[논문리뷰] MetaFormer Is Actually What You Need for Vision (PoolFormer)
CVPR 2022. [Paper] [Github]
Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, Shuicheng Yan
Sea AI Lab | National University of Singapore
22 Nov 2021
Introduction
Transformers는 컴퓨터 비전 분야에서 많은 관심과 성공을 거두었다. 순수 Transformer를 이미지 분류 작업에 적용하는 ViT의 중요한 연구 이후, 다양한 컴퓨터 비전 task에서 더욱 개선하고 유망한 성능을 달성하기 위해 많은 후속 모델이 개발되었다.
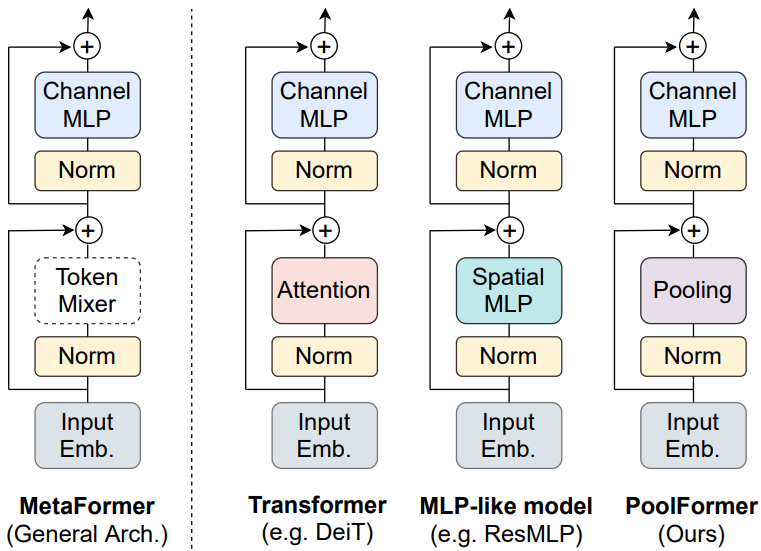
위 그림에 표시된 Transformer 인코더는 두 가지 구성 요소로 구성된다. 하나는 토큰 간 정보를 혼합하기 위한 attention 모듈이며 이를 token mixer라고 부른다. 다른 구성 요소에는 channel MLP와 residual connection과 같은 나머지 모듈이 포함된다. Attention 모듈을 특정 token mixer로 간주함으로써 위 그림에 표시된 것처럼 전체 Transformer를 token mixer가 지정되지 않은 일반 아키텍처 MetaFormer로 추가로 추상화된다.
Transformers의 성공은 오랫동안 attention 기반 token mixer 덕분이었다. 이러한 공통된 믿음을 바탕으로 ViT를 개선하기 위해 attention 모듈의 다양한 변형이 개발되었다. 그러나 최근 연구에서는 attention 모듈을 token mixer인 spatial MLP로 완전히 대체하고 파생된 MLP-like 모델이 이미지 분류 벤치마크에서 쉽게 경쟁력 있는 성능을 얻을 수 있음을 발견했다. 후속 연구들에서는 데이터 효율적인 학습과 특정 MLP 모듈 디자인을 통해 MLP-like 모델을 더욱 개선하고 ViT에 대한 성능 격차를 점차적으로 좁히고 token mixer로서 주목받는 지배력에 도전하였다.
최근의 일부 접근 방식에서는 MetaFormer 아키텍처 내에서 다른 유형의 token mixer를 탐색하고 고무적인 성능을 보여주었다. 예를 들어 attention을 푸리에 변환으로 대체해도 바닐라 Transformer 정확도의 약 97%를 달성한다. 이 모든 결과를 종합해 보면 모델이 MetaFormer를 일반 아키텍처로 채택하는 한 유망한 결과를 얻을 수 있을 것으로 보인다. 따라서 저자들은 특정 token mixer와 비교할 때 MetaFormer가 모델이 경쟁력 있는 성능을 달성하는 데 더 필수적이라고 가정하였다.
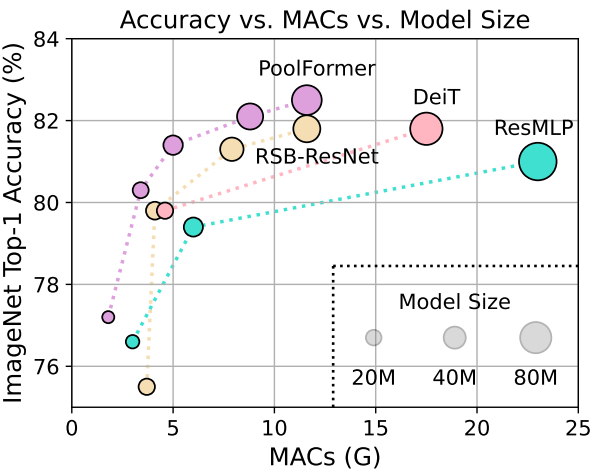
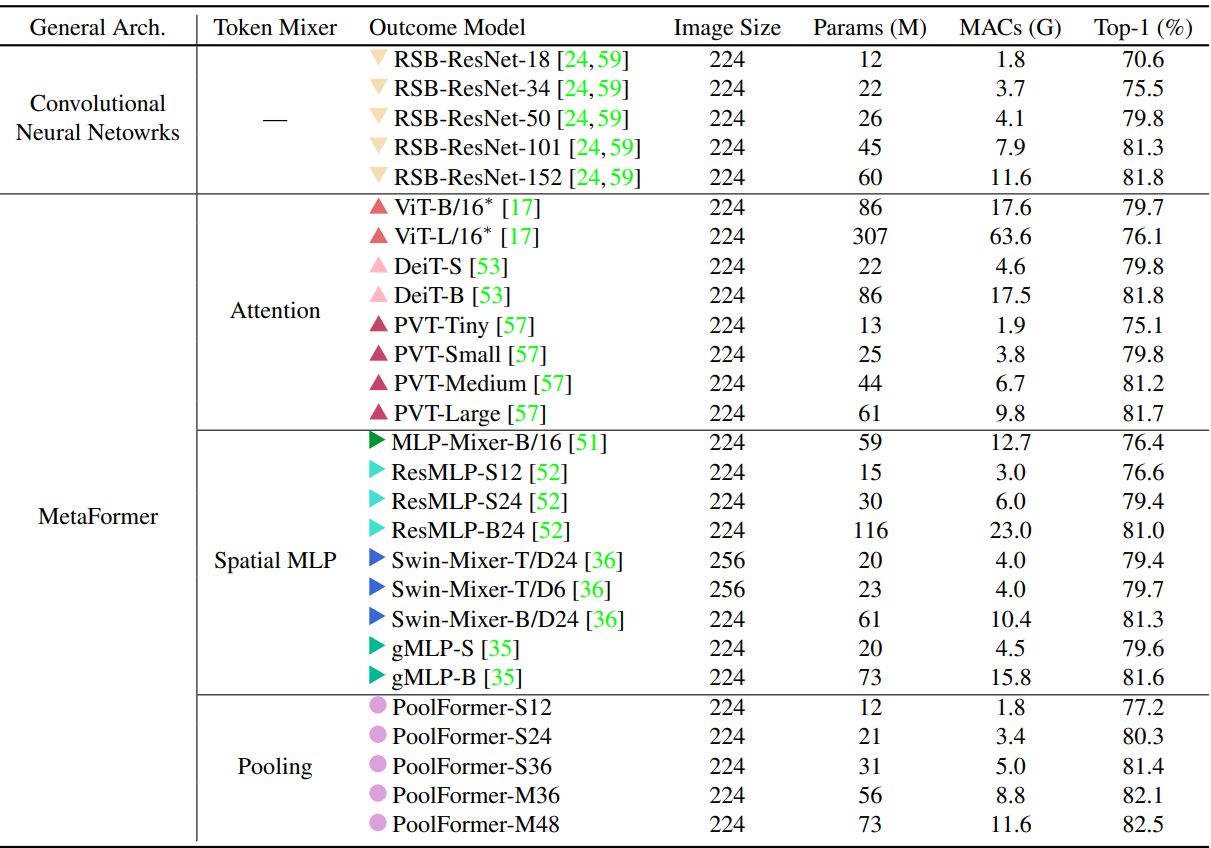
이 가설을 검증하기 위해 저자들은 매우 간단한 non-parametric 연산자인 pooling을 token mixer로 적용하여 기본적인 token 혼합만을 수행하였다. 놀랍게도 PoolFormer라고 불리는 이 파생 모델은 경쟁력 있는 성능을 달성하며 위 그래프에서 것처럼 DeiT와 ResMLP를 포함하여 잘 튜닝된 Transformer와 MLP-like 모델보다 지속적으로 성능이 뛰어나다. 보다 구체적으로, PoolFormer-M36은 ImageNet-1K 분류 벤치마크에서 82.1%의 top-1 정확도를 달성하여 잘 튜닝된 ViT/MLP-like baseline인 DeiTB/ResMLP-B24를 35%/52% 더 적은 파라미터와 50%/62% 더 적은 MAC 수로 0.3%/1.1% 정확도로 능가한다. 이러한 결과는 단순한 token mixer를 사용하더라도 MetaFormer가 여전히 유망한 성능을 제공할 수 있음을 보여준다. 따라서 본 논문은 MetaFormer가 특정 token mixer보다 경쟁력 있는 성과를 달성하는 데 더 필수적인 비전 모델에 대한 사실상의 필요라고 주장한다. 이는 token mixer가 중요하지 않다는 의미는 아니다. MetaFormer에는 여전히 추상화된 구성 요소가 있다. 이는 token mixer가 attention과 같은 특정 타입으로 제한되지 않음을 의미한다.
Method
1. MetaFormer
MetaFormer는 token mixer를 지정하지 않고 다른 구성 요소는 Transformer와 동일하게 유지되는 일반적인 아키텍처이다. 입력 $I$는 먼저 ViT에 대한 패치 임베딩과 같은 입력 임베딩으로 처리된다.
\[\begin{equation} X = \textrm{InputEmb} (I) \in \mathbb{R}^{N \times C} \end{equation}\]여기서 $X$는 시퀀스 길이가 $N$이고 임베딩 차원이 $C$인 임베딩 토큰이다. 그런 다음 임베딩 토큰은 반복되는 MetaFormer 블록에 공급되며, 각 블록에는 두 개의 residual sub-block이 포함된다. 구체적으로, 첫 번째 sub-block은 주로 토큰 간 정보를 전달하는 token-mixer를 포함하며 이 sub-block은 다음과 같이 표현될 수 있다.
\[\begin{equation} Y = \textrm{TokenMixer} (\textrm{Norm} (X)) + X \end{equation}\]여기서 $\textrm{Norm} (\cdot)$은 layer normalization 또는 batch normalization과 같은 정규화를 나타낸다. $\textrm{TokenMixer}(\cdot)$는 주로 토큰 정보를 혼합하는 모듈을 의미한다. 최근 ViT 모델이나 MLP-like 모델의 spatial MLP에서 다양한 attention 메커니즘을 통해 구현된다. 일부 token mixer는 attention과 같이 채널을 혼합할 수도 있지만 token mixer의 주요 기능은 토큰 정보를 전파하는 것이다.
두 번째 sub-block은 non-linear activation을 갖춘 2-layer MLP로 구성된다.
\[\begin{equation} Z = \sigma (\textrm{Norm} (Y) W_1) W_2 + Y \end{equation}\]여기서 $W_1 \in \mathbb{R}^{C \times rC}$와 $W_2 \in \mathbb{R}^{rC \times C}$는 MLP 확장 비율 $r$에 대한 학습 가능한 파라미터이다. $\sigma(\cdot)$는 GELU 또는 ReLU와 같은 non-linear activation function이다.
Instantiations of MetaFormer
MetaFormer는 token mixer의 구체적인 디자인을 지정하여 다양한 모델을 즉시 얻을 수 있는 일반적인 아키텍처를 설명한다. Token mixer가 attention 또는 spaital MLP로 지정되면 MetaFormer는 각각 Transformer와 MLP-like 모델이 된다.
2. PoolFormer
Transformer의 도입부터 많은 연구들이 attention에 많은 중요성을 부여하고 다양한 attention 기반 token mixer를 설계하는 데 중점을 두었다. 대조적으로, 일반적인 아키텍처, 즉 MetaFormer에 거의 관심을 기울이지 않았다.
본 논문은 이 MetaFormer 일반 아키텍처가 최근 Transformer와 MLP-like 모델의 성공에 주로 기여한다고 주장한다. 이를 시연하기 위해 저자들은 당황스러울 정도로 간단한 연산자인 pooling을 의도적으로 token mixer로 사용하였다. 이 연산자에는 학습 가능한 파라미터가 없으며 각 토큰이 근처 token feature를 평균적으로 집계하도록 한다.
본 논문은 비전 task를 대상으로 하기 때문에 입력이 채널 우선 데이터 형식, 즉 $T \in \mathbb{R}^{C \times H \times W}$라고 가정한다. Pooling 연산자는 다음과 같이 표현될 수 있다.
\[\begin{equation} T_{:, i, j}^\prime = \frac{1}{K \times K} \sum_{p, q = 1}^K T_{:, i+p-\frac{K+1}{2}, i+q-\frac{K+1}{2}} - T_{:, i, j} \end{equation}\]여기서 $K$는 pooling 크기이다. MetaFormer 블록에는 이미 residual connection이 있으므로 입력 자체의 뺄셈이 위 식에 추가된다. Pooling의 코드는 Algorithm 1에 나와 있다.

잘 알려진 바와 같이, self-attention과 spatial MLP는 혼합할 토큰 수에 비례하는 계산 복잡도를 갖는다. 더욱이 spatial MLP는 더 긴 시퀀스를 처리할 때 훨씬 더 많은 파라미터를 가져온다. 결과적으로 self-attention과 spatial MLP는 일반적으로 수백 개의 토큰만 처리할 수 있다. 대조적으로, pooling에는 학습 가능한 파라미터가 없이 시퀀스 길이에 선형적인 계산 복잡도가 필요하다. 따라서 저자들은 전통적인 CNN과 최근 계층적 Transformer 변형과 유사한 계층적 구조를 채택하여 pooling을 활용하였다.
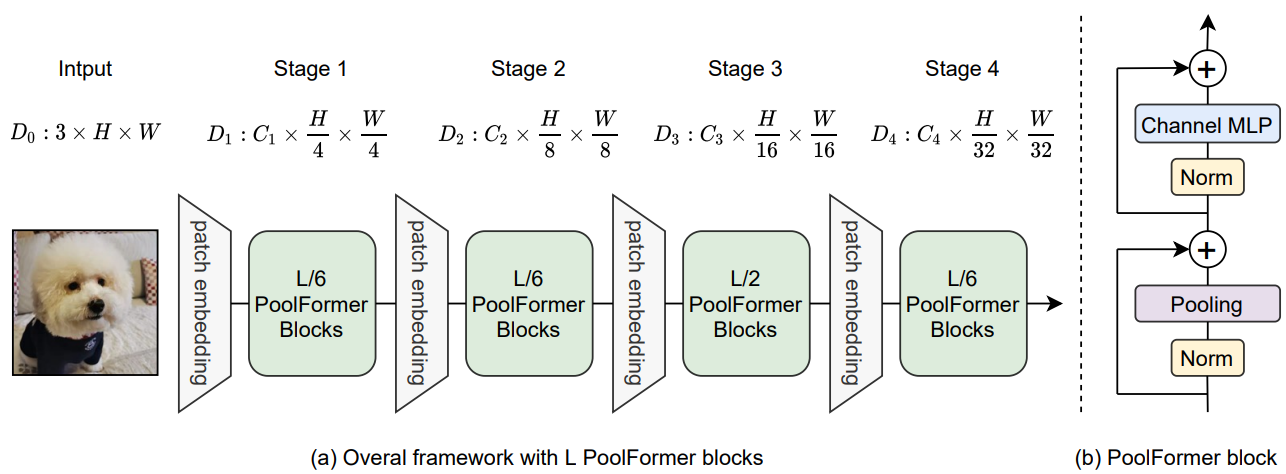
위 그림은 PoolFormer의 전체 프레임워크를 보여준다. 구체적으로 PoolFormer는 각각 $\frac{H}{4} \times \frac{W}{4}$, $\frac{H}{8} \times \frac{W}{8}$, $\frac{H}{16} \times \frac{W}{16}$, $\frac{H}{32} \times \frac{W}{32}$개의 토큰으로 구성된 4단계를 가지고 있다. 여기서 $H$와 $W$는 입력 이미지의 너비와 높이이다. 임베딩 차원에는 두 가지 그룹이 있다.
- 4단계의 각 임베딩 차원이 64, 128, 320, 512인 소형 모델
- 4단계의 각 임베딩 차원이 96, 192, 384, 768인 중간 크기 모델
총 $L$개의 PoolFormer 블록이 있다고 가정하면 단계 1, 2, 3, 4에는 각각 $L/6$, $L/6$, $L/2$, $L/6$개의 PoolFormer 블록을 포함한다. MLP 확장 비율은 4로 설정된다. 위의 단순 모델 스케일링 규칙에 따라 PoolFormer의 5가지 모델 크기를 얻었으며 해당 hyperparameter는 아래 표와 같다.
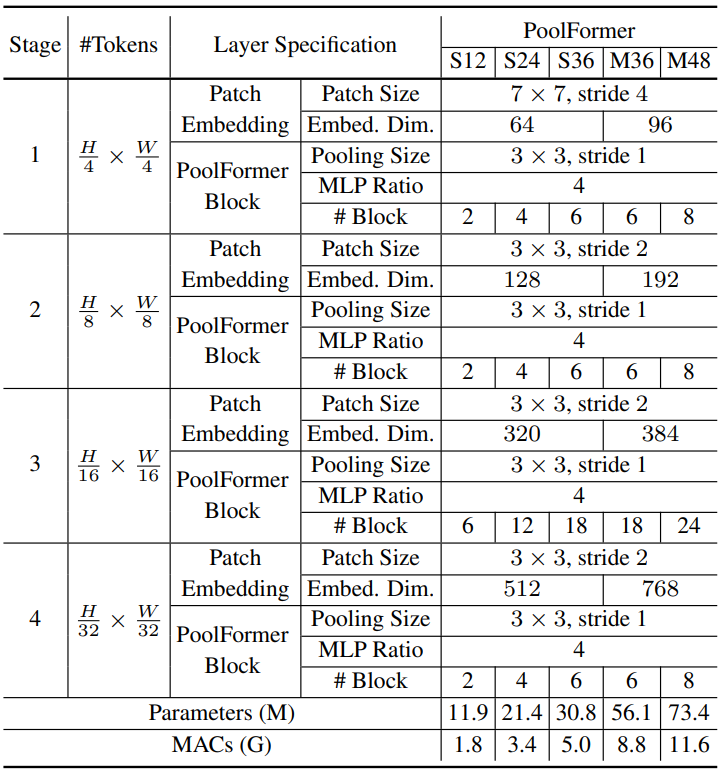
Experiments
1. Image classification
- 데이터셋: ImageNet-1K
- 구현 디테일
다음은 ImageNet-1K에 대한 분류 성능을 비교한 표이다.
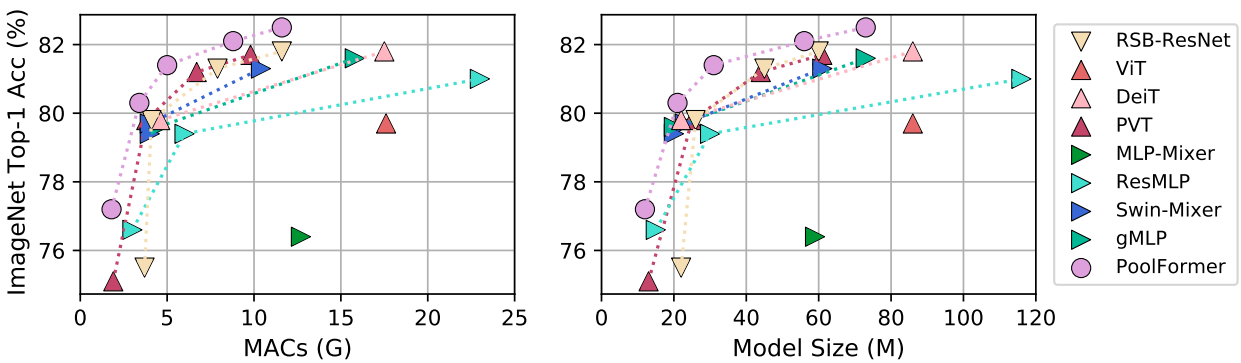
다음은 MAC과 모델 크기에 따른 ImageNet-1K top-1 정확도를 비교한 그래프이다.
2. Object detection and instance segmentation
- 데이터셋: COCO
- 구현 디테일
- backbone
- RetinaNet: object detection
- Mask R-CNN: object detection, instance segmentation
- 이미지 크기: 512$\times$512
- epoch: 12
- batch size: 16
- optimzer: AdamW
- weight decay: 0.05
- learning rate: $1 \times 10^{-4}$, polynomial decay schedule (0.9)
- backbone
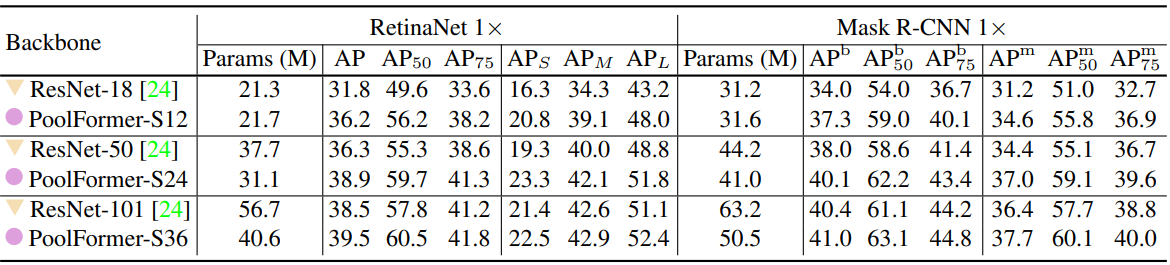
다음은 COCO val2017에서의 object detection과 instance segmentation 성능을 비교한 표이다.
3. Semantic segmentation
- 데이터셋: ADE20K
- 구현 디테일
- 이미지 크기: 512$\times$512
- iteration: 4만
- batch size: 32
- optimzer: AdamW
- weight decay: 0.05
- learning rate: $2 \times 10^{-4}$, polynomial decay schedule (0.9)
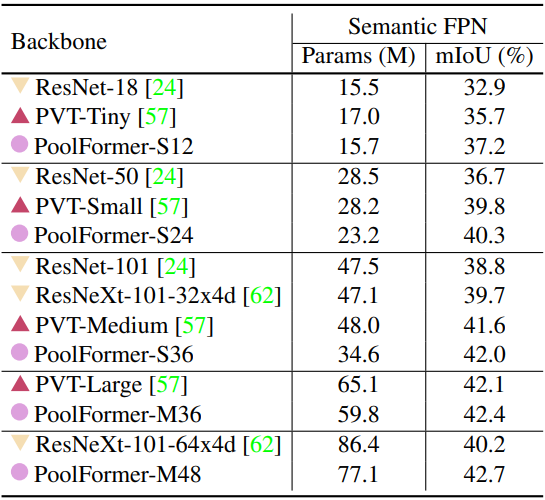
다음은 ADE20K validation set에서의 semantic segmentation 성능을 비교한 표이다.
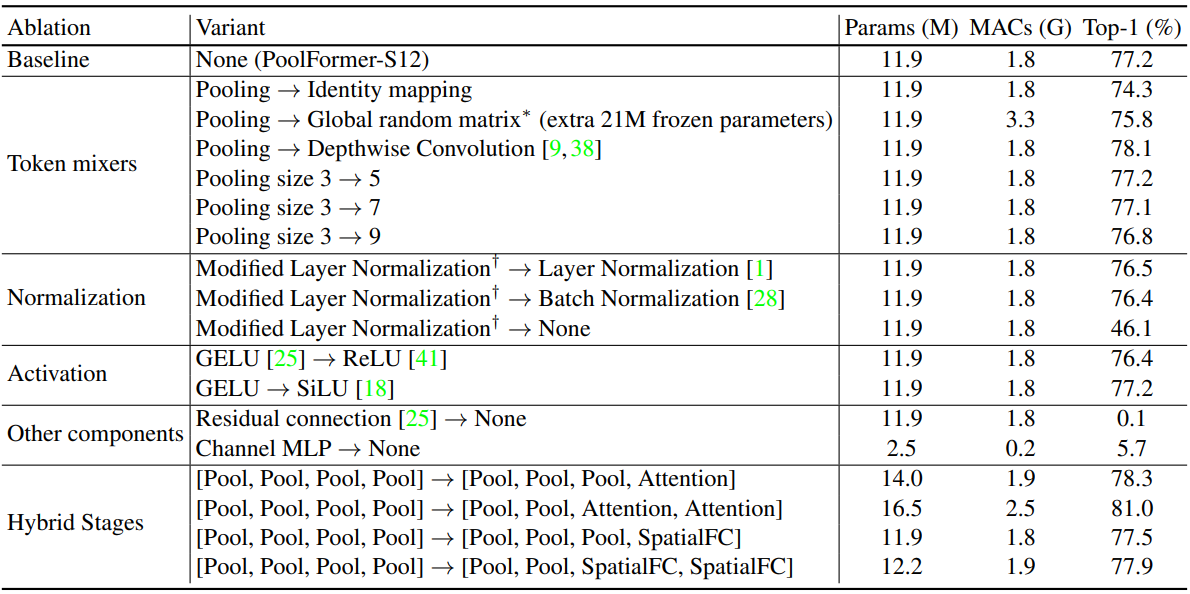
4. Ablation studies
다음은 PoolFormer에 대한 ablation 결과이다. (ImageNet-1K 분류 벤치마크)