[논문리뷰] Towards Practical Plug-and-Play Diffusion Models (PPAP)
CVPR 2023. [Paper] [Github]
Hyojun Go, Yunsung Lee, Jin-Young Kim, Seunghyun Lee, Myeongho Jeong, Hyun Seung Lee, Seungtaek Choi
Riiid AI Research
12 Dec 2022
Introduction
최근 diffusion 기반 생성 모델은 다양한 도메인에서 굉장한 성공을 보였다. 특히, 이미지 생성의 경우 diffusion model이 GAN보다 고품질의 이미지를 생성할 수 있으며 mode collapse나 학습 불안정성을 겪지 않는다고 알려져 있다.
이러한 장점 외에도 diffusion model의 공식은 원하는 조건을 향해 생성 프로세스를 guide하는 외부 모델의 guidance를 허용한다. Guided diffusion은 외부 유도 모델을 활용하고 diffusion model의 추가 fine-tuning이 필요하지 않기 때문에 plug-and-play 방식으로 저렴하고 제어 가능한 발전 가능성이 있다.
예를 들어, 이전 접근 방식은 클래스 조건부 이미지 생성을 위해 이미지 classifier를 사용하고, 패션 이미지 편집을 위한 패션 이해 모델을 사용하고, 텍스트 기반 이미지 생성을 위한 비전 언어 모델을 사용했다. 이 중에서 공개적으로 사용 가능한 상용 모델을 guidance로 사용할 수 있다면 하나의 diffusion model을 다양한 생성 task에 쉽게 적용할 수 있다.
이를 위해 기존에는 학습 데이터셋의 noisy한 버전에서 외부 상용 모델을 fine-tuning하여 diffusion process에서 발생하는 noisy한 latent 이미지에 모델을 적용하는 것이다. 그러나 이러한 방식에는 plug-and-play 생성에 대한 두 가지 문제가 있다.
- 단일 guidance 모델은 다양한 레벨의 noise로 손상된 입력을 예측하기에 불충분하며, 너무 어려운 task이다.
- 레이블이 지정된 학습 데이터셋이 필요하다.
본 논문에서는 먼저 첫 번째 문제를 이해하기 위해 noise의 정도를 다양하게 하여 classifier의 동작을 조사한다. Noise가 많은 손상된 이미지에 대해 학습된 guidance 모델은 coarse한 구조를 기반으로 이미지를 분류한다. 결과적으로 이러한 모델은 필수 골격 feature을 생성하도록 diffusion model을 guide한다. 한편, 깨끗한 이미지에 대해 학습된 guidance 모델은 이미지의 fine한 디테일을 캡처하여 diffusion model이 마무리 작업을 수행하도록 guide한다.
저자들은 이러한 주요 관찰 결과를 바탕으로 특정 noise 영역에 특화되도록 각각 fine-tuning된 여러 guidance 모델을 사용하는 새로운 multi-experts strategy를 제안한다. Multi-experts strategy의 효과에도 불구하고 다양한 생성 task에 대한 새로운 상용 모델을 적용할 때마다 여러 네트워크를 관리하고 레이블이 지정된 데이터를 활용해야 한다.
Multi-experts strategy를 사용한 diffusion model의 보다 실용적인 plug-and-play guidance를 위해 Practical Plug-And-Play (PPAP)라는 프레임워크를 도입한다. 첫째, multi-experts strategy로 인해 guidance 모델의 크기가 엄청나게 커지는 것을 방지하기 위해 상용 모델을 noisy한 이미지에 적응시키는 동시에 파라미터 수를 보존할 수 있는 효율적인 fine-tuning 체계를 활용한다. 둘째, 깨끗한 diffusion 생성 데이터에 대한 상용 모델 지식을 expert guidance model로 이전하여 레이블이 지정된 데이터셋을 수집할 필요가 없다.
Motivation
1. Preliminaries
Diffusion models
자세한 내용은 DDPM 논문리뷰 참고
\[\begin{equation} q(x_t \vert x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I) \\ x_t = \sqrt{\alpha_t} x_0 + \sqrt{1 - \alpha_t} \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) \\ \alpha_t := \prod_{s=1} (1- \beta_s) \\ x_{t-1} = \frac{1}{\sqrt{1 - \beta_t}} (x_t - \frac{\beta_t}{\sqrt{1 - \alpha_t}} \epsilon_\theta (x_t, t) ) + \sigma_t z \end{equation}\]Guided diffusion with external models
Guided diffusion은 외부 모델을 활용하여 diffusion model의 샘플 생성을 조정한다. 입력의 특정 특성을 예측하는 외부 안내 모델 $f_\phi$가 있다고 가정하자 (ex. 이미지 클래스를 예측하는 classifier). Reverse diffusion의 각 timestep $t$에서 guidance 모델을 사용하여 $x_t$가 특정 원하는 특성 $y_{target}$을 가질 확률을 증가시키는 방향으로 $x_t$에 대한 기울기를 계산한다. 그런 다음 일반적인 denoising 업데이트 외에도 $x_t$를 업데이트하여 해당 방향으로 한 step 더 나아간다. Reverse diffusion process는 다음과 같이 수정된다.
\[\begin{aligned} x_{t-1} = & \frac{1}{\sqrt{1 - \beta_t}} (x_t - \frac{\beta_t}{\sqrt{1 - \alpha_t}} \epsilon_\theta (x_t, t) ) \\ & + \sigma_t z - s \sigma_t \nabla_{x_t} \mathcal{L}_{guide} (f_\phi (x_t), y_{target}) \end{aligned}\]\(\mathcal{L}_{guide}\)는 guidance loss이고 $s$는 guidance 강도이다. 이 공식을 사용하면 외부 모델이 다양한 task를 위해 diffusion을 guide할 수 있다. 예를 들어, 클래스 조건부 이미지 생성의 경우 $f_\phi$는 $P_\phi (y_{target} \vert x_t)$를 출력하는 이미지 classifier이고, \(\mathcal{L}_{guide}\)는 $- \log (p_\phi (y_{target} \vert x_t))$로 주어진다.
2. Observation
Naive한 diffusion guidance 방식이 어떻게 실패하는지를 살펴보자. 구체적으로, 저자들은 guided diffusion에 사용될 때 신뢰도가 낮은 예측으로 인해 상용 모델이 실패하는 반면 광범위한 noise로 손상된 데이터에 대해 학습된 모델은 예측 task의 어려움으로 인해 실패한다는 것을 보여준다. 그런 다음 서로 다른 noise 레벨로 손상된 입력에 대해 학습된 classifier가 서로 다른 동작을 보인다는 것을 확인한다. 저자들은 이것이 diffusion guidance에 직접적인 영향을 미친다는 것을 보여준다. 즉, 다른 noise 영역에 특화된 expert guidance model을 갖는 것이 성공적인 guidance를 위해 매우 중요하다.
Setup
관찰 연구에는 diffusion model과 노이즈로 손상된 데이터에 대해 fine-tuning된 다양한 classifier가 포함된다. Guidance classifier의 경우 ImageNet에서 사전 학습된 ResNet50을 사용하고 필요할 때 fine-tuning했다. ImageNet 256$\times$256에서 학습된 diffusion model을 최대 timestep $T = 1000$으로 사용한다. Noisy한 데이터 버전을 생성하기 위해 forward diffusion process를 수행한다. 즉, 입력 $x_0$이 주어지면 $t = 1, \cdots, T$에 대해 $x_t$를 얻는다. Diffusion model을 guide하기 위한 classifier와 함께 25 step의 DDIM sampler를 사용한다.
Naive external model guidance is not enough

저자들은 naive diffusion guidance의 failure case를 조사하였다. 먼저, ImageNet 클래스 레이블에 대한 상용 ResNet50 classifier로 diffusion guidance를 시도하였다. 위 그림의 첫 행을 보면 모델이 diffusion guidance를 위한 의미있는 기울기를 제공하는 데 실패하였다.
또한 저자들은 ResNet50 classifier를 모든 timestep에 대한 forward diffusion process를 통해 손상된 데이터로 fine-tuning하였다. Fine-tuning한 모델은 naive한 상용 모델을 사용할 때보다 좋은 성능을 보인다.
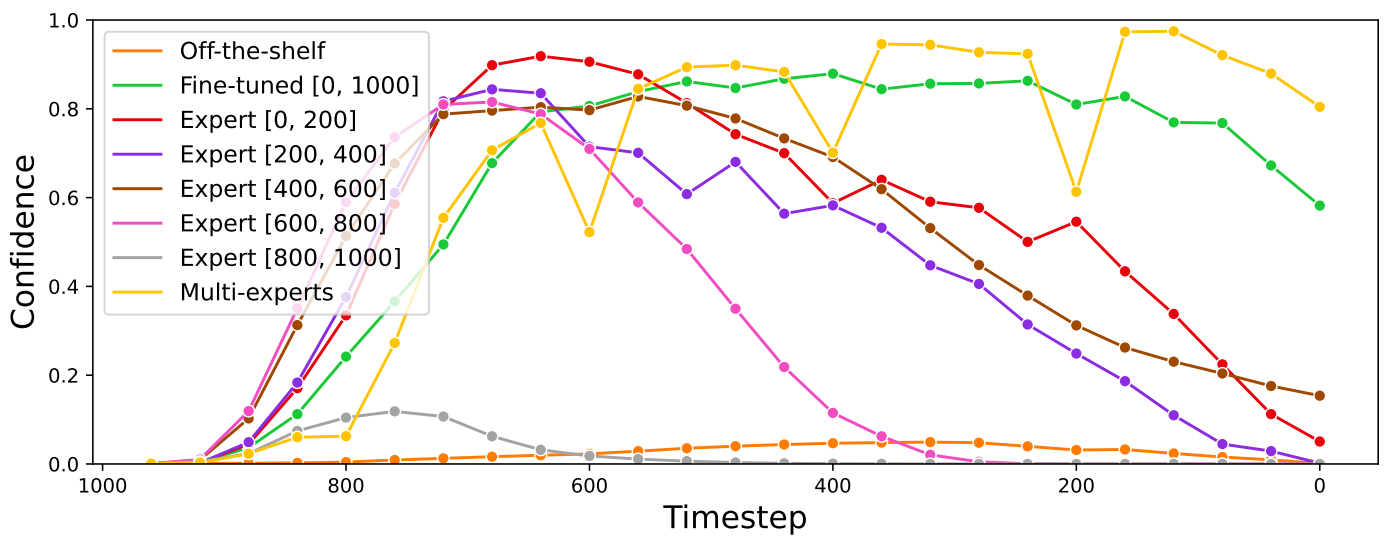
Naive diffusion guidance가 실패한 것은 위 그래프에서 볼 수 있듯이 상용 모델이 out-of-distribution에서 신뢰도가 낮고 엔트로피가 높은 출력을 내기 때문이다. Fine-tuning한 모델은 보다 깨끗한 이미지 ($t \approx 200)에서 classifier의 신뢰도가 감소하며 위 그림의 두번째 행과 같이 failure case로 이끈다.
Behavior of classifier according to learned noise
Single noise-aware model의 failure를 이해하기 위해, 저자들은 특정 noise level에서 fine-tuning된 classifier의 동작을 조사하였다. 구체적으로, 5개의 ResNet50 classifier \(f_{\phi_i}, i \in \{1, \cdots, 5\}\)를 fine-tuning하였다. $f_{\phi_i}$는 noisy한 입력 \(x_t, t \in \{(i-1) \cdot 200, \cdots, i \cdot 200\}\)에서 학습된다. 저자들은 먼저 Grad-CAM을 통해 각 $f_{\phi_i}$가 다르게 행동함을 관찰하였다.

예를 들어, 위 그림에서 볼 수 있듯이 noise가 적은 이미지에서 학습된 $f_{\phi_1}$과 $f_{\phi_2}$는 눈 등의 독특한 feature를 기반으로 허스키를 예측한다. 반면, noise가 많은 이미지에서 학습된 $f_{\phi_4}$과 $f_{\phi_5}$는 전체적인 모양을 기반으로 예측을 만든다.
이러한 차이는 다른 $f_{\phi_i}$를 사용하여 diffusion을 guide할 때 나타난다. 예를 들어 noise가 많은 이미지에서 학습된 $f_{\phi_5}$는 처음에는 거친 모양을 생성하지만 더 미세한 디테일을 채우지 못한다. 반면 noise가 적은 이미지로 학습된 $f_{\phi_1}$은 털이 많은 질감과 같은 특정 디테일을 생성하는 데 집중하는 것으로 보이지만 전체적인 구조가 부족하여 허스키 같은 이미지를 생성하지 못한다.
이러한 classifier의 동작은 이전 관점과 일치한다. Unconditional diffusion은 각각 큰 noise와 작은 noise에서 전체 구조와 미세한 디테일에 초점을 맞춘다. 저자들은 이를 고려하여 classifier가 해당 noise level을 학습함으로써 특정 noise level에서 diffusion을 guide할 수 있다는 가설을 세웠다.
3. Multi-Experts Strategy
앞의 관찰로부터 저자들은 특정 noise 범위에 전문화하도록 각 expert를 fine-tuning하는 multi-experts strategy를 제안한다. 깨끗한 데이터셋 \(\{(x_0, y)\}\)와 최대 diffusion step $T$가 주어진다고 가정하자. $N$개의 expert guidance model을 학습하며, $n$번째 expert $f_{\phi_n}$은 noisy한 데이터 \(x_t, t \in \{\frac{n-1}{N} T, \cdots, \frac{n}{N} T\}\)가 주어지면 ground-truth label $y$를 예측한다. 그런 다음 reverse diffusion process 중에 적합한 guidance model을 timestep에 따라 할당한다. Model guidance는 다음과 같이 다시 쓸 수 있다.
\[\begin{aligned} x_{t-1} = & \frac{1}{\sqrt{1 - \beta_t}} (x_t - \frac{\beta_t}{\sqrt{1 - \alpha_t}} \epsilon_\theta (x_t, t)) \\ & + \sigma_t z - s \sigma_t \nabla_{x_t} \mathcal{L}_{guide} (f_{\phi_n} (x_t), y) \end{aligned}\]여기서 $n$은 \(t \in \{\frac{n-1}{N} T + 1, \cdots, \frac{n}{N} T\}\)를 만족한다. 이 전략은 하나의 외부 guidance model만을 사용하기 때문에 추가적인 모델 inference 시간 비용을 발생시키지 않는다.
Practical Plug-and-Play Diffusion
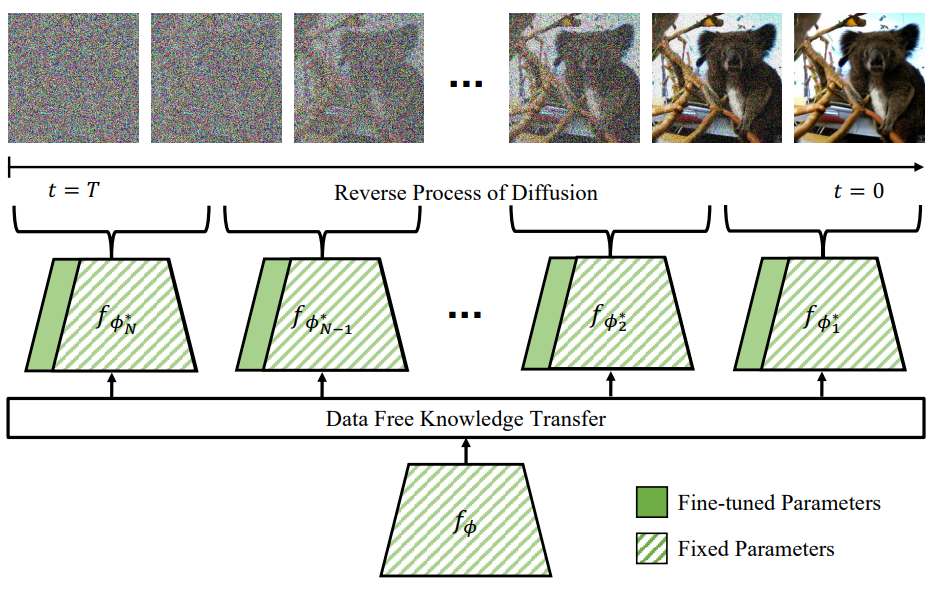
새로운 상용 모델을 적용할 때마다 multi-expert strategy는 여러 네트워크를 활용하고 레이블이 지정된 데이터셋을 수집해야 한다. 이러한 비실용성을 다루기 위해 위 그림과 같이 다음 두 가지 구성 요소로 multi-expert strategy를 취하는 Practical Plug-And-Play (PPAP)라는 plug-and-play diffusion guidance 프레임워크를 제안한다.
- Guidance model의 크기가 엄청나게 커지는 것을 방지하기 위해 파라미터 공유를 기반으로 파라미터 효율적인 fine-tuning 방식을 도입
- 깨끗한 diffusion으로 생성된 데이터에 대한 상용 모델의 지식을 expert guidance model로 이전하는 지식 이전 방식을 사용하여 레이블이 지정된 데이터의 필요성을 우회
1. Parameter Efficient Multi-Experts Strategy
제안된 multi-expert strategy의 한 가지 한계는 guidance model의 수가 $N$배 증가함에 따라 fine-tuning을 위한 파라미터의 수가 $N$배 증가한다는 것이다. 이 문제를 해결하기 위해 대부분의 고정된 상용 모델을 재사용하면서 소수의 파라미터만 fine-tuning하는 파라미터 효율적인 전략을 사용한다.
구체적으로 bias와 batch normalization을 fine-tuning하고 상용 모델의 특정 가중치 행렬에 LoRA를 적용한다. 이 방법은 모델 깊이를 확장하는 등 아키텍처를 변경하지 않기 때문에 추가적인 inference 시간 비용이 발생하지 않는다. 상용 모델 $f_\phi$와 구별하기 위해 $n$번째 expert를 $f_{\phi_n^\ast}$로 표시한다. Diffusion model의 reverse process에서 상용 backbone model을 재사용하면서 noise 영역에 따라 추가된 학습 파라미터만 바꾸면 된다.
2. Data Free Knowledge Transfer
지금까지 guidance model을 학습시키는 데 사용된 데이터셋 \(\{(x_0, y)\}\)에 접근할 수 있다고 가정했다. 실용적인 plug-and-play 생성을 위해서는 각 task에 적합한 레이블이 지정된 데이터셋을 얻지 않고도 상용 모델로 guidance를 적용할 수 있어야 한다.
여기서 저자들은 diffusion model을 사용하여 깨끗한 데이터셋 \(\{\tilde{x}_0\}\)를 생성한 다음 expert guidance model을 학습시키는 데 사용할 것을 제안한다. 기본 가정은 깨끗한 이미지에서 상용 모델의 예측을 모방함으로써 expert가 어느 정도 noise 영역에서 작동할 수 있다는 것이다. 즉, 상용 모델 $f_\phi$를 teacher로 취급하고 expert guidance model $f_{\phi_n}$을 학습할 때 깨끗한 데이터에 대한 예측을 레이블로 사용한다. Knowledge transfer loss를 다음과 같이 공식화한다.
\[\begin{equation} \mathcal{L}_{KT} = \mathbb{E}_{t \sim \textrm{unif}\{\frac{n-1}{N} T, \cdots, \frac{n}{N} T\}} [\mathcal{L}(\textrm{sg}(f_\phi (\tilde{x}_0)), f_{\phi_n^\ast} (\tilde{x}_t))] \end{equation}\]$\textrm{sg}(\cdot)$은 stop-gradient 연산자이며, $\mathcal{L}$은 task별 loss function이다. 위의 공식을 사용하면 다양한 loss function을 사용하는 것만으로도 쉽게 다양한 task를 적응시킬 수 있다.
Image classification
이미지 classifier는 이미지를 입력으로 받아 logit vector를 출력한다. Classifier를 위한 knowledge transfer loss \(\mathcal{L}_{clsf}\)는 다음과 같다.
\[\begin{equation} \mathcal{L}_{clsf} = D_{KL} (\textrm{sg} (\textrm{s} (f_\phi (\tilde{x}_0) / \tau)), \textrm{s}(f_{\phi_n^\ast} (\tilde{x}_t))) \end{equation}\]$\textrm{s}$는 softmax 연산자이고 $\tau$는 temperature hyperparameter이며 $D_{KL} (\cdot)$은 KL divergence이다.
Experiment
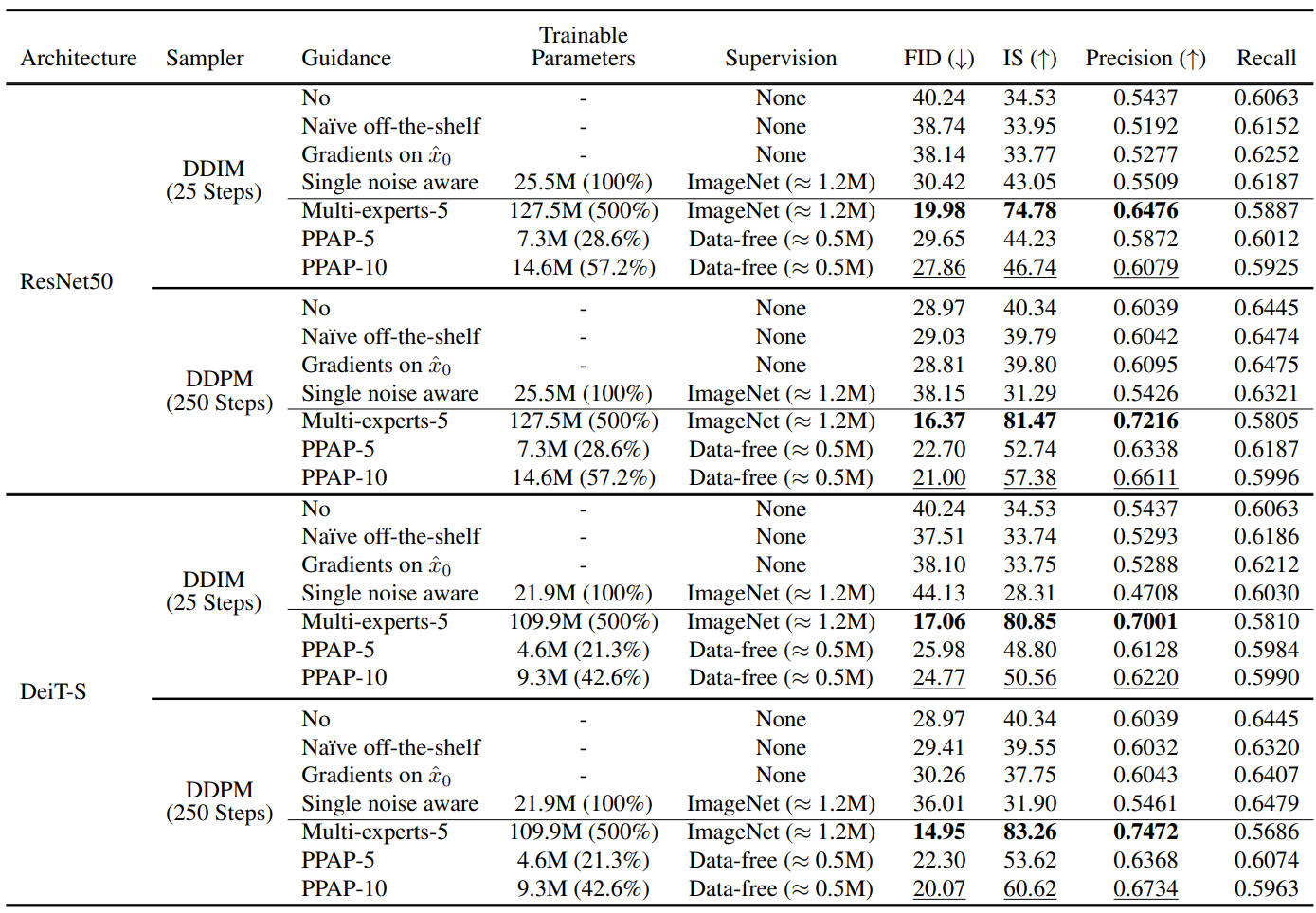
1. ImageNet Classifier Guidance
- Base model: ImageNet에서 사전 학습된 unconditional ADM 256$\times$256
- Classifier: CNN 기반 ResNet50, Transformer 기반 DeiT-S
- Guidance model:
- Naive off-the-shelf: Noise에 대한 추가 학습 없이 사전 학습된 모델 사용
- Single noise aware: 전체 noise 범위에서 손상된 데이터로 fine-tuning
- Multi-experts-$N$: Parameter-efficient tunning 없이 $N$개의 expert guidance model을 supervised 방식으로 fine-tuning
- PPAP-$N$: 생성된 이미지로 $N$개의 expert를 파라미터 효율적인 지식 이전
Main results
다음은 ResNet50과 DeiT-S에 대한 전체적인 결과를 나타낸 표이다.
다음은 DDPM 250 stepd으로 ImageNet에서 클래스 조건부 생성을 한 정성적 결과이다.

Ablation study
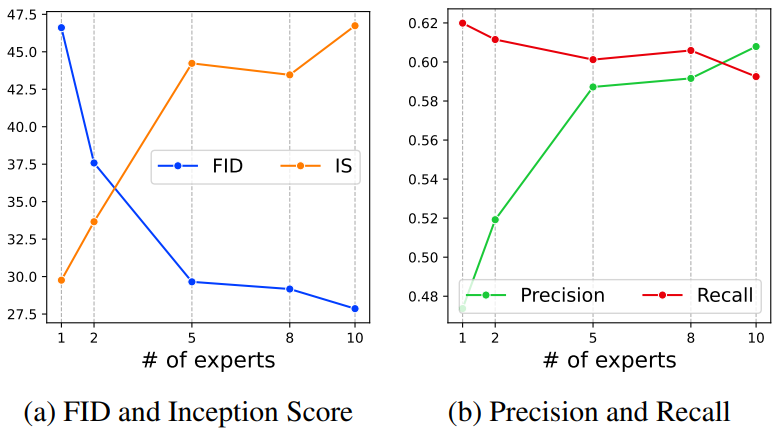
다음은 expert의 수에 대한 ablation study 결과를 나타낸 그래프이다.
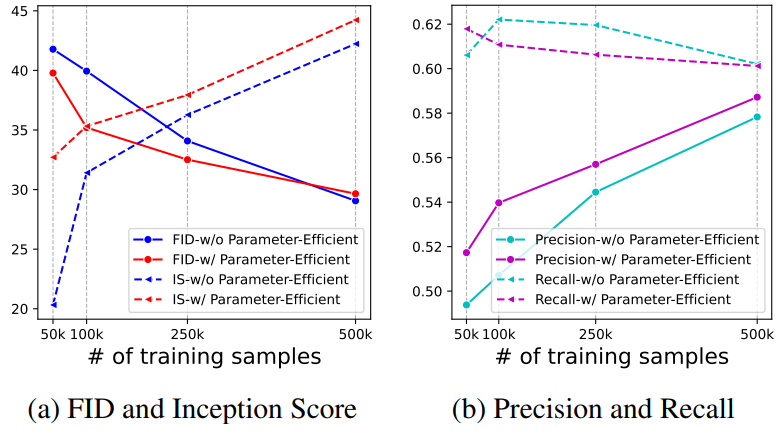
다음은 parameter-efficient tunning과 데이터 효율성에 대한 ablation study 결과를 나타낸 그래프이다.
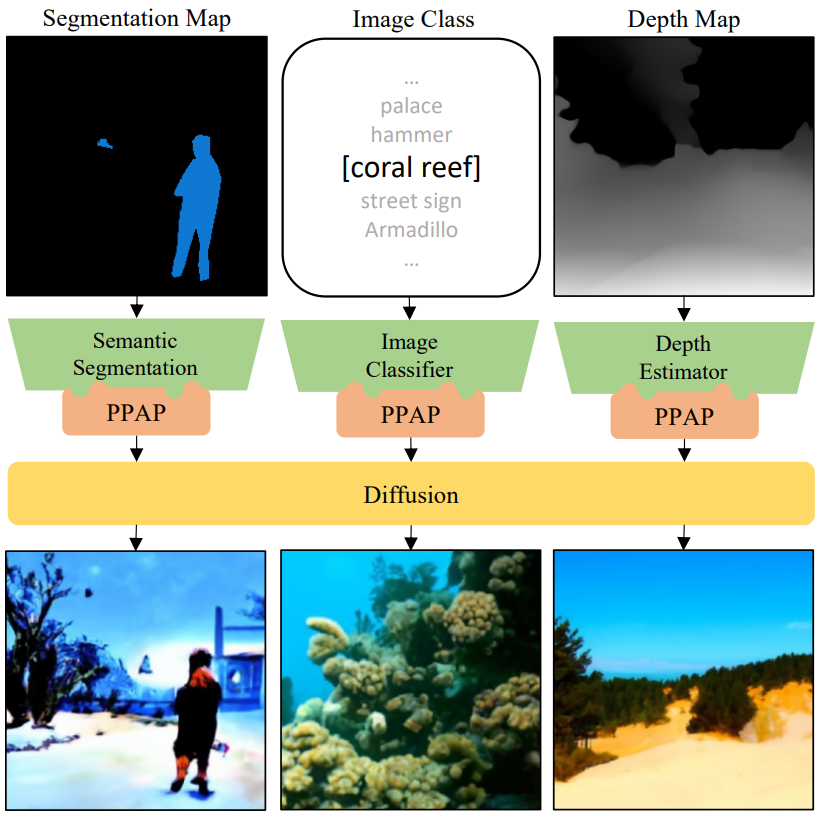
2. Guiding GLIDE for Various Downstream Tasks
GLIDE는 2개의 diffusion model로 구성된다.
- Generator: 주어진 텍스트 입력에서 64$\times$64 이미지 생성
- Upsampler: 생성된 64$\times$64 이미지를 256$\times$256 이미지로 upsample
GLIDE를 unconditional하게 만들기 위해 빈 토큰을 generator의 입력으로 주었다. Upsampler는 크기만 키우므로 generator를 guide한다. 모든 guidance model은 5개의 expert로 구성된다. Data-free knowledge transfer의 경우 50만 개의 unconditional 64$\times$64 이미지를 25-step DDIM sampler로 생성한다. Guidance 이미지 생성의 경우 generator는 250 step의 DDPM sampler를 사용하고 upsampler는 fast27 sampler을 사용한다.
다음은 ResNet50으로 GLIDE를 guide하여 생성한 이미지이다.

다음은 MidaS depth estimator로 GLIDE를 guide하여 생성한 이미지이다.

다음은 DeepLabv3 semantic segmentation으로 GLIDE를 guide하여 생성한 이미지이다.
