[논문리뷰] PoseTraj: Pose-Aware Trajectory Control in Video Diffusion
CVPR 2025. [Paper] [Page] [Github]
Longbin Ji, Lei Zhong, Pengfei Wei, Changjian Li
University of Edinburgh | NTU
20 Mar 2024

Introduction
본 논문은 잠재적인 물체 회전을 포함하는 궤적을 이용하여 동영상 생성을 제어하는 문제를 다룬다. 궤적 기반의 모션 제어는 대상 물체가 지정된 경로를 정확하게 따라가도록 요구하며, 생성된 동영상의 시간적 일관성과 사실성을 유지하여야 한다. 기존 연구들은 물체의 6D 포즈 (위치 및 방향)의 잠재적 변화를 고려하지 않고 물체가 2차원 이미지 공간에서 궤적을 따르도록 제한하였다. 결과적으로, 이러한 연구들은 평행 이동에서는 우수한 성능을 보이지만, 궤적이 암시적으로 회전을 수반하는 경우 물체를 제어하지 못한다. 이러한 제한은 두 가지 주요 요인에서 발생한다.
- 수집된 동영상 데이터셋에서 물체의 움직임은 거의 평행 이동이고 회전은 드물며 자동으로 주석을 달기 어렵다.
- 픽셀 공간에서 2D 궤적과 물체로부터 잠재적인 회전을 추론하는 것은 본질적으로 적합하지 않다.
본 논문에서는 PoseTraj라는 새로운 궤적 기반 모션 제어 프레임워크를 제시하였다. 이 프레임워크는 궤적의 잠재적 회전을 감지하고 그에 따른 제어를 수행할 수 있다. 궤적의 회전을 감지하는 능력은 2단계 사전 학습 파이프라인에서 비롯되며, 합성 데이터셋인 PoseTraj-10K를 사용한다. 이 데이터셋은 회전을 포함하는 2,000개의 서로 다른 물체에 대한 다양한 궤적을 가진 10,000개 이상의 동영상과 물체의 3D bounding box로 구성되었으며, 오픈 월드 동영상에서 궤적과 3D bounding box를 정확하게 추정하는 어려움을 해결하였다.
첫 번째 단계에서는 PoseTraj-10K로 모델을 사전 학습하여 외관 디테일을 강조하지 않고 궤적을 따라 정확한 3D bounding box를 가진 동영상 프레임을 생성한다. 3D bounding box 생성을 도입하여 모델이 궤적을 따라 물체 위치를 이해하고 잠재적인 회전 변화를 인지하도록 지원한다. 두 번째 단계에서는 물체 엔티티와 포즈에 대한 학습된 지식을 바탕으로 물체의 외관을 개선하는 데 집중하여 모델을 사전 학습시킨다. 두 단계의 사전 학습을 통해 모델은 잠재적인 회전을 인식하고 궤적을 따라 물체를 안정적으로 유지할 수 있다. 마지막으로, 실제 동영상 데이터셋에 대해 camera-disentangled fine-tuning을 수행하여 실제 동영상에 대해 모델의 일반화를 향상시킨다.
PoseTraj-10K Dataset Construction
궤적 기반 동영상 생성 모델을 학습시키려면 쌍으로 구성된 데이터, 즉 명확하게 식별 가능한 이동하는 물체들과 물체들의 정확한 궤적이 포함된 고품질 동영상이 필요하다.
그러나 오픈 도메인 동영상에서 이러한 데이터를 얻는 것은 몇 가지 중요한 과제를 안고 있다.
- 일반적으로 필터링된 동영상 데이터셋에서는 넓은 범위의 회전과 같은 복잡한 모션이 드물며, point-tracking이나 flow-matching을 사용하여 정확하게 주석을 달기 어렵다.
- 물체의 큰 움직임은 카메라 모션과 밀접하게 결합되는 경우가 많아 물체의 움직임과 카메라 모션을 분리하기가 어렵다.
결과적으로, 현재의 포즈 추정 방법으로는 오픈 도메인 동영상에서 움직이는 물체의 정확한 6D 포즈를 얻는 것이 여전히 불가능하다.
따라서 저자들은 세 가지 주요 장점을 제공하는 합성 데이터셋 PoseTraj-10K를 구성했다.
- 다양하고 포괄적인 범위의 물체를 제공하여 특히 복잡한 기하학적 구조와 광범위한 회전에 대한 robust한 모션 이해를 향상시킨다.
- 다양하고 정확한 궤적을 생성할 수 있어 카메라 모션의 간섭 없이 물체 움직임의 일관성을 보장한다.
- 제어된 렌더링을 통해 사전 학습 과정에서 중간 학습 신호 역할을 하는 정확한 3D bounding box 파라미터를 쉽게 얻을 수 있다.
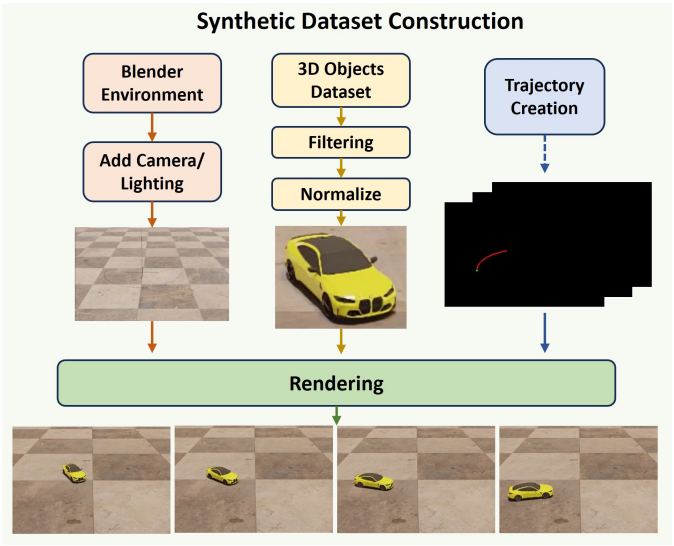
위 그림은 Blender에서 구현한 렌더링 파이프라인을 보여준다. 먼저, 사실적인 가상 장면을 설정하고 Objaverse에서 2,000개의 고품질 3D 모델을 샘플링했다. 선택된 모델의 품질을 보장하기 위해 GPT4v를 사용하여 지나치게 복잡하거나 흔하지 않은 물체를 필터링한 후, 수동으로 선택하여 고품질의 일상 물체를 가장 잘 표현하는 상위 2,000개의 모델을 얻었다. 각 모델은 정규화되며, 회전 각도, 궤적 모양, 길이가 랜덤하게 지정된 고유한 랜덤 궤적이 할당된다. 애니메이션 과정에서 3D 모델은 회전 중심을 유지하면서 지정된 궤적을 따라가므로 최종 렌더링에서 회전 중심의 움직임이 가능하다.
Method
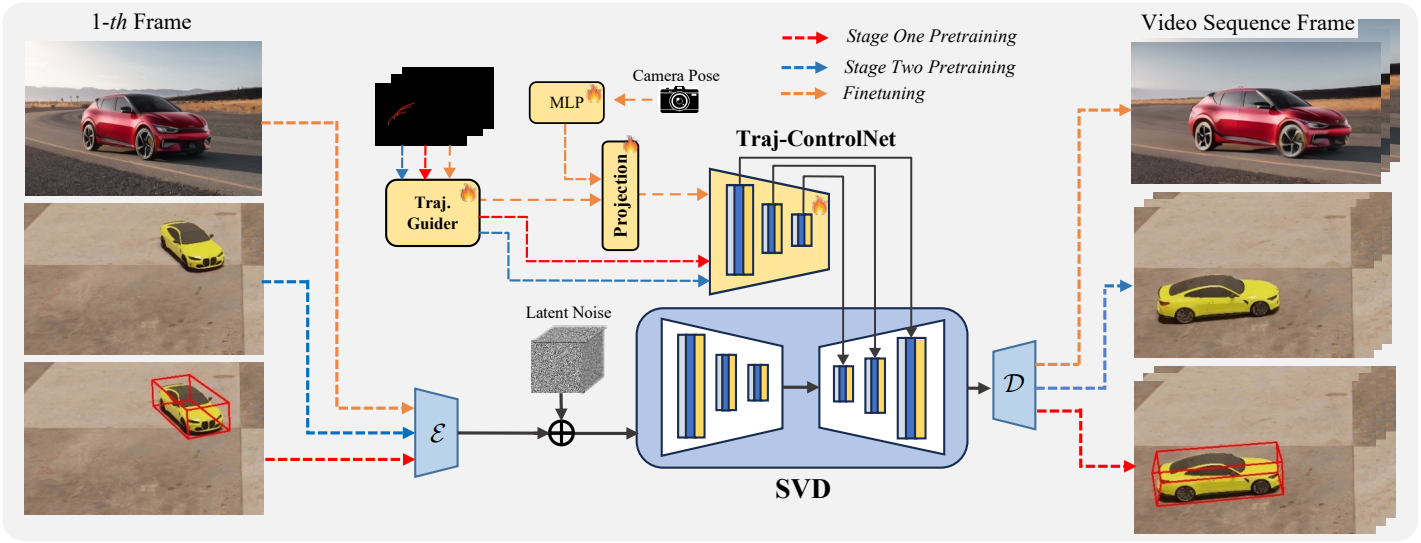
- 입력
- 전경 물체를 포함하는 이미지 $\textbf{I} \in \mathbb{R}^{H \times W \times 3}$
- 선분 이미지의 집합 \(\textbf{I}_\textbf{tr} = \{I_\textrm{tr}^i\}_{i=1}^L\)로 그려지는 궤적 \(\textbf{tr} = \{(x_i, y_i)\}_{i=1}^L\)
- 출력
- 물체가 궤적을 정확하게 따르는 동시에 일관되고 자연스러운 외관을 유지하는 동영상 프레임 시퀀스 \(\{f_i\}_{i=1}^L\)
본 논문은 사전 학습된 diffusion model을 가이드하는 ControlNet의 성공에 영감을 받아, SVD의 인코더 블록의 학습 가능한 복사본으로 구성된 Traj-ControlNet을 설계하였다. 일련의 궤적 이미지 \(\textbf{I}_\textbf{tr}\)이 주어지면, 3D ConvNet으로 궤적 feature를 인코딩한 다음 Traj-ControlNet에 입력하여 SVD의 residual feature를 예측하여 생성된 동영상이 궤적을 따르도록 한다.
1. Two-stage Pose-aware Pretraining
본 논문은 2D 픽셀 공간 내에서 잠재적인 6D 포즈 변화를 감지하는 모델의 능력을 향상시키기 위해, 정확한 위치 및 포즈 정보를 제공하는 3D bounding box를 주요 학습 신호로 선택했으며, 3D bounding box 생성을 중간 학습 신호로 통합하는 새로운 2단계 사전 학습 파이프라인을 제안하였다. 두 사전 학습은 PoseTraj10K 합성 데이터셋을 기반으로 한다.
1단계: 3D bounding box 기반 위치 추정
각 동영상 프레임에 대해 3D bounding box 파라미터를 개별적으로 회귀 분석하고 물체의 외형을 생성하는 대신, 물체와 함께 이미지 공간에 3D bounding box를 동시에 생성한다. 이를 위해 데이터셋의 한 데이터 예제를 기반으로, 먼저 이미지 위의 픽셀 공간에서 3D bounding box를 렌더링하여 bounding box를 얻는다. 다른 프레임에도 동일한 렌더링 프로세스를 적용하여 bounding box가 추가된 동영상을 얻는다. 이러한 공동 생성 프로세스는 모델이 궤적을 따라 물체의 위치를 더 잘 이해하고 잠재적인 회전 변화를 인식하도록 도와준다.
2단계: 물체 중심 재구성
실제 적용에서는 생성된 동영상에 bounding box가 필요하지 않다. 또한, 1단계에서는 명시적인 bounding box 제약 조건을 사용하여 모델이 물체 엔티티와 포즈를 학습하지만, 생성된 물체에는 외관 디테일이 부족하다. 따라서 2단계에서는 bounding box 생성을 배제하고 3D bounding box 학습을 제거할 상태로 모델을 fine-tuning하여 물체의 외관을 개선한다.
본 논문의 재구성 주입 방식은 두 가지 주요 이점을 제공한다.
- Bounding box는 픽셀 수준의 학습 대상 역할을 함으로써 연속적인 3D 인식을 명확하게 향상시킨다.
- 이러한 학습 대상은 재구성 대상을 변경하는 것만으로 쉽게 제거할 수 있으며, 이를 통해 학습-inference 불일치를 완화할 수 있다.
2. Camera-disentangled Finetuning
두 단계의 사전 학습 후, 모델은 궤적을 따라 물체의 형태와 세부적인 모습을 유지하면서 잠재적인 회전을 인식하는 법을 학습한다. 그러나 사전 학습된 모델을 실제 동영상에 적용하는 것은 여전히 중요한 과제이다. 카메라가 고정된 합성 데이터셋과 달리, 실제 동영상은 예측 불가능하고 불규칙적인 카메라 모션을 보이는 경우가 많다. 카메라 모션과 물체의 움직임이 구분되지 않으면 물체 추적에 오차가 발생할 수 있다. 따라서 본 논문에서는 능동적인 물체의 움직임과 수동적인 카메라 모션을 구분하기 위해 추가적인 카메라 모션 정보를 모델에 통합하는 camera-disentangled fine-tuning을 도입하였다.
구체적으로, 실제 동영상 데이터셋인 VIPSeg에 모션 궤적과 프레임당 카메라 포즈 \(\{\textrm{Cam}^i\}_{i=1}^L\)를 주석으로 추가한다. 카메라 포즈를 MLP layer를 통과시킨 다음 궤적 feature와 concat하여 추가 입력으로 통합한다. Concat된 feature는 초기화되지 않은 MLP projection layer에 공급되고 Traj-ControlNet에 추가 입력된다. Inference 시에는 카메라 포즈 정보를 제공하기 어려우므로, 이 fine-tuning 단계에서 카메라 포즈를 50%로 제거하여 모델이 카메라 정보 없이 동영상을 생성할 수 있도록 한다. 이 접근 방식은 모델이 물체의 움직임과 카메라 모션을 구별하는 데 도움이 되므로 궤적 추적 정확도를 높이고 다양한 동영상 컨텍스트에서 robustness를 강화한다.
3. Training and Inference
MSE loss는 동영상 생성 학습에 일반적으로 사용되며, 그 목적은 timestep $t$의 latent $x_t$의 실제 noise $\epsilon$과 예측된 noise $\epsilon_\theta$ 사이의 차이를 최소화하는 것이다. 두 사전 학습 단계와 fine-tuning 단계 모두 동일한 MSE loss를 활용하지만, 조건 $C^i$에 차이가 있다.
\[\begin{equation} \mathcal{L}_\textrm{MSE} = \mathbb{E}_{x_t, \epsilon} \left[ \sum_{i=1}^L \| \epsilon - \epsilon_\theta (x_t, t, C^i) \|_2^2 \right] \\ \textrm{where} \quad C^i = \begin{cases} \{ I_\textrm{tr}^i, \textbf{I}_\textrm{bbox} \} & \textrm{stage 1} \\ \{ I_\textrm{tr}^i, \textbf{I}\} & \textrm{stage 2} \\ \{ I_\textrm{tr}^i, \textbf{I}, \textrm{Cam}^i \} & \textrm{fine-tuning} \end{cases} \end{equation}\]Spatial enhancement loss
모든 프레임의 오차를 단순히 집계하는 것은 개별 프레임의 공간적 재구성 정확도를 간과하여 큰 회전의 움직임에서 물체 엔티티가 붕괴될 수 있다. 각 프레임당 짧은 궤적 세그먼트는 개별 프레임 내에서 정확한 위치 정보를 제공하므로, 프레임당 이미지를 재구성하여 공간적 일관성을 향상시키기 위해 추가적인 spatial enhancement loss를 도입한다. 구체적으로, $j$번째 프레임의 궤적 \(I_\textrm{tr}^j\)를 무작위로 샘플링하여 Traj-ControlNet 조건으로 사용한다. 해당 latent $x_{t,j}$와 초기 프레임 $\textbf{I}$ (1단계의 경우 \(\textbf{I}_\textrm{bbox}\))로부터, 이 특정 프레임에 대한 타겟 noise \(\epsilon_j\)를 생성하도록 모델을 학습시키는 것이 목표이다.
\[\begin{equation} \mathcal{L}_\textrm{SPA} = \| \epsilon_j - \epsilon_\theta (x_{t,j}, t, C^j) \|_2^2, \quad j \in [1, L] \end{equation}\]Backpropagation에서는 spatial layer들만 업데이트되므로, 프레임별 공간 정확도에 초점을 맞춘 fine-tuning이 가능하다.
전반적으로, 각 단계에 대한 프레임워크의 loss function은 다음과 같이 정의된다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_\textrm{MSE} + \lambda_\textrm{SPA} \mathcal{L}_\textrm{SPA} \end{equation}\]Inference
Inference 시에 사용자는 입력 이미지가 주어지면 회전 또는 이동 가능한 사용자 지정 궤적을 자유롭게 그릴 수 있으며, 이 궤적에 따라 모델은 동영상을 생성한다. 본 논문의 모델은 두 개 이상의 궤적을 지원하며, 사용자는 기존 동영상에서 추출한 카메라 포즈를 제공하여 카메라 모션을 제어할 수 있다.
Experiments
- 구현 디테일
- base model: SVD
- 320$\times$576, 14프레임
- 모션 궤적 추출: CoTracker2
- 카메라 포즈 추출: DROID-SLAM
- GPU: NVIDIA A100 1개
- batch size: 1
- optimizer: AdamW
- learning rate: $10^{-5}$
- step: 5천 / 5천 / 1만
1. Comparison
다음은 SOTA 방법들과 궤적 정확도 및 동영상 품질을 비교한 표이다.

다음은 VIPSeg에서의 제어 결과를 비교한 것이다.

다음은 DAVIS에서의 제어 결과를 비교한 것이다. (out-of-distribution)

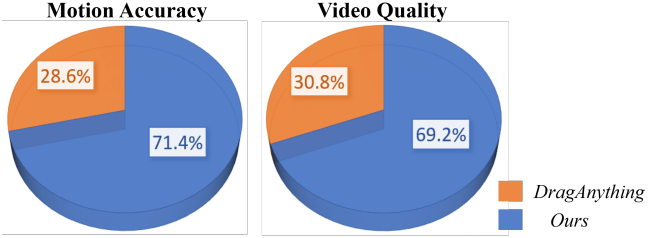
다음은 user study 결과이다.
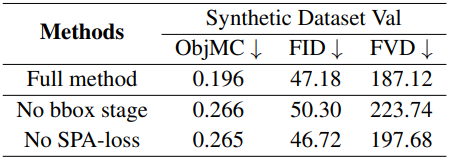
2. Ablation Study
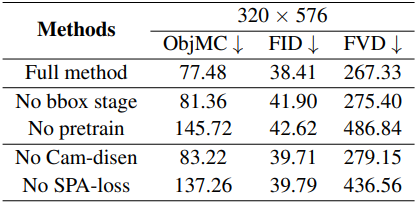
다음은 (왼쪽) 현실 test set과 (오른쪽) 합성 validation set에서의 ablation 결과이다.
다음은 합성 데이터셋에 대한 ablation 결과를 시각화한 것이다.
