[논문리뷰] PLADIS: Pushing the Limits of Attention in Diffusion Models at Inference Time by Leveraging Sparsity
ICCV 2025. [Paper] [Page] [Github]
Kwanyoung Kim, Byeongsu Sim
Samsung Research
10 Mar 2025

Introduction
Classifier-Free Guidance (CFG)는 conditional 모델과 unconditional 모델의 score function 차이를 계산하고 가중치를 적용하여 샘플이 특정 클래스에 속할 가능성을 높이는 대표적인 샘플링 기법이다. CFG는 효과적이지만 추가적인 학습과 inference가 필요하며, 가중치가 너무 높을 경우 샘플 품질이 저하될 수 있다.
CFG에서 영감을 받아 다양한 guidance 샘플링 방법이 연구되어 왔다. 그러나 최근 방법들은 추가적인 neural function evaluation (NFE)을 필요로 하며, 두 모델 간의 차이를 계산해야 하므로 guidance-distilled model에는 적용할 수 없다.
추가적인 학습이나 NFE가 필요하지 않고, 다른 guidance 샘플링 방법과 결합할 수 있으며, guidance-distilled model에도 적용할 수 있는 범용 부스팅 방법을 개발할 수 있을까?
본 논문에서는 완전히 새로운 접근 방식을 통해 attention 기반 방법을 채택하여 이 어려운 문제를 해결하고자 하였다. 본 논문의 가장 중요한 기여는 $\alpha\textrm{-Entmax}$를 통한 sparse attention의 중요성을 발견한 것이다. $\alpha\textrm{-Entmax}$는 $\alpha \rightarrow 1$일 때 softmax이고 $\alpha = 2$일 때 sparsemax이며, 모든 $\alpha > 1$에 대해 sparsity를 가지고 logit을 확률에 매핑한다.
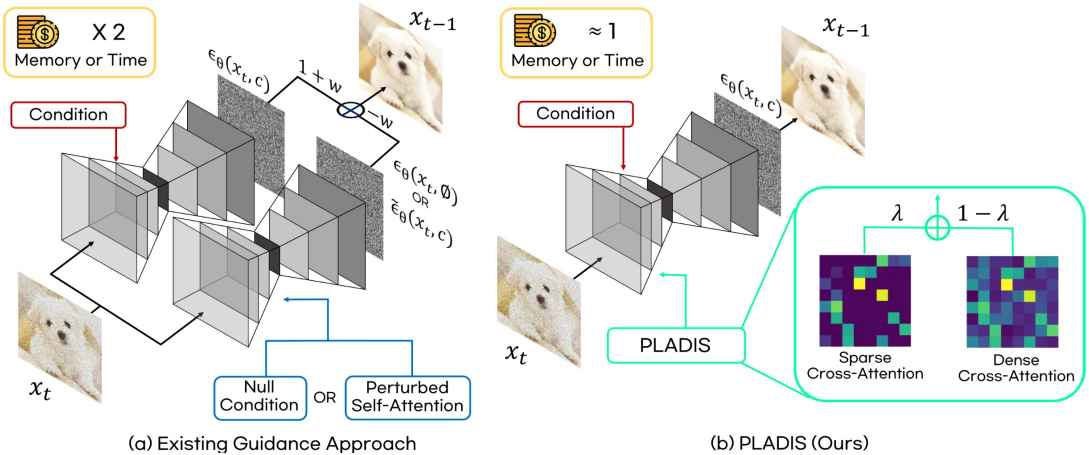
구체적으로, inference 과정에서 cross-attention을 sparse attention으로 대체한다. 추가적인 inference 시간을 필요로 하는 self-attention을 통해 모델을 약화시키는 대신, cross-attention 메커니즘을 수정함으로써 추가 inference의 필요성을 없앨 수 있다. 이는 다른 guidance 샘플링 방법 및 guidance-distilled model과의 호환성을 보장한다.
이를 바탕으로, 본 논문은 sparse attention과 dense attention 간의 차이에 가중치를 부여하여 sparsity를 강조하는 새롭고 간단한 방법인 PLADIS를 제안하였다. PLADIS는 앞서 언급한 문제점들을 효과적으로 해결하여 성능 향상과 텍스트-이미지 정렬 개선을 가져왔다.
Method
1. Entmax
\(\alpha\textrm{-Entmax}: \mathbb{R}^{M} \rightarrow \mathbb{R}^M\)는 softmax와 sparsemax를 일반화한 확률 분포 매핑 함수이다.
\[\begin{equation} \alpha\textrm{-Entmax} (\textbf{z}) = \underset{\textbf{p} \in \Delta^M}{\arg \max} [\langle \textbf{p}, \textbf{z} \rangle - \Psi_\alpha (\textbf{p})] \\ \Psi_\alpha = \begin{cases} \frac{1}{\alpha (\alpha-1)} \sum_{i=1}^M (p_i - p_i^\alpha), & \alpha \ne 1 \\ - \sum_{i=1}^M (p_i - \log p_i), & \alpha = 1 \end{cases} \end{equation}\]주로 attention에서 더 sparse한 가중치를 얻고 싶을 때 쓰인다. 기존 attention 메커니즘 $\textrm{At}$와 $\alpha\textrm{-Entmax}$를 적용한 sparse attention 메커니즘 \(\textrm{At}_\alpha\)는 다음과 같다.
\[\begin{aligned} & \textrm{At} (\textbf{Q}_t, \textbf{K}_t, \textbf{V}_t) = \textrm{Softmax} (\textbf{Q}_t \textbf{K}_t^\top / \sqrt{d}) \textbf{V}_t \\ & \textrm{At}_\alpha (\alpha, \textbf{Q}_t, \textbf{K}_t, \textbf{V}_t) = \alpha\textrm{-Entmax} (\textbf{Q}_t \textbf{K}_t^\top / \sqrt{d}) \textbf{V}_t \\ \end{aligned}\](\(\textbf{Q}_t\), \(\textbf{K}_t\), \(\textbf{V}_t\)는 timestep $t$에서의 query, key, value, $d$는 key와 value의 차원)
2. Sparse Attention for T2I Generation
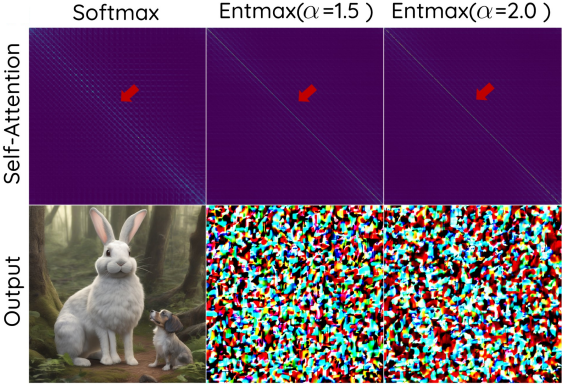
T2I diffusion model에서 sparse attention 메커니즘의 효율성을 평가하기 위해, 저자들은 먼저 표준 self-attention을 $\alpha = 1.5$와 $\alpha = 2.0$의 $\alpha\textrm{-Entmax}$로 대체했다. Self-attention의 경우 $\alpha\textrm{-Entmax}$ 대부분의 entry가 대각선을 따라 집중되는 것이 관찰되었다. 이러한 현상으로 인해 각 패치는 주로 자기 자신에게만 집중하게 되어 픽셀 간 상호 작용이 심각하게 제한되고 궁극적으로 이미지 생성에 실패하게 된다.

놀랍게도, cross-attention 모듈을 sparse attention 모듈로 대체하면 모델이 sparse attention 모듈로 학습되지 않았음에도 불구하고 생성 품질이 향상되고 텍스트 정렬이 개선되었다. 위 그림에서 볼 수 있듯이, baseline 모델은 “Boost”라는 텍스트를 정확하게 생성하지 못한 반면, sparse attention으로 변경한 모델은 성공적이고 정확하게 텍스트를 생성하였다.
3. Effect of Sparsity in Cross-Attention Module
저자들은 T2I diffusion model의 cross-attention 모듈 내 sparse attention 메커니즘에서 sparsity가 미치는 영향을 추가적으로 탐구하였다. 저자들은 sparsity의 영향을 평가하기 위해 표준 cross-attention layer를 sparse layer로 대체하고, $\alpha$ 값을 변화시키면서 CFG guidance를 사용하여 5,000개의 샘플을 생성했다.
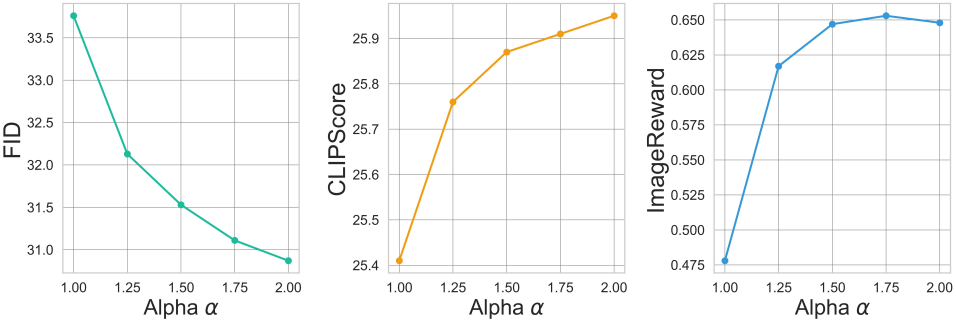
흥미롭게도, 추가 학습 없이도 $\alpha$ 값이 높아질수록, 즉 sparsity가 높아질수록 생성 품질, 텍스트 정렬, 그리고 인간 선호도 점수가 향상되었다. Sparse cross-attention은 sparse한 정렬을 생성하여 이미지와 텍스트 임베딩 간의 더욱 엄격한 일치를 보장한다. 이는 전반적인 성능 향상으로 이어진다.
4. PLADIS
Sparse attention에 대한 연구를 바탕으로, 저자들은 PLADIS라는 간단하면서도 더욱 효과적인 접근 방식을 제안하였다. 구체적으로, 추가적인 NFE를 도입하지 않고 sparse attention의 장점을 향상시키는 것을 목표로 하였다. CFG에서 영감을 받아, 저자들은 dense attention과 sparse attention의 query-key 상관관계를 extrapolation한다.
\[\begin{equation} \textrm{At}_\textrm{PLADIS} (\alpha, \lambda, \textbf{Q}_t, \textbf{K}_t, \textbf{V}_t) = \textrm{At} (\textbf{Q}_t, \textbf{K}_t, \textbf{V}_t) + \lambda (\textrm{At}_\alpha (\alpha, \textbf{Q}_t, \textbf{K}_t, \textbf{V}_t) - \textrm{At}(\textbf{Q}_t, \textbf{K}_t, \textbf{V}_t)) \end{equation}\]$\lambda$는 sparse attention 효과가 강조되는 정도를 결정하는 hyperparameter이다. Sparsity 정도 $1 < \alpha \le 2$는 또 다른 hyperparameter이지만 효율적인 알고리즘이 존재하는 것으로 알려진 두 가지 옵션 $α = 1.5$와 $α = 2$만 고려한다.
Attention 모듈을 수정하는 다른 방법에는 대상 layer에 대한 hyperparameter 탐색이 필요하다. 그러나 PLADIS의 경우 모든 cross-attention layer에 위 식을 적용하는 것만으로 충분하므로 더 쉽게 확장할 수 있다. 또한 다른 guidance 방법과 달리 추가 step이 필요하지 않으므로 guidance-distilled model로 확장할 수 있다.
Experiment
- 구현 디테일
- backbone: Stable Diffusion XL (SDXL)
- baseline hyperparameter: $\alpha = 1.5$, $\lambda = 2.0$
1. Results
다음은 MS-COCO 데이터셋에서 다양한 guidance 방법들과 비교한 결과이다.
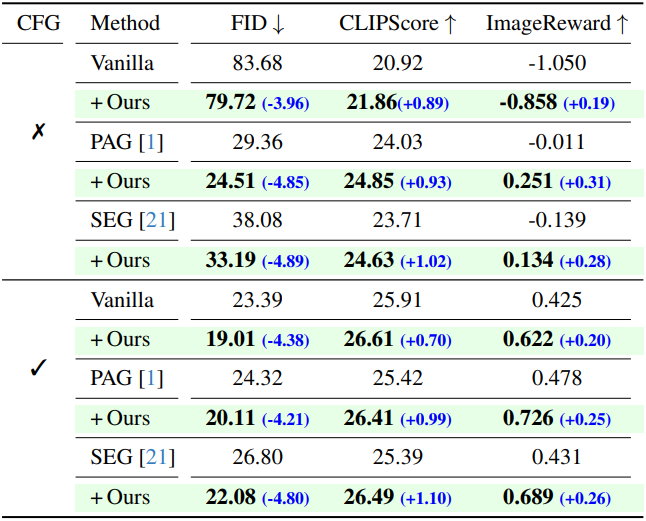
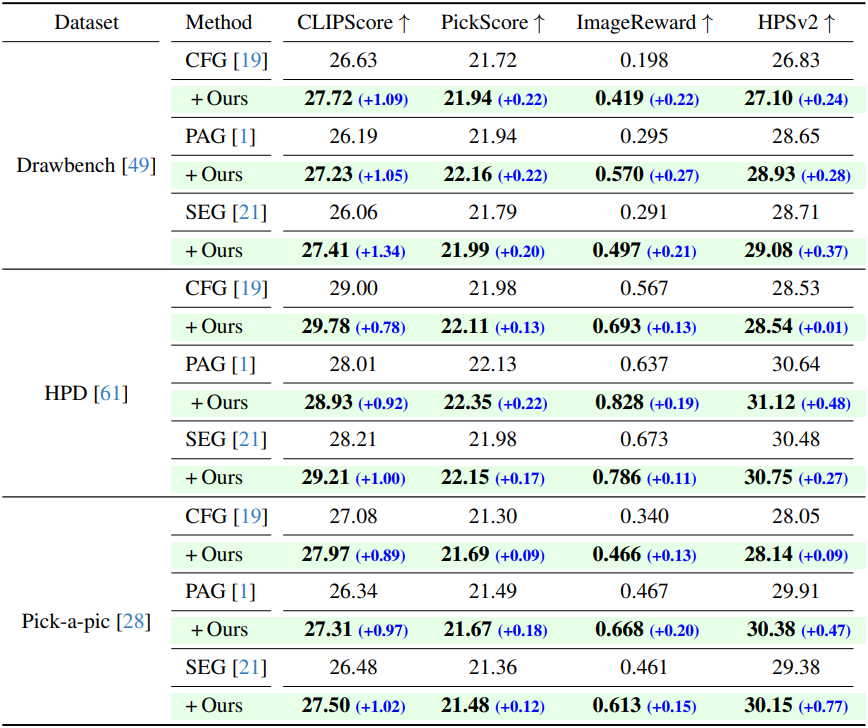
다음은 텍스트 정렬 및 인간 선호도 데이터셋에서 다양한 guidance 방법들과 비교한 결과이다.
다음은 $\lambda$에 따른 생성 결과를 비교한 예시들이다.

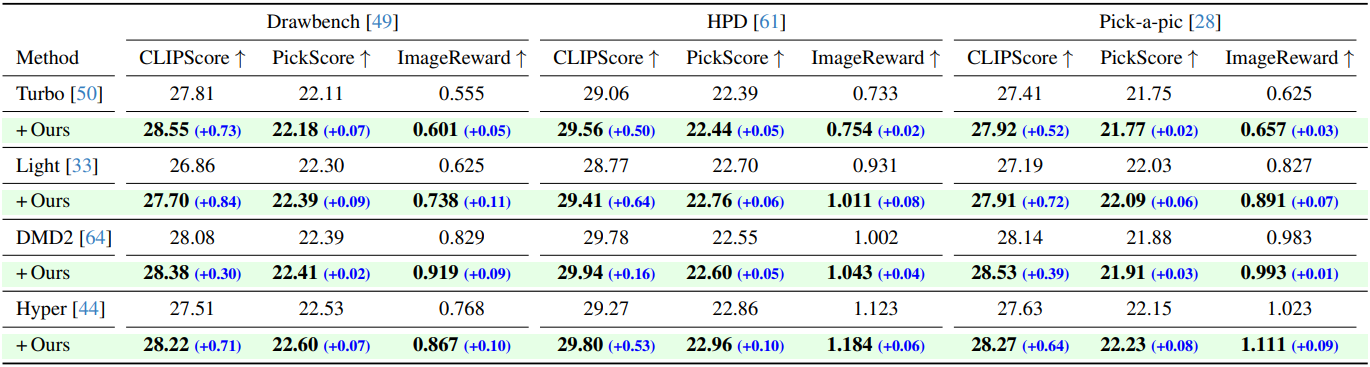
다음은 guidance-distilled model에 PLADIS를 적용한 결과이다. (4-step 샘플링)
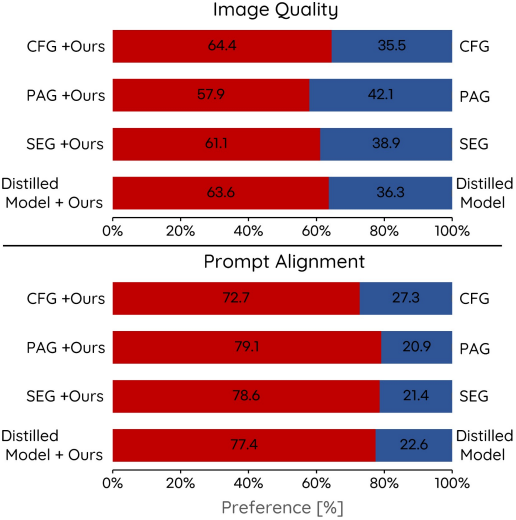
다음은 user study 결과이다.
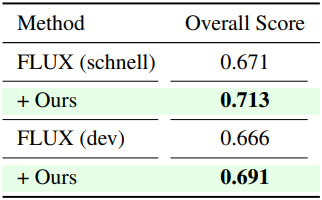
다음은 Flux에 PLADIS를 적용한 결과이다.

다음은 FreeU 및 ControlNet과 비교한 결과이다.

2. Ablation Study and Analysis
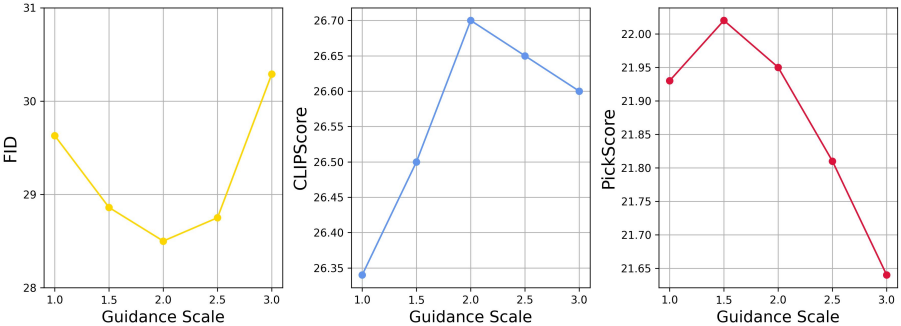
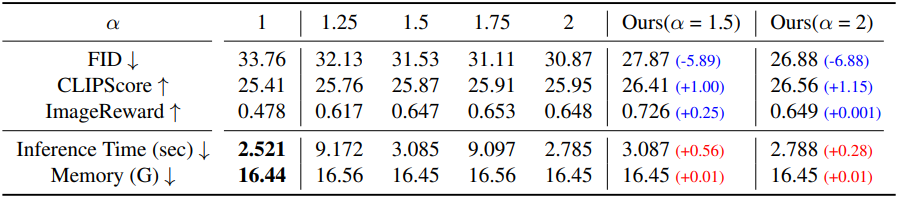
다음은 $\alpha$에 대한 ablation study 결과이다.
다음은 $\lambda$에 대한 ablation study 결과이다.