[논문리뷰] PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
arXiv 2022. [Paper] [Github]
Juncai Peng, Yi Liu, Shiyu Tang, Yuying Hao, Lutao Chu, Guowei Chen, Zewu Wu, Zeyu Chen, Zhiliang Yu, Yuning Du, Qingqing Dang, Baohua Lai, Qiwen Liu, Xiaoguang Hu, Dianhai Yu, Yanjun Ma
Baidu Inc.
6 Apr 2022
Introduction
딥러닝의 눈부신 발전과 함께 CNN을 기반으로 한 semantic segmentation 방법이 많이 제안되었다. FCN은 end-to-end 및 pixel-to-pixel 방식으로 학습된 최초의 fully convolutional network이며, 인코더-디코더 아키텍처를 제시하였다. 더 높은 정확도를 달성하기 위해 PSPNet은 pyramid pooling module(PPM)을 활용하여 글로벌 컨텍스트를 집계하고 SFNet은 feature 표현을 강화하기 위해 flow alignment module을 제안하였다.
그러나 이러한 모델들은 계산 비용이 높기 때문에 실시간 응용 프로그램에는 적합하지 않다. Inference 속도를 높이기 위해 Espnetv2는 경량 convolution을 사용하여 확대된 receptive field에서 feature를 추출하였다. BiSeNetV2는 bilateral segmentation network를 제안하고 디테일한 feature와 semantic feature를 별도로 추출하였다. STDCSeg는 계산 효율성을 향상시키기 위해 STDC라는 새로운 backbone을 설계하였다. 그러나 이러한 모델들은 정확도와 속도 사이에서 만족스러운 균형을 이루지 못하였다.
본 연구에서는 PP-LiteSeg라는 실시간 수작업 네트워크를 제안하였다. PPLiteSeg는 인코딩-디코더 아키텍처를 채택하고
- Flexible and Lightweight Decoder (FLD)
- Unified Attention Fusion Module (UAFM)
- Simple Pyramid Pooling Module (SPPM)
의 세 가지 새로운 모듈로 구성된다.
Semantic segmentation 모델의 인코더는 계층적 feature를 추출하고, 디코더는 feature를 융합하고 unsample한다. 인코더의 낮은 레벨부터 높은 레벨까지의 feature에 대해 채널 수는 증가하고 공간 크기는 감소하므로 효율적인 디자인이다. 디코더의 높은 레벨에서 낮은 레벨까지의 feature은 공간 크기가 증가하는 반면 채널 수는 동일하다. 따라서 저자들은 점진적으로 채널을 줄이고 feature의 공간 크기를 늘리는 FLD를 제시하였다. 또한, 제안된 디코더의 볼륨은 인코더에 따라 쉽게 조절될 수 있다. 이 유연한 디자인은 인코더와 디코더의 계산 복잡도 사이의 균형을 유지하여 전체 모델을 더욱 효율적으로 만든다.
Feature 표현을 강화하는 것은 분할 정확도를 향상시키는 중요한 방법이다. 이는 일반적으로 디코더의 하위 레벨 feature와 상위 레벨 feature를 융합하여 달성된다. 그러나 기존 방식의 융합 모듈은 일반적으로 높은 계산 비용으로 인해 어려움을 겪는다. 본 논문에서는 feature 표현을 효율적으로 강화하기 위한 UAFM을 제안하였다. UAFM은 먼저 attention 모듈을 활용하여 가중치 $\alpha$를 생성한 다음 입력 feature를 $\alpha$와 융합한다. UAFM에는 두 가지 종류의 attention 모듈, 즉 입력 feature의 공간 사이 및 채널 사이 관계를 활용하는 공간 및 채널 attention 모듈이 있다.
컨텍스트별 집계는 분할 정확도를 높이는 또 다른 핵심이지만, 이전 집계 모듈들은 시간이 많이 걸린다. 저자들은 PSPNet의 PPM 프레임워크를 기반으로 중간 및 출력 채널을 줄이고 short-cut을 제거하며 concatenate 연산을 합연산으로 대체하는 SPPM을 설계하였다.
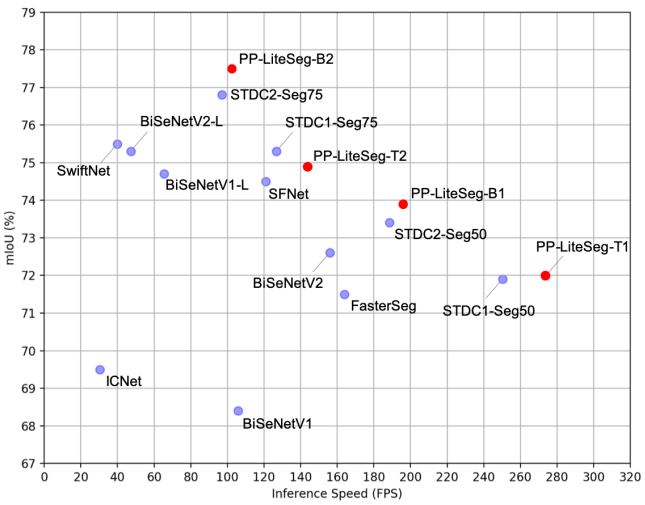
PP-LiteSeg는 분할 정확도와 inference 속도 간의 탁월한 균형을 달성한다. 특히 PP-LiteSeg는 Cityscapes test set에서 72.0% mIoU/273.6 FPS와 77.5% mIoU/102.6 FPS를 달성했다.
Proposed Method
1. Flexible and Lightweight Decoder
인코더-디코더 아키텍처는 semantic segmentation에 효과적인 것으로 입증되었다. 일반적으로 인코더는 계층적 feature를 추출하기 위해 여러 단계로 그룹화된 일련의 레이어를 활용한다. 낮은 레벨에서 높은 레벨로 갈수록 채널 수가 점차 증가하고 feature의 공간적 크기가 감소한다. 이 디자인은 각 단계의 계산 비용 균형을 유지하여 인코더의 효율성을 보장한다. 디코더에는 feature의 융합 및 업샘플링을 담당하는 여러 단계도 있다. Feature의 공간적 크기는 높은 레벨에서 낮은 레벨로 증가하지만 최근 경량 모델의 디코더는 모든 레벨에서 feature 채널을 동일하게 유지한다. 따라서 얕은 단계의 계산 비용은 깊은 단계의 계산 비용보다 훨씬 크므로 얕은 단계의 계산 중복이 발생한다.
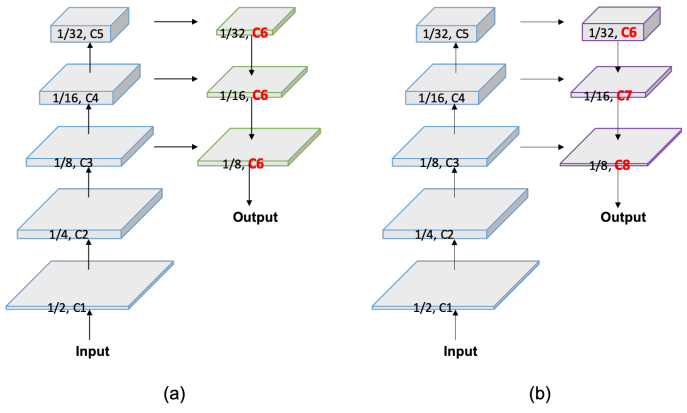
본 논문은 디코더의 효율성을 향상시키기 위해 Flexible and Lightweight Decoder (FLD)를 제시하였다. 위 그림에서 (a)는 기존의 인코더-디코더이고 (b)는 FLD이다. FLD는 feature의 채널을 높은 레벨에서 낮은 레벨로 점진적으로 감소시킨다. FLD는 인코더와 디코더 간의 더 나은 균형을 달성하기 위해 계산 비용을 쉽게 조정할 수 있다. FLD의 feature 채널이 감소하고 있지만 PP-LiteSeg는 다른 방법에 비해 경쟁력 있는 정확도를 달성한다.
2. Unified Attention Fusion Module
위에서 설명한 것처럼 높은 분할 정확도를 달성하려면 여러 단계의 feature를 융합하는 것이 필수적이다. 본 논문에서는 융합된 feature 표현을 풍부하게 하기 위해 채널 및 공간 attention을 적용하는 Unified Attention Fusion Module (UAFM)을 제안하였다.
UAFM Framework

위에서 볼 수 있듯이 UAFM은 attention 모듈을 활용하여 가중치 $\alpha$를 생성하고 Mul 및 Add 연산을 통해 입력 feature를 $\alpha$와 융합한다. 입력 feature는 $F_\textrm{high}$와 $F_\textrm{low}$이다. $F_\textrm{high}$는 더 깊은 모듈의 출력이고 $F_\textrm{low}$는 인코더의 출력이며, 채널이 동일하다. UAFM은 먼저 bilinear interpolation을 사용하여 $F_\textrm{high}$를 $F_\textrm{low}$와 동일한 크기인 $F_\textrm{up}$으로 업샘플링한다. 그런 다음 attention 모듈은 $F_\textrm{up}$과 $F_\textrm{low}$를 입력으로 가중치 $\alpha$를 생성한다. 그 후 attention으로 가중된 feature를 얻기 위해 element-wise 곱연산을 $F_\textrm{up}$과 $F_\textrm{low}$에 각각 적용한다. 마지막으로 attention으로 가중된 feature들에 대해 element-wise 합연산을 수행하고 융합된 feature를 출력한다.
여기서 attention 모듈은 공간 attention 모듈이나 채널 attention 모듈이다.
Spatial Attention Module

공간 attention 모듈은 공간 사이의 관계를 활용하여 입력 feature의 각 픽셀의 중요성을 나타내는 가중치를 생성한다. 위 그림에서 볼 수 있듯이 입력 feature, 즉 $F_\textrm{up} \in \mathbb{R}^{C \times H \times W}$와 $F_\textrm{low} \in \mathbb{R}^{C \times H \times W}$가 주어지면 먼저 채널 축을 따라 mean 연산과 max 연산을 수행하여 4가지 feature를 생성한다. 그 후, 이 네 가지 feature는 $F_\textrm{cat} \in \mathbb{R}^{4 \times H \times W}$로 concatenate된다. Concatenate된 feature에 convolution과 sigmoid 연산을 적용하여 $\alpha \in \mathbb{R}^{1 \times H \times W}$를 생성한다.
추가로 계산 비용을 줄이기 위해 max 연산을 제거할 수도 있다.
Channel Attention Module

채널 attention 모듈은 채널 사이의 관계를 활용하여 입력 feature에서 각 채널의 중요성을 나타내는 가중치를 생성한다. 위 그림에서 볼 수 있듯이 제안된 채널 attention 모듈은 average-pooling과 max-pooling 연산을 활용하여 입력 feature의 공간 차원을 압축한다. 이를 통해 $\mathbb{R}^{C \times 1 \times 1}$ 차원의 4개의 feature가 생성된다. 그런 다음 채널 축을 따라 이 네 가지 feature를 concatenate하고 convolution과 sigmoid 연산을 수행하여 가중치 $\alpha \in \mathbb{R}^{C \times 1 \times 1}$를 생성한다.
3. Simple Pyramid Pooling Module
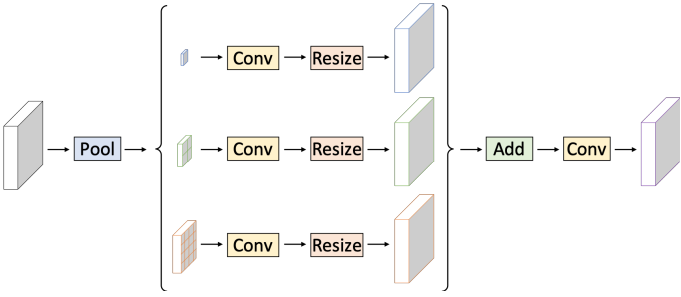
본 논문은 위 그림과 같이 Simple Pyramid Pooling Module (SPPM)을 제안하였다. 먼저 Pyramid Pooling Module (PPM)을 활용하여 입력 feature를 융합한다. PPM에는 세 가지 global-average-pooling 연산이 있으며 bin 크기가 각각 1$\times$1, 2$\times2, 4$\times$4이다. 그 후 출력 feature 뒤에는 convolution과 업샘플링 연산이 이어진다. Convolution 연산의 경우 커널 크기는 1$\times$1이고 출력 채널은 입력 채널보다 작다. 마지막으로 업샘플링된 feature들을 더하고 convolution 연산을 적용하여 개선된 feature를 생성한다. 원래 PPM과 비교하여 SPPM은 중간 채널과 출력 채널을 줄이고 short-cut을 제거하며 concatenate 연산을 합연산으로 대체한다. 결과적으로 SPPM은 실시간 모델에 더 효율적이고 적합하다.
4. Network Architecture
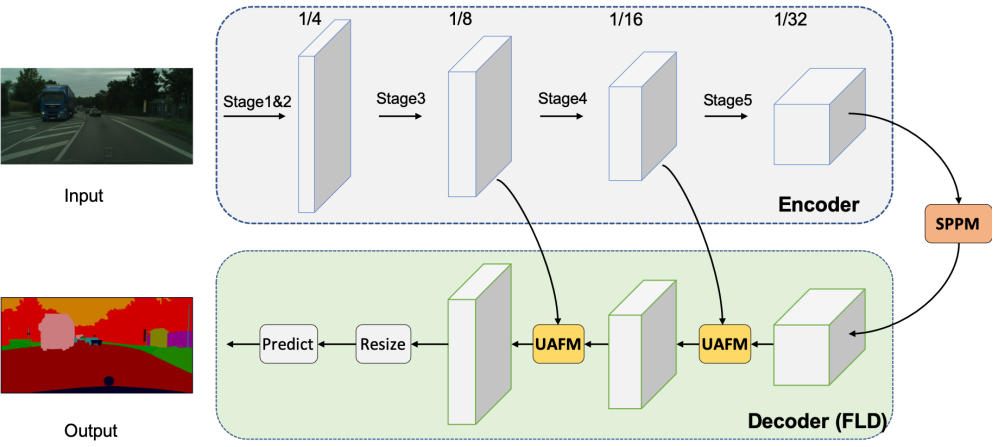
PP-LiteSeg의 아키텍처는 위 그림과 같다. PP-LiteSeg는 크게 인코더, 집계, 디코더의 세 가지 모듈로 구성된다.
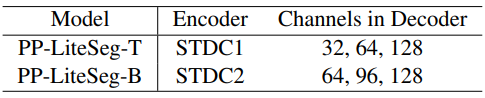
첫째, 입력 이미지가 주어지면 PP-Lite는 계층적 feature를 추출하기 위해 공통 경량 네트워크를 인코더로 활용하며, 저자들은 STDCNet을 선택했다. STDCNet에는 5개의 stage가 있고 각 stage의 stride는 2이므로 최종 feature 크기는 입력 이미지의 1/32이다. 위 표와 같이 PP-LiteSeg의 두 가지 버전, 즉 PP-LiteSeg-T와 PP-LiteSeg-B가 있으며, 인코더는 각각 STDC1과 STDC2이다. PPLiteSeg-B는 더 높은 분할 정확도를 달성하는 반면 PP-LiteSeg-T의 inference 속도가 더 빠르다. 인코더 학습에 SSLD 방법을 적용하고 강화된 사전 학습된 가중치를 얻으며, 이는 학습의 수렴에 도움이 된다.
둘째, PP-LiteSeg는 SPPM을 채택하여 장거리 의존성을 모델링한다. SPPM은 인코더의 출력 feature를 입력으로 사용하여 글로벌 컨텍스트 정보가 포함된 feature를 생성한다.
마지막으로 PP-LiteSeg는 제안된 FLD를 활용하여 여러 레벨의 feature들을 점진적으로 융합하고 결과 이미지를 출력한다. FLD는 2개의 UAFM과 1개의 분할 헤드로 구성된다. 효율성을 위해 UAFM에서는 공간 attention 모듈을 채택한다. 각 UAFM은 인코더 단계에서 추출된 하위 레벨 feature와 SPPM 또는 깊은 융합 모듈에서 생성된 상위 레벨 feature를 입력으로 사용한다. 후자의 UAFM은 1/8의 다운샘플링 비율로 융합된 feature를 출력한다. 분할 헤드에서는 1/8 다운샘플링된 feature의 채널을 클래스 수로 줄이기 위해 Conv-BN-Relu 연산을 수행한다. Feature 크기를 입력 이미지 크기로 확장하기 위해 업샘플링 연산이 수행되고, argmax 연산은 각 픽셀의 레이블을 예측한다. 모델을 최적화하기 위해 cross entropy loss가 채택되었다.
Experiments
- 데이터셋: Cityscapes, CamVid
- 학습 디테일
- optimizer: SGD (momentum = 0.9)
- warp-up과 poly learning rate schedule 사용
- Cityscapes
- batch size: 16
- iteration: 16만
- 초기 learning rate: 0.005
- weight decay: $5 \times 10^{-4}$
- 해상도: 1024$\times$512
- CamVid
- batch size: 24
- iteration: 1,000
- 초기 learning rate: 0.01
- weight decay: $10^{-4}$
- 해상도: 960$\times$720
- Data augmentation: random scaling, random cropping, random horizontal flipping, random color jittering, normalization
1. Experiments on Cityscapes
Comparisons with State-of-the-arts
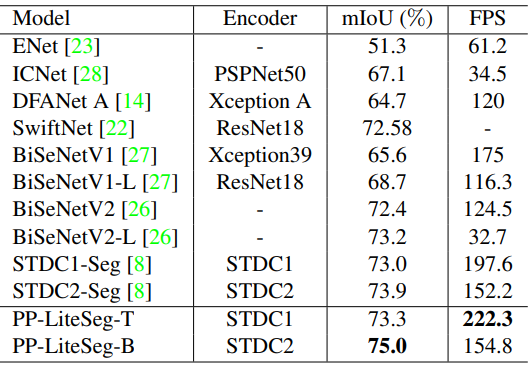
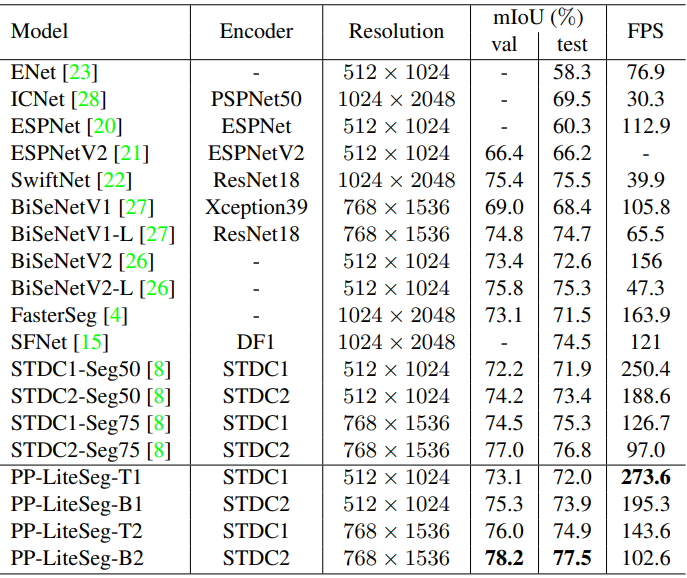
다음은 Cityscapes에서 SOTA 실시간 방법들과 비교한 표이다.
Ablation study
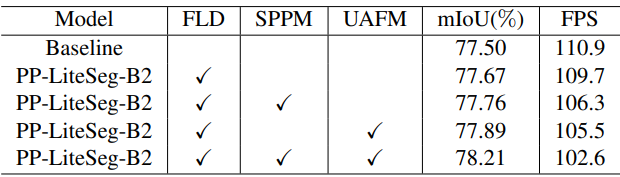
다음은 Cityscapes validation set에서의 ablation study 결과이다.
다음은 Cityscapes validation set에서의 결과를 비교한 것이다.
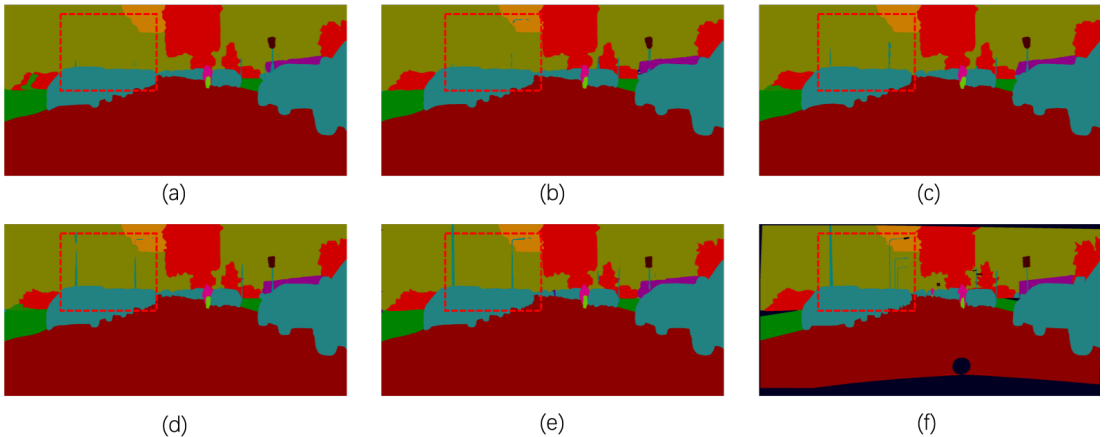
- (a): baseline
- (b): baseline + FLD
- (c): baseline + FLD + SPPM
- (d): baseline + FLD + UAFM
- (e): baseline + FLD + SPPM + UAFM
- (f): ground truth
2. Experiments on CamVid
다음은 CamVid test set에서 SOTA 실시간 방법들과 비교한 표이다.