용한다.

Stage 1: Pre-training
이 단계에서는 $\alpha_x = 0$으로 고정하고 \(I_\textrm{raw}\)만 학습시킨다. 이 단계는 3DGS와 동일하다.
\[\begin{equation} I (x, \omega_o) = I_\textrm{raw} (x, \omega_o) \end{equation}\]이 단계가 끝나면 Gaussian의 geometry와 raw radiance가 수렴한다. 이후 단계에서는 geometry 파라미터를 계속 fine-tuning한다.
Stage 2: Specular distillation
\(I_\textrm{raw}\)가 학습되면 $\alpha_x$를 0.01로 초기화하고 $m_x = 1$로 고정하여 specular 효과를 피팅하기 시작한다. Specular 항을 먼저 distillation하는 이유는 모호성이 적고 더 빨리 처리되기 때문이다.
\[\begin{equation} I (x, \omega_o) = \alpha_x I_\textrm{spec} (x, \omega_o) + (1 - \alpha_x) I_\textrm{raw} (x, \omega_o) \end{equation}\]Normal 재구성을 위해 3DGS-DR의 normal propagation과 color sabotage를 사용한다. 정반사는 SH 기반 \(I_\textrm{raw}\)보다 고주파의 뷰에 따른 효과를 더 잘 근사하기 때문에 alpha map은 image-fitting loss만 있는 roughness가 낮은 영역에서 자연스럽게 증가한다. 이 단계가 끝나면 반사 물체의 normal 및 roughness와 정반사에서 볼 수 있는 environment map의 일부가 수렴한다.
이 단계의 학습이 끝나면 난반사는 \(I_\textrm{raw}\)에 남아 있고 diffuse-only 픽셀의 distillation 진행률은 0에 가깝다. 모델은 이미 새로운 뷰 합성 능력이 개선되었지만, relighting을 위해 재료 파라미터를 추가로 분해하려면 여전히 diffuse 항을 distillation해야 한다.
다음 단계를 시작하기 전에 현재 geometry 파라미터를 사용하여 visibility 항 $V(x, \omega_i)$를 베이킹한다.
Stage 3: Diffuse distillation
이 단계에서는 $m_x$를 고정 해제한다. 그러나 specular 단계와 달리 이미지 loss만으로는 난반사와 유사하게 낮은 주파수의 SH radiance를 구별하기에 충분하지 않다. 따라서 추가 loss 항 \(\mathcal{L}_\alpha\)를 도입한다.
\[\begin{equation} \mathcal{L}_\alpha = \textrm{MSE} (I_\textrm{mask}, \alpha_x) \end{equation}\]여기서 \(I_\textrm{mask}\)는 물체 마스크이다. \(I_\textrm{mask}\)는 모든 물체로 덮인 픽셀에서 1이고 그렇지 않은 경우 0이다. 소프트한 제약 조건으로 $\alpha$를 1로 끌어올리면 설명 가능한 raw radiance 부분이 난반사로 정제되고 정반사는 변경된 $m_x$에 따라 조정된다. 이 단계가 끝나면 raw radiance가 자연스럽게 상호 반사와 같은 모델링되지 않은 성분을 나타낸다.
추가로, nvdiffrec을 따라 \(\mathcal{L}_\textrm{light}\)를 추가하여 environment map을 가능한 한 흰색에 가깝게 만든다.
\[\begin{equation} \mathcal{L}_\textrm{light} = \sum_{i=1}^3 \vert l_i - \frac{1}{3} \sum_{j=1}^3 l_j \vert \end{equation}\]여기서 $l_i$와 $l_j$는 빛의 개별 RGB 성분을 나타낸다. 최종 loss function은 다음과 같다.
\[\begin{equation} \mathcal{L} = \lambda_1 \mathcal{L}_\textrm{rgb} + \lambda_2 \mathcal{L}_\alpha + \lambda_3 \mathcal{L}_\textrm{light} \end{equation}\](\(\lambda_1 = 1.0\), \(\lambda_2 = 0.08\), \(\lambda_3 = 0.003\))
Stage 4: Joint refinement
이 마지막 단계에서는 $\alpha$의 learning rate를 약간 줄이고 다른 모든 파라미터를 fine-tuning한다. 실제 장면의 경우 $L$을 고정하고 \(\mathcal{L}_\alpha\)에서 \(I_\textrm{mask}\) 항을 삭제한다.
\[\begin{equation} \mathcal{L}_\textrm{alpha} = \textrm{MSE} (1, \alpha_x) \end{equation}\]위 식으로 전환하면 배경 픽셀을 포함한 전체 이미지가 추출된다.
이러한 변경은 조명 변화가 있을 때 배경 픽셀이 전경 픽셀과 일관되게 반응하는 것을 선호하기 때문이다. 이를 위해 이전에 무시했던 배경 픽셀에 diffuse 성분 fitting을 장려해야 한다. 그러나 이러한 픽셀은 shading 모델로 제대로 설명되지 않으며 높은 fitting 오차가 발생한다. 따라서 $L$을 고정하여 픽셀 사이의 오차 전파를 용이하게 하는 gradient를 차단하여 배경 fitting 오차를 자체 픽셀로 제한한다.
Results
- 데이터셋
- 합성 장면: Shiny Blender, Glossy Synthetic, TensoIR Synthetic
- 실제 장면: Stanford ORB
- 구현 디테일
- specular distillation 단계 전에 $r$과 $c$의 모든 채널을 0.99로 초기화
- $c$, $r$, $m$에는 sigmoid를 적용하여 0과 1 사이로 범위를 제한
- environment map에는 exponential activation을 적용하여 HDR을 더 잘 반영하도록 함
- \(I_\textrm{phy}\)는 ACES Filmic tone mapping curve로 톤 매핑된 후 sRGB color space로 변환됨
- environment light cubemap 해상도: 128$\times$128$\times$6
- 거리 $d$는 각 Gaussian의 중심과 카메라까지의 거리를 splatting하여 계산
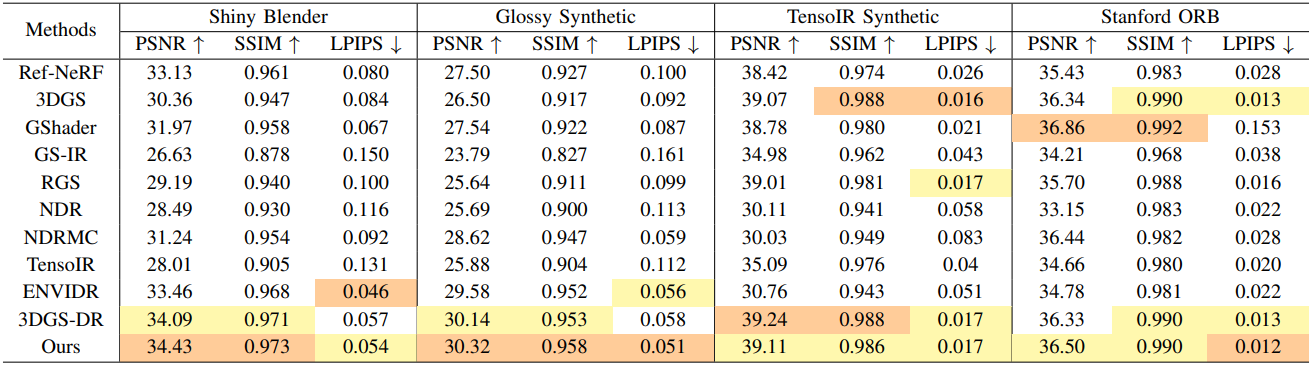
1. Comparisons with baselines
Novel view synthesis
다음은 novel views synthesis 성능을 기존 방법들과 비교한 결과이다.
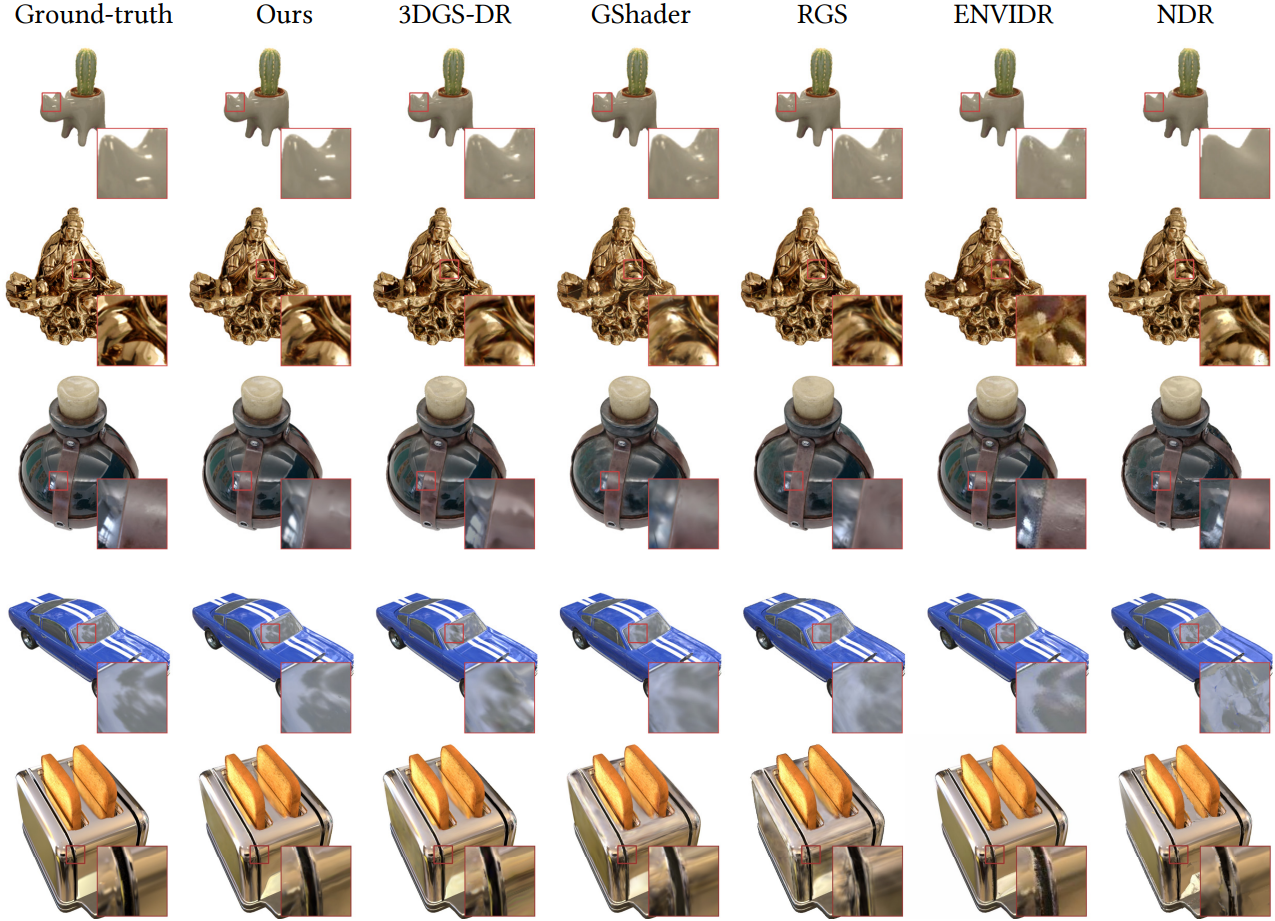
Decomposition
다음은 normal과 조명 재구성 품질을 각각 MAE°와 LPIPS로 기존 방법들과 비교한 표이다.

다음은 위에서부터 normal, environment map, albedo를 기존 방법들과 비교한 결과이다.



다음은 분해 결과를 기존 방법들과 비교한 것이다.

Relighting
다음은 relighting 결과를 기존 방법들과 비교한 것이다.

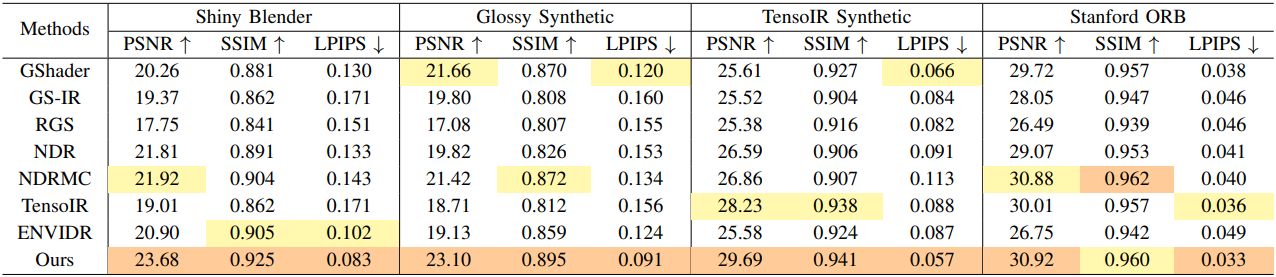
Efficiency
다음은 평균 학습 시간과 렌더링 FPS를 비교한 표이다.

2. Ablation Study
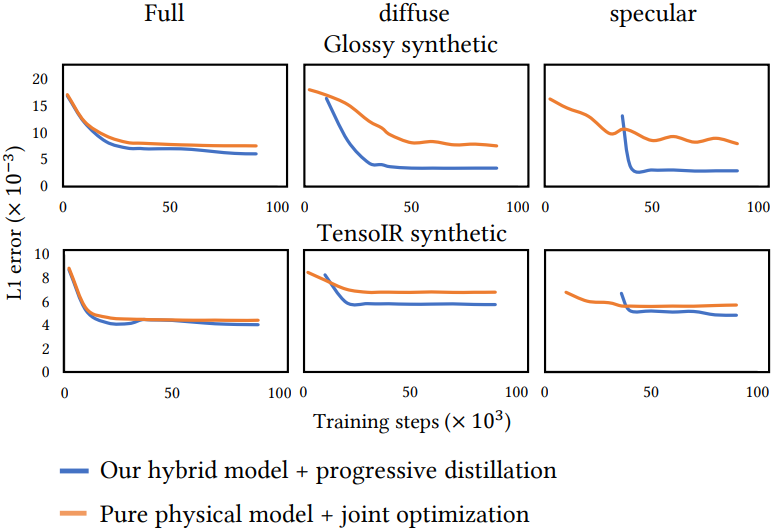
다음은 학습이 진행됨에 따른 전체 렌더링, diffuse 성분, specular 성분에 대한 L1 error를 비교한 그래프이다.
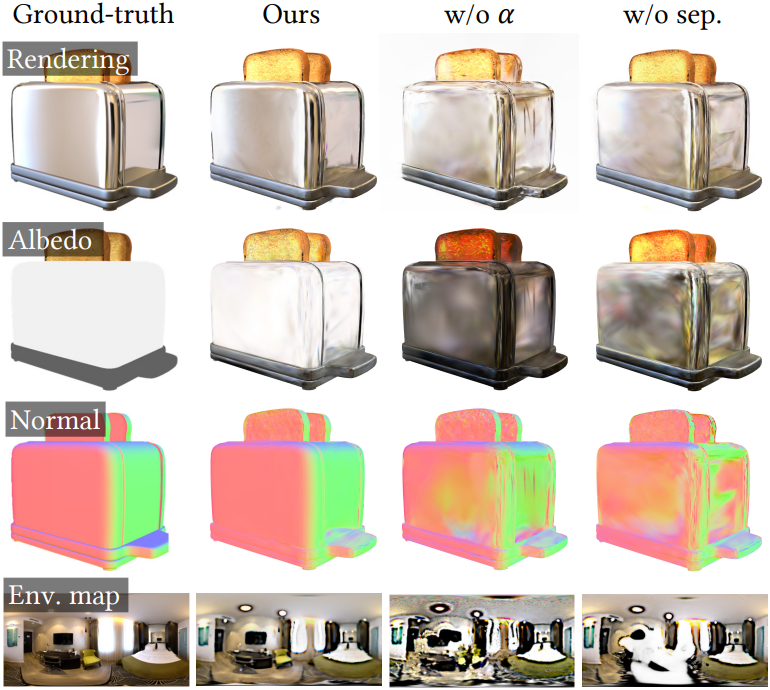
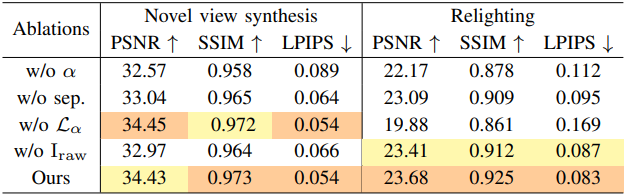
다음은 ablation study 결과이다.
다음은 원래 NDR과 본 논문의 최적화 방법을 사용한 NDR (NDR-PRD)을 비교한 결과이다. (표는 PSNR을 비교)


Limitations
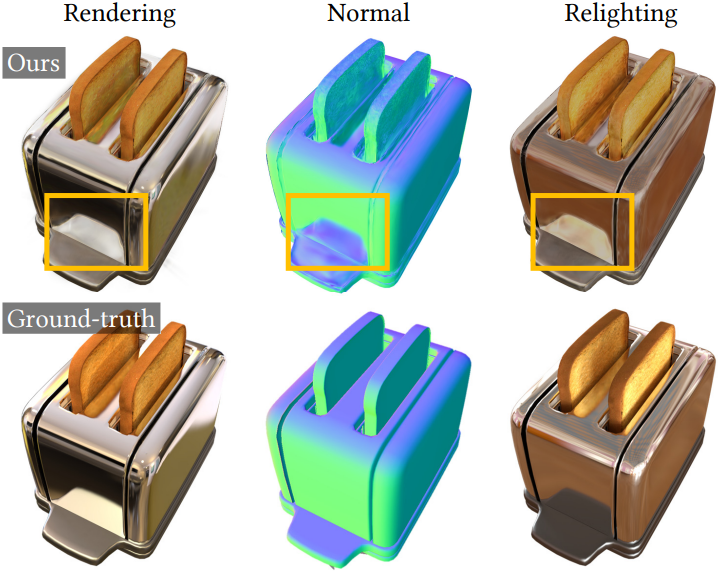
- 간접 조명을 명시적으로 처리할 수 없다. 이는 specular inter-reflection이 있는 표면에서 잘못된 normal을 초래하고, 부정확한 relighting 결과로 이어진다.
- 3-order SH를 사용하여 그리드 포인트에서 visibility를 압축하는데, 이는 diffuse 표면의 부드러운 그림자에 더 적합하다.
- 그림자는 albedo에 베이킹될 수 있다.
- Deferred shading 특성 상 유리와 같은 투명하거나 반투명한 물체의 렌더링 품질이 좋지 못하다.