[논문리뷰] Pow3R: Empowering Unconstrained 3D Reconstruction with Camera and Scene Priors
CVPR 2025. [Paper] [Page]
Wonbong Jang, Philippe Weinzaepfel, Vincent Leroy, Lourdes Agapito, Jerome Revaud
UCL | Naver Labs Europe
21 Mar 2025

Introduction
DUSt3R는 calibration되지 않고 포즈를 모르는 이미지로부터 3D 재구성을 수행하여 fine-tuning 없이 여러 후속 비전 task를 한 번에 해결한다. DUSt3R의 성공은 두 가지 주요 요인에 기인한다.
- 출력 공간에 대한 유연성을 제공하고 카메라 파라미터, 포즈, 깊이를 쉽게 추출할 수 있는 pointmap 표현을 사용한다.
- 방대한 3D 학습 데이터와 결합된 강력한 사전 학습을 활용하는 transformer 아키텍처를 사용한다.
DUSt3R와 그 후속 모델인 MASt3R는 큰 성공에도 불구하고 입력 공간 측면에서 매우 제한적이다. 즉, RGB 이미지만 사용한다. 그러나 실제로 많은 실제 응용 프로그램은 calibration된 카메라 intrinsic, RGB-D 센서나 LIDAR 등의 sparse/dense depth와 같은 추가 모달리티를 제공한다. 이는 추가 입력 모달리티를 가장 잘 활용하는 방법과 이를 통해 성능을 향상시킬 뿐만 아니라 SfM이나 LiDAR의 sparse한 포인트 클라우드에서 전체 깊이를 얻는 것과 같은 새로운 기능을 사용할 수 있는지에 대한 의문을 제기한다.
본 논문에서는 test-time에 사용 가능한 사전 정보 (카메라 intrinsic, sparse 또는 dense depth, 또는 상대적 카메라 포즈 등)를 DUSt3R에 제공하는 새로운 3D feedforward 모델인 Pow3R를 소개한다. Test-time에 모델이 다양한 조건에서 작동할 수 있도록 각 학습 iteration마다 입력 모달리티의 무작위 부분집합이 입력된다. 결과적으로, 사전 정보가 없을 때는 DUSt3R와 비슷한 수준의 성능을, 사전 정보가 있을 때는 DUSt3R보다 우수한 성능을 보이는 모델을 얻는다.
또한, Pow3R는 추가로 새로운 기능을 얻는다. 예를 들어, 카메라 intrinsic 입력을 통해 principal point가 중심에서 멀리 떨어진 이미지를 처리할 수 있으므로 sliding window inference와 같은 극단적인 cropping을 수행할 수 있다. 또한, Pow3R는 두 번째 이미지의 pointmap을 좌표계에 직접 출력하여 상대적 포즈 추정 속도를 높인다.
Method
- 입력
- 주어진 정적 장면의 두 입력 이미지 $I^1, I^2 \in \mathbb{R}^{W \times H \times 3}$
- (선택) 보조 정보 \(\Omega \subseteq \{K_1, K_2, P_{12}, D^1 , D^2\}\)
- $K_1, K_2 \in \mathbb{R}^{3 \times 3}$: 각 카메라의 intrinsic
- $P_{12} \in \mathbb{R}^{4 \times 4}$: 두 카메라 사이의 상대적 포즈
- $D^1, D^2 \in \mathbb{R}^{W \times H}$, \(M^1, M^2 \in \{0, 1\}^{W \times H}\): depth map과 깊이가 유효한 픽셀을 지정하는 마스크
- 목표
- 두 이미지 모두에 대해 pointmap $X^{1,1}, X^{2,1}, X^{2,2} \in \mathbb{R}^{W \times H \times 3}$을 예측 ($X^{n,m}$은 $I^m$의 카메라 좌표계에서의 $I^n$의 pointmap)
- Pointmap으로부터 카메라 intrinsic, extrinsic, dense depth map을 추출
1. Overall architecture
본 논문은 DUSt3R 프레임워크를 따른다. DUSt3R는 ViT를 기반으로 하는 foundation model로, 포즈를 모르고 calibration되지 않은 두 개의 입력 이미지만 주어졌을 때 두 개의 3D pointmap $X^{1,1}$과 $X^{2,1}$을 예측할 수 있다. 그럼에도 불구하고 DUSt3R는 카메라나 깊이에 대한 잠재적으로 사용 가능한 정보를 활용할 수 없어 실제 사용이 제한된다. 이러한 단점을 해결하기 위해, 원래 DUSt3R 네트워크 $\mathcal{F}$를 두 가지 방법으로 향상시킨다.
- 카메라 intrinsic, 카메라 포즈, depth map과 같은 추가 정보를 DUSt3R에 원활하게 통합하기 위한 특정 모듈을 도입하였다.
- 이미지 $I^2$의 pointmap을 자체 좌표계로 나타내는 추가 pointmap $X^{2,2}$를 예측한다. 세 개의 pointmap을 예측하면 한 번의 forward pass에서 두 카메라에 대한 모든 정보를 복구할 수 있다.
인코더
두 이미지를 독립적으로 인코딩하기 위해 공유 ViT 인코더를 사용한다. 인코더는 $I$ 외에도 각 이미지의 intrinsic $K$와 깊이 $D$에 대한 보조 정보를 받을 수 있다. 두 입력 이미지 $I^1$, $I^2$와 각각의 보조 정보 \(\Omega_1 \in \sigma(\{K_1, D_1\})\), \(\Omega_2 \in \sigma(\{K_2, D_2\})\)에 대해, 인코더는 샴(Siamese) 방식으로 정보를 처리한다. ($\sigma$는 모든 부분집합의 집합)
\[\begin{equation} F^1 = \textrm{Encoder}(I^1, \Omega_1), \quad F^2 = \textrm{Encoder}(I^2, \Omega_2) \end{equation}\]디코더
마찬가지로, 네트워크에는 각각 대응하는 head를 가진 두 개의 디코더가 있으며, 하나는 $X^{1,1}$을 예측하고 다른 하나는 $X^{2,1}$과 $X^{2,2}$를 추정한다. 두 디코더는 자신의 토큰과 상대 디코더의 이전 블록 출력 간의 cross-attention을 통해 통신한다. 각 디코더는 상대적 위치 $P_{12}$를 추가 입력으로 받을 수도 있고 받지 않을 수도 있다 (\(\Omega_D \in \sigma (P_{12})\)).
\[\begin{aligned} G_i^1 &= \textrm{DecoderBlock}_i^1 (G_{i-1}^1, G_{i-1}^2, \Omega_D) \\ G_i^2 &= \textrm{DecoderBlock}_i^2 (G_{i-1}^2, G_{i-1}^1, \Omega_D) \end{aligned}\]각 branch에서 $B$개의 디코더 블록을 통과한 후, head는 pointmap과 pointmap에 대한 confidence map을 예측한다.
\[\begin{aligned} X^{1,1}, C^{1,1} &= \textrm{Head}^1 (G_B^1) \\ X^{2,1}, C^{2,1}, X^{2,2}, C^{2,2} &= \textrm{Head}^1 (G_B^1) \end{aligned}\]DPT head를 사용하는 DUSt3R와 달리, Pow3R는 효율적이고 비슷한 성능을 내는 linear head를 두 head에 사용하였다.
3D Regression Loss
DUSt3R를 따라, 실제 pointmap과 예측된 pointmap 간의 거리를 scale-invariant 방식으로 최소화하도록 모델을 학습시켜, 모델이 다양한 스케일의 여러 데이터셋에서 학습할 수 있도록 한다. 픽셀 $(i, j)$에서 예측된 pointmap과 실제 pointmap \(\hat{X}^{n,m}\) 간의 regression loss는 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L}_{i,j}^\textrm{regr} (n,m) = \left\| \frac{X_{i,j}^{n,m}}{z_m} - \frac{\hat{X}_{i,j}^{n,m}}{\hat{z}_m} \right\| \\ \textrm{where} \; z_1 = \textrm{norm} (X^{1,1} \cup X^{2,1}), \; z_2 = \textrm{X}^{2,2} \end{equation}\]($\textrm{norm}(\cdot)$은 유효한 픽셀들에 대한 3D 포인트의 평균 거리)
Confidence-aware loss
모델은 각 픽셀 $(i, j)$의 신뢰 수준 $C_{i,j}^{n,m}$를 예측하는 방법을 공동으로 학습한다. 주어진 pointmap $X^{n,m}$에 대한 confidence-aware regression loss는 confidence map으로 가중된 \(\mathcal{L}^\textrm{regr}\)로 표현할 수 있다.
\[\begin{equation} \mathcal{L}^\textrm{conf} (n,m) = \sum_{i,j \in \mathcal{D}} C_{i,j}^{n,m} \mathcal{L}_{i,j}^\textrm{regr} (n,m) - \alpha \log C_{i,j}^{n,m} \end{equation}\]($\alpha = 0.2$)
이 loss는 예측이 어려운 영역에서 정확하지 않을 때 모델에 미치는 영향을 줄여 모델이 외삽하도록 유도한다. 최종 loss는 다음과 같다.
\[\begin{equation} \mathcal{L} = \mathcal{L}^\textrm{conf}(1,1) + \mathcal{L}^\textrm{conf}(2,1) + \beta \mathcal{L}^\textrm{conf}(2,2) \end{equation}\]($\beta = 1.0$)
2. Adding Versatile Conditioning
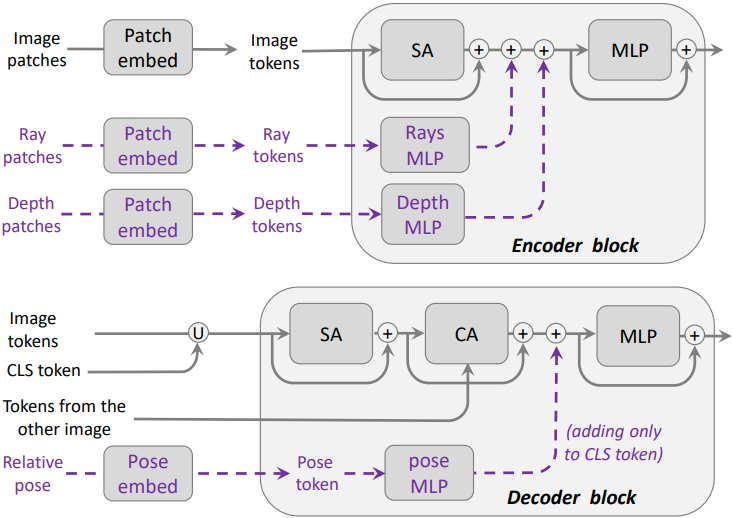
보조 정보에 대한 지식은 test-time의 3D 예측을 크게 향상시킬 수 있다. 본 모델은 최대 5가지의 서로 다른 모달리티, 즉 두 개의 intrinsic $K_1$, $K_2$, 각 이미지에 대한 depth map $D_1$, $D_2$, 상대적 포즈 $P_{12}$를 활용한다. 이를 기반으로 출력을 컨디셔닝하기 위해, 먼저 전용 MLP를 사용하여 보조 정보를 임베딩한 다음 파이프라인의 여러 지점에 이러한 임베딩을 삽입한다.
저자들은 두 가지 옵션을 논의하였다.
- embed: 표준 positional embedding과 마찬가지로 첫 번째 transformer 블록 앞의 토큰 임베딩에 보조 임베딩을 더한다.
- inject-n: 각 모달리티에 대한 전용 MLP를 $n$개의 transformer 블록에 삽입한다.
실험 결과 ‘inject-1’이 ‘embed’보다 약간 더 나은 성능을 보였으며, n > 1인 ‘inject-n’도 마찬가지이다.
Intrinsics
다음으로, intrinsic 행렬 $K \in \mathbb{R}^{3 \times 3}$에서 카메라 광선을 생성하여 RGB 픽셀과 광선 간의 직접적인 대응 관계를 설정한다. 픽셀 위치 $(i, j)$의 광선은 $K^{−1} [i,j,1]$로 계산되고 현재 카메라 포즈에 대한 해당 픽셀의 시야 방향을 인코딩한다. 이를 통해 non-centered crop을 잠재적으로 처리하고 더 높은 이미지 해상도에서 추론을 수행할 수 있다. RGB 입력과 마찬가지로 광선을 patchify하고 임베딩하여 인코더에 제공한다.
Depth map / 포인트 클라우드
Depth map $D$와 sparsity mask $M$이 주어지면 먼저 $D^\prime = D/\textrm{norm}(D)$로 정규화하여 모든 깊이 범위를 처리한다. RGB 및 광선의 경우, $[D^\prime, M] \in \mathbb{R}^{W \times H \times 2}$를 patchify하고 패치 임베딩을 계산한 다음 인코더에 입력한다. 깊이와 유효 마스크를 함께 patchify하면 모든 수준의 sparsity를 처리할 수 있다.
카메라 포즈
상대적 포즈 $P_{12} = [R_{12} \vert t_{12}]$가 주어지면 출력에 스케일이 지정되지 않았으므로 translation scale을 \(t_{12}^\prime = t_{12} / \| t_{12} \|\)로 정규화한다. Depth map이나 카메라 intrinsic과 달리 카메라 포즈는 dense한 픽셀 맵으로 표현할 수 없다. 따라서 카메라 포즈는 두 이미지 사이의 전체 픽셀에 영향을 미치므로 임베딩은 두 디코더의 글로벌 CLS 토큰에 더해진다.
3. Downstream Tasks
Depth map
Pointmap 표현에서 $X^{1,1}$과 $X^{2,2}$의 $z$축은 각각 첫 번째와 두 번째 이미지의 depth map에 직접 대응된다. DUSt3R는 $X^{1,1}$만 출력하므로 $(I^1, I^2)$와 $(I^2, I^1)$ 쌍의 두 번의 forward pass로 두 depth map을 모두 추출한다.
고해상도 처리

DUSt3R의 한계는 특정 해상도에 대해 학습되었으며 더 높은 해상도로 일반화되지 않는다는 것이다. 간단한 해결책은 학습 중에 더 높은 해상도를 포함하는 것이지만, 많은 데이터셋이 고해상도 GT를 제공하지 않으며 학습 비용이 엄청나게 클 수 있다.
반대로 Pow3R는 crop의 카메라 intrinsic이 crop 위치 정보를 제공하므로 기본적으로 crop을 처리할 수 있다. 따라서 sliding window 방식으로 예측을 수행하여 간단한 스티칭으로 모든 해상도에 대한 예측을 생성할 수 있다. 각 crop에 대한 예측은 설계상 다른 스케일을 가질 수 있으며 직접 스티칭할 수 없지만, 겹쳐지는 영역에서 신뢰도를 기반으로 스케일을 계산하여 겹쳐지는 영역을 혼합한다.
초점 거리 추정
DUSt3R와 유사하게 강력한 Weiszfeld solver를 사용하여 pointmap $X^{1,1}$과 $X^{2,2}$에서 두 입력 이미지의 초점 거리를 복구할 수 있다. DUSt3R는 depth map 예측과 마찬가지로 두 번째 이미지의 초점 거리를 계산하기 위해 $(I^2, I^1)$을 추론해야 하는 반면, Pow3R은 한 번의 pass에서 이를 예측한다.
상대적 포즈 추정
Pow3R는 두 개의 다른 카메라 좌표에서 두 번째 이미지의 pointmap을 예측하므로 $X^{2,2}$와 $X^{2,1}$ 사이의 스케일링된 상대적 포즈 $P^\ast = [R^\ast \vert t^\ast]$를 얻기 위해 Procrustes alignment로 상대적 포즈를 직접 예측한다.
\[\begin{equation} R^\ast, t^\ast = \underset{\sigma, R, t}{\arg \min} \sum_{i,j} \sqrt{C_{i,j}^{2,2} C_{i,j}^{2,1}} \| \sigma (RX_{i,j}^{2,2} + t) - X_{i,j}^{2,1} \|^2 \end{equation}\]Procrustes alignment는 노이즈와 outlier에 민감하지만, PnP를 사용한 RANSAC과 비슷한 성능을 보이면서 훨씬 더 빠르다.
글로벌 정렬
네트워크 $\mathcal{F}$는 이미지 쌍에 대한 pointmap을 예측한다. 모든 예측을 동일한 월드 좌표계에서 정렬하기 위해, 모든 쌍별 예측과 일치하는 카메라별 intrinsic, depth map, 포즈를 찾기 위해 글로벌 에너지 함수를 최소화하는 DUSt3R의 글로벌 정렬 알고리즘을 사용한다.
Experiments
- 데이터셋: Habitat, MegaDepth, ARKitScenes, Static Scenes 3D, BlendedMVS, ScanNet++, Co3Dv2, Waymo (총 850만 개의 이미지 쌍)
- 학습 디테일
- 보조 정보
- 균일한 확률로 모달리티 개수 $m$을 선택한 후, $m$개의 모달리티를 랜덤하게 선택
- Depth map은 랜덤하게 sparsify
- Intrinsic은 50% 확률로 non-centered crop을 수행
- GPU: A100 8개
- 먼저 3일 동안 224px 해상도로 학습시킨 후, 2일 동안 가변 종횡비의 512px로 fine-tuning
- 보조 정보
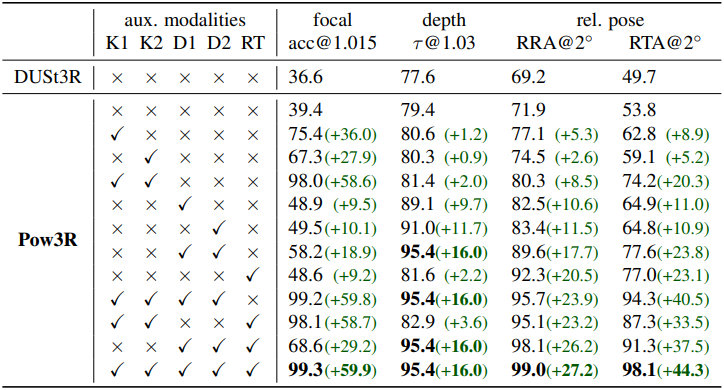
1. Guiding the output prediction
다음은 보조 정보에 따른 성능을 비교한 표이다.
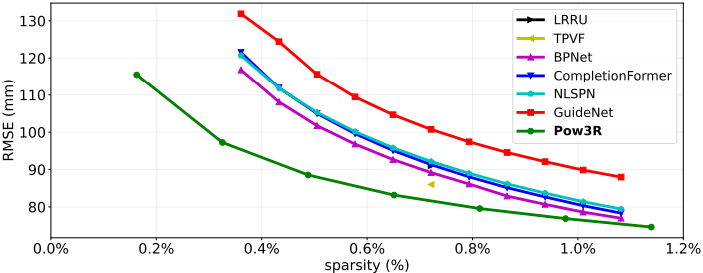
다음은 depth completion에 성능을 다른 방법들과 비교한 그래프이다. (NYUd)
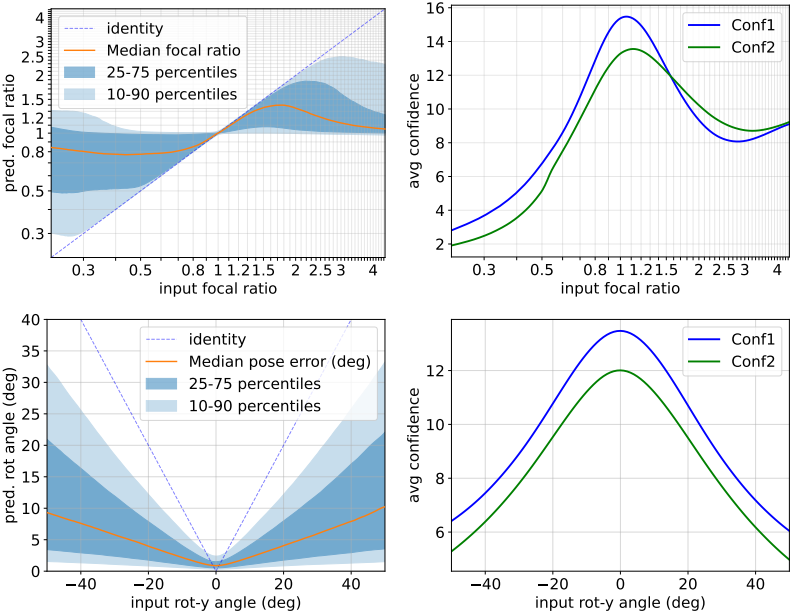
다음은 (위) 잘못된 초점 거리와 (아래) 잘못된 상대적 포즈에 모델이 어떻게 반응하는 지를 나타낸 그래프이다.
2. Multi-View Depth Estimation
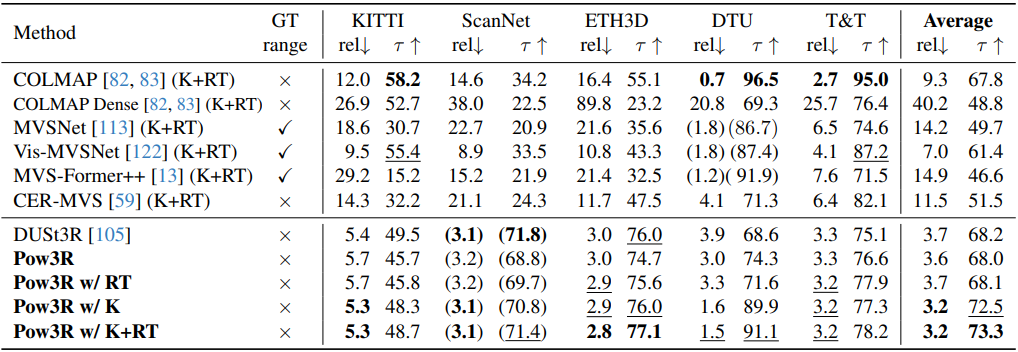
다음은 멀티뷰 깊이 추정에 대한 비교 결과이다.
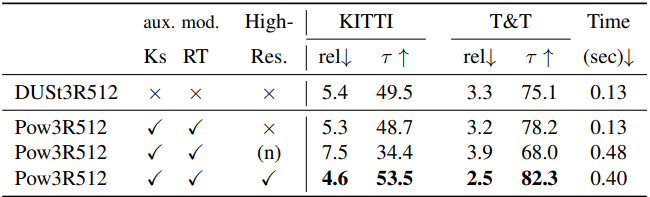
다음은 고해상도에서의 멀티뷰 깊이 추정 결과이다. (n)은 downsampling 없이 고해상도 이미지를 바로 넣은 경우.
3. Multi-View Stereo
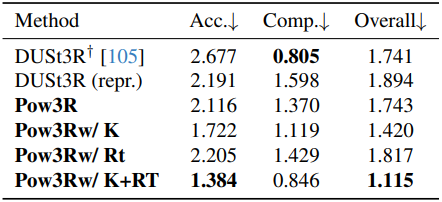
다음은 MVS에 대한 비교 결과이다.
4. Multi-View Pose estimation
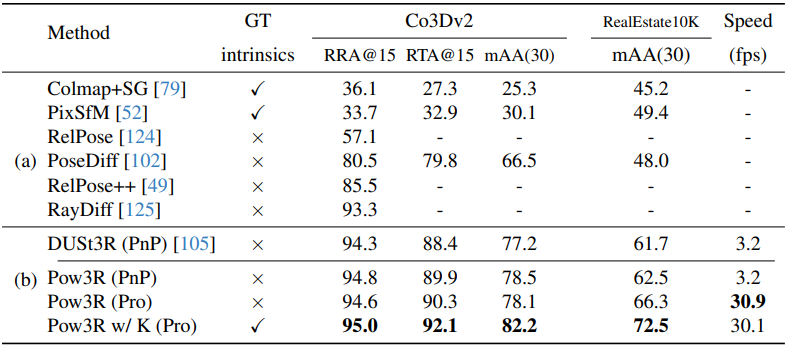
다음은 멀티뷰 포즈 추정에 대한 비교 결과이다.
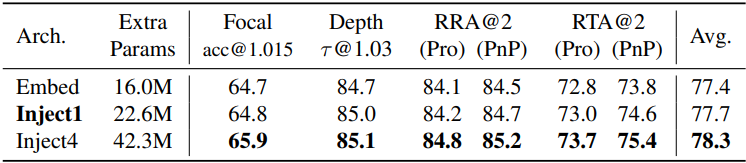
5. Architecture ablation
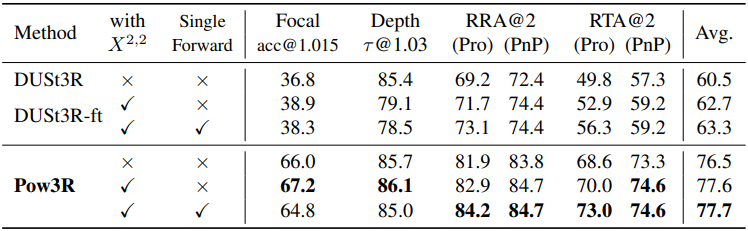
다음은 $X^{2,2}$ 추정에 대한 ablation 결과이다.
다음은 아키텍처에 대한 ablation 결과이다.